分享嘉宾:刘冰冰 亚马逊云科技
编辑整理:张了了 聚水潭
出品平台:DataFunTalk
导读:数据库经过了几十年的发展,目前已经是一项非常成熟的技术,然而随着当今互联网的极速增长,我们进入到云时代,企业亟需构建现代化的应用,因此数据库有了更大的挑战。今天结合当前时代的发展和趋势,分享未来数据库需要关注的硬核创新。
今天的介绍围绕以下几部分展开:
--

当今社会IT的快速发展,对诞生于20世纪70年代初的数据库技术提出了更高的要求。
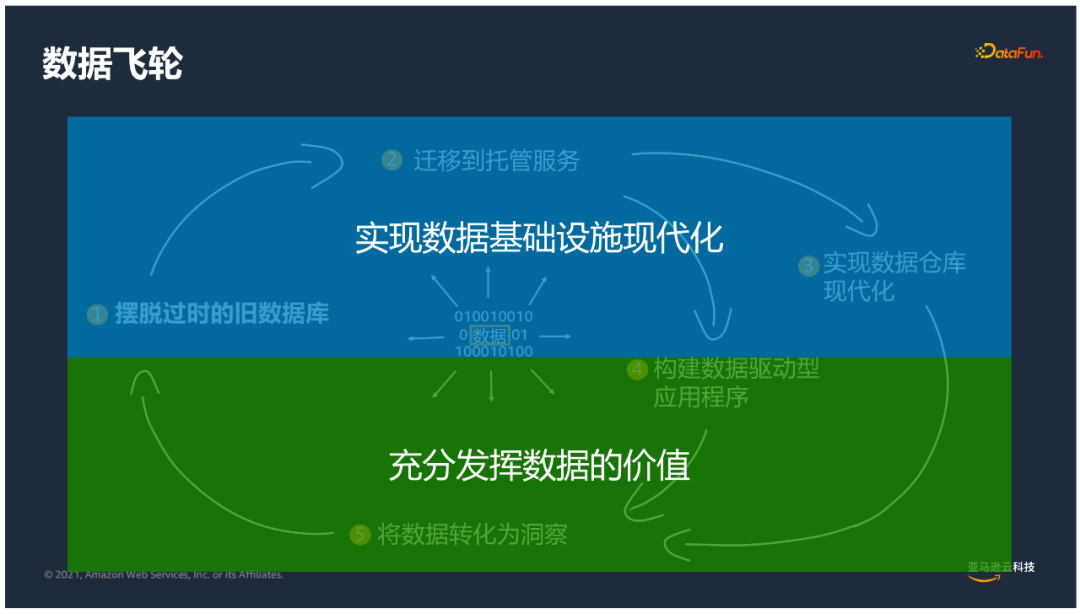
不可否认的是当今时代数据已经成为企业最宝贵的资产,数据库作为存储和管理数据的载体,合理利用可以使企业的数据飞轮转起来,充分发挥数据的价值,使数据转化为业务洞察来指导企业发展。
数据库在企业存储和分析、现代化支撑方面起到了非常重要的作用,因此数据库需要做出更多创新;摆脱传统数据库的使用方式,通过迁移上云的方式来实现托管服务,然后基于数据库构建现代化云数据库,基于数据驱动的应用,把数据转化为洞察。
数据库的现代化过程,对企业也非常重要。数据基础设施的建设,数据库的支撑以及数仓的构建可以使企业中的数据充分流转,发挥出应有的价值。

很多企业目前还是在自己的IDC数据中心去管理数据库,会有很多挑战,主要有以下几种:
很多用户在使用传统关系型数据库,面临着成本高、license惩罚性许可导致的不方便、管理复杂等问题。

很多用户使用传统的关系型数据库都会遇到这些挑战:成本高昂、技术专有化、管理数据库的学习成本高、管理工作复杂,还会遇到License的限定等问题。
基于以上挑战,目前越来越多用户希望利用云的资源来实现数据库的创新,包括:
--
云原生数据库是一种构建和运行都充分利用云计算模型优势的构建数据库的方法。亚马逊云科技VP Adrian Cockcroft提出,云原生架构充分利用按需交付、全球部署、弹性和更高级别的服务,它们大大提高了开发人员的开发效率、业务敏捷性、可拓展性、可用性,资源利用率和成本节约。
我们把客户对云的接受分为了云好奇、云亲近和云原生三个阶段。
和数据库相结合,再去理解云原生,就是利用云上的创新的技术和架构赋能数据库,让数据库有更好的敏捷性、扩展性、高性能,从而实现全球部署、按需交付和弹性,以及高可用性。
基于以上理解,亚马逊发布了业界第一个云原生数据库Amazon Aurora,这也是亚马逊云科技历史上用户数量增速最快的云服务。它具有如下优势:
① Amazon Aurora的特点
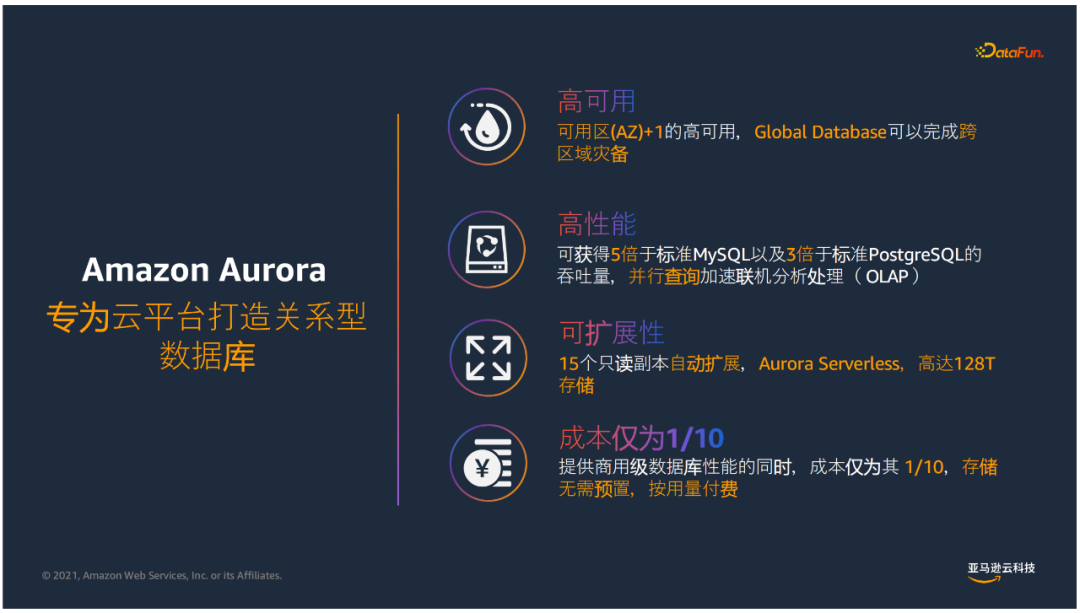
可以实现最多可容忍AZ+1失效的高可用性,设计面向金融级跨3个AZ的数据库,同时提供了Global Database完成跨区域灾备。
可获得5倍于标准MySQL以及3倍于标准postgreSql的吞吐量,并行查询加速联机分析处理。
15个只读副本实现扩展性,Aurora Serverless来实现无服务器架构按需、自动拓展的数据库服务,可以实现无业务时自动关闭、按需启动数据库;同时拥有128T的存储。
提供商用级数据库性能的同时,成本仅为传统商业版数据库1/10,存储无需预置,按量付费。
② 设计原则及架构
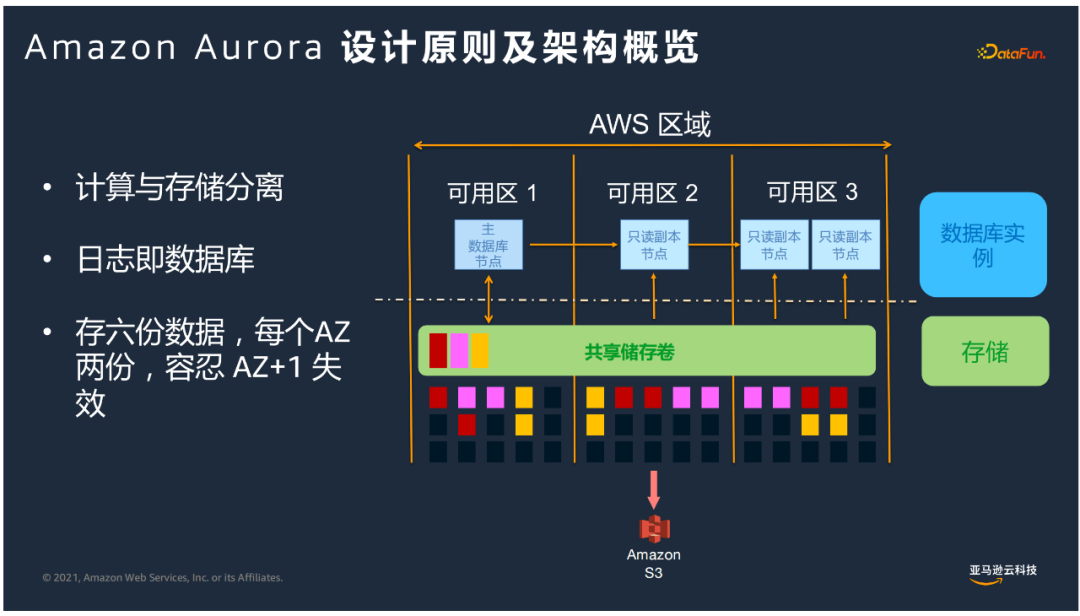
基于计算层和存储层分别进行拓展,计算拓展8-10分钟。
消除了数据库这端很多脏页回写到存储的动作,变化的日志流存储到共享储存卷来处理。
每个AZ存两份数据,即跨三个AZ存储6个数据副本,做到了保障开箱即用金融级别的高可用性,如果有一个AZ故障,依然可以保证4/6副本,保持可写的状态;如果有AZ+1故障,依然有3份副本,不会有数据丢失,可以通过幸存的3副本恢复损坏的副本来恢复写能力;如果面临整个区域故障,Global Database提供了跨区域的灾备能力。
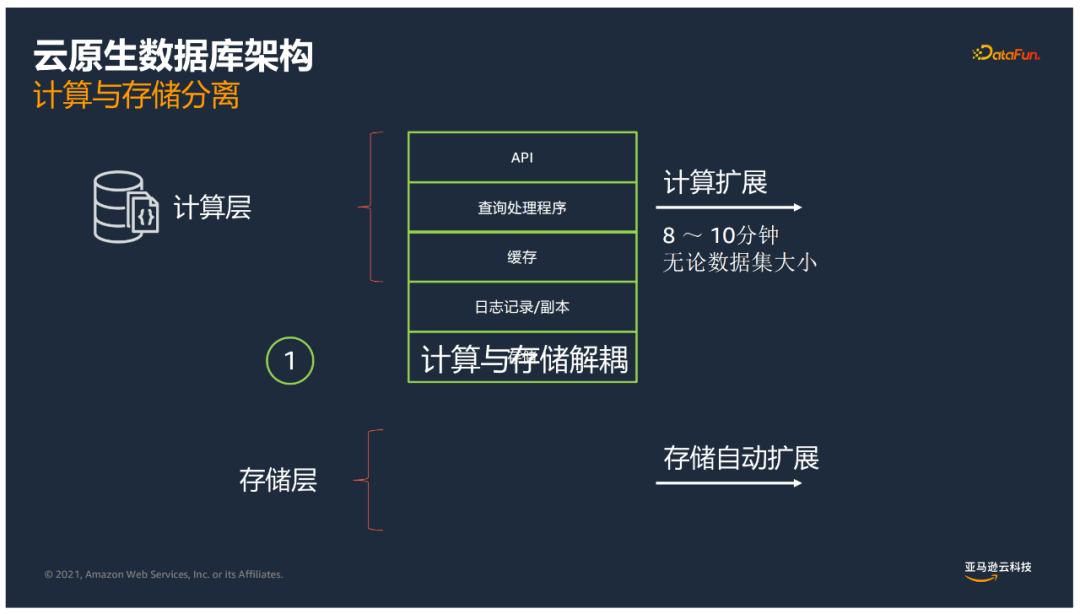
我们把很多数据库计算的动作下推到智能的存储引擎。计算与存储解耦,计算层和存储层可根据各自需求进行扩展。无论数据量多大,计算扩展速度可以很快。
③ Amazon Aurora 提供极致可用性

Aurora实现了开箱即用金融级的高可用性。如果一个数据中心宕掉了,再加上另一个AZ里的一份数据宕掉了,数据库仍然可以访问。因为在数据层面,是把数据打散,10GB为一个单元,每个数据有6份拷贝,每个AZ是两份,这样可以保证面临AZ+1故障时,仍然有3份拷贝可读。同时,我们还通过Global Database提供了跨区域的灾备。
④ 客户案例

九州通B2B系统的业务特点是读多写少,之前遇到过以下挑战:
使用了Aurora之后明显有了提升,主要体现在以下几方面:
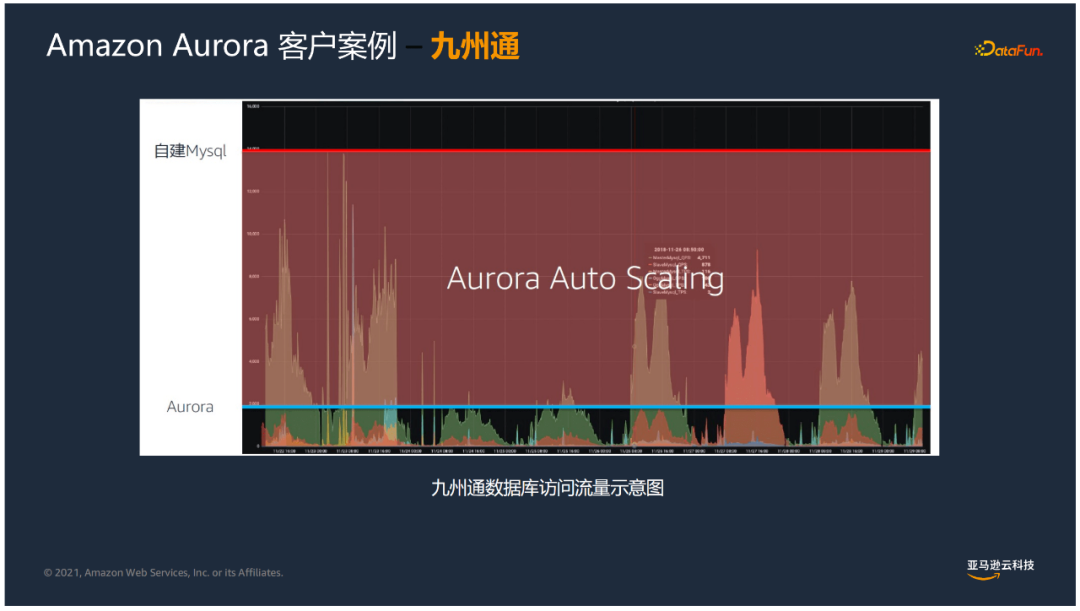
上图中可以看到,原来的自建Mysql需要把资源开的很高,来应付业务高峰时的负载。而Aurora按需而动,在高峰来临时扩展读副本,负载下降后再回缩读副本,有非常好的伸缩性。
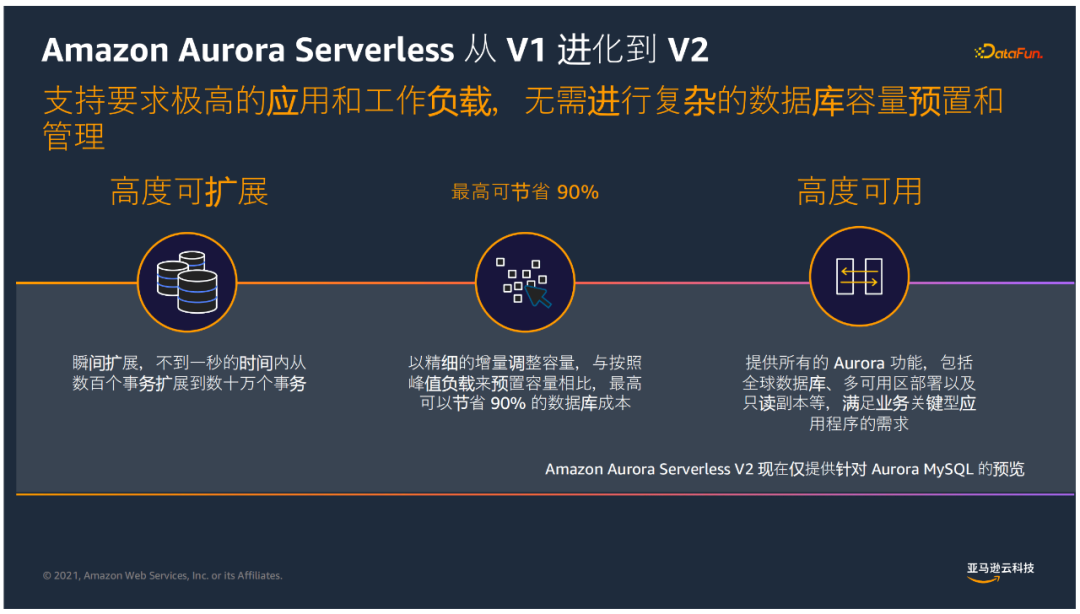
⑤ Aurora Serverless

Aurora Serverless是Aurora提供的无服务架构,扩展性有了更高提升,可以实现以下功能:
⑥ Aurora Global Database
现代化应用的全球部署,需要通过构建数据库:
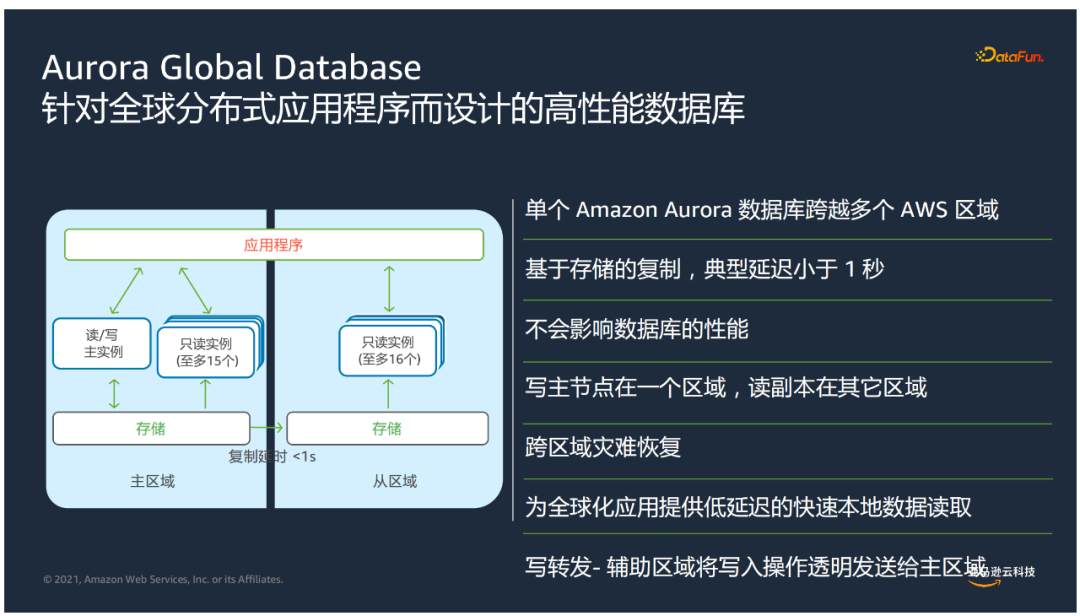
Global Database是针对全球分布式应用程序而设计的高性能数据库,有以下特点:

使用了Aurora之后明显有了提升,主要体现在以下几方面:
--
迁移对于企业来说是面临的一个较大挑战,怎么无缝实现从传统的数据库迁移到云上?下面来介绍另一个硬核创新,云原生数据库迁移利器。
① 挑战
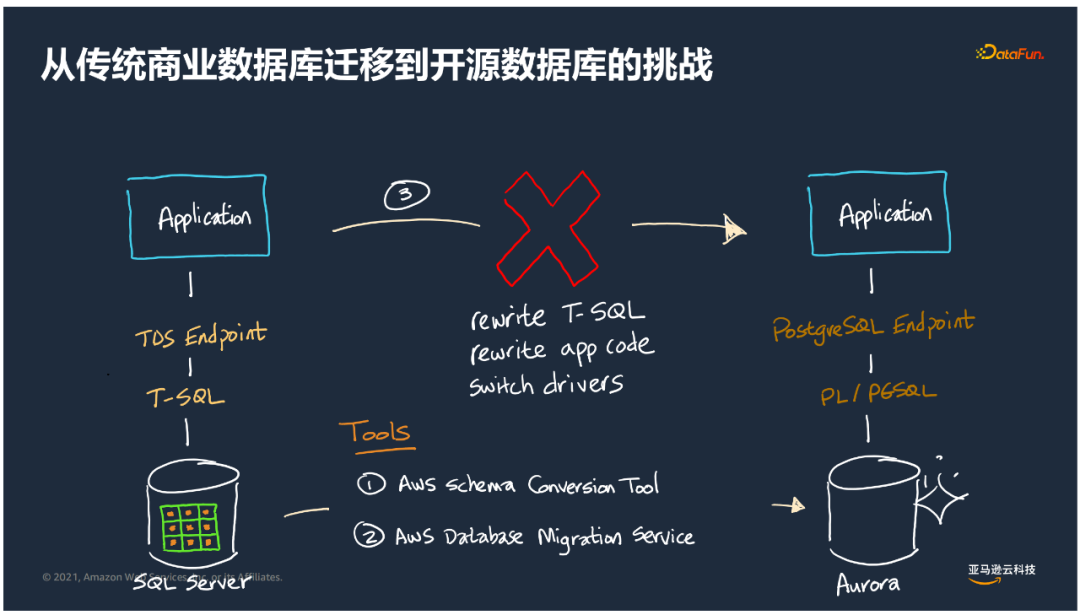
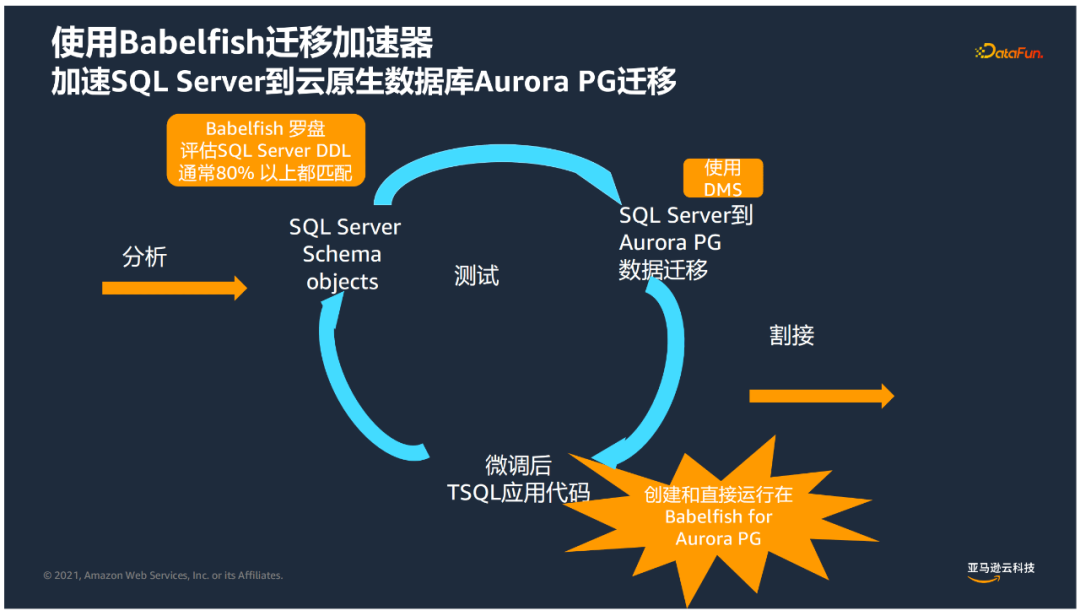
以微软SQL Server迁移到Aurora PGSQL为例:
② Babelfish for Aurora PostgreSQL
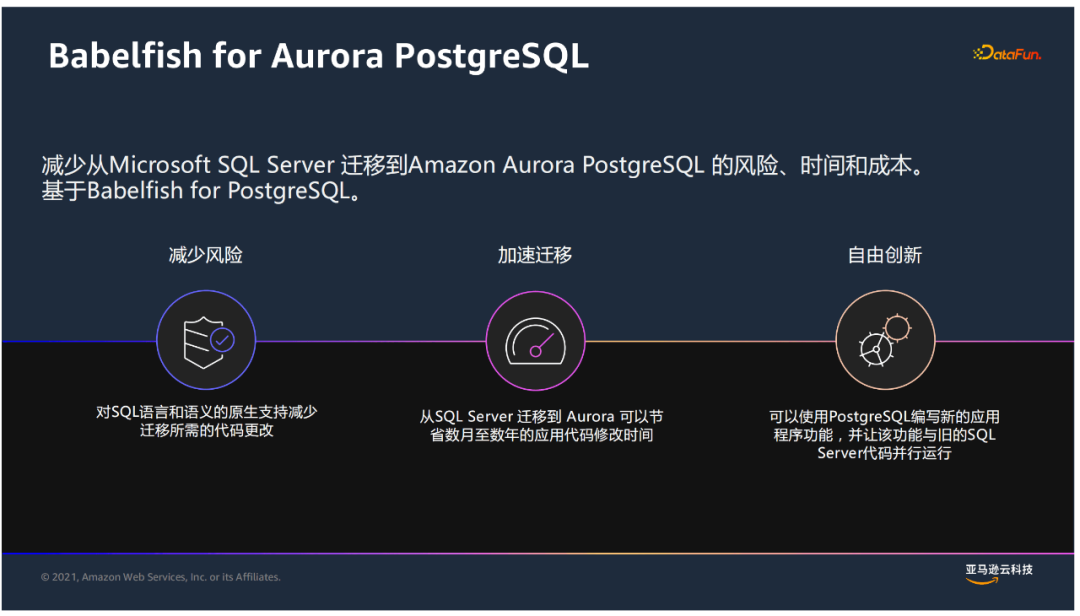
它能够原生地支持对T-SQL语言的理解,同时支持SQL Server协议访问,这样使得迁移时间大大缩短。迁移后,既可以访问原有的SQLServer代码,又可以利用PostgreSQL编写新的功能,并且两者之间可以进行调用。
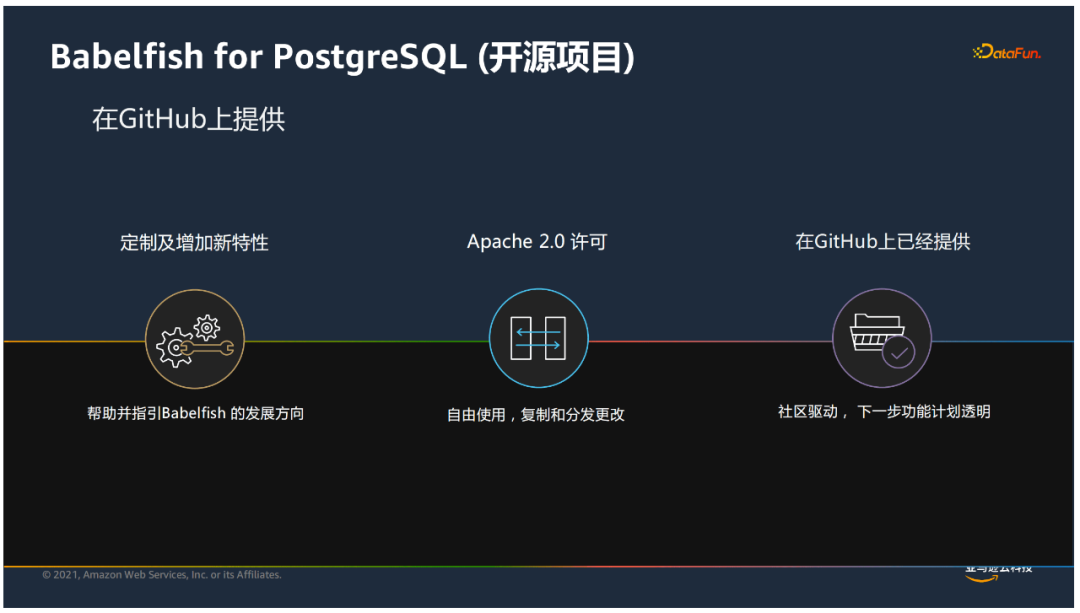
我们也已将Babelfish for PostagreSQL项目开源。
③ Babelfish部署模型
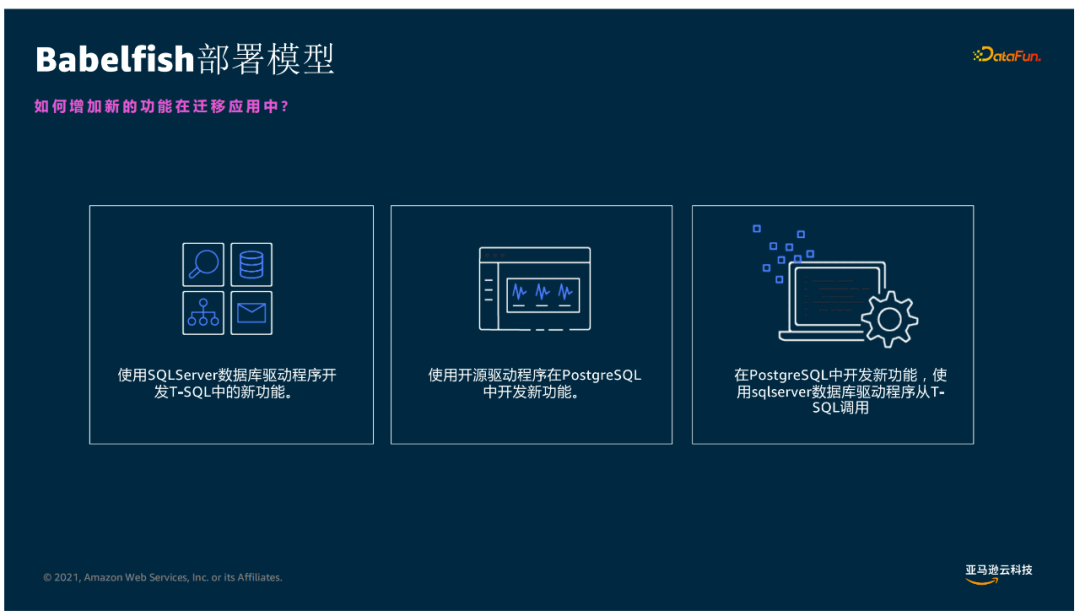


④ 迁移流程
--
Q:Aurora后续有开源的计划吗?
A:我们目前已经把一些Aurora相关的项目在开源,例如Babelfish for Aurora PostgreSQL , 希望能将亚马逊云科技更多技术赋能客户和开源社区,助力客户和开源社区持续的技术创新。
Q:Aurora底层的存储复制使用的技术?
A:Aurora存储层复制使用Quorum协议实现,把数据块划分为10GB为一个单元,每份数据6份副本,将6个副本存储在3个AZ,为了满足一致性,需要满足两个条件,首先Vr + Vw > V,V=6,Vw=4,Vr=3,Aurora可以实现开箱即用的金融级高可用性 (跨3个AZ,最多可容忍AZ+1故障):Aurora可以容忍任何一个AZ出现故障,不会影响写服务;任何一个AZ出现故障,以及另外一个AZ中的一个节点出现故障,不会影响读服务且不会丢失数据。
今天的分享就到这里,谢谢大家。
分享嘉宾:

本文首发于微信公众号“DataFunTalk”。
当我使用Bundler时,是否需要在我的Gemfile中将其列为依赖项?毕竟,我的代码中有些地方需要它。例如,当我进行Bundler设置时:require"bundler/setup" 最佳答案 没有。您可以尝试,但首先您必须用鞋带将自己抬离地面。 关于ruby-我需要将Bundler本身添加到Gemfile中吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/4758609/
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只
我实际上是在尝试使用RVM在我的OSX10.7.5上更新ruby,并在输入以下命令后:rvminstallruby我得到了以下回复:Searchingforbinaryrubies,thismighttakesometime.Checkingrequirementsforosx.Installingrequirementsforosx.Updatingsystem.......Errorrunning'requirements_osx_brew_update_systemruby-2.0.0-p247',pleaseread/Users/username/.rvm/log/138121
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Rubysyntaxquestion:Rational(a,b)andRational.new!(a,b)我正在阅读ruby镐书,我对创建有理数的语法感到困惑。Rational(3,4)*Rational(1,2)产生=>3/8为什么Rational不需要new方法(我还注意到例如我可以在没有new方法的情况下创建字符串)?
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co