学习文档地址:Elasticsearch Guide [7.16] | Elastic
全文检索属于最常见的需求,开源的ElasticSearch是目前全文检索引擎的首选。它可以快速的存储、搜索、分析海量数据。维基百科、StackOver Flow、Github都采用它。ElasticSearch的底层开源库Lucene。但是,你没有办法直接用Lucene,必须自己写代码去调用它的接口。ElasticSearch是Lucene的封装,提供了REST API 的操作接口,开箱即用。
①应用程序搜索、网站搜索、企业搜索
②日志处理和分析
③基础设施指标和容器检测
④应用程序性能检测
⑤地理空间数据分析和可视化
⑥安全分析、业务分析
1.索引(Index)
ES中的索引若当动词类比于Mysql的insert
ES中的索引若当名词类比于Mysql的database
2.类型(Type)
ES中的类型类比于Mysql中的table
3.文档(Document)
ES中的文档类比于Mysql中的记录,并且ES中的文档是json格式的数据
4.倒排索引
ES为什么能快速的进行全文检索的原因在于为数据创建倒排索引
什么是倒排索引?
将数据拆分为一个个的字或者多个词,并且为将含有某个字或词的数据添加这个字或词的索引中
例如:

 相关性得分:用于将检索的数据进行一个排序,即看命中率
相关性得分:用于将检索的数据进行一个排序,即看命中率
例如:检索红海特工行动,就会将红海特工行动分为红海、特工、行动三个词,会将1,2,3,4,5都检索出来,文档1是红海行动即命中了红海、行动两个词,即2中2肯定是排在第一位,文档2和文档3是3中2,文档4是2中1,文档5是4中2。
①设置虚拟机的内存大小
Vagrant 如何调整虚拟机的内存大小?_axfcjwkbi259888707的博客-CSDN博客


② 下载镜像文件
# 下载ES镜像文件,存储和检索数据
sudo docker pull elasticsearch:7.4.2
# 下载可视化kibana镜像文件,可视化检索数据
sudo docker pull kibana:7.4.2③ 创建目录及配置
# 创建目录方便挂载
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
# 配置允许主机访问
echo " http.host: 0.0.0.0" >> /mydata/elasticsearch/config/elasticsearch.yml

④运行容器
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
9200是访问端口,9300是集群节点交流端口,ES_JAVA_OPTS="-Xms64m -Xmx512m" 设置ES的占用内存,-v设置映射文件
访问:http://192.168.56.22:9200
出现问题:访问拒绝
出现原因:文件权限不够,访问拒绝
# 查看容器日志
docker logs elasticsearch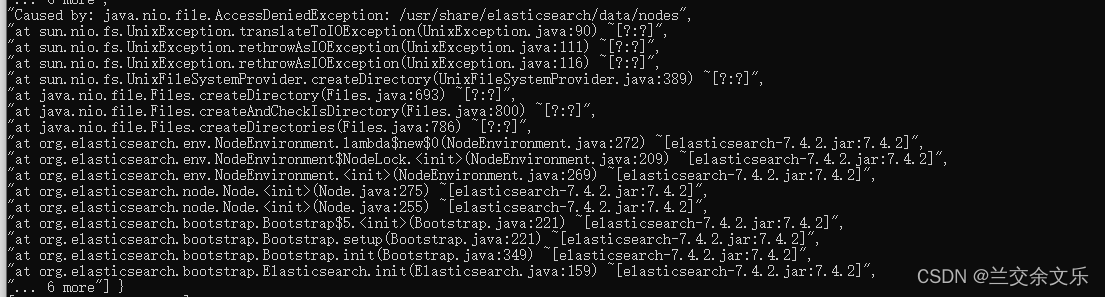
解决方案: 将任意组任意成员的访问权限设置为rwx, - R :递归
chmod -R 777 /mydata/elasticsearch重启容器
docker start [id]

看到以下界面,则说明ES安装成功:

设置ES开机自启动
sudo docker update elasticsearch --restart=always①创建容器,注意写自己的ip地址
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.56.22:9200 -p 5601:5601 \
-d kibana:7.4.2

看到以下界面,则说明kibana安装成功
设置kibana开机自启动
sudo docker update kibana --restart=always①查看所有节点:GET /_cat/nodes
 ② 查看ES的健康状况:GET /_cat/health
② 查看ES的健康状况:GET /_cat/health
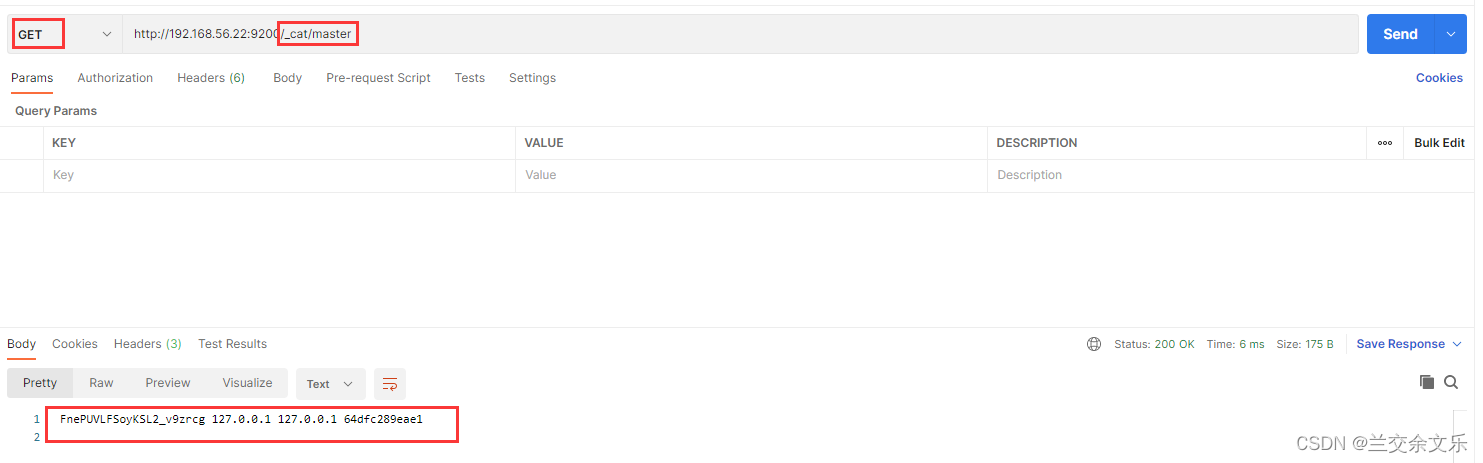
 ③查看主节点:GET /_cat/master
③查看主节点:GET /_cat/master
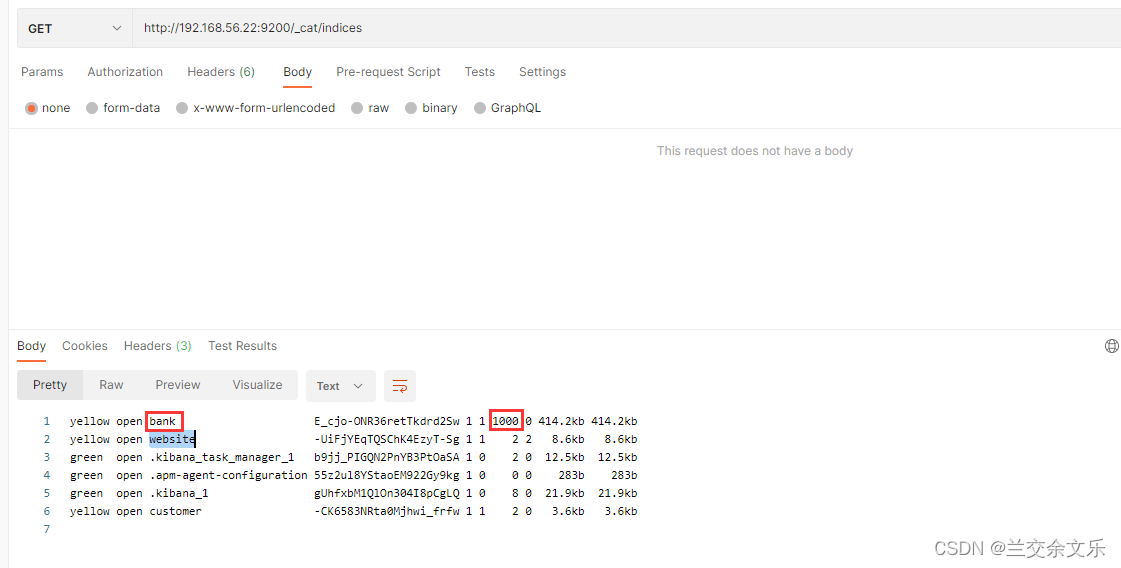
④ 查看所有索引:GET /_cat/indices

索引一个文档(保存)
保存一个数据,保存在那个索引的那个类型下,指定用那个唯一标识
PUT请求保存文档
PUT /customer/external/1
再发送一次相同的请求就变成了更新

将唯一标识去除则报错
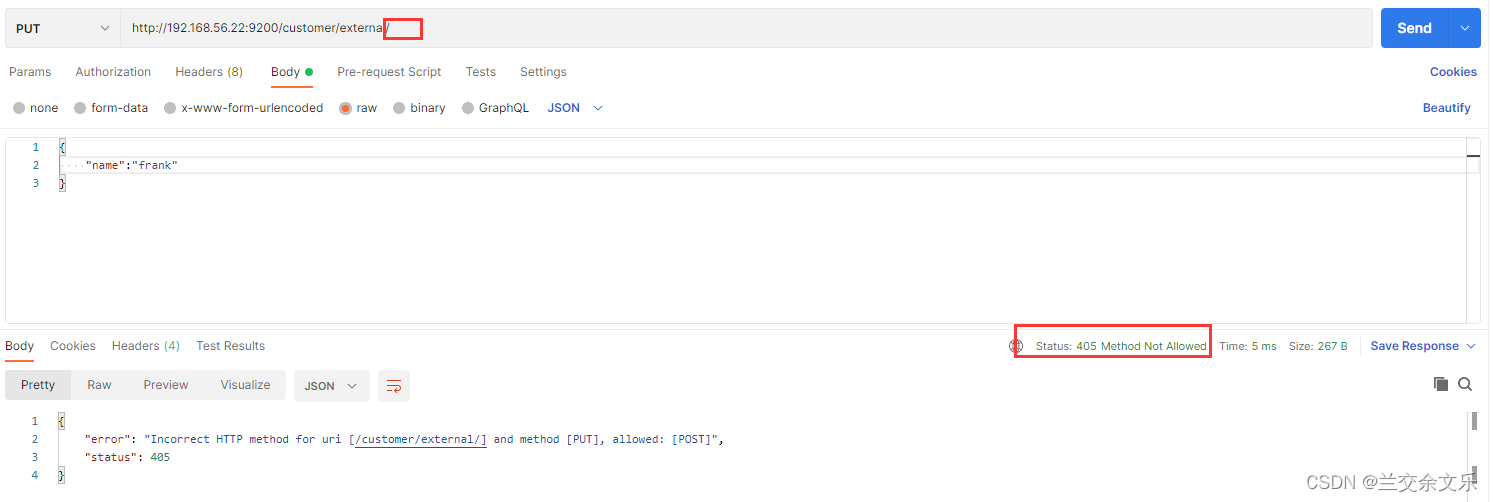
说明:PUT请求必须携带唯一标识,若标识id不存在或者无数据则为新建,否则为更新
POST请求保存文档

再次发送相同的请求 ,变成更新状态
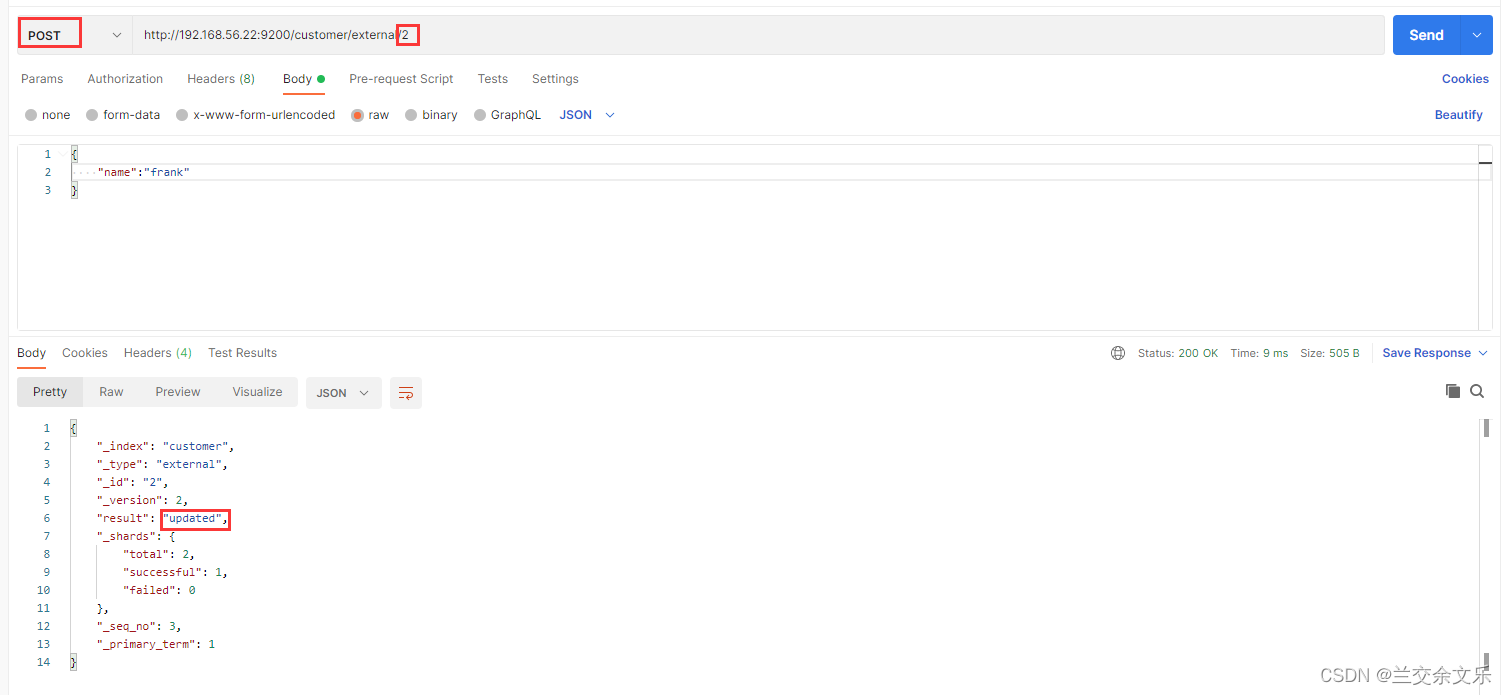
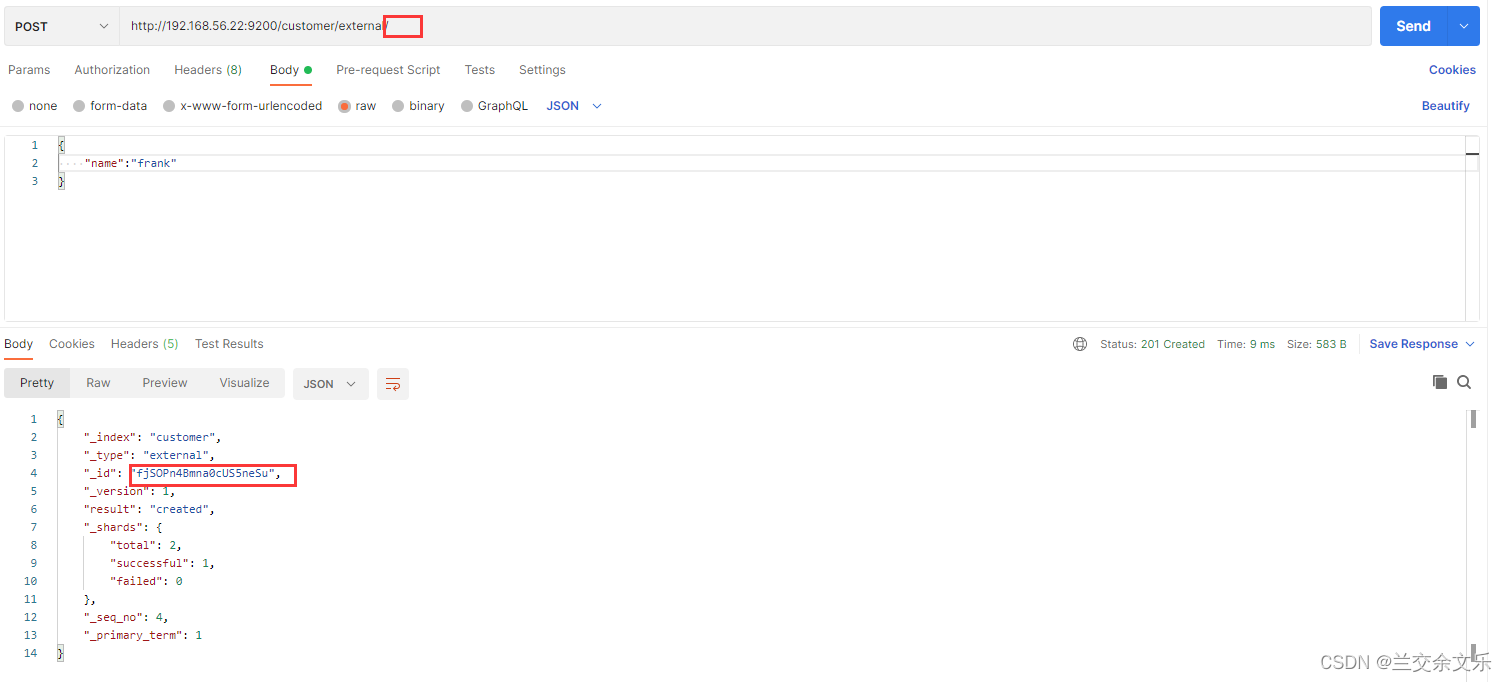
不携带唯一标识,将会自动生成一个唯一标识


模拟并发操作,一条请求想将name修改为1,一条请求想将name修改为2,判断依据就是?_seq_no=1&_primary_term=1
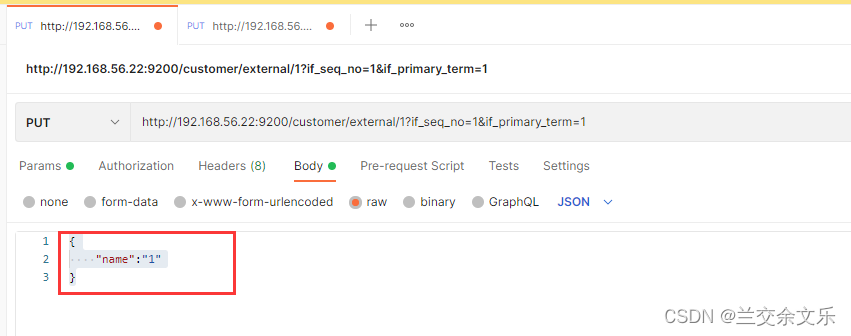
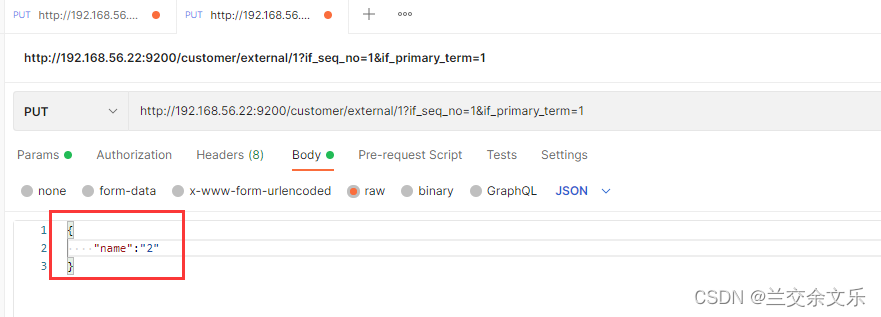
假设第一条请求先到达ES
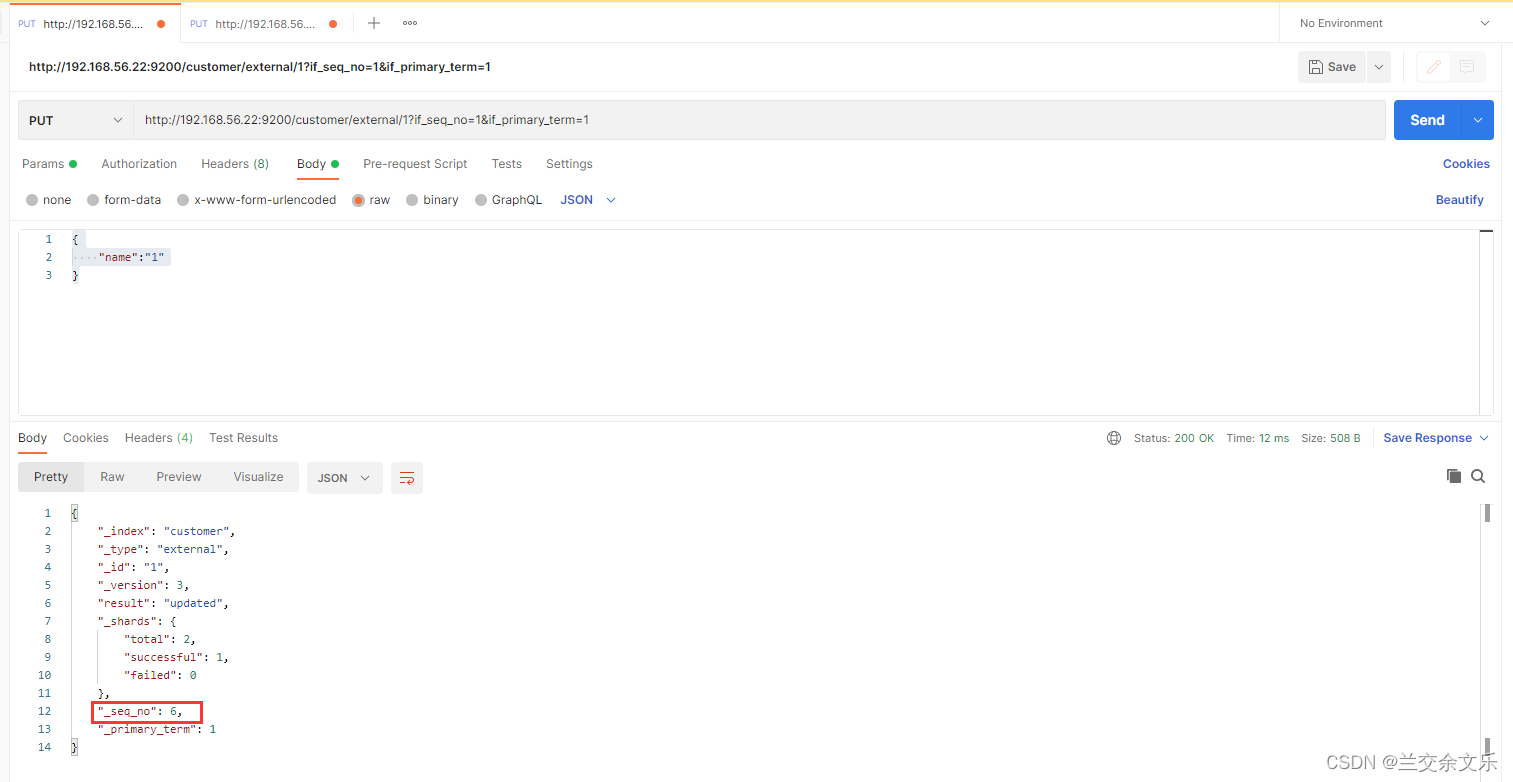
第二条请求达到ES
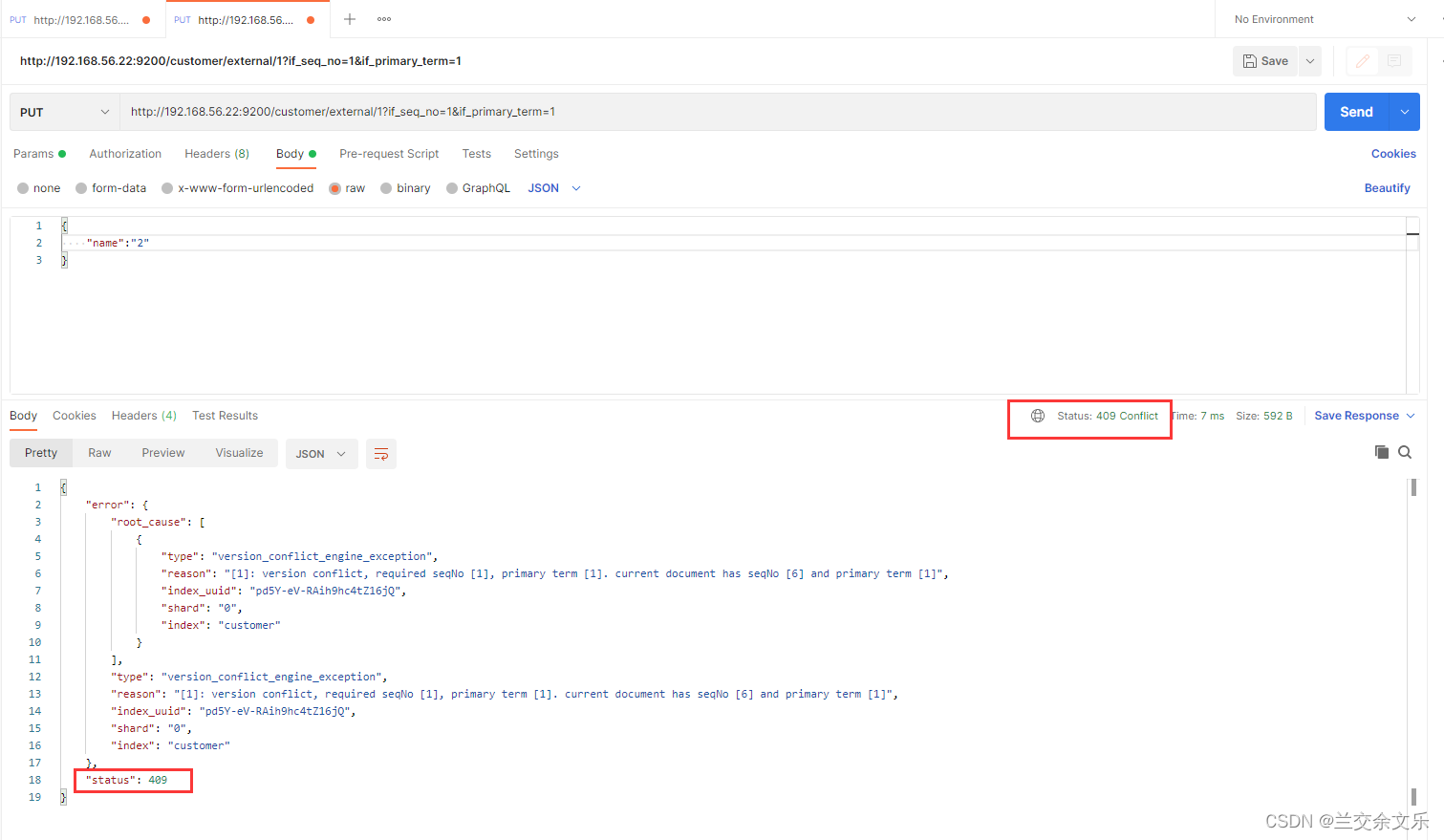
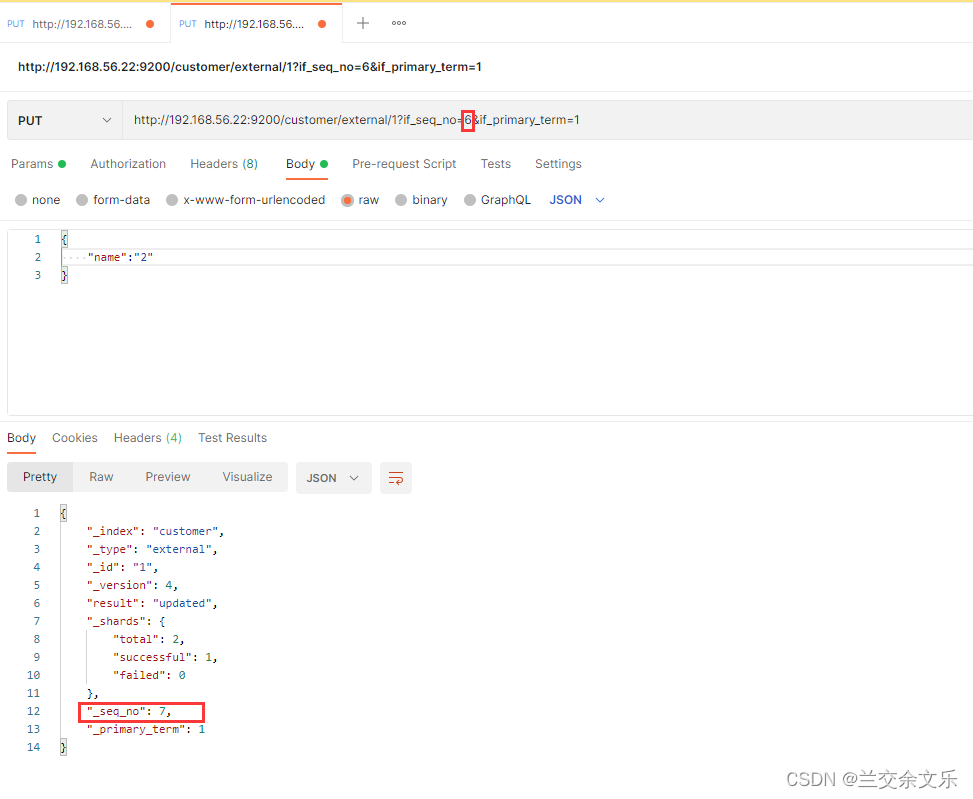
更新失败,修改_seq_no的值则更新成功
删除文档&索引
DELETE /customer/external/1
DELETE /customer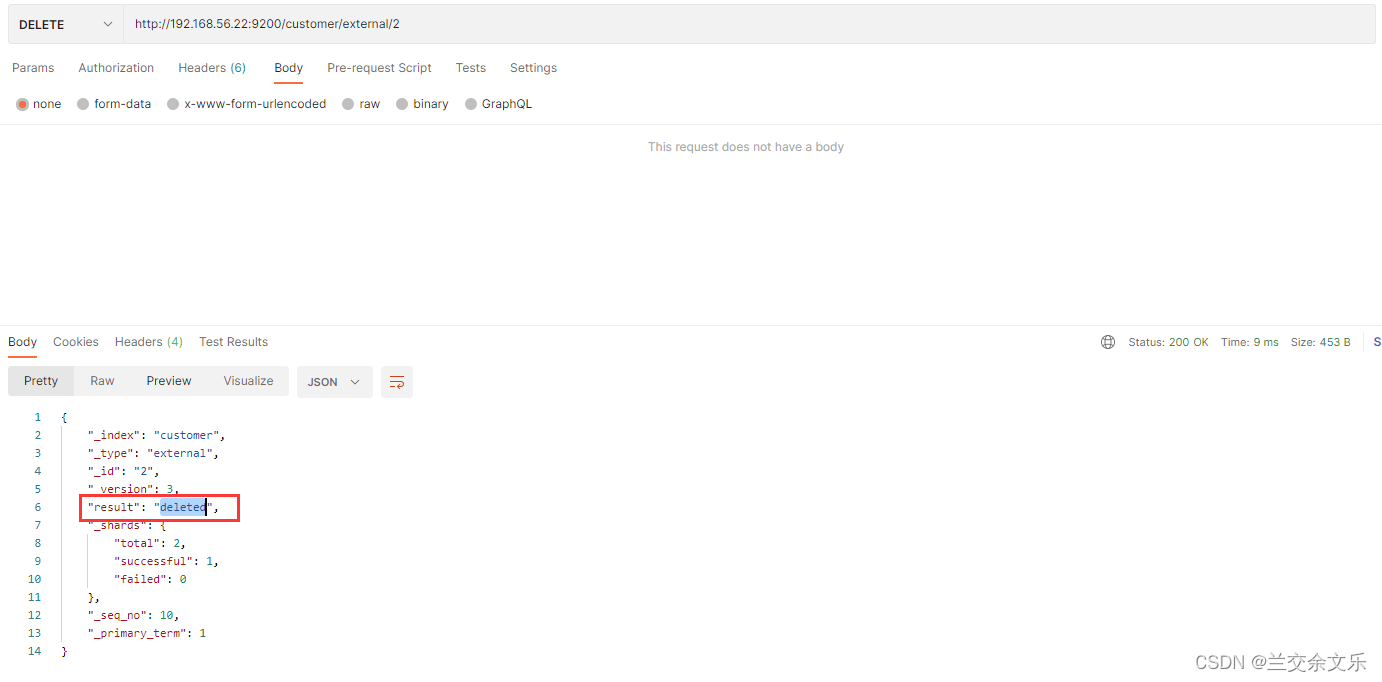
bulk批量API
语法规则

两两一组
POST customer/external/_bulk
{"index":{"_id":"1"}}
{"name":"frank"}
{"index":{"_id":"2"}}
{"name":"kobe"}
使用kibana发送请求


彼此操作之间互不影响
复杂实例测试
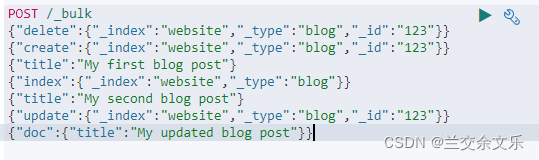
导入测试数据
数据地址:登录 - Gitee.com

学习文档地址:Quick start | Elasticsearch Guide [7.16] | Elastic
①将请求参数放在uri路径之后
GET /bank/_search?q=*&sort=account_number:ascq=*:查询所有,sort=account_number:asc即按account_number升序排列
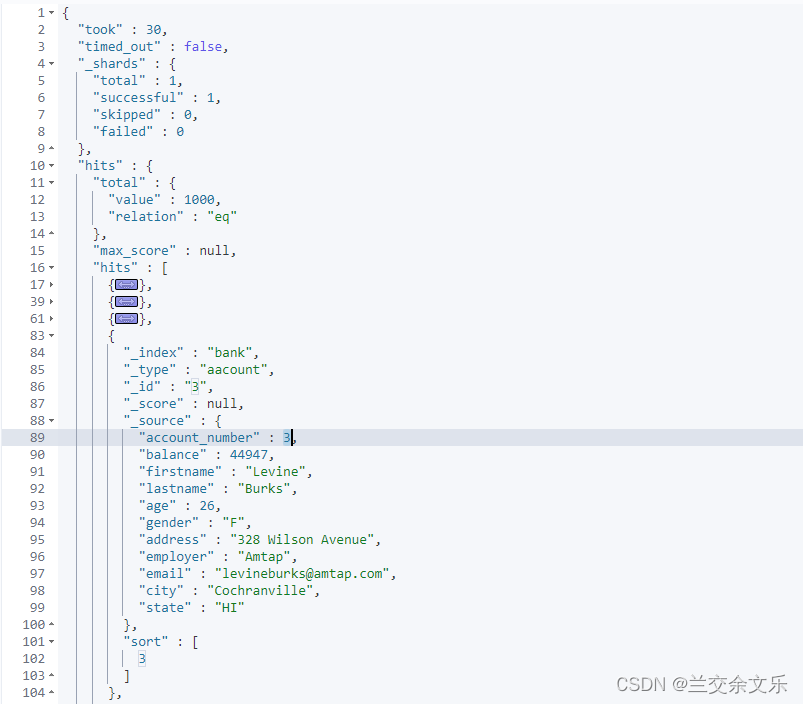
took:ES执行搜索所花费的时间
timed_out:是否超时
_shards:告诉我们多少个分片被搜索了,以及统计了成功/失败的搜素分片
hits:搜索结果
hits.total:搜索结果
hits.hits:实际搜索结果数组(默认为前10文档)
sort: 结果的排序key(没有则按score排序)
_score:相关性得分(全文检索用)
max_score:最高得分(全文检索用)
②通过请求体方式访问
GET /bank/_search
{
"query" : { "match_all" : { } },
"sort" : [ { "account_number" : "asc" } ]
} 基本语法:
{
QUERY_NAME:{
ARGUMENT:value,
ARGUMENT:value,
...
}
}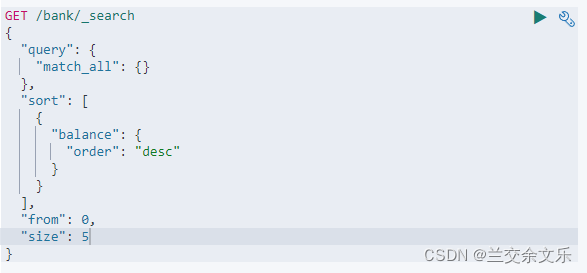
from和size 类比mysql中limit即分页查询
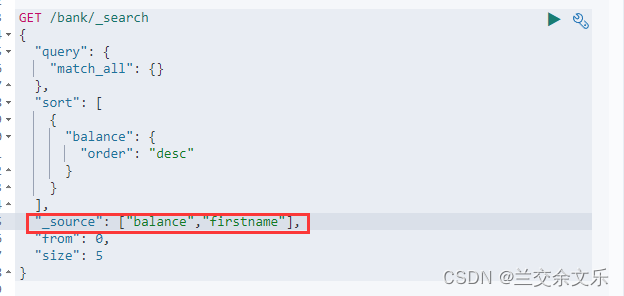

match_all:匹配全部
match:全文检索
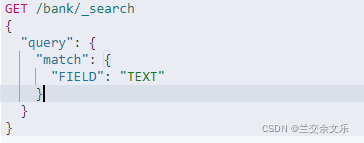
①检索字段非字符串则是精确匹配

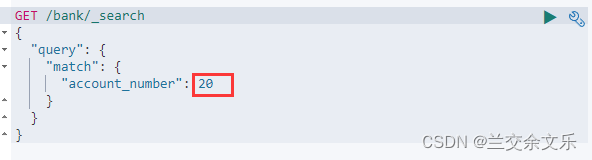
无论是字符串"20"还是数字20,检索结果都是一样的

② 匹配字段是字符串类型则是全文检索

 可以查出包含mill或者lane或者mill lane的文档,并且按照相关性得分进行一个排序
可以查出包含mill或者lane或者mill lane的文档,并且按照相关性得分进行一个排序
与match不同的是,不进行一个分词匹配,当作一个整体进行匹配

也可以使用keyword进行一个精确匹配

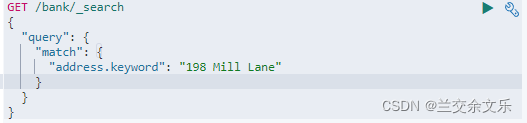

match_phrase和keyword的区别:
match_phrase:不区分大小写,包含匹配字段
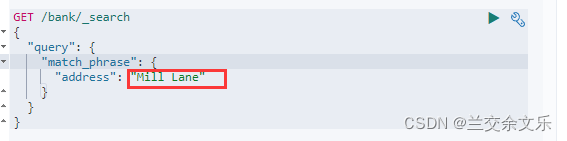

 keyword:必须精确匹配
keyword:必须精确匹配


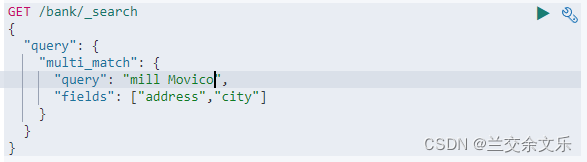
多字段匹配会进行一个分词匹配

must:一定满足
must_not:一定不满足
should:可满足不满足也行,但是满足了得分会更高
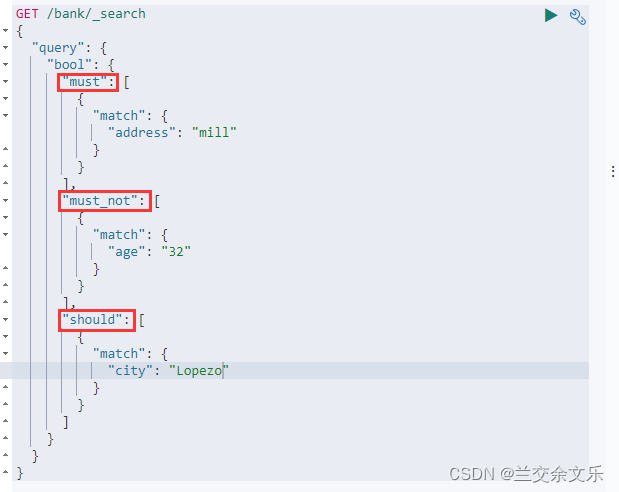
must和should会计算相关性得分,而filter并不会计算相关性得分


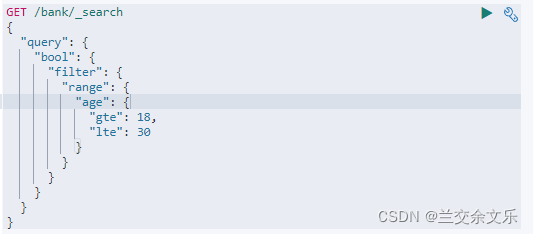
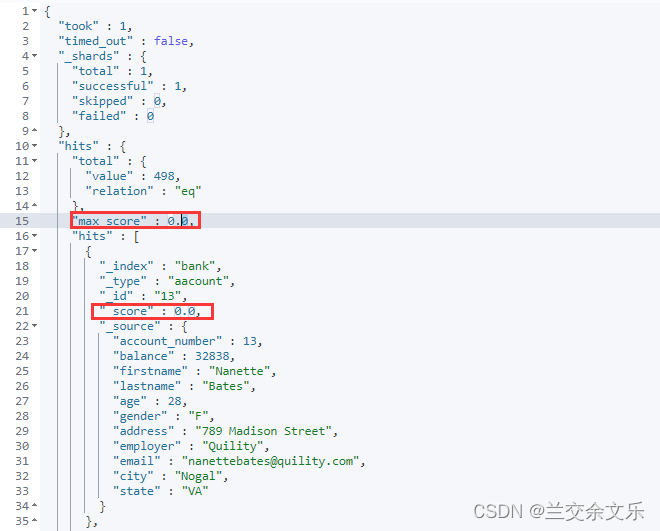
match用于全文检索字段,term用于非全文检索字段即非文本字段
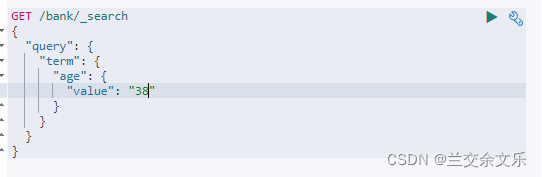
聚合分析相当于mysql中的group by和聚合函数
语法规则:
"aggregations":{
"<aggregations_name>":{
"<aggregations_type>":{
<aggregation_body>
}
[,"meta":{ [<meta_data_body>] }]?
[,"aggregations":{ [<sub_aggregation>+ }]?
}
[,"<aggregation_name_2>":{...}]*
}例题1:搜索address中包含mill的所有人的年龄分布以及平均年龄
terms:按照指定字段进行分组
avg:计算平均值


例题2:按照年龄聚合,并且请求这些年龄段人的平均工资

例题3: 查出所有年龄分布,并且这些年龄段中M的平均工资和F的平均工资以及这个年龄段的总体平均薪资
映射类比mysql中的定义列的数据类型
字段的数据类型:Field data types | Elasticsearch Guide [8.0] | Elastic
说明:ES7之后去掉了type
理由:


说明: keyword是text的一个属性,text类型会进行全文检索而keyword是精确匹配并不会进行全文检索
地址:Dynamic mapping | Elasticsearch Guide [8.0] | Elastic
地址:Explicit mapping | Elasticsearch Guide [8.0] | Elastic
模板:
PUT /my-index-000001
{
"mappings": {
"properties": {
"age": { "type": "integer" },
"email": { "type": "keyword" },
"name": { "type": "text" }
}
}
}

 说明:按照以上方式向已存在的映射中添加一个新的字段会报错
说明:按照以上方式向已存在的映射中添加一个新的字段会报错
正确的方式:
PUT /my_index/_mapping
{
"properties": {
"employee-id": {
"type": "keyword",
"index": false
}
}
}index为映射参数,控制该字段是否能被索引,默认为true
地址:index | Elasticsearch Guide [8.0] | Elastic
地址:Reindex API | Elasticsearch Guide [8.0] | Elastic
6.0以后没有type的模板:
POST _reindex
{
"source": {
"index": "my-index-000001"
},
"dest": {
"index": "my-new-index-000001"
}
}6.0以前的数据迁移的模板:
POST _reindex
{
"source": {
"index": "my-index-000001",
"type": "xxxx"
},
"dest": {
"index": "my-new-index-000001"
}
}案例:将bank的数据迁移到newbank中
①创建一个新的索引

②进行一个数据迁移

分词就是将一段话分成一个个词语
地址:Standard tokenizer | Elasticsearch Guide [8.1] | Elastic
案例:标准分词器
POST _analyze
{
"tokenizer": "standard",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}结果:以空格将这句话分成一个个的单词
注意:不能用elasticsearch-plugin install xxx.zip 进行自动安装
由于我们安装的ES是7.4.2,因此,我们安装的ik分词器版本要与ES对应

下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.4.2
安装ik分词器的步骤:
①进入ES容器内部的plugins目录,由于创建容器时进行了映射,因此,等价于进入mydata/elasticsearch/plugins目录
cd /mydata/elasticsearch/plugins或者
docker exec -it 容器id /bin/bash
②下载ik分词器的zip
使用wget命令在线下载
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.4.2/elasticsearch-analysis-ik-7.4.2.zip③解压
unzip 下载的文件
mv elasticsearch/ik④ 查看是否安装好
cd ../bin
elasticsearch plugin list :即可列出系统的分词器由于虚拟机网络或者很多命令没有设置好,后面会进行一个设置,为了方便后续的操作,这里我们安装xshell
下载地址:XShell免费版(解决官网打不开的问题)_QWQ___qwq的博客-CSDN博客_xshell不免费了吗
①要使用xshell需要进行权限认证,即开放权限认证
1.连接虚拟机:vagrant ssh
2.修改ssh配置文件: vi /etc/ssh/sshd_config
3.修改:PasswordAuthentication yes
4.重启服务:service sshd restart
②将解压好的ik压缩包传送到linux中

③修改文件权限
chmod -R 777 /ik④重启容器
docker restart elasticsearch⑤查看是否安装成功
1. docker exec -it 容器id /bin
3. elasticsearch-plugin list如果出现ik则表示安装ik分词器成功

简单测试分词器
①ik_smart
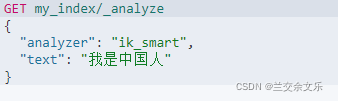

②ik_max_word


①cd /etc/sysconfig/network-scripts


② eth1即网卡1才是虚拟机的ip地址,因此,编辑ifcfg-eth1
vi ifcfg-eth1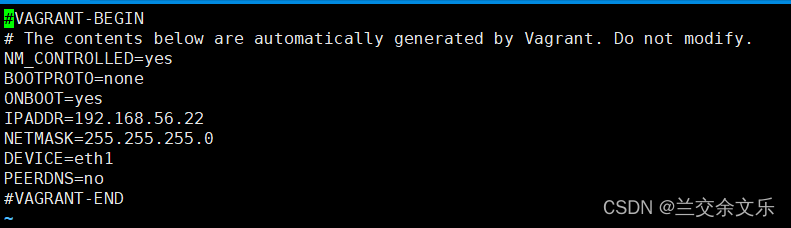
③添加网关和dns
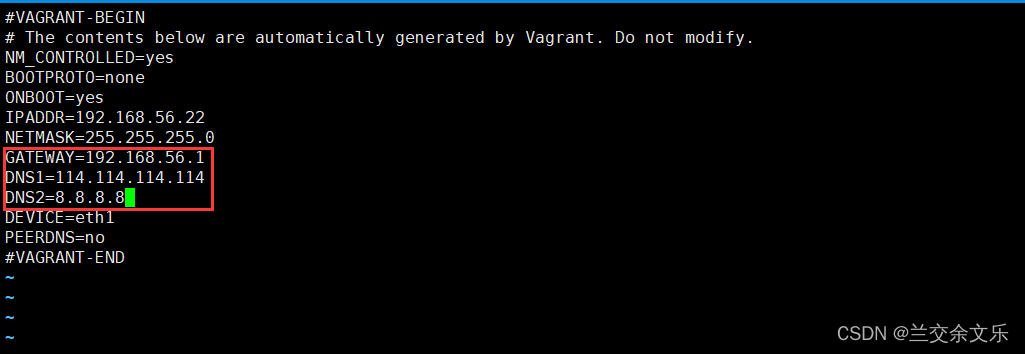
④网络服务重启
service network restart
①备份yum源
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup②使用新yum源
curl -o /etc/yum.repos.d/CentOS7-163-Base.repo http://mirrors.163.com/.help/CentOS7-Base-163.repo
或
wget -O /etc/yum.repos.d/CentOS7-Aliyun.repo http://mirrors.aliyun.com/repo/Centos-7.repo
③生成缓存
yum makecache下载wget和unzip
yum install -y wget
yum install -y unzip自定义的词库需要部署到Nginx中,因此,需要安装Nginx
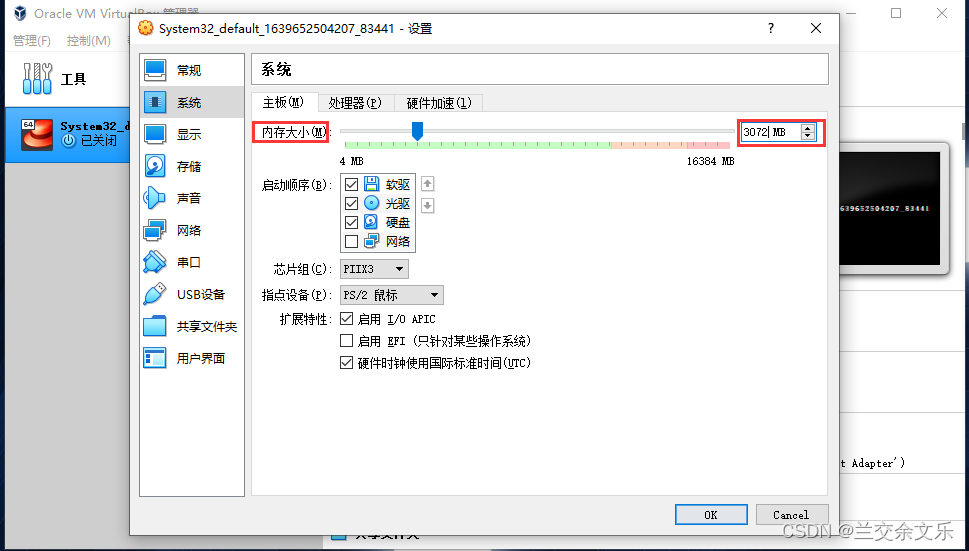
①扩大虚拟机的内存大小

② 随便启动一个Nginx实例,目的是为了复制出配置文件
docker run -p 80:80 --name nginx -d nginx:1.10③将容器内的配置文件拷贝到当前目录
1. cd /mydata
2. mkdir nginx
#nginx与.之间有空格,"."别忘了
3. docker container cp nginx:/etc/nginx .
#删除原容器
4. docker stop nginx
5. docker rm nginx
#修改文件名
6. mv nginx conf
7. mkdir nginx
8. mv conf nginx
④创建新Nginx容器
docker run -p 80:80 --name nginx \
-v /mydata/nginx/html:/usr/share/nginx/html \
-v /mydata/nginx/logs:/var/log/nginx \
-v /mydata/nginx/conf:/etc/nginx \
-d nginx:1.10
⑤开机自启动
sudo docker update nginx --restart=always出现以下页面则表示安装成功

说明:nginx部署的页面都存在html中
在html下编写index.html



①在nginx中为ES创建存放的目录并设置词库
cd /mydata/nginx/html
#创建存放ik词库的目录
mkdir es
#创建词库
vi fenci.txt
②为ik分词器设置外部词库
cd /mydata/elasticsearch/plugins/ik/config
vi IKAnalyzer.cfg.xml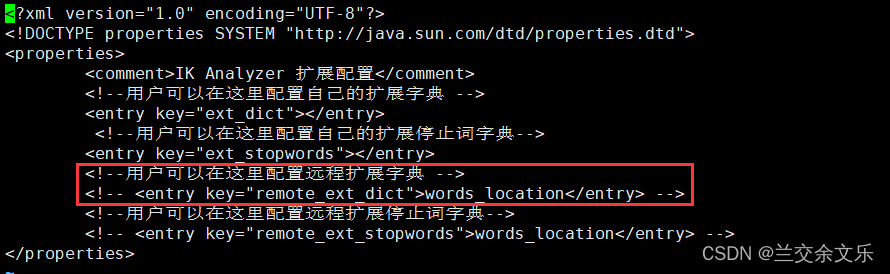

重启ES
docker restart elasticsearch测试


我试图在我的网站上实现使用Facebook登录功能,但在尝试从Facebook取回访问token时遇到障碍。这是我的代码:ifparams[:error_reason]=="user_denied"thenflash[:error]="TologinwithFacebook,youmustclick'Allow'toletthesiteaccessyourinformation"redirect_to:loginelsifparams[:code]thentoken_uri=URI.parse("https://graph.facebook.com/oauth/access_token
我想用sunspot重现以下原始solr查询q=exact_term_text:fooORterm_textv:foo*ORalternate_text:bar*但我无法通过标准的太阳黑子界面理解这是否可能以及如何实现,因为看起来:fulltext方法似乎不接受多个文本/搜索字段参数我不知道将什么参数作为第一个参数传递给fulltext,就好像我通过了"foo"或"bar"结果不匹配如果我传递一个空参数,我得到一个q=*:*范围过滤器(例如with(:term).starting_with('foo*')(顾名思义)作为过滤器查询应用,因此不参与评分。似乎可以手动编写字符串(或者可能使
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
我一直在使用postgres关注railscast的全文搜索,但我不断收到以下错误#的未定义局部变量或方法“作用域”我关注了railscast确切地。我安装了所有正确的gem。(pg_search,pg)。这是我的代码文章Controller(我在这里也使用acts_as_taggable)defindex@articles=Article.text_search(params[:query]).page(params[:page]).per_page(3)ifparams[:tag]@articles=Article.tagged_with(params[:tag])else@art
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>
我目前还在上学,正在上一门关于用C++实现数据结构的类(class)。在业余时间,我喜欢使用“高级”语言(主要是Ruby和一些c#)进行编程。既然这些高级语言为你管理内存,你会用数据结构做什么?我可以理解对队列和堆栈的需求,但是您需要在Ruby中使用二叉树吗?还是2-3-4树?为什么?谢谢。 最佳答案 Sosincethesehigherlevellanguagesmanagethememoryforyou,whatwouldyouusedatastructuresfor?使用数据结构的主要原因与垃圾收集无关。但它是以某种方式有效的
我有一个Rails应用程序,现在设置了ElasticSearch和Tiregem以在模型上进行搜索,我想知道我应该如何设置我的应用程序以对模型中的某些索引进行模糊字符串匹配。我将我的模型设置为索引标题、描述等内容,但我想对其中一些进行模糊字符串匹配,但我不确定在何处进行此操作。如果您想发表评论,我将在下面包含我的代码!谢谢!在Controller中:defsearch@resource=Resource.search(params[:q],:page=>(params[:page]||1),:per_page=>15,load:true)end在模型中:classResource'Us
我正在使用RubyonRailsv3.0.9,我想检索我设置了链接的每个网站的favicon.ico图像。也就是说,如果在我的应用程序中我设置了http://www.facebook.com/URL,我想检索Facebook的图标并在我的网页中使用\插入它。当然,我也想为所有其他网站这样做。如何以“自动”方式从网站检索favicon.ico图标(“自动”是指在网站中搜索图标并获取它的链接-我认为不是,因为并非所有网站都有一个名为“favicon.ico”的图标。我想以“自动”方式识别它)?P.S.:我想做的是像Facebook在您的Facebook页面中添加链接\URL时所做的那样:它
我想从C函数返回多个值,恕我直言,散列是一个不错的选择。我首先使用rb_intern('A_KEY')创建key,但扩展崩溃了。现在,我正在使用rb_str_new2,但我更喜欢符号。如何创建一个新符号,并在不引用类或方法的情况下使用它? 最佳答案 您需要使用ID2SYM宏将从rb_intern获得的标识符转换为ruby符号。尝试改变rb_intern('A_KEY')到ID2SYM(rb_intern('A_KEY')) 关于c-我如何在Ruby的C扩展API上检索'standal
美团外卖搜索工程团队在Elasticsearch的优化实践中,基于Location-BasedService(LBS)业务场景对Elasticsearch的查询性能进行优化。该优化基于Run-LengthEncoding(RLE)设计了一款高效的倒排索引结构,使检索耗时(TP99)降低了84%。本文从问题分析、技术选型、优化方案等方面进行阐述,并给出最终灰度验证的结论。1.前言最近十年,Elasticsearch已经成为了最受欢迎的开源检索引擎,其作为离线数仓、近线检索、B端检索的经典基建,已沉淀了大量的实践案例及优化总结。然而在高并发、高可用、大数据量的C端场景,目前可参考的资料并不多。因此
