针对设计过程的问题,如有疑问,欢迎留言讨论!点我返回目录
LC滤波器,是指将电感(L)与电容器 ©进行组合设计构成的滤波电路,可去除或通过特定频率的无源器件。电容器具有隔直流通交流,且交流频率越高越容易通过的特性。而电感则具有隔交流通直流,且交流频率越高越不易通过的特性。因此,电容器和电感是特性完全相反的被动元器件,通过将电容和电感组合,就可去除或通过特定频率的信号。
LC滤波器按所通过信号的频段分为以下三类
低通滤波器是一种用于传递直流或者低频信号,衰减高频信号的滤波器。
作为被最广泛使用的滤波器电路,主要用于剔除高频噪声。此外,音响中用于剔除低音用扬声器的高音/中音成分。
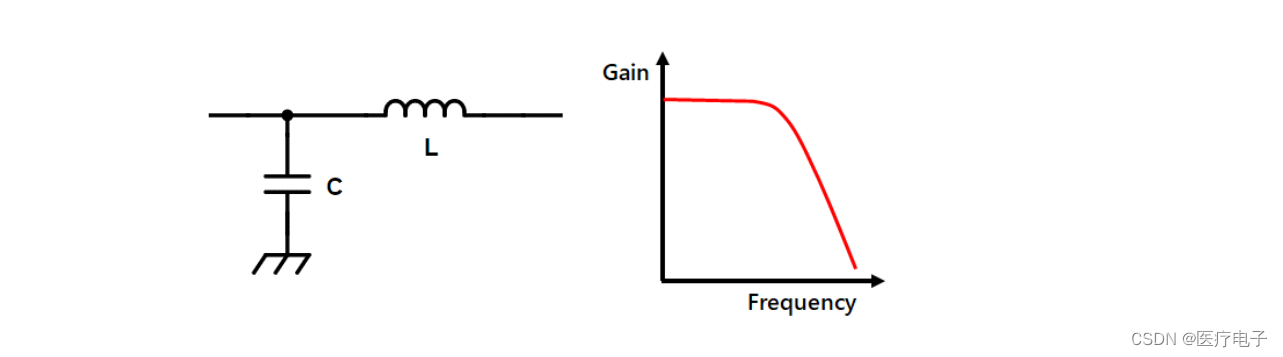
高通滤波器是允许高于某一截频的频率通过,而大大衰减较低频率的一种滤波器。这种滤波器被用于剔除听阈的低频噪声,或剔除高音用扬声器的中音/低音成分等。
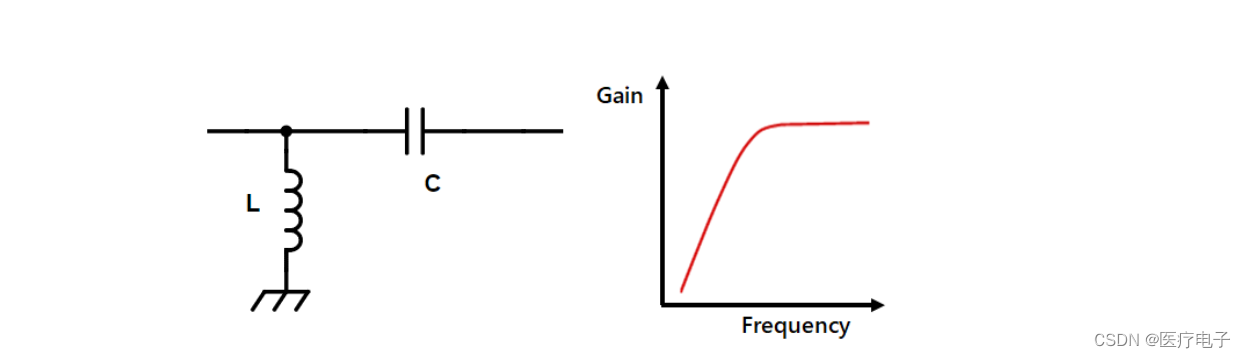
带通滤波器是用来只允许特定频率的信号通过,屏蔽其他频率信号的滤波器电路。这种滤波器被用于收音机的选台(调整频率)、或剔除中音用扬声器的低音/高音成分等。
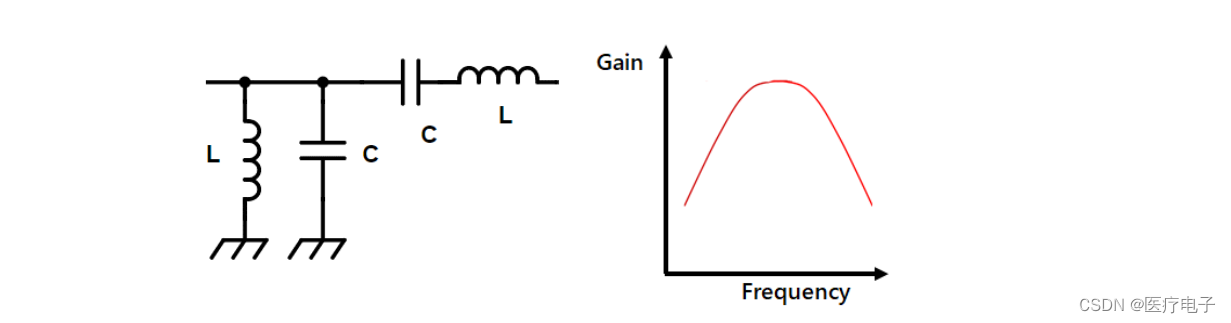
电容器和电感,虽然各自单独具有噪声去除效果,但是通过将2个零部件进行组合,就可获得更大的噪声去除效果。串联连接的电感以隔断高频噪声,用并联连接的电容器来使高频噪声旁通的方式发挥作用。但是,噪声去除效果也会随输入侧和输出侧各自的外部阻抗的高低而改变。譬如,即使试图用低阻抗的电容器来使噪声旁通,如果输出阻抗更低,则噪声会流向负荷侧。相反,即使试图以高阻抗的电感来隔断噪声,如果输出阻抗更高,则噪声会流向负荷侧。因此,外部阻抗高时,将电容器配置在附近;外部阻抗低时,将电感配置在附近。如上所述,考虑外部阻抗,低通滤波器可区分为以下4类。
应用场景:输入阻抗 ⇒ 高;输出阻抗 ⇒ 低 时
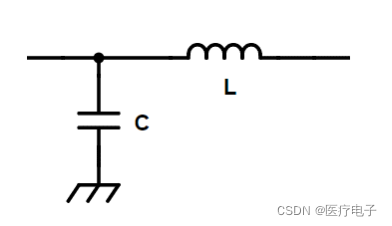
应用场景:输入阻抗 ⇒ 低;输出阻抗 ⇒ 高 时
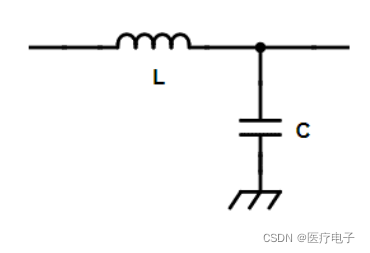
应用场景输入阻抗 ⇒ 高;输出阻抗 ⇒ 高 时
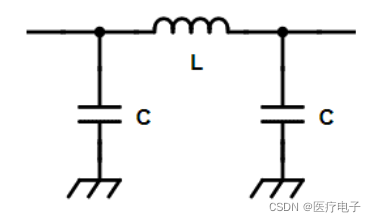
应用场景:输入阻抗 ⇒ 低;输出阻抗 ⇒ 低 时
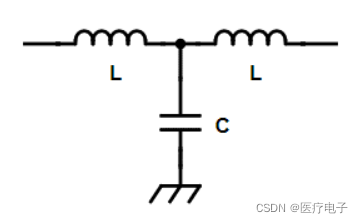
相比L型滤波器,π型和T型滤波器的噪声去除效果更好,因而还要考虑这方面的因素来选定电路。
要在信号电路上从信号波形去除噪声时,必须选定在信号频率下不会衰减而在噪声频率下衰减会增大的零部件常数。要在电源电路上从直流电压去除噪声时,由于直流的衰减为零,因而只考虑噪声频率的衰减量。
滤波器的衰减特性(频率引起的衰减量的变化)可通过计算来求得,但实际的电容器和电感除了纯粹的静电电容和电感外还包含有影响性能的成分,因而无法单纯地计算。
在L型滤波器上标示出基于电容器和电感的实际等效电路的电路图。
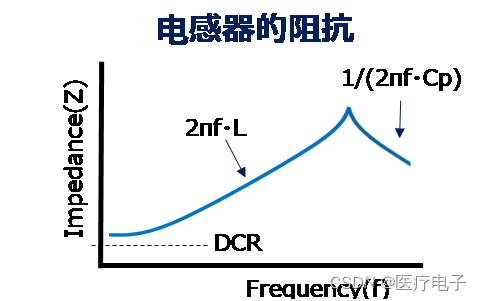
电容器上除了静电电容©外还包含有等效串联电阻(ESR)和等效串联电感(ESL),电感上除了电感(L)外还包含有直流电阻(DCR)和杂散电容(Cp)。
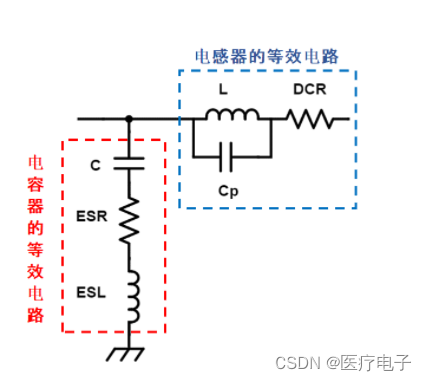
电容器若只是C成分,频率越高阻抗低,噪声吸收效果越好,但在实际的电容器上则根据ESR来决定阻抗的下限值,并且阻抗在高频域会随ESL而升高,变得不易吸收噪声。
此外,电感若只是L成分,频率越高阻抗高,噪声隔断效果越好,但实际上阻抗会随电感器中所包含的Cp而在高频域下降,噪声的隔断效果下降。
再者,各自的成分也会随频率而发生值的变化,因而将这些因素全都考虑进来选定零部件就变得相当难。
因此,LC滤波器上经常会使用模拟工具来选定零部件。
通常,模拟工具上可使用按零部件的型号别提供的S参数或SPICE模型,来计算每个频率的正确的衰减量。
需求:射频噪声中包括AM频带(1MHz左右)和FM频带(80MHz左右),选定在这2个频带衰减量满足-60dB以上的零部件。
另外,前提条件是假定输入/输出阻抗为50Ω。
目标频率 : 1MHz, 80MHz
目标衰减量 :-60dB
输入/输出阻抗 :150Ω
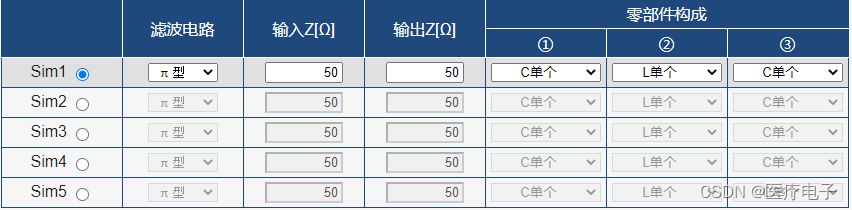
1 仿真条件
从L型、π型、T型中选择。
今本次选择π型,并将输入/输出阻抗设定为50Ω。
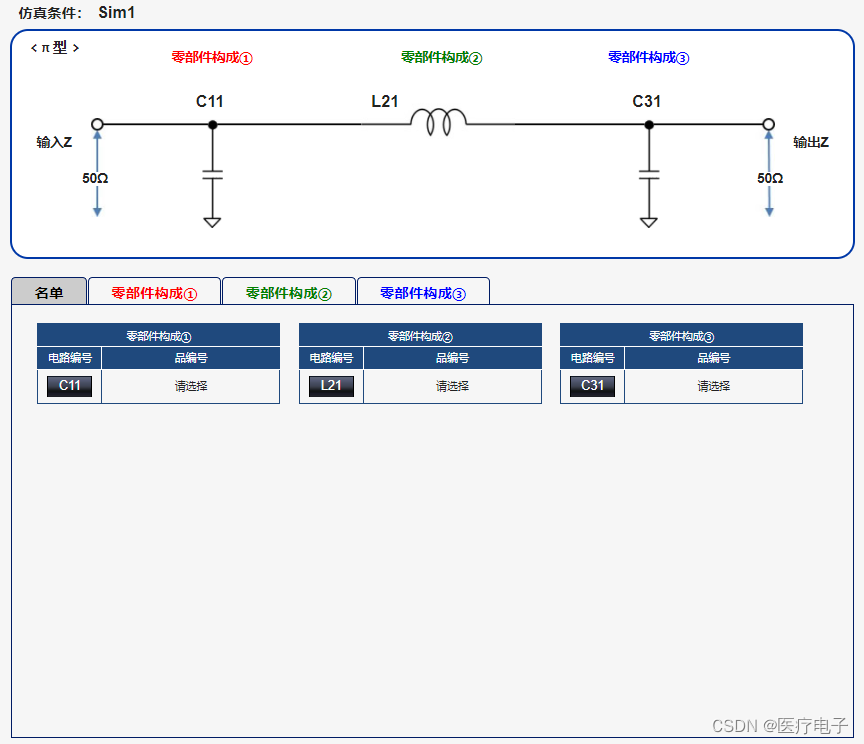
** 2 选择使用零部件**
从已被登录的零部件中选择任意的电容器型号和电感型号。
本次在①100μF的电容器和10μH的电感、②10μF的电容器和1μH的电感这2个条件下进行了模拟。
** 3 仿真结果**
模拟结果,满足目标值的为选定②的组合。实际上进行电路和零部件的各种组合的模拟,选定最佳的零部件。
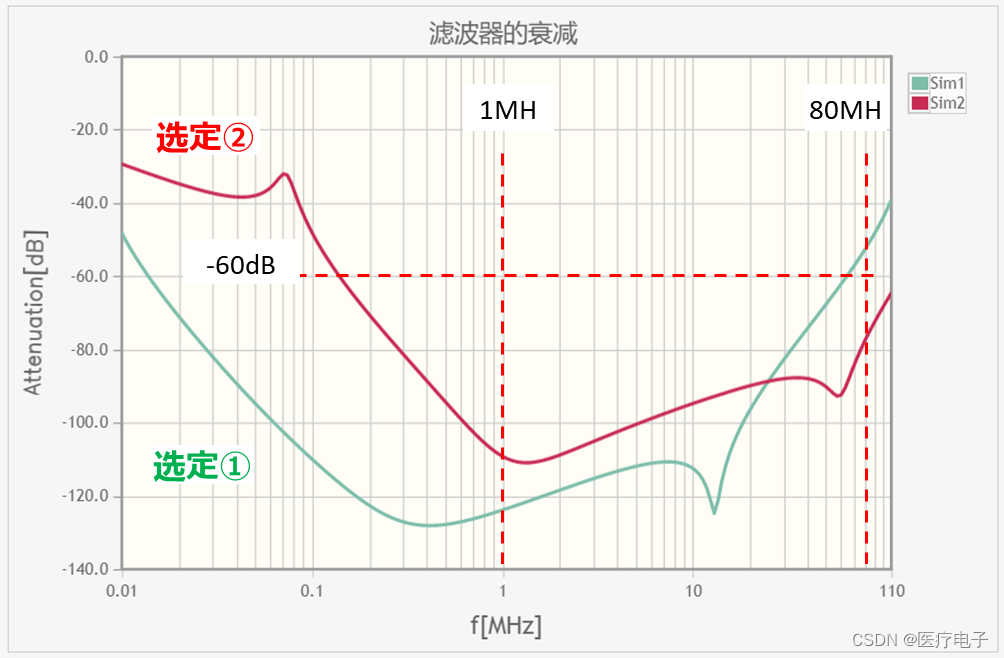
本次模拟中得出的结果是,C值和L值小的组合,比C值和L值大的组合更满足目标值。这取决于在高频域电容器的ESL和电感的Cp有较大的影响。
在低频域(大致在0.1MHz以下),ESL和Cp的影响小,衰减量大致上只由C值和L值来决定,因而C值和L值大的①的衰减量增大。但是,在像FM频带(80MHz)那样的高频域,ESL和Cp的值大的①的衰减量减小,因而衰减量发生了逆转。
(如果是相同规格的零部件,C值大的ESL也会增大,此外,L值大的Cp也会增大)
如上所述,在进行LC滤波器的设计时,如果不考虑电容器的ESL和电感的Cp选定零部件,就会得到与预测不同的结果,对此要予以注意。
欢迎一起讨论技术问题,求关注!
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
在Ruby中,是否有一种简单的方法可以将n维数组中的每个元素乘以一个数字?这样:[1,2,3,4,5].multiplied_by2==[2,4,6,8,10]和[[1,2,3],[1,2,3]].multiplied_by2==[[2,4,6],[2,4,6]]?(很明显,我编写了multiplied_by函数以区别于*,它似乎连接了数组的多个副本,不幸的是这不是我需要的)。谢谢! 最佳答案 它的长格式等价物是:[1,2,3,4,5].collect{|n|n*2}其实并没有那么复杂。你总是可以使你的multiply_by方法:c
我正在使用Ruby解决一些ProjectEuler问题,特别是这里我要讨论的问题25(Fibonacci数列中包含1000位数字的第一项的索引是多少?)。起初,我使用的是Ruby2.2.3,我将问题编码为:number=3a=1b=2whileb.to_s.length但后来我发现2.4.2版本有一个名为digits的方法,这正是我需要的。我转换为代码:whileb.digits.length当我比较这两种方法时,digits慢得多。时间./025/problem025.rb0.13s用户0.02s系统80%cpu0.190总计./025/problem025.rb2.19s用户0.0
我正在构建一个小部件来显示奥运会的奖牌数。我有一个“国家”对象的集合,其中每个对象都有一个“名称”属性,以及奖牌计数的“金”、“银”、“铜”。列表应该排序:1.首先是奖牌总数2.如果奖牌相同,按类型分割(金>银>铜,即2金>1金+1银)3.如果奖牌和类型相同,则按字母顺序子排序我正在用ruby做这件事,但我想语言并不重要。我确实找到了一个解决方案,但如果感觉必须有更优雅的方法来实现它。这是我做的:使用加权奖牌总数创建一个虚拟属性。因此,如果他们有2个金牌和1个银牌,加权总数将为“3.020100”。1金1银1铜为“3.010101”由于我们希望将奖牌数排序为最高的,因此列表按降序排
我想为名字验证编写一个正则表达式。正则表达式应包括所有字母(拉丁/法语/德语字符等)。但是我想从中排除数字并允许-。所以基本上它是\w(减)数(加)-。请帮忙。 最佳答案 ^[\p{L}-]+$\p{L}匹配anykindofletterfromanylanguage. 关于ruby-on-rails-rails中的正则表达式匹配[\w]和"-"但不匹配数字,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.c