Hive自定义UDF函数详解
UDF全称:User-Defined Functions,即用户自定义函数,在Hive SQL编译成MapReduce任务时,执行java方法,类似于像MapReduce执行过程中加入一个插件,方便扩展。
UDF:操作单个数据行,产生单个数据行;
UDAF:操作多个数据行,产生一个数据行;
UDTF:操作一个数据行,产生多个数据行一个表作为输出;
1.编写UDF函数,UDF需要继承org.apache.hadoop.hive.ql.exec.UDF,UDTF继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF,UDAF使用比较少,这里先不讲解
2.将写好的类打包为jar,如HiveUDF-1.0.jar,并且上传到Hive机器或者HDFS目录
3.入到Hive shell环境中,输入命令add jar /home/hadoop/HiveUDF-1.0.jar注册该jar文件;或者把HiveUDF-1.0.jar上传到hdfs,hadoop fs -put HiveUDF-1.0.jar /home/hadoop/HiveUDF-1.0.jar,再输入命令add jar hdfs://hadoop60:8020/home/hadoop/HiveUDF-1.0.jar;
4.为UDF类起一个别名,create temporary function myudf as ‘com.master.HiveUDF.MyUDF’;注意,这里UDF只是为这个Hive会话临时定义的;
5.在select中使用myudf();
1)UDF,自定义一个函数,并且实现把列中的数据由小写转换成大写
2)UDTF,拆分一个表中的name字段,以|为分割,分成不同的列,如下所示:
表中的数据为:
id name
1 Ba|qz
2 xa
要拆分成如下格式:
id name
1 Ba
1 qz
2 xa
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.1.1</version>
</dependency>
create table if not exists t_user (
id int,
name string
)
clustered by (id) into 2 buckets
row format delimited fields terminated by '|'
stored as orc TBLPROPERTIES('transactional'='true');
向Hive表中插入数据:
insert into t_user values(1,'Ba|qz');
insert into t_user values(1,'xa');
UDF函数需要继承org.apache.hadoop.hive.ql.exec.UDF类,并且添加evaluate方法,原因是:UDF类默认的UDFMethodResolver是org.apache.hadoop.hive.ql.exec.DefaultUDFMethodResolver,evaluate方法是在DefaultUDFMethodResolver中进行配置,默认绑定的是evaluate方法。
添加evaluate有两个注意事项:
1)evaluate方法遵循重载的原则,参数是用户自定义的,调用那个方法调用是在使用函数时候的参数决定。
2)evaluate方法必须有返回值,返回类型以及方法参数可以是Java数据或相应的Writable类。
具体实现:
public class MyUDF extends UDF {
public String evaluate(String s) {
if (s == null) {
return "";
}
return s.toUpperCase();
}
}
1)UDTF限制(----后面为原文解析),官网地址:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-Built-inTable-GeneratingFunctions(UDTF)
在UDTF中Select里面不能有其他语句----No other expressions are allowed in SELECT/SELECT pageid, explode(adid_list) AS myCol… is not supported
UDTF不能被嵌套----UDTF’s can’t be nested/SELECT explode(explode(adid_list)) AS myCol… is not supported
UDTF不支持GROUP BY / CLUSTER BY / DISTRIBUTE BY / SORT BY----GROUP BY/ CLUSTER BY/ DISTRIBUTE BY/ SORT BY is not supported/SELECT explode(adid_list) AS myCol … GROUP BY myCol is not supported
继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF,实现initialize,process,close三个方法。
2)注意事项
initialize方法制定了返回的列名及数据类型(forward写入数据的类型是一个数组,对应着initialize定义的列名),可以返回多个,在List里面对应即可。函数列名调用的时侯通过:myudtf(col,col1) t1 as co1,col2来使用列名。
3)实现
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class MyUDTF extends GenericUDTF {
@Override
public StructObjectInspector initialize(ObjectInspector[] argOIs) throws UDFArgumentException {
List<String> fieldNames = new ArrayList<>();
List<ObjectInspector> fieldTypes = new ArrayList<>();
fieldNames.add("col");
fieldTypes.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldTypes);
}
@Override
public void process(Object[] args) throws HiveException {
String col = args[0].toString();
String[] cols = col.split("\\|");
for (String c : cols) {
String[] results = new String[1];
results[0] = c;
forward(results);
}
}
@Override
public void close() throws HiveException {
}
}
4)在Hive Shell中添加临时函数
上传到Linux目录,然后用add jar来添加路径
hive>add jar /home/hadoop/hivetest/HiveUDF-1.0.jar
创建临时函数:
hive>create temporary function myudf as "com.master.HiveUDF.MyUDF";
hive>create temporary function myudtf as "com.master.HiveUDF.MyUDTF"
5)UDF使用
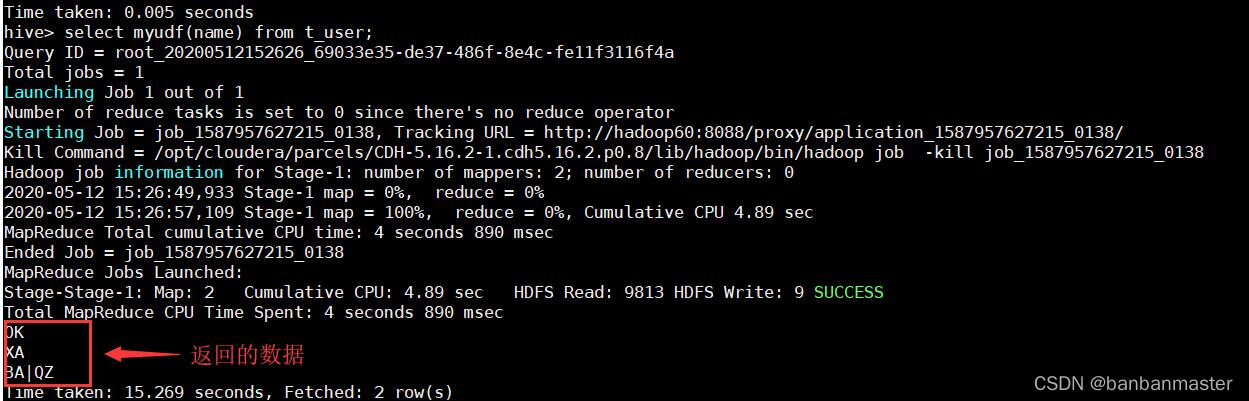
select myudf(name) from t_user;
效果如下
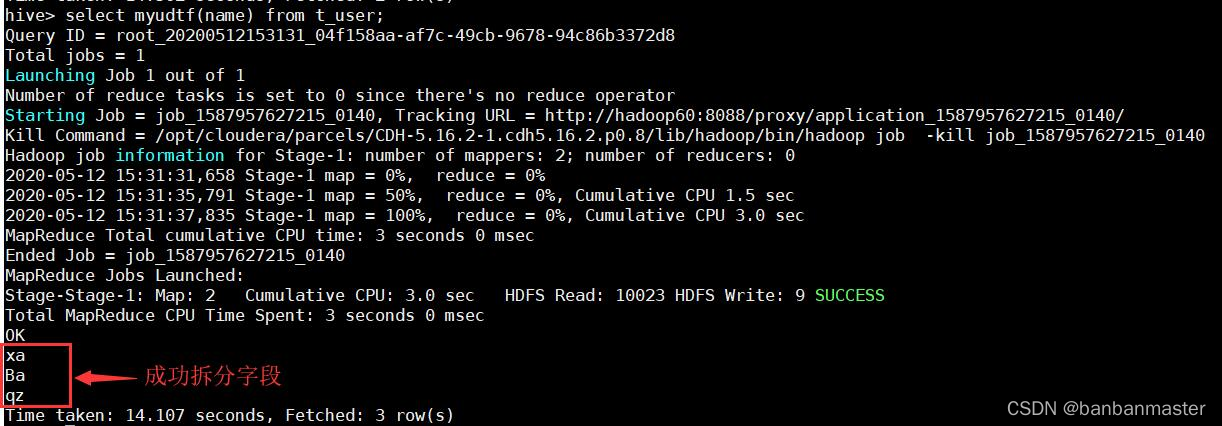
select myudtf(name) from t_user
效果如下:
但是貌似没有和前面的数据结合,这时候,需要用lateral view来操作,语句如下
select t1.id,t2.col from t_user t1 lateral view myudtf(name) t2 as col
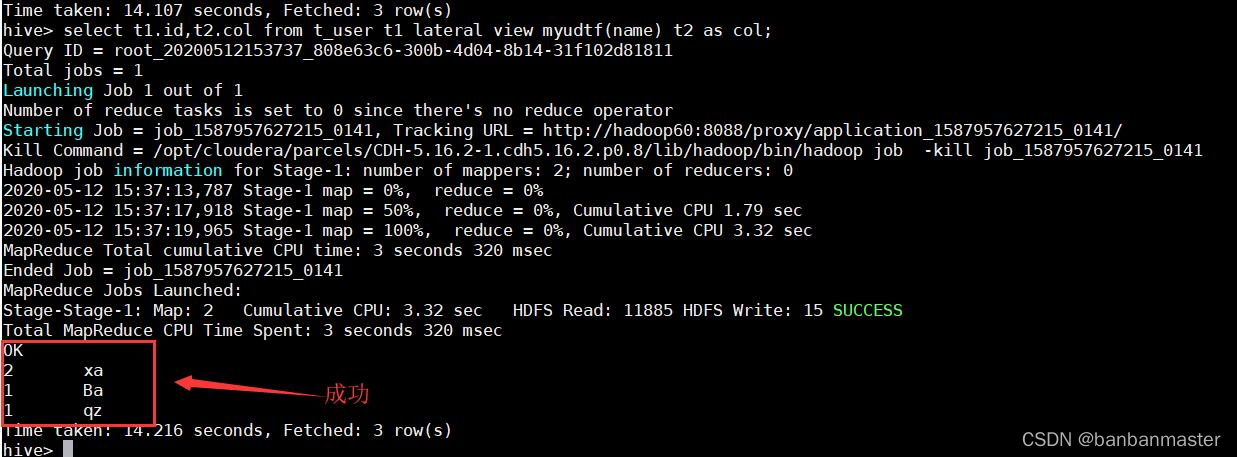
lateral view用于和split, explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合
我正在尝试设置一个puppet节点,但rubygems似乎不正常。如果我通过它自己的二进制文件(/usr/lib/ruby/gems/1.8/gems/facter-1.5.8/bin/facter)在cli上运行facter,它工作正常,但如果我通过由rubygems(/usr/bin/facter)安装的二进制文件,它抛出:/usr/lib/ruby/1.8/facter/uptime.rb:11:undefinedmethod`get_uptime'forFacter::Util::Uptime:Module(NoMethodError)from/usr/lib/ruby
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun
我想在一个没有Sass引擎的类中使用Sass颜色函数。我已经在项目中使用了sassgem,所以我认为搭载会像以下一样简单:classRectangleincludeSass::Script::FunctionsdefcolorSass::Script::Color.new([0x82,0x39,0x06])enddefrender#hamlengineexecutedwithcontextofself#sothatwithintemlateicouldcall#%stop{offset:'0%',stop:{color:lighten(color)}}endend更新:参见上面的#re
我正在尝试用ruby中的gsub函数替换字符串中的某些单词,但有时效果很好,在某些情况下会出现此错误?这种格式有什么问题吗NoMethodError(undefinedmethod`gsub!'fornil:NilClass):模型.rbclassTest"replacethisID1",WAY=>"replacethisID2andID3",DELTA=>"replacethisID4"}end另一个模型.rbclassCheck 最佳答案 啊,我找到了!gsub!是一个非常奇怪的方法。首先,它替换了字符串,所以它实际上修改了
我有一些代码在几个不同的位置之一运行:作为具有调试输出的命令行工具,作为不接受任何输出的更大程序的一部分,以及在Rails环境中。有时我需要根据代码的位置对代码进行细微的更改,我意识到以下样式似乎可行:print"Testingnestedfunctionsdefined\n"CLI=trueifCLIdeftest_printprint"CommandLineVersion\n"endelsedeftest_printprint"ReleaseVersion\n"endendtest_print()这导致:TestingnestedfunctionsdefinedCommandLin
我有一个只接受一个参数的方法:defmy_method(number)end如果使用number调用方法,我该如何引发错误??通常,我如何定义方法参数的条件?比如我想在调用的时候报错:my_method(1) 最佳答案 您可以添加guard在函数的开头,如果参数无效则引发异常。例如:defmy_method(number)failArgumentError,"Inputshouldbegreaterthanorequalto2"ifnumbereputse.messageend#=>Inputshouldbegreaterthano
我使用Ember作为我的前端和GrapeAPI来为我的API提供服务。前端发送类似:{"service"=>{"name"=>"Name","duration"=>"30","user"=>nil,"organization"=>"org","category"=>nil,"description"=>"description","disabled"=>true,"color"=>nil,"availabilities"=>[{"day"=>"Saturday","enabled"=>false,"timeSlots"=>[{"startAt"=>"09:00AM","endAt"=>
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c