信息收集的作用:
有句话说“ 知己知彼,百战不殆 ”。最了解你的人往往都是你的对手。
如果你所掌握到的信息比别人多且更详细的时候那么你才能占据了先机,这一条不仅仅用于商业、战争、渗透测试中也适用。
工具下载:
信息收集工具 链接:https://pan.baidu.com/s/1nSJoi-N7jCIGcL2_CLLF4g
提取码:tian
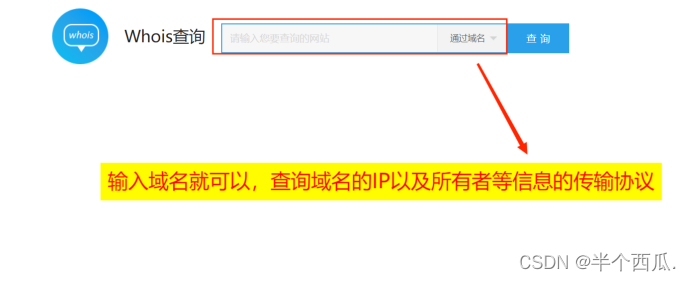
whois 是什么?
whois(读作“Who is”,非缩写)是用来查询域名的IP以及所有者等信息的传输协议。简单说,whois就是一个用来查询域名是否已经被注册,以及注册域名的详细信息的数据库(如域名所有人、域名注册商)
查询的途径:
(1)站长之家:域名Whois查询 - 站长之家
(2)爱站工具网:站长工具_whois查询工具_爱站网
(3)VirusTotal:VirusTotal
什么是备案?
网站备案是根据国家法律法规规定,需要网站的所有者向国家有关部门申请的备案,这是国家信息产业部对网站的一种管理,为了防止在网上从事非法的网站经营活动的发生.
查询的途径:
(1)天眼查:ICP备案查询_备案号查询_网站备案查询 - 天眼查
(2)ICP备案查询网:ICP备案查询网

(1)谷歌语法.
site功能:搜索指定的域名网页内容,子网和网页相关的
site:网站 “你要的信息”
site:zhihu.com“web安全”
filetype功能:搜索指定的文件类型
filetype:pdf “你要的信息”
filetype:ppt“你要的信息”
site:zhihu.com filetype:pdf“你要的信息” ———在zhihu网站里搜索pdf
inurl功能:搜索url网址存在特定关键字的网页,可以用来搜寻有注入点的网站
inurl:.php?id= ——搜索网址中有“php?id”的网页
inurl:view.php=? ——搜索网址中有“view.php=”的网页
inurl:.jsp?id= ——搜索网址中有“.jsp?id”的网页
inurl:.asp?id= ——搜索网址中有“asp?id”的网页
inurl:/admin/login.php ——搜索网址中有“/admin/login.php”的网页
inurl:login ——搜索网址中有“login”的网页
intitle功能:搜索标题存在特定关键字的网页
intitle:后台登录 ——搜索网址中是“后台登录”的网页
intitle:后台登录 filetype:php ——搜索网址中是“后台登录”的php网页
intitle:index of “keymord” ——搜索网址中关键字“keymord”的网页
intitle:index of “parent directory” ——搜索根目录 相关的索引目录信息
intitle:index of “password” ——搜索密码相关的索引目录信息
intitle:index of “login” ——搜索登录页面的信息
intitle:index of “admin” ——搜索后台登录页面信息
intext功能:搜索正文存在特定关键字的网页
intext:powered by Discuz ——搜索Discuz论坛相关的页面
intext:powered by wordpress ——搜索wordpress制作的博客网址
intext:powered by *cms ——搜索*CMS相关的页面
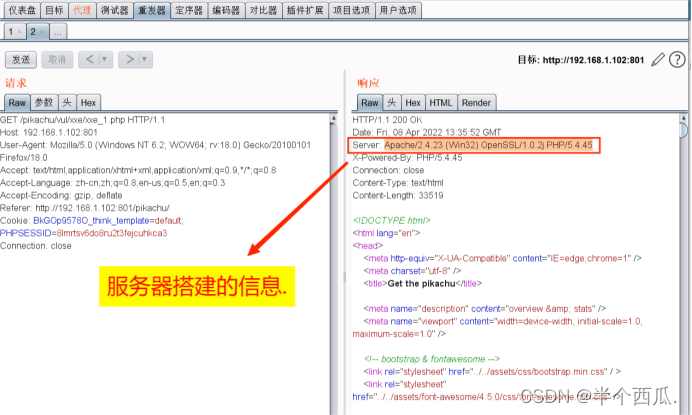
intext:powered by xxx inurl:login ——搜索此类网址的后台登录页面(2)Burp查询服务器的某些信息.(服务器用什么搭建的)
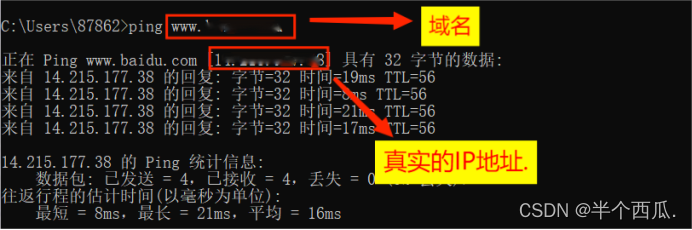
(3)IP地址(ping 指令)(查看真实的IP地址)
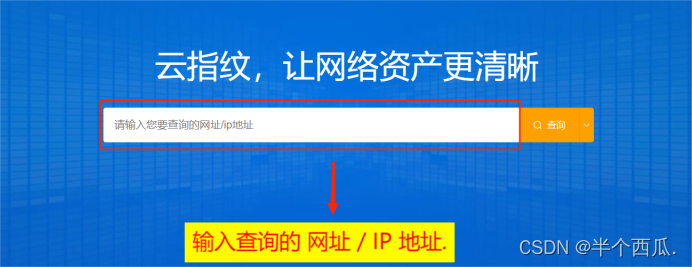
(4)网站指纹识别.(查看CMS:如Discuz ! X3.3)
1. BugScaner:在线指纹识别,在线cms识别小插件--在线工具
2. WhatWeb:WhatWeb - Next generation web scanner.
3. 云悉指纹:yunsee.cn-2.0
(5)网站容器.( nmap扫描 )
扫描一般用的:(1)主机发现:nmap -sn 地址/24
(2)端口扫描:nmap -sS 地址
(3)系统扫描:nmap -o 地址
(4)版本扫描:nmap -sV 地址
(5)综合扫描:nmap -A 地址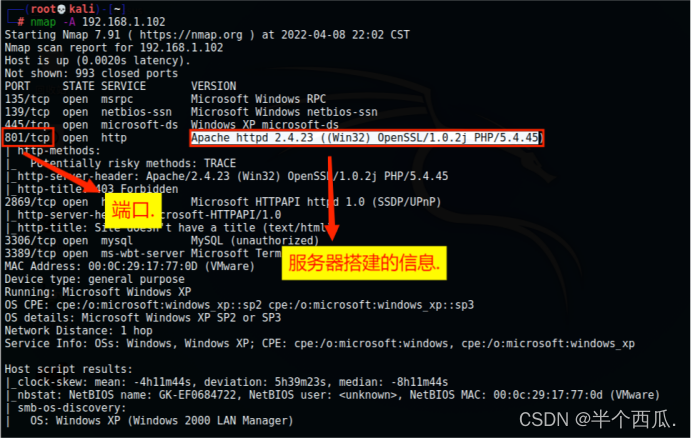
(6)查看服务器有什么脚本类型(直接看网址)
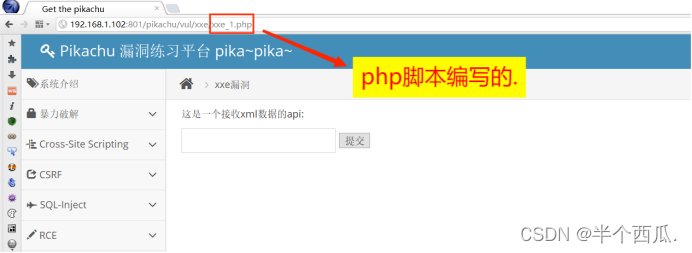
(7)数据库类型.
常见搭配:
ASP 和 ASPX 网站搭建:ACCESS、SQL Server (数据库)
PHP 网站搭建:MySQL、PostgreSQL (数据库)
JSP 网站搭建:Oracle、MySQL (数据库)为什么要收集子域名?
1.子域名枚举可以发现更多评估范围相关的域名/子域名,以增加漏洞发现机率;
2.探测到更多隐藏或遗忘的应用服务,这些应用往往可导致一些严重漏洞;
(1)谷歌语法.
Site:域名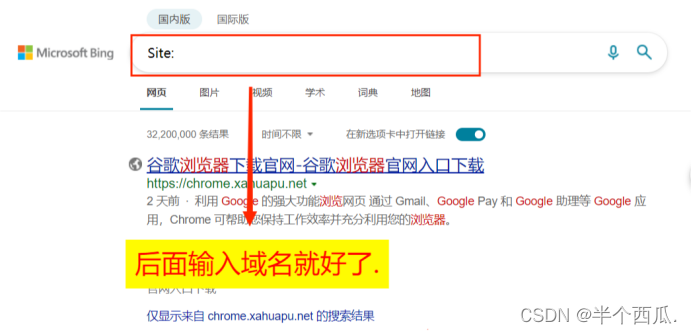
(2)在线子域名爆破:在线子域名查询
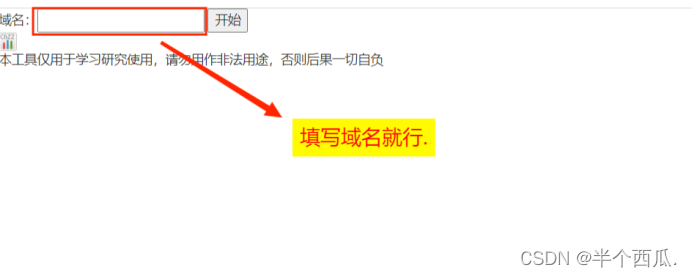
(3)Loyer子域名挖掘
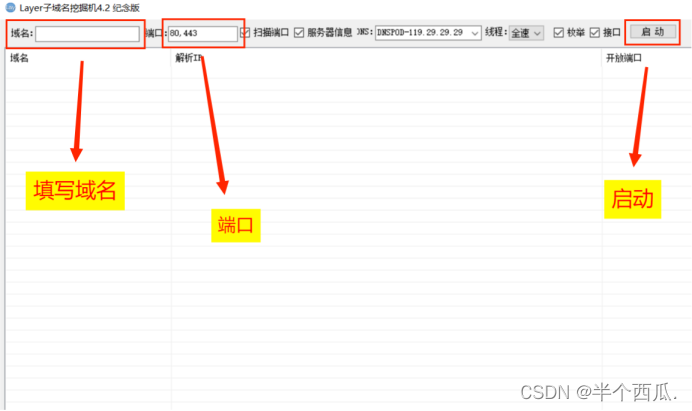
为什么收集常用端口信息?
在渗透测试的过程中,对端口信息的收集是一个很重要的过程,通过扫描服务器开放的端口以及从该端口判断服务器上存在的服务,就可以对症下药,便于我们渗透目标服务器.
常见的扫描端口工具:
(1)Nmap
端口扫描:nmap -sS 地址
默认扫描:nmap 地址
指定端口扫描:nmap –p 端口 地址
完整扫描到端口、服务及版本:nmap –v –sV 地址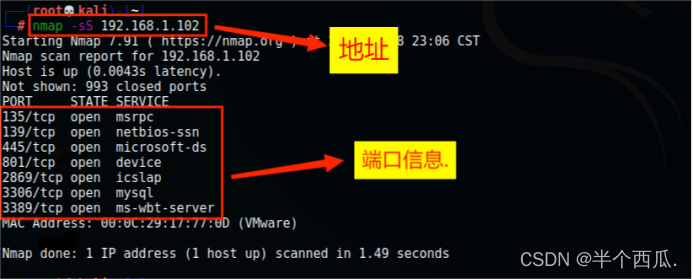
(2)Masscan
masscan IP地址 -p 端口(1-10000)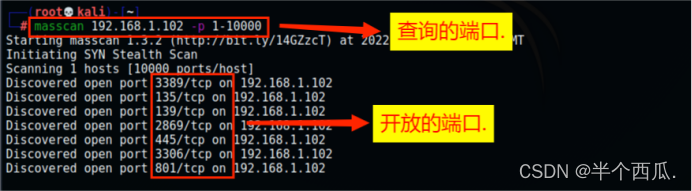
(3)御剑高速TCP端口扫描工具

为什么要进行指纹识别?
快速识别出网站的搭建环境,网站使用的系统,网站防火墙,和cms源码中使用的一些js库.
指纹识别工具:
(1)在线指纹识别工具:在线指纹识别,在线cms识别小插件--在线工具 (bugscaner.com)
(2)云悉在线CMS指纹识别平台:云悉互联网WEB资产在线梳理|在线CMS指纹识别平台 - 云悉安全平台 (yunsee.cn)
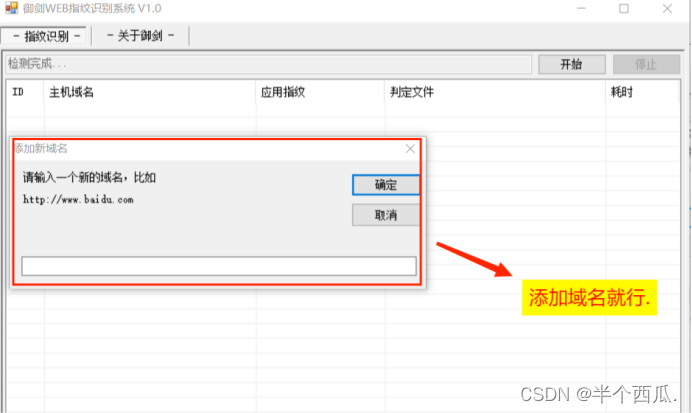
(3)御剑web指纹识别系统:
什么是CDN ?
CDN的全称Content Delivery Network,即内容分发网络,CDN的基本原理是广泛采用各种缓存服务器,将这些缓存服务器分布到用户访问的网络中,在用户访问网站时,由距离最近的缓存服务器直接响应用户请求.
(1)全球 Ping 检测.
(2)查询网查询.
查询网:ip地址查询 ip查询 查ip 公网ip地址归属地查询 网站ip查询 同ip网站查询 iP反查域名 iP查域名 同ip域名
(3)web in Lookup 查询.
链接:ip地址查询 ip查询 查ip 公网ip地址归属地查询 网站ip查询 同ip网站查询 iP反查域名 iP查域名 同ip域名
(4)子域名IP.
链接:在线子域名查询
(5)查询网址
链接:https://securitytrails.com/
(6)crt.sh的查询.
链接:crt.sh | Certificate Search
为什么要收集敏感目录文件?
在渗透测试中,最关键的一步就是探测web目录结构和隐藏的敏感文件,因为可以获取到网站的后台管理页面、文件上传页面、甚至可以扫出网站的源代码.
常用工具:
(1)dirb 工具.
dirb 地址 (比如:dirb http://192.168.1.102:801/)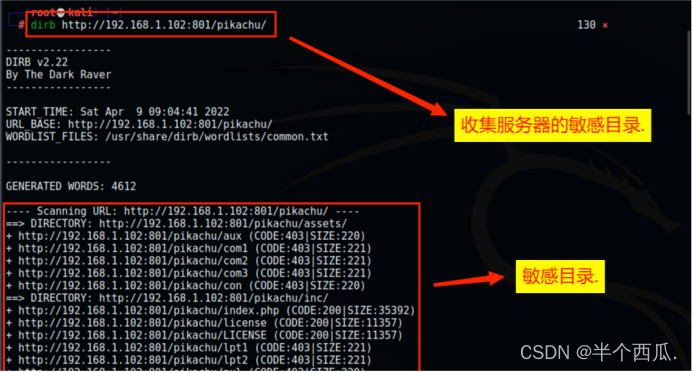
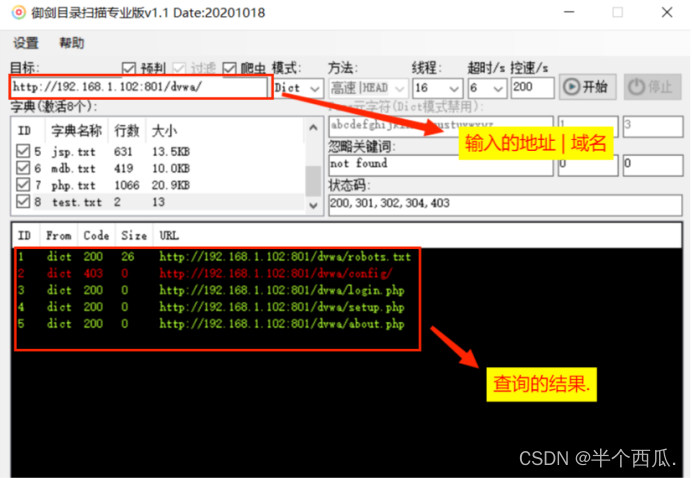
(2)御剑敏感目录收集工具.
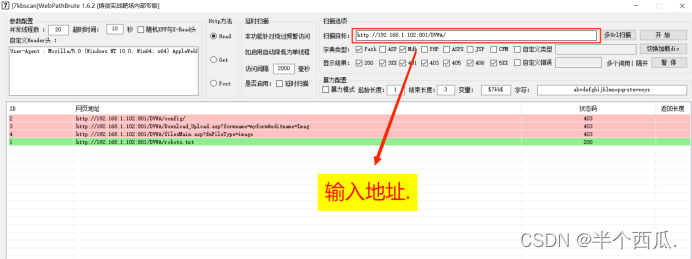
(3)7KBwebpathBurute
(4)也可以用更高级的工具:Awvs,Nessus,Burp爬虫等等.
什么是社会工程学?
社会工程学(Social Engineering,又被翻译为:社交工程学)在上世纪60年代左右作为正式的学科出现,广义社会工程学的定义是:建立理论并通过利用自然的、社会的和制度上的途径来逐步地解决各种复杂的社会问题,经过多年的应用发展,社会工程学逐渐产生出了分支学科,如网络社会工程学.
(1)QQ号:查询QQ号 看看朋友圈有没有开放(里面会有一些信息可以收集.)
(2)微信号:转账--的时候会有一个真实姓名(朋友圈可能有信息可以收集.)
(3)支付宝--转账--的时候会有一个真实姓名.(就可以收集真实姓名的一个字.)
(4)电话:查询可以收集到这个电话是哪个地方的等等,操作都可以收集到信息的.(打电话)
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
您如何在Rails中的实时服务器上进行有效调试,无论是在测试版/生产服务器上?我试过直接在服务器上修改文件,然后重启应用,但是修改好像没有生效,或者需要很长时间(缓存?)我也试过在本地做“脚本/服务器生产”,但是那很慢另一种选择是编码和部署,但效率很低。有人对他们如何有效地做到这一点有任何见解吗? 最佳答案 我会回答你的问题,即使我不同意这种热修补服务器代码的方式:)首先,你真的确定你已经重启了服务器吗?您可以通过跟踪日志文件来检查它。您更改的代码显示的View可能会被缓存。缓存页面位于tmp/cache文件夹下。您可以尝试手动删除
在Ruby中是否有Gem或安全删除文件的方法?我想避免系统上可能不存在的外部程序。“安全删除”指的是覆盖文件内容。 最佳答案 如果您使用的是*nix,一个很好的方法是使用exec/open3/open4调用shred:`shred-fxuz#{filename}`http://www.gnu.org/s/coreutils/manual/html_node/shred-invocation.html检查这个类似的帖子:Writingafileshredderinpythonorruby?