0. 准备工作
在开始后续功能演示之前,我们需要先安装Chrome浏览器并配置好ChromeDriver,当然也需要安装selenium库!
pip install selenium
其实,有两种方式安装浏览器驱动:一种是常见的手动安装,另一种则是利用第三方库自动安装。
以下前提:大家都已经安装好了Chrome浏览器哈
手动安装
先查看本地Chrome浏览器版本:(两种方式均可)
在浏览器的地址栏键入Chrome://version,即可查看浏览器版本号
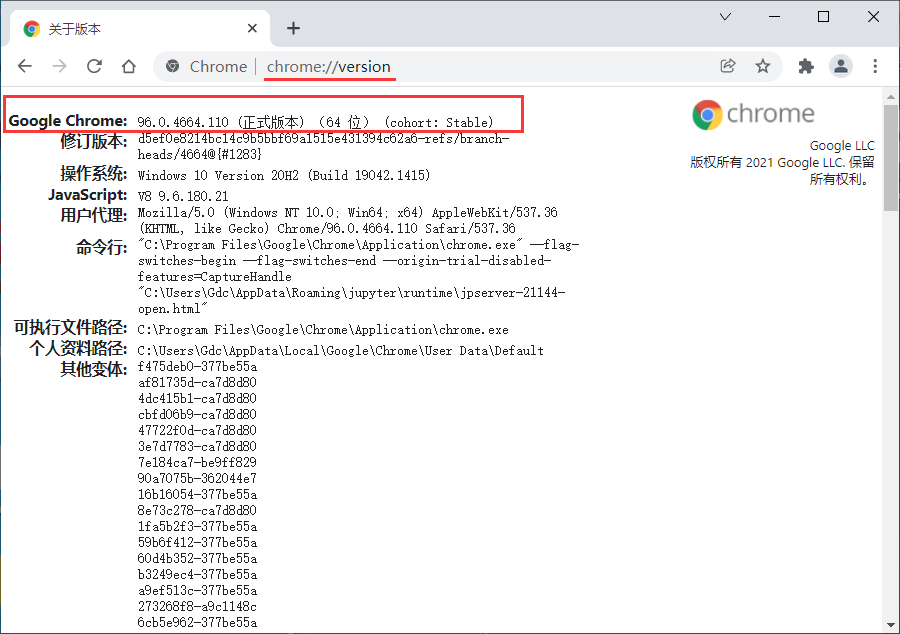
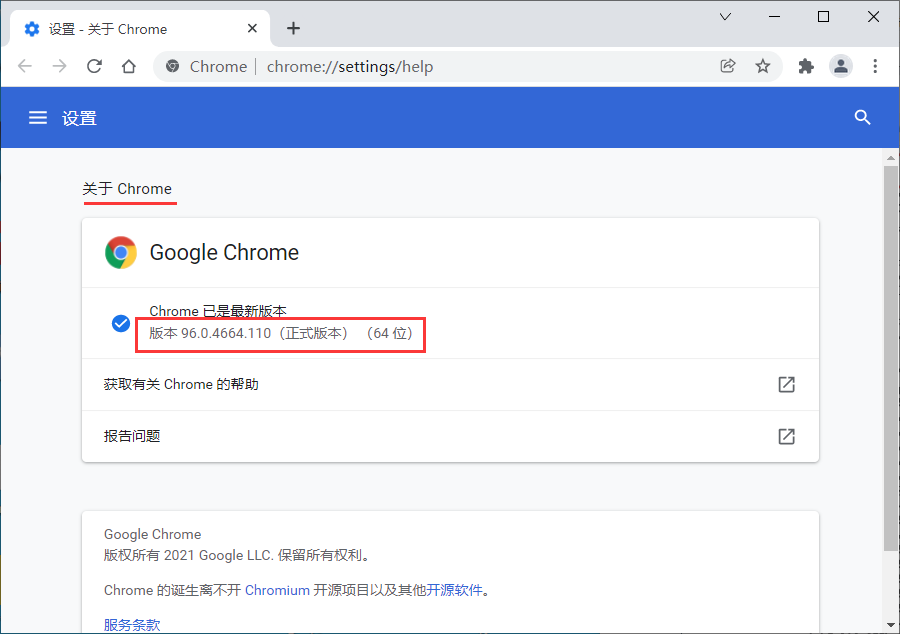
或者点击Chrome菜单 帮助→关于Google Chrome,查看浏览器版本号
再选择对应版本号的驱动版本
下载地址:https://chromedriver.storage.googleapis.com/index.html
最后进行环境变量配置,也就是将对应的ChromeDriver的可执行文件chromedriver.exe文件拖到Python的Scripts目录下。
注:当然也可以不这样做,但是在调用的时候指定chromedriver.exe绝对路径亦可。
自动安装
自动安装需要用到第三方库webdriver_manager,先安装这个库,然后调用对应的方法即可。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from webdriver_manager.chrome import ChromeDriverManager
browser = webdriver.Chrome(ChromeDriverManager().install())
browser.get('http://www.baidu.com')
search = browser.find_element_by_id('kw')
search.send_keys('python')
search.send_keys(Keys.ENTER)
# 关闭浏览器
browser.close()
在上述代码中,ChromeDriverManager().install()方法就是自动安装驱动的操作,它会自动获取当前浏览器的版本并去下载对应的驱动到本地。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST chromedriver version for 96.0.4664 google-chrome
There is no [win32] chromedriver for browser in cache
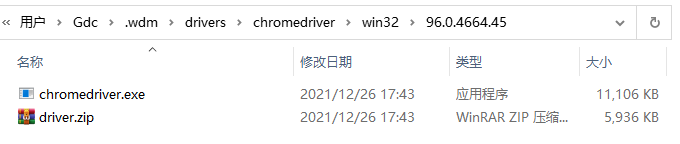
Trying to download new driver from https://chromedriver.storage.googleapis.com/96.0.4664.45/chromedriver_win32.zip
Driver has been saved in cache [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45]
如果本地已经有该浏览器渠道,则会提示其已存在。
====== WebDriver manager ======
Current google-chrome version is 96.0.4664
Get LATEST driver version for 96.0.4664
Driver [C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe] found in cache
搞定以上准备工作,我们就可以开始本文正式内容的学习啦~
1. 基本用法
这节我们就从初始化浏览器对象、访问页面、设置浏览器大小、刷新页面和前进后退等基础操作。
在准备工作部分我们提到需要将浏览器渠道添加到环境变量或者指定绝对路径,前者可以直接初始化后者则需要进行指定。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 指定绝对路径的方式
path = r'C:\Users\Gdc\.wdm\drivers\chromedriver\win32\96.0.4664.45\chromedriver.exe'
browser = webdriver.Chrome(path)
# 关闭浏览器
browser.close()
初始化浏览器对象
可以看到以上是有界面的浏览器,我们还可以初始化浏览器为无界面的浏览器。
from selenium import webdriver
# 无界面的浏览器
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome(options=option)
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 截图预览
browser.get_screenshot_as_file('截图.png')
# 关闭浏览器
browser.close()
截图
完成浏览器对象的初始化后并将其赋值给了browser对象,接下来我们就可以调用browser来执行各种方法模拟浏览器的操作了。
进行页面访问使用的是get方法,传入参数为待访问页面的URL地址即可。
from selenium import webdriver
# 初始化浏览器为chrome浏览器
browser = webdriver.Chrome()
# 访问百度首页
browser.get(r'https://www.baidu.com/')
# 关闭浏览器
browser.close()
set_window_size()方法可以用来设置浏览器大小(就是分辨率),而maximize_window则是设置浏览器为全屏!
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器大小:全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 设置分辨率 500*500
browser.set_window_size(500,500)
time.sleep(2)
# 设置分辨率 1000*800
browser.set_window_size(1000,800)
time.sleep(2)
# 关闭浏览器
browser.close()
这里就不截图了,大家自行演示看效果哈~
刷新页面是我们在浏览器操作时很常用的操作,这里refresh()方法可以用来进行浏览器页面刷新。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
try:
# 刷新页面
browser.refresh()
print('刷新页面')
except Exception as e:
print('刷新失败')
# 关闭浏览器
browser.close()
大家也是自行演示看效果哈,同F5快捷键。
前进后退也是我们在使用浏览器时非常常见的操作,这里forward()方法可以用来实现前进,back()可以用来实现后退。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 设置浏览器全屏
browser.maximize_window()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 打开淘宝页面
browser.get(r'https://www.taobao.com')
time.sleep(2)
# 后退到百度页面
browser.back()
time.sleep(2)
# 前进的淘宝页面
browser.forward()
time.sleep(2)
# 关闭浏览器
browser.close()
2. 获取页面基础属性
当我们用selenium打开某个页面,有一些基础属性如网页标题、网址、浏览器名称、页面源码等信息。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
# 网页标题
print(browser.title)
# 当前网址
print(browser.current_url)
# 浏览器名称
print(browser.name)
# 网页源码
print(browser.page_source)
输出如下:
百度一下,你就知道
https://www.baidu.com/
chrome
<html><head><script async="" src="https://passport.baidu.com/passApi/js/wrapper.js?cdnversion=1640515789507&_=1640515789298"></script><meta http-equiv="Content-Type" content="text/html;charset=utf-8"><meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"><meta content="always" name="referrer"><meta name="theme-color"..."
需要注意的是,这里的页面源码我们就可以用正则表达式、Bs4、xpath以及pyquery等工具进行解析提取想要的信息了。
3. 定位页面元素
我们在实际使用浏览器的时候,很重要的操作有输入文本、点击确定等等。对此,Selenium提供了一系列的方法来方便我们实现以上操作。常说的8种定位页面元素的操作方式,我们一一演示一下!
我们以百度首页的搜索框节点为例,搜索python
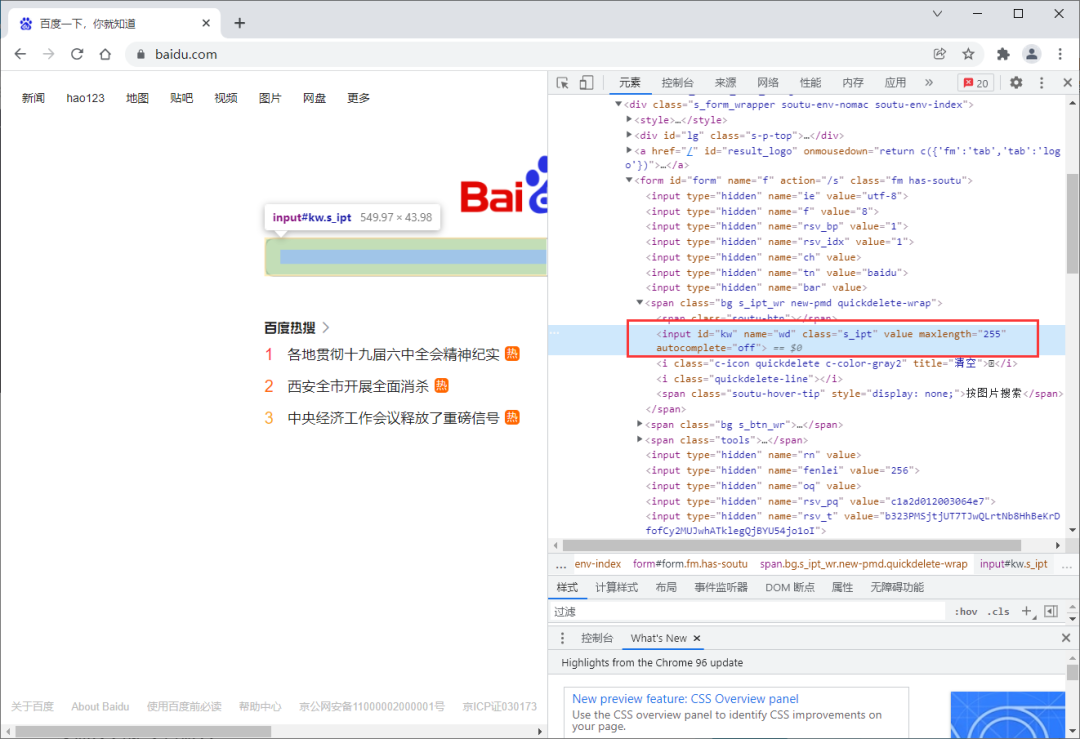
搜索框
搜索框的html结构:
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
find_element_by_id()根据id属性获取,这里id属性是 kw
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 在搜索框输入 python
browser.find_element_by_id('kw').send_keys('python')
time.sleep(2)
# 关闭浏览器
browser.close()
find_element_by_name()根据name属性获取,这里name属性是 wd
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 在搜索框输入 python
browser.find_element_by_name('wd').send_keys('python')
time.sleep(2)
# 关闭浏览器
browser.close()
find_element_by_class_name()根据class属性获取,这里class属性是s_ipt
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 在搜索框输入 python
browser.find_element_by_class_name('s_ipt').send_keys('python')
time.sleep(2)
# 关闭浏览器
browser.close()
我们知道HTML是通过tag来定义功能的,比如input是输入,table是表格等等。每个元素其实就是一个tag,一个tag往往用来定义一类功能,我们查看百度首页的html代码,可以看到有很多同类tag,所以其实很难通过tag去区分不同的元素。
find_element_by_tag_name()
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 在搜索框输入 python
browser.find_element_by_tag_name('input').send_keys('python')
time.sleep(2)
# 关闭浏览器
browser.close()
由于存在多个input,以上代码会报错。
这种方法顾名思义就是用来定位文本链接的,比如百度首页上方的分类模块链接。
find_element_by_link_text()
以新闻为例
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 点击新闻 链接
browser.find_element_by_link_text('新闻').click()
time.sleep(2)
# 关闭浏览器全部页面
browser.quit()
有时候一个超链接的文本很长,我们如果全部输入,既麻烦,又显得代码很不美观,这时候我们就可以只截取一部分字符串,用这种方法模糊匹配了。
find_element_by_partial_link_text()
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 点击新闻 链接
browser.find_element_by_partial_link_text('闻').click()
time.sleep(2)
# 关闭浏览器全部页面
browser.quit()
前面介绍的几种定位方法都是在理想状态下,有一定使用范围的,那就是:在当前页面中,每个元素都有一个唯一的id或name或class或超链接文本的属性,那么我们就可以通过这个唯一的属性值来定位他们。
但是在实际工作中并非有这么美好,那么这个时候我们就只能通过xpath或者css来定位了。
find_element_by_xpath()
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 在搜索框输入 python
browser.find_element_by_xpath("//*[@id='kw']").send_keys('python')
time.sleep(2)
# 关闭浏览器
browser.close()
这种方法相对xpath要简洁些,定位速度也要快些。
find_element_by_css_selector()
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 在搜索框输入 python
browser.find_element_by_css_selector('#kw').send_keys('python')
time.sleep(2)
# 关闭浏览器
browser.close()
除了上述的8种定位方法,Selenium还提供了一个通用的方法find_element(),这个方法有两个参数:定位方式和定位值。
# 使用前先导入By类
from selenium.webdriver.common.by import By
以上的操作可以等同于以下:
browser.find_element(By.ID,'kw')
browser.find_element(By.NAME,'wd')
browser.find_element(By.CLASS_NAME,'s_ipt')
browser.find_element(By.TAG_NAME,'input')
browser.find_element(By.LINK_TEXT,'新闻')
browser.find_element(By.PARTIAL_LINK_TEXT,'闻')
browser.find_element(By.XPATH,'//*[@id="kw"]')
browser.find_element(By.CSS_SELECTOR,'#kw')
如果定位的目标元素在网页中不止一个,那么则需要用到find_elements,得到的结果会是列表形式。简单来说,就是element后面多了复数标识s,其他操作一致。
4. 获取页面元素属性
既然我们有很多方式来定位页面的元素,那么接下来就可以考虑获取以下元素的属性了,尤其是用Selenium进行网络爬虫的时候。
以百度首页的logo为例,获取logo相关属性
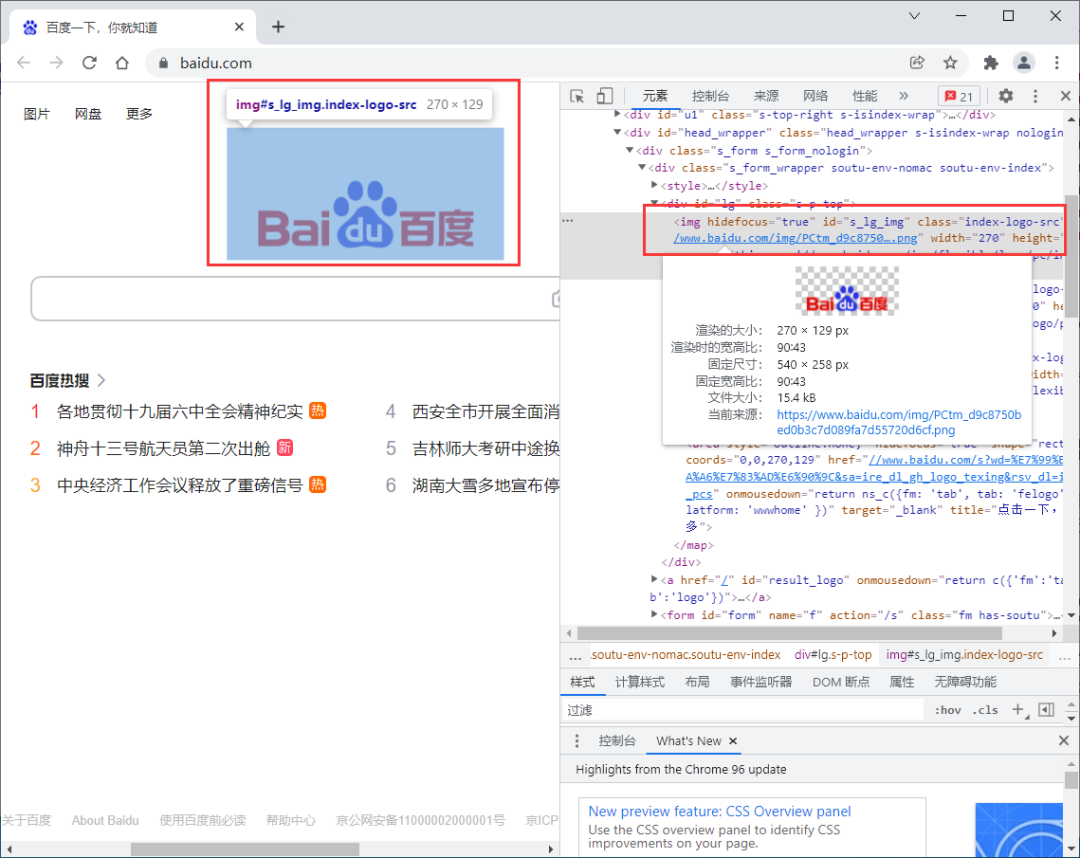
<img hidefocus="true" id="s_lg_img" class="index-logo-src" src="//www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png" width="270" height="129" onerror="this.src='//www.baidu.com/img/flexible/logo/pc/index.png';this.onerror=null;" usemap="#mp">
获取logo的图片地址
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
logo = browser.find_element_by_class_name('index-logo-src')
print(logo)
print(logo.get_attribute('src'))
# 关闭浏览器
browser.close()
输出:
<selenium.webdriver.remote.webelement.WebElement (session="e95b18c43a330745af019e0041f0a8a4", element="7dad5fc0-610b-45b6-b543-9e725ee6cc5d")>
https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png
以热榜为例,获取热榜文本和链接
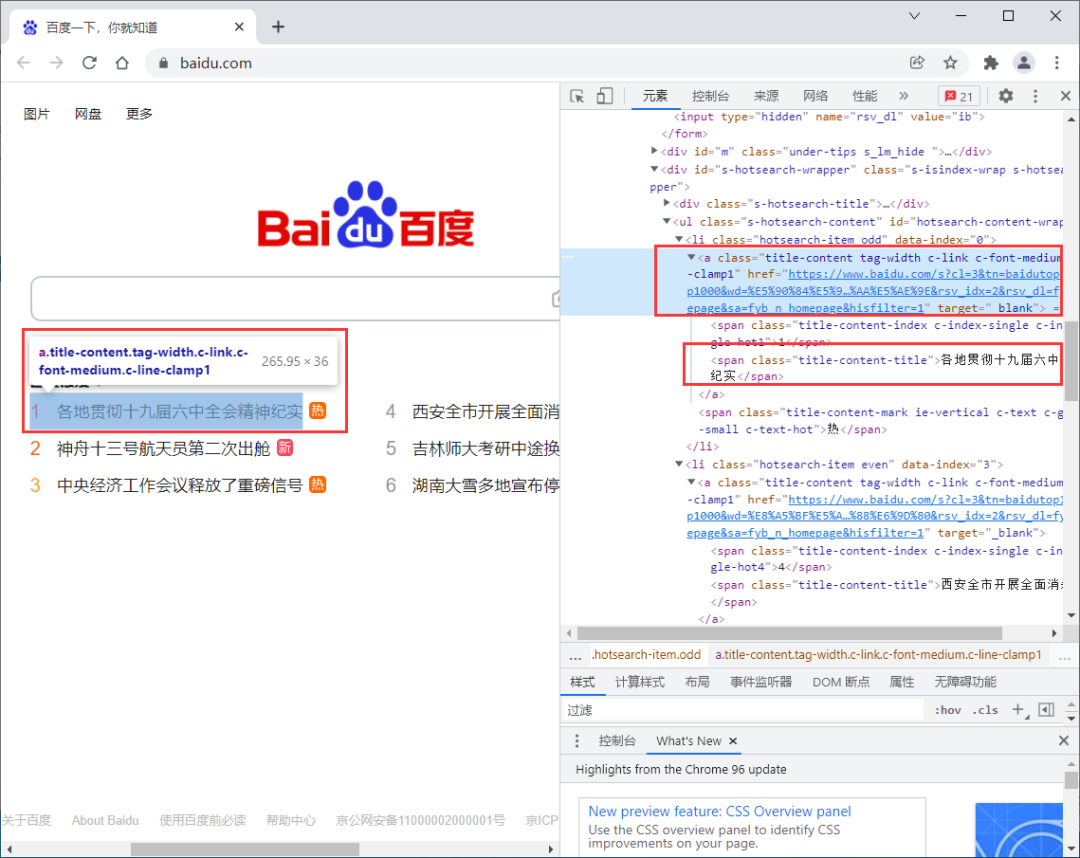
<a class="title-content tag-width c-link c-font-medium c-line-clamp1" href="https://www.baidu.com/s?cl=3&tn=baidutop10&fr=top1000&wd=%E5%90%84%E5%9C%B0%E8%B4%AF%E5%BD%BB%E5%8D%81%E4%B9%9D%E5%B1%8A%E5%85%AD%E4%B8%AD%E5%85%A8%E4%BC%9A%E7%B2%BE%E7%A5%9E%E7%BA%AA%E5%AE%9E&rsv_idx=2&rsv_dl=fyb_n_homepage&sa=fyb_n_homepage&hisfilter=1" target="_blank"><span class="title-content-index c-index-single c-index-single-hot1">1</span><span class="title-content-title">各地贯彻十九届六中全会精神纪实</span></a>
获取热榜的文本,用的是text属性,直接调用即可
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
logo = browser.find_element_by_css_selector('#hotsearch-content-wrapper > li:nth-child(1) > a')
print(logo.text)
print(logo.get_attribute('href'))
# 关闭浏览器
browser.close()
输出:
1各地贯彻十九届六中全会精神纪实
https://www.baidu.com/s?cl=3&tn=baidutop10&fr=top1000&wd=%E5%90%84%E5%9C%B0%E8%B4%AF%E5%BD%BB%E5%8D%81%E4%B9%9D%E5%B1%8A%E5%85%AD%E4%B8%AD%E5%85%A8%E4%BC%9A%E7%B2%BE%E7%A5%9E%E7%BA%AA%E5%AE%9E&rsv_idx=2&rsv_dl=fyb_n_homepage&sa=fyb_n_homepage&hisfilter=1
除了属性和文本值外,还有id、位置、标签名和大小等属性。
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
logo = browser.find_element_by_class_name('index-logo-src')
print(logo.id)
print(logo.location)
print(logo.tag_name)
print(logo.size)
# 关闭浏览器
browser.close()
输出:
6af39c9b-70e8-4033-8a74-7201ae09d540
{'x': 490, 'y': 46}
img
{'height': 129, 'width': 270}
5. 页面交互操作
页面交互就是在浏览器的各种操作,比如上面演示过的输入文本、点击链接等等,还有像清除文本、回车确认、单选框与多选框选中等。
其实,在之前的小节中我们有用过此操作。
send_keys()
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 定位搜索框
input = browser.find_element_by_class_name('s_ipt')
# 输入python
input.send_keys('python')
time.sleep(2)
# 关闭浏览器
browser.close()
同样,我们也用过这个点击操作。
click()
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 选中新闻按钮
click = browser.find_element_by_link_text('新闻')
# 点击之
click.click()
time.sleep(2)
# 关闭浏览器全部页面
browser.quit()
既然有输入,这里也就有清除文本啦。
clear()
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 定位搜索框
input = browser.find_element_by_class_name('s_ipt')
# 输入python
input.send_keys('python')
time.sleep(2)
# 清除python
input.clear()
time.sleep(2)
# 关闭浏览器
browser.close()
比如,在搜索框输入文本python,然后回车就出查询操作结果的情况。
submit()
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 定位搜索框
input = browser.find_element_by_class_name('s_ipt')
# 输入python
input.send_keys('python')
time.sleep(2)
# 回车查询
input.submit()
time.sleep(5)
# 关闭浏览器
browser.close()
单选比较好操作,先定位需要单选的某个元素,然后点击一下即可。
多选好像也比较容易,依次定位需要选择的元素,点击即可。
下拉框的操作相对复杂一些,需要用到Select模块。
先导入该类
from selenium.webdriver.support.select import Select
在select模块中有以下定位方法
'''1、三种选择某一选项项的方法''' select_by_index() # 通过索引定位;注意:index索引是从“0”开始。 select_by_value() # 通过value值定位,value标签的属性值。 select_by_visible_text() # 通过文本值定位,即显示在下拉框的值。 '''2、三种返回options信息的方法''' options # 返回select元素所有的options all_selected_options # 返回select元素中所有已选中的选项 first_selected_options # 返回select元素中选中的第一个选项 '''3、四种取消选中项的方法''' deselect_all # 取消全部的已选择项 deselect_by_index # 取消已选中的索引项 deselect_by_value # 取消已选中的value值 deselect_by_visible_text # 取消已选中的文本值
我们来进行演示一波,由于暂时没找到合适的网页,我这边写了一个简单的网页本地测试(文件存为 帅哥.html)
<html>
<body>
<form>
<select name="帅哥">
<option value="才哥">才哥</option>
<option value="小明" selected="">小明</option>
<option value="小华">小华</option>
<option value="草儿">小草</option>
</select>
</form>
</body>
</html>
然后,再演示下拉框的不同选择的方式
from selenium import webdriver
from selenium.webdriver.support.select import Select
import time
url = 'file:///C:/Users/Gdc/Desktop/帅哥.html'
browser = webdriver.Chrome()
browser.get(url)
time.sleep(2)
# 根据索引选择
Select(browser.find_element_by_name("帅哥")).select_by_index("2")
time.sleep(2)
# 根据value值选择
Select(browser.find_element_by_name("帅哥")).select_by_value("草儿")
time.sleep(2)
# 根据文本值选择
Select(browser.find_element_by_name("帅哥")).select_by_visible_text("才哥")
time.sleep(2)
# 关闭浏览器
browser.close()
下拉框
6. 多窗口切换
比如同一个页面的不同子页面的节点元素获取操作,不同选项卡之间的切换以及不同浏览器窗口之间的切换操作等等。
Selenium打开一个页面之后,默认是在父页面进行操作,此时如果这个页面还有子页面,想要获取子页面的节点元素信息则需要切换到子页面进行擦走,这时候switch_to.frame()就来了。如果想回到父页面,用switch_to.parent_frame()即可。
我们在访问网页的时候会打开很多个页面,在Selenium中提供了一些方法方便我们对这些页面进行操作。
current_window_handle:获取当前窗口的句柄。
window_handles:返回当前浏览器的所有窗口的句柄。
switch_to_window():用于切换到对应的窗口。
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 打开百度
browser.get('http://www.baidu.com')
# 新建一个选项卡
browser.execute_script('window.open()')
print(browser.window_handles)
# 跳转到第二个选项卡并打开知乎
browser.switch_to.window(browser.window_handles[1])
browser.get('http://www.zhihu.com')
# 回到第一个选项卡并打开淘宝(原来的百度页面改为了淘宝)
time.sleep(2)
browser.switch_to.window(browser.window_handles[0])
browser.get('http://www.taobao.com')
7. 模拟鼠标操作
既然是模拟浏览器操作,自然也就需要能模拟鼠标的一些操作了,这里需要导入ActionChains 类。
from selenium.webdriver.common.action_chains import ActionChains
这个其实就是页面交互操作中的点击click()操作。
context_click()
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 定位到要右击的元素,这里选的新闻链接
right_click = browser.find_element_by_link_text('新闻')
# 执行鼠标右键操作
ActionChains(browser).context_click(right_click).perform()
time.sleep(2)
# 关闭浏览器
browser.close()
在上述操作中
ActionChains(browser):调用ActionChains()类,并将浏览器驱动browser作为参数传入
context_click(right_click):模拟鼠标双击,需要传入指定元素定位作为参数
perform():执行ActionChains()中储存的所有操作,可以看做是执行之前一系列的操作
double_click()
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get(r'https://www.baidu.com')
time.sleep(2)
# 定位到要双击的元素
double_click = browser.find_element_by_css_selector('#bottom_layer > div > p:nth-child(8) > span')
# 双击
ActionChains(browser).double_click(double_click).perform()
time.sleep(15)
# 关闭浏览器
browser.close()
drag_and_drop(source,target)拖拽操作嘛,开始位置和结束位置需要被指定,这个常用于滑块类验证码的操作之类。
我们以菜鸟教程的一个案例来进行演示
https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
time.sleep(2)
browser.switch_to.frame('iframeResult')
# 开始位置
source = browser.find_element_by_css_selector("#draggable")
# 结束位置
target = browser.find_element_by_css_selector("#droppable")
# 执行元素的拖放操作
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()
# 拖拽
time.sleep(15)
# 关闭浏览器
browser.close()
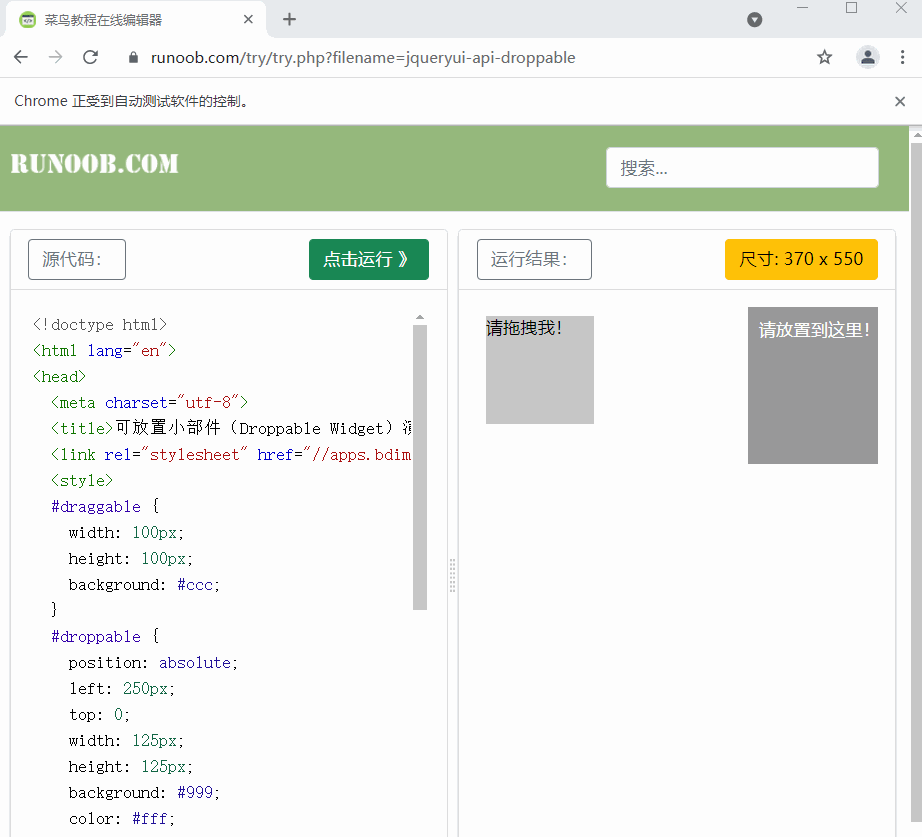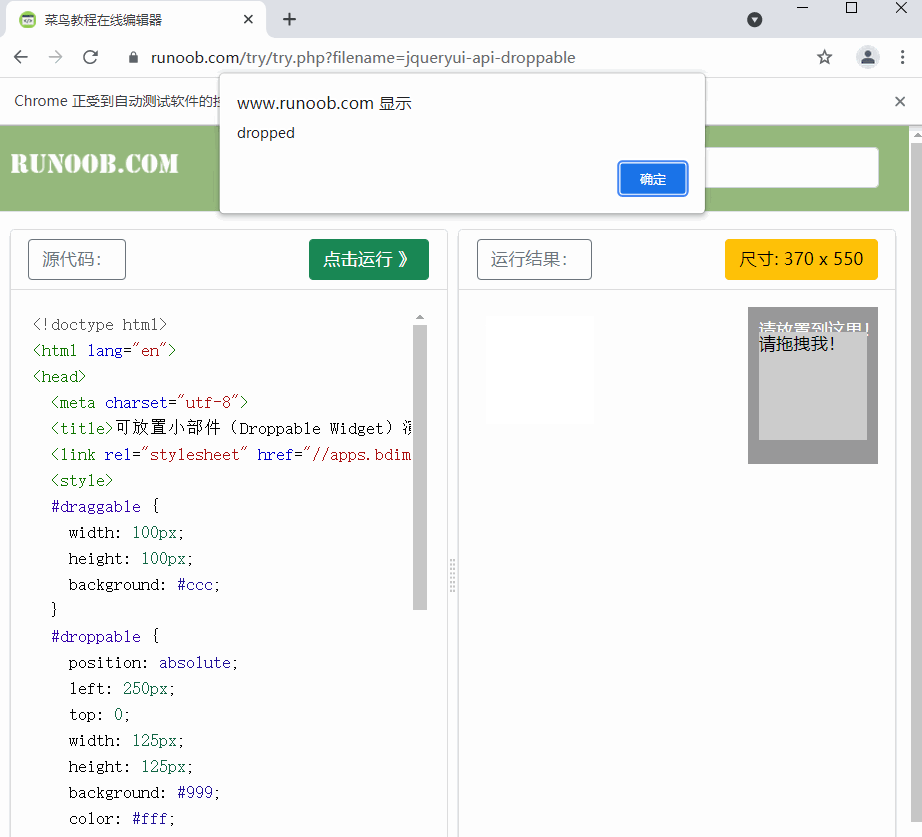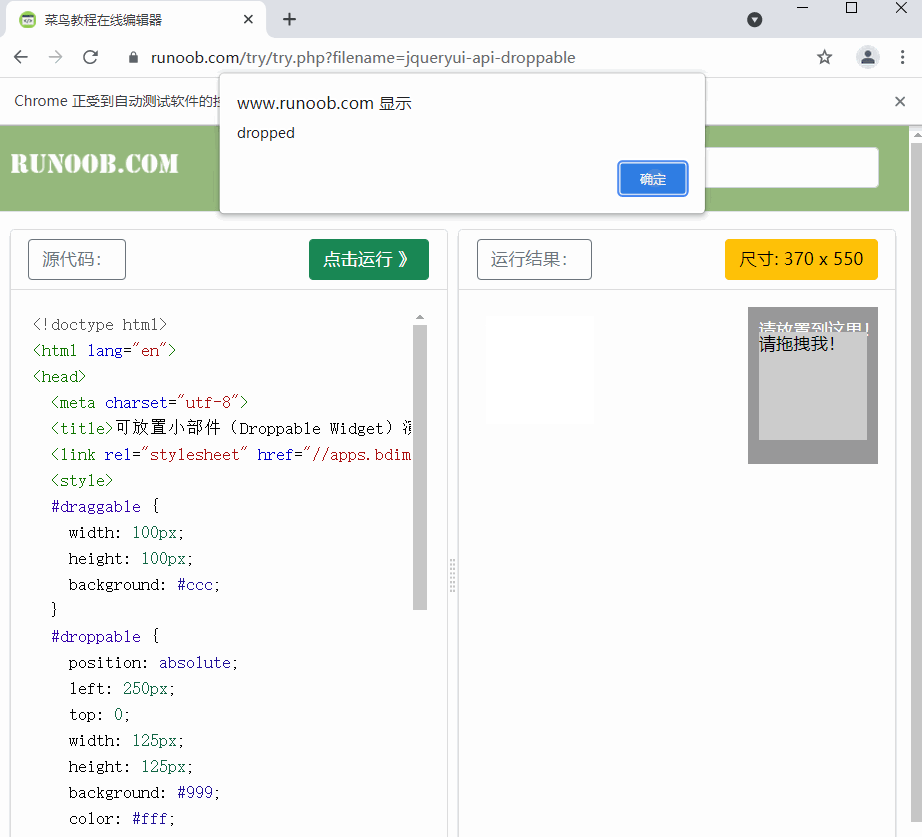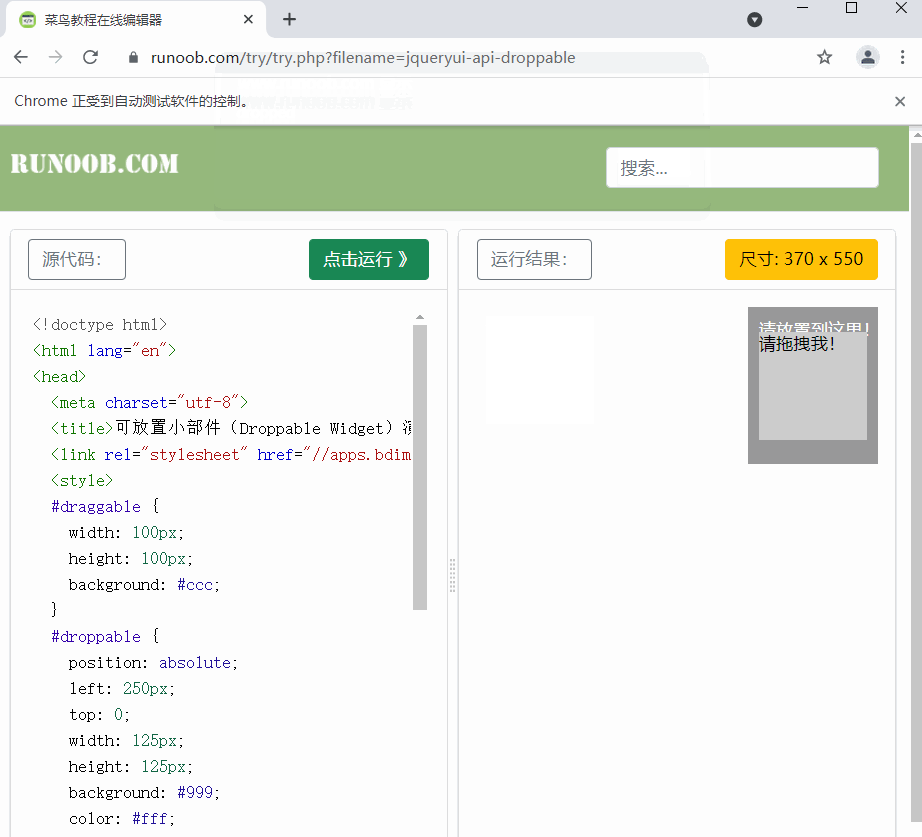
拖拽
move_to_element()
from selenium.webdriver.common.action_chains import ActionChains
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.baidu.com'
browser.get(url)
time.sleep(2)
# 定位悬停的位置
move = browser.find_element_by_css_selector("#form > span.bg.s_ipt_wr.new-pmd.quickdelete-wrap > span.soutu-btn")
# 悬停操作
ActionChains(browser).move_to_element(move).perform()
time.sleep(5)
# 关闭浏览器
browser.close()
悬停效果
8. 模拟键盘操作
selenium中的Keys()类提供了大部分的键盘操作方法,通过send_keys()方法来模拟键盘上的按键。
引入Keys类
from selenium.webdriver.common.keys import Keys
常见的键盘操作
send_keys(Keys.BACK_SPACE):删除键(BackSpace)
send_keys(Keys.SPACE):空格键(Space)
send_keys(Keys.TAB):制表键(TAB)
send_keys(Keys.ESCAPE):回退键(ESCAPE)
send_keys(Keys.ENTER):回车键(ENTER)
send_keys(Keys.CONTRL,'a'):全选(Ctrl+A)
send_keys(Keys.CONTRL,'c'):复制(Ctrl+C)
send_keys(Keys.CONTRL,'x'):剪切(Ctrl+X)
send_keys(Keys.CONTRL,'v'):粘贴(Ctrl+V)
send_keys(Keys.F1):键盘F1.....
send_keys(Keys.F12):键盘F12
实例操作演示:
定位需要操作的元素,然后操作即可!
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
import time
browser = webdriver.Chrome()
url = 'https://www.baidu.com'
browser.get(url)
time.sleep(2)
# 定位搜索框
input = browser.find_element_by_class_name('s_ipt')
# 输入python
input.send_keys('python')
time.sleep(2)
# 回车
input.send_keys(Keys.ENTER)
time.sleep(5)
# 关闭浏览器
browser.close()
9. 延时等待
如果遇到使用ajax加载的网页,页面元素可能不是同时加载出来的,这个时候尝试在get方法执行完成时获取网页源代码可能并非浏览器完全加载完成的页面。所以,这种情况下需要设置延时等待一定时间,确保全部节点都加载出来。
三种方式可以来玩玩:强制等待、隐式等待和显式等待
就很简单了,直接time.sleep(n)强制等待n秒,在执行get方法之后执行。
implicitly_wait()设置等待时间,如果到时间有元素节点没有加载出来,就会抛出异常。
from selenium import webdriver
browser = webdriver.Chrome()
# 隐式等待,等待时间10秒
browser.implicitly_wait(10)
browser.get('https://www.baidu.com')
print(browser.current_url)
print(browser.title)
# 关闭浏览器
browser.close()
设置一个等待时间和一个条件,在规定时间内,每隔一段时间查看下条件是否成立,如果成立那么程序就继续执行,否则就抛出一个超时异常。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
# 设置等待时间10s
wait = WebDriverWait(browser, 10)
# 设置判断条件:等待id='kw'的元素加载完成
input = wait.until(EC.presence_of_element_located((By.ID, 'kw')))
# 在关键词输入:关键词
input.send_keys('Python')
# 关闭浏览器
time.sleep(2)
browser.close()
WebDriverWait的参数说明:
WebDriverWait(driver,timeout,poll_frequency=0.5,ignored_exceptions=None)
driver: 浏览器驱动
timeout: 超时时间,等待的最长时间(同时要考虑隐性等待时间)
poll_frequency: 每次检测的间隔时间,默认是0.5秒
ignored_exceptions:超时后的异常信息,默认情况下抛出NoSuchElementException异常
until(method,message='')
method: 在等待期间,每隔一段时间调用这个传入的方法,直到返回值不是False
message: 如果超时,抛出TimeoutException,将message传入异常
until_not(method,message='')
until_not与until相反,until是当某元素出现或什么条件成立则继续执行,until_not是当某元素消失或什么条件不成立则继续执行,参数也相同。
其他等待条件
from selenium.webdriver.support import expected_conditions as EC
# 判断标题是否和预期的一致
title_is
# 判断标题中是否包含预期的字符串
title_contains
# 判断指定元素是否加载出来
presence_of_element_located
# 判断所有元素是否加载完成
presence_of_all_elements_located
# 判断某个元素是否可见. 可见代表元素非隐藏,并且元素的宽和高都不等于0,传入参数是元组类型的locator
visibility_of_element_located
# 判断元素是否可见,传入参数是定位后的元素WebElement
visibility_of
# 判断某个元素是否不可见,或是否不存在于DOM树
invisibility_of_element_located
# 判断元素的 text 是否包含预期字符串
text_to_be_present_in_element
# 判断元素的 value 是否包含预期字符串
text_to_be_present_in_element_value
#判断frame是否可切入,可传入locator元组或者直接传入定位方式:id、name、index或WebElement
frame_to_be_available_and_switch_to_it
#判断是否有alert出现
alert_is_present
#判断元素是否可点击
element_to_be_clickable
# 判断元素是否被选中,一般用在下拉列表,传入WebElement对象
element_to_be_selected
# 判断元素是否被选中
element_located_to_be_selected
# 判断元素的选中状态是否和预期一致,传入参数:定位后的元素,相等返回True,否则返回False
element_selection_state_to_be
# 判断元素的选中状态是否和预期一致,传入参数:元素的定位,相等返回True,否则返回False
element_located_selection_state_to_be
#判断一个元素是否仍在DOM中,传入WebElement对象,可以判断页面是否刷新了
staleness_of
10. 其他
补充一些
还有一些操作,比如下拉进度条,模拟javaScript,使用execute_script方法来实现。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')
在selenium使用过程中,还可以很方便对Cookie进行获取、添加与删除等操作。
from selenium import webdriver
browser = webdriver.Chrome()
# 知乎发现页
browser.get('https://www.zhihu.com/explore')
# 获取cookie
print(f'Cookies的值:{browser.get_cookies()}')
# 添加cookie
browser.add_cookie({'name':'才哥', 'value':'帅哥'})
print(f'添加后Cookies的值:{browser.get_cookies()}')
# 删除cookie
browser.delete_all_cookies()
print(f'删除后Cookies的值:{browser.get_cookies()}')
输出:
Cookies的值:[{'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com', ...]
添加后Cookies的值:[{'domain': 'www.zhihu.com', 'httpOnly': False, 'name': '才哥', 'path': '/', 'secure': True, 'value': '帅哥'}, {'domain': '.zhihu.com', 'httpOnly': False, 'name': 'Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49', 'path': '/', 'secure': False, 'value': '1640537860'}, {'domain': '.zhihu.com',...]
删除后Cookies的值:[]
以上就是本次有关Selenium的全部内容,后续我们将演示Selenium在爬虫以及web自动化方面的一些实战案例,敬请期待!
需要完整版PDF,请私博主!
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我将Cucumber与Ruby结合使用。通过Selenium-Webdriver在Chrome中运行测试时,我想将下载位置更改为测试文件夹而不是用户下载文件夹。我当前的chrome驱动程序是这样设置的:Capybara.default_driver=:seleniumCapybara.register_driver:seleniumdo|app|Capybara::Selenium::Driver.new(app,:browser=>:chrome,desired_capabilities:{'chromeOptions'=>{'args'=>%w{window-size=1920,1
我是Ruby新手,并被要求在我们的新项目中使用它。我们还被要求使用Padrino(Sinatra)作为后端/框架。我们被要求使用Rspec进行测试。我一直在寻找可以指导在Padrino上使用RspecforRuby的教程。我得到的主要是引用RoR。但是,我需要RubyonPadrino。请在任何入门/指南/引用/讨论等方面指导我。如有不妥之处请指正。可能是我没有针对我的问题搜索正确的词/短语组合。我正在使用Ruby1.9.3和Padrinov.0.10.6。注意:我还提到了SOquestion,但它没有帮助。 最佳答案 我没用过Pa
文章目录1.任务背景2.任务目标3.相关知识点4.任务实操4.1安装配置JDK4.2启动FISCOBCOS4.3下载解压WeBASE-Front4.4拷贝sdk证书文件4.5启动节点4.6访问节点4.7检查运行状态5.任务总结1.任务背景FISCOBCOS其实是有控制台管理工具,用来对区块链系统进行各种管理操作。但是对于初学者来说,还是可视化界面更友好,本节就来介绍WeBASE管理平台,这是一款微众银行开源的自研区块链中间件平台,可以降低区块链使用的门槛,大幅提高区块链应用的开发效率。微众银行是腾讯牵头设立的民营银行,在国内民营银行里还是比较出名的。微众银行参与FISCOBCOS生态建设,一定
Asitcurrentlystands,thisquestionisnotagoodfitforourQ&Aformat.Weexpectanswerstobesupportedbyfacts,references,orexpertise,butthisquestionwilllikelysolicitdebate,arguments,polling,orextendeddiscussion.Ifyoufeelthatthisquestioncanbeimprovedandpossiblyreopened,visitthehelpcenter提供指导。9年前关闭。我打算学习Seleni
我一直在工作中使用seleniumIDE。现在我们决定将Seleniumwebdriver与Ruby结合使用。我完全不知道如何设置我的Mac,MacProYosemite10.10.5。在我的终端中,我运行了这些命令:$ruby-e"$(curl-fsSLhttps://raw.githubusercontent.com/Homebrew/install/master/install)"$brewdoctorYoursystemisreadytobrew.$brewinstallruby==>Summary/usr/local/Cellar/openssl/1.0.2d_1:464fi