Java工具包提供了强大的数据结构。在Java中的数据结构主要包括以下几种接口和类:
枚举(Enumeration)、位集合(BitSet)、向量(Vector)、栈(Stack)、字典(Dictionary)、哈希表(Hashtable)、属性(Properties)
以上这些类是传统遗留的,在Java2中引入了一种新的框架-集合框架(Collection)
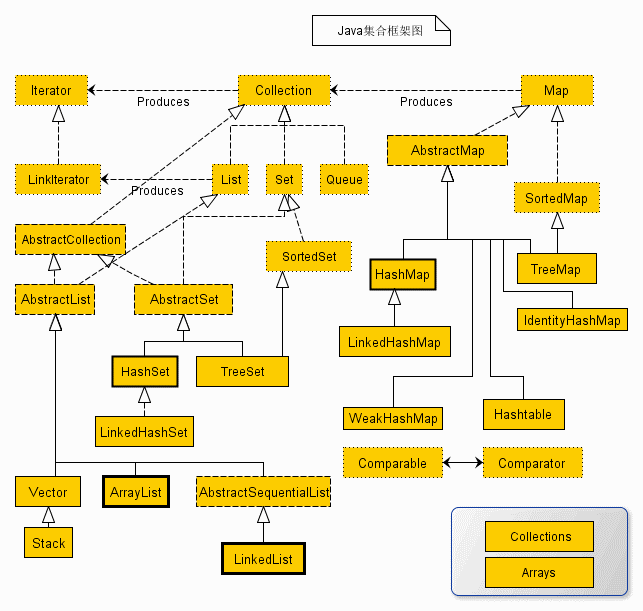
Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。
Collection 接口又有 3 种子类型,List、Set 和 Queue,再下面是一些抽象类,最后是具体实现类,常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap 等等。
结构特点
| List | Set | Map |
|---|---|---|
| 存储单列数据 | 存储单列数据 | 存储键值对 |
| 有顺序的,并且值允许重复 | 无顺序的,并且不允许重复 | 无序的,它的键是不允许重复的,但是值是允许重复的 |
实现类
List接口:
| LinkedList | ArrayList | Vector |
|---|---|---|
| 基于链表实现 | 基于数组实现 | 基于数组实现 |
| 链表内存是散列的,增删快,查找慢 | 效率高,增删慢,查找快 | 效率低,增删慢,查找慢 |
| 非线程安全 | 非线程安全 | 线程安全 |
Set接口:
| HashSet | LinkedHashSet | TreeSet |
|---|---|---|
| 基于HashMap 实现 | 继承于 HashSet、基于LinkedHashMap实现 | |
| 重写 equals()和 hash Code()方法 | ||
| 允许有 null 值 | ||
| 非线程安全 | 非线程安全 | 非线程安全 |
Map接口:
| HashMap | HashTable | LinkedHashMap | SortMap |
|---|---|---|---|
| 支持 null 值和 null 键 | 不支持 null 值和 null 键 | HashMap 的一个子类 | 接口 TreeMap |
| 高效 | 低效 | 保存了记录的插入顺序 | 能够把它保存的记录根据键排序 |
| 非线程安全 | 线程安全 | 非线程安全 | 非线程安全 |
ArrayList 类是一个可以动态修改的数组,与普通数组的区别就是它是没有固定大小的限制,我们可以添加或删除元素。
import java.util.ArrayList; // 引入 ArrayList 类
ArrayList<E> objectName =new ArrayList<>(); // 初始化
| 方法 | 描述 |
|---|---|
| add(int index,E element) | 将元素插入到指定位置的 arraylist 中 |
| clear() | 删除 arraylist 中的所有元素 |
| clone() | 复制一份 arraylist |
| contains(Object obj) | 判断元素是否在 arraylist |
| get(int index) | 通过索引值获取 arraylist 中的元素 |
| set(int index, E element) | 替换 arraylist 中指定索引的元素 |
| indexOf(Object obj) | 返回 arraylist 中元素的索引值 |
| remove(Object obj) | 删除 arraylist 里的单个元素 |
| size() | 返回 arraylist 里元素数量 |
| isEmpty() | 判断 arraylist 是否为空 |
| subList(int fromIndex, int toIndex) | 截取部分 arraylist 的元素 |
| sort(Comparator c) | 根据指定的顺序对 arraylist 元素进行排序 |
| toArray(T[] arr【可选参数】) | 将 arraylist 转换为数组【无参数返回类型为Object】 |
| toString() | 将 arraylist 转换为字符串 |
| lastIndexOf() | 返回指定元素在 arraylist 中最后一次出现的位置 |
| trimToSize() | 将 arraylist 中的容量调整为数组中的元素个数 |
| removeRange(int fromIndex, int toIndex) | 删除 arraylist 中指定索引之间存在的元素 |
链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的地址。
链表可分为单向链表和双向链表。
继承了 AbstractSequentialList 类。
实现了 Queue 接口,可作为队列使用。
实现了 List 接口,可进行列表的相关操作。
实现了 Deque 接口,可作为队列使用。
实现了 Cloneable 接口,可实现克隆。
实现了 java.io.Serializable 接口,即可支持序列化,能通过序列化去传输。
| 方法 | 描述 |
|---|---|
| boolean add(E e) | 链表末尾添加元素,返回是否成功,成功为 true,失败为 false。 |
| void add(int index, E element) | 向指定位置插入元素。 |
| void addFirst(E e) | 元素添加到头部。 |
| void addLast(E e) | 元素添加到尾部。 |
| boolean offer(E e) | 向链表末尾添加元素,返回是否成功,成功为 true,失败为 false。 |
| boolean offerFirst(E e) | 头部插入元素,返回是否成功,成功为 true,失败为 false。 |
| boolean offerLast(E e) | 尾部插入元素,返回是否成功,成功为 true,失败为 false。 |
| void clear() | 清空链表。 |
| E removeFirst() | 删除并返回第一个元素。 |
| E removeLast() | 删除并返回最后一个元素。 |
| boolean remove(Object o) | 删除某一元素,返回是否成功,成功为 true,失败为 false。 |
| E remove(int index) | 删除指定位置的元素。 |
| E poll() | 删除并返回第一个元素。 |
| E remove() | 删除并返回第一个元素。 |
| boolean contains(Object o) | 判断是否含有某一元素。 |
| E get(int index) | 返回指定位置的元素。 |
| E getFirst() | 返回第一个元素。 |
| E getLast() | 返回最后一个元素。 |
| int indexOf(Object o) | 查找指定元素从前往后第一次出现的索引。 |
| int lastIndexOf(Object o) | 查找指定元素最后一次出现的索引。 |
| E peek() | 返回第一个元素。 |
| E element() | 返回第一个元素。 |
| E peekFirst() | 返回头部元素。 |
| E peekLast() | 返回尾部元素。 |
| E set(int index, E element) | 设置指定位置的元素。 |
| int size() | 返回链表元素个数。 |
| Object[] toArray() | 返回一个由链表元素组成的数组。 |
| T[] toArray(T[] a) | 返回一个由链表元素转换类型而成的数组。 |
Java Collections框架的Stack类提供了堆栈的实现。但是,建议Deque用作堆栈而不是Stack类。这是因为Stack的方法是同步的。
以下是Deque接口提供的用于实现堆栈和队列的方法:
栈(后进先出):
Deque que = new LinkedList();
que.push(e);//在双端队列的开头添加元素
que.pop();//弹出栈顶
que.peek();//查看栈顶
队列(先进先出)
add(E);//boolean 在队尾添加元素,添加成功返回true,如果队列已满无法添加则抛出异常。
offer(E);//boolean 在队尾添加元素,添加成功返回true,如果队列已满无法添加则返回false。
remove();//E 删除队头元素,并返回删除的元素,如果队列为null,抛出异常。
poll();//E 删除队头元素,并返回删除的元素,如果队列为null,返回null。
element();//E 获取队头元素,如果队列为null将抛出异常。
peek();//E 获取队头元素,如果队列为null将返回null。
HashSet 基于 HashMap 来实现的,是一个不允许有重复元素的集合。
创建对象:
HashSet<String> sites = new HashSet<String>();
| 方法 | 描述 |
|---|---|
| add(E) | 添加元素 |
| contains(E) | 判断元素是否存在 |
| remove() | 删除元素;删除成功返回 true,否则为 false |
| size() | 计算大小; |
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 实现了 Map 接口,根据键的 HashCode 值存储数据,具有很快的访问速度,最多允许一条记录的键为 null,不支持线程同步。
创建对象:
HashMap<Integer, String> Sites = new HashMap<Integer, String>();
| 方法 | 描述 |
|---|---|
| put(key,E) | 添加元素 |
| get(key) | 访问元素 |
| remove(key) | 删除元素 |
| clear() | 删除所有键值对 |
| size() | 计算大小 |
| isEmpty() | 判断 hashMap 是否为空 |
| containsKey(Object key) | 检查 hashMap 中是否存在指定的 key 对应的映射关系 |
| containsValue(Object value) | 检查 hashMap 中是否存在指定的 value 对应的映射关系。 |
| replace(K key, V newValue) | 替换 hashMap 中是指定的 key 对应的 value |
| getOrDefault(Object key, V defaultValue) | 获取指定 key 对应对 value,如果找不到 key ,则返回设置的默认值 |
| values() | 返回 hashMap 中存在的所有 value 值。 |
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD