单元测试是所有测试中最底层的一类测试,是第一个环节,也是最重要的一个环节,是唯一一次有保证能够代码覆盖率达到100%的测试,是整个软件测试过程的基础和前提,单元测试防止了开发的后期因bug过多而失控,单元测试的性价比是最好的。
覆盖率(code coverage rate)是反映测试用例对被测软件覆盖程度的重要指标,也是衡量测试工作进展情况的重要指标。在代码逻辑比较复杂的情况下,测试工作往往只能覆盖到显而易见的逻辑分支,而更多的深层次的逻辑分支则不容易被测试人员发现。为了保证测试的覆盖率,有些开发人员会尝试协助测试人员写出所有的测试用例,这不仅会牺牲大量的宝贵的开发时间,同时也拥有一定的难度,最重要原因就是因为测试难以量化。而代码覆盖工具就是用来量化代码测试的覆盖率,让测试人员可以直观的发现那些没有覆盖到的代码分支。
先介绍Qt代码做单元测试和生成报告的途径有哪些,后面会详细介绍具体怎么操作
推荐使用:在 Linux下通过Qt使用gtest和qtest,然后通过lcov导出生成报告。 下面介绍原因。
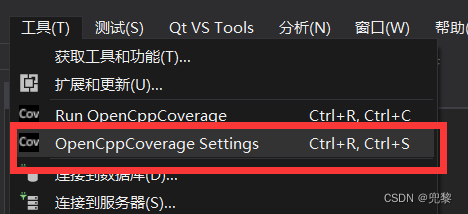
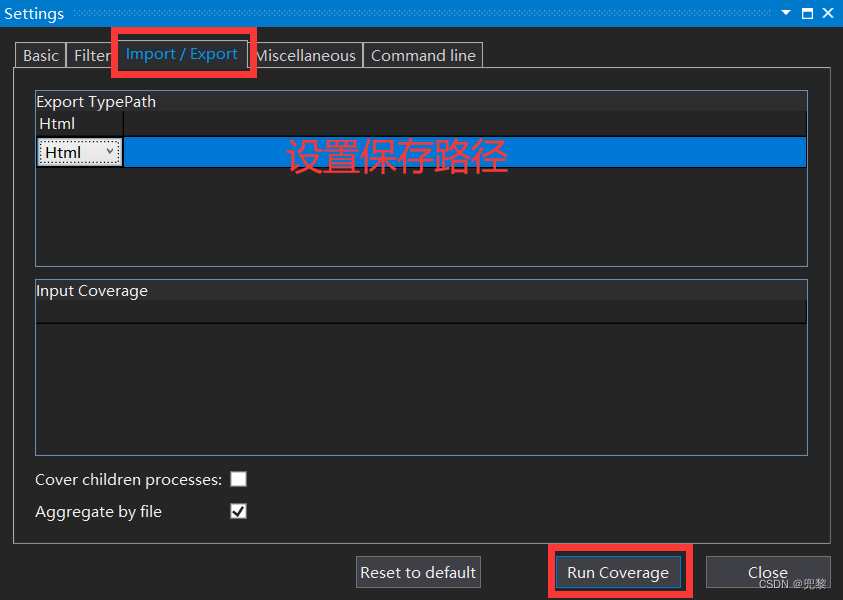
对于界面来说,需要点击才能产生覆盖率,这个不是特别友好
include(../test/test.pri) # 测试子工程
include(../gtest/googletest/gtest_dependency.pri) # gtest 子工程
QMAKE_LFLAGS +=-fprofile-arcs -ftest-coverage
QMAKE_CXXFLAGS += --coverage # 申明为要做单元测试
LIBS += -lgcov # 引入库文件
// 依赖的头文件
#include <gtest/gtest.h>
#include <gmock/gmock.h>
::testing::InitGoogleTest(&argc, argv); // 在mian函数中 初始化测试环境
return RUN_ALL_TESTS(); // 运行所有测试单元
TEST(test_case_name, test_name)
{
std::unique_ptr<***> p = std::make_unique<***>();
}
Qt下查看测试情况:
| 命令 | 意义 |
|---|---|
| ENABLE BRANCH="–rc lcov branch coverage=1 | 打开分支覆盖率显示 |
| lcov -d .-c -o r.info $(ENABLE BRANCH} 1>/dev/null | 1>/dev/null也可以去掉,它的作用是不输出信息到终端 |
| genhtml --branch-coverage -o result $ENABLE BRANCHI rinfo | 生成全部覆盖率信息 r.info 总的覆盖率信息,并生成到result 文件夹中 |
| lcov --extract rinfo '* /path/*i -o resultinfo | 抽取想要的覆盖率信息,eg:抽取path下的覆盖率信息 ,具体可以通过result文件夹下indes.html 中查看要抽取部分,可以多个 |
| genhtml result.info -o output/ | 重新生成报告,并导出到 output文件夹中 |
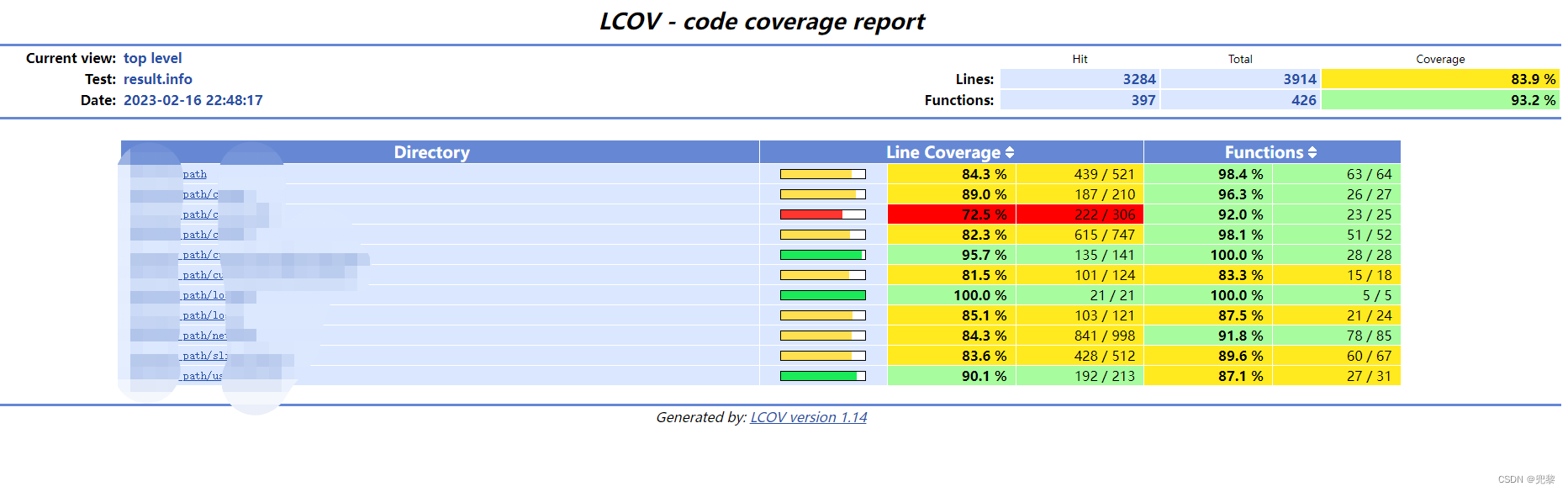
除了导出报告方法和Linux不一样外,其他步骤和Linux一样
生成报告命令**(coverage.html报告名,可修改)**:
gcovr -r . --html --html-details -o coverage.html
但是有个问题,只能生成ui_.h和moc_.cpp的报告,具体怎么生成源码测试报告的方案没研究明白
有研究明白的或者知道怎么生成的,希望留言指教,谢谢**
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A