事务有四大特性ACID分别是:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
其中隔离性是通过数据库的锁加上MVCC(多版本并发控制)来保证的。
在介绍MVCC之前先来了解一下当前读和快照读。
当前读读取的是记录的最新版本。同时在读取的时候还要保证其他的并发事务不能更改当前记录,那么当前读会对它要读取的记录进行加锁。不同的操作会加上不同类型的锁,如:SELECT ... LOCK IN SHARE MODE(共享锁),SELECT ... FOR UPDATE、UPDATE、INSERT、 DELETE(排他锁)。
简单的不加锁的SELECT就是快照读,快照读读取的是快照生成时的数据,不一定是最新的数据,它是不加锁的非阻塞读。而不同隔离级别下,创建快照的时机也不同:
READ-COMMITTED(读已提交):事务每次SELECT时创建ReadViewREPEATABLE-READ(可重复读):事务第一次SELECT时创建ReadView,后续一直使用在MySQL默认隔离级别(REPEATABLE-READ)下,快照读保证了数据的可重复读。
MVCC全称Multi-Version Concurrency Control,即多版本并发控制。它是一种并发控制的方法,它可以维护一个数据的多个版本,用更好的方式去处理读写冲突,做到即使有读写冲突也能不加锁。MySQL中MVCC的具体实现,还需要依赖于表中的三个隐藏字段、Undo Log日志以及ReadView。
mysql> SHOW CREATE TABLE stu \G;
*************************** 1. row ***************************
Table: stu
Create Table: CREATE TABLE `stu` (
`id` int NOT NULL,
`name` varchar(10) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
mysql> SELECT * FROM stu;
+----+--------+
| id | name |
+----+--------+
| 1 | m |
| 2 | f |
+----+--------+
当创建了上述这张表后,我们在查看表结构时只能看到id、name字段,实际上除了这两个字段外,InnoDB引擎还自动为我们添加了三个隐藏字段,见下表:
| 字段 | 含义 |
|---|---|
| DB_TRX_ID | 最近修改事务ID,记录插入这条记录或最后一次修改该记录的事务ID。 |
| DB_ROLL_PTR | 回滚指针,指向这条记录的上一个版本,用于配合Undo Log,指向上一个版本。 |
| DB_ROW_ID | 隐藏主键,如果表结构没有指定主键,将会生成该隐藏字段。 |
我们可以使用ibd2sdi工具来从表空间文件中提取序列化的字典信息(SDI),来验证一下这三个隐藏字段是否存在。
["ibd2sdi"
,
{
"type": 1,
"id": 402,
"object":
{
"mysqld_version_id": 80025,
"dd_version": 80023,
"sdi_version": 80019,
"dd_object_type": "Table",
"dd_object": {
"name": "stu",
"mysql_version_id": 80025,
"created": 20220919023413,
"last_altered": 20220919023413,
"hidden": 1,
"options": "avg_row_length=0;encrypt_type=N;explicit_encryption=0;key_block_size=0;keys_disabled=0;pack_record=1;stats_auto_recalc=0;stats_sample_pages=0;",
"columns": [
{
"name": "id",
"type": 4,
"is_nullable": false,
"is_zerofill": false,
"is_unsigned": false,
"is_auto_increment": false,
"is_virtual": false,
"hidden": 1,
···省略
},
{
"name": "name",
"type": 16,
"is_nullable": false,
"is_zerofill": false,
"is_unsigned": false,
"is_auto_increment": false,
"is_virtual": false,
"hidden": 1,
···省略
},
{
"name": "DB_TRX_ID", #最近修改事务ID
"type": 10,
"is_nullable": false,
"is_zerofill": false,
"is_unsigned": false,
"is_auto_increment": false,
"is_virtual": false,
"hidden": 2,
···省略
},
{
"name": "DB_ROLL_PTR", #回滚指针
"type": 9,
"is_nullable": false,
"is_zerofill": false,
"is_unsigned": false,
"is_auto_increment": false,
"is_virtual": false,
"hidden": 2,
···省略
}
],
注意:因为这张表里已经指定了主键为id列,所以不会生成隐藏主键DB_ROW_ID列。
回滚日志,在增、改、删操作的时候产生的便于数据回滚的日志。当INSERT操作的时候,产生的回滚日志在事务提交后可被立即删除。而UPDATE和DELETE操作的时候,产生的Undo Log日志不仅在进行数据回滚时需要,在进行快照读时也需要,所以不会立即被删除。
Undo Log详情可见文章:待浩源Undo Log文章发表后添加
当有多个并发事务操作一行数据时,对这行数据的修改会产生多个版本,多个版本通过上述的一个隐藏字段DB_ROLL_PTR回滚指针指向Undo Log数据地址形成一个链表,即MVCC版本链。
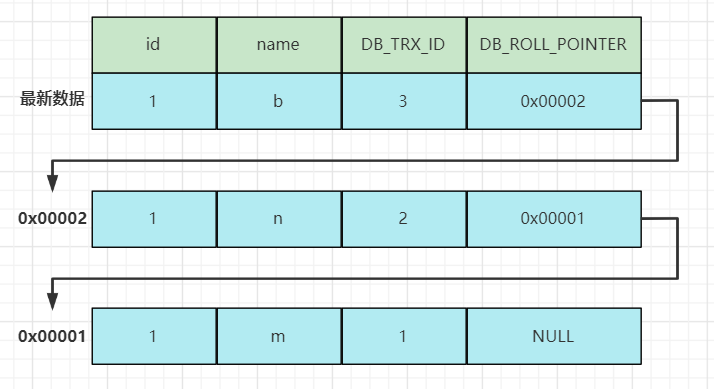
ReadView读视图是快照读SQL执行时MVCC提取数据的依据,记录并维护系统当前活跃的事务(未提交的)id。
上面讲过Undo Log和MVCC版本链,一条数据经过多次修改会产生多个版本,而快照读是根据不同时机创建的快照获取数据的,那么快照读SQL在执行时该读取那个版本的数据就是靠ReadViw读视图来决定的。
ReadView读视图中包含了四个核心字段,也是读取数据的判断依据:
| 字段 | 含义 |
|---|---|
| m_ids | 当前活跃的事务ID集合 |
| min_trx_id | 最小活跃事务ID |
| max_trx_id | 预分配事务ID,当前最大事务ID+1(因为事务ID是自增的) |
| creator_trx_id | ReadView创建者的事务ID |
ReadView一共有四种匹配规则:
| 条件 | 能否访问 | 说明 |
|---|---|---|
| trx_id == creatro_trx_id | 可以访问该版本 | 成立,说明数据是当前这个事务更改的。 |
| trx_id < min_trx_id | 可以访问该版本 | 成立,说明数据已经提交了。 |
| trx_id > max_trx_id | 不可以访问该版本 | 成立,说明该事务是在ReadView生成后才开启的。 |
| min_trx_id <= trx_id <= max_trx_id | 如果trx_id不在m_ids中,那么可以访问该版本 | 成立,说明数据已经提交。 |
前面有提到过在READ-COMMITTED隔离级别下事务在每次快照读SQL执行时创建ReadView,每次创建的ReadView的四个字段对应的值也是不同的,所以在READ-COMMITTED隔离级别下每次快照读SQL获取的数据可能也是不同的。
下面通过一个READ-COMMITTED隔离级别下并发事务的案例来详细看看:
现有四个并发事务同时访问一条数据:
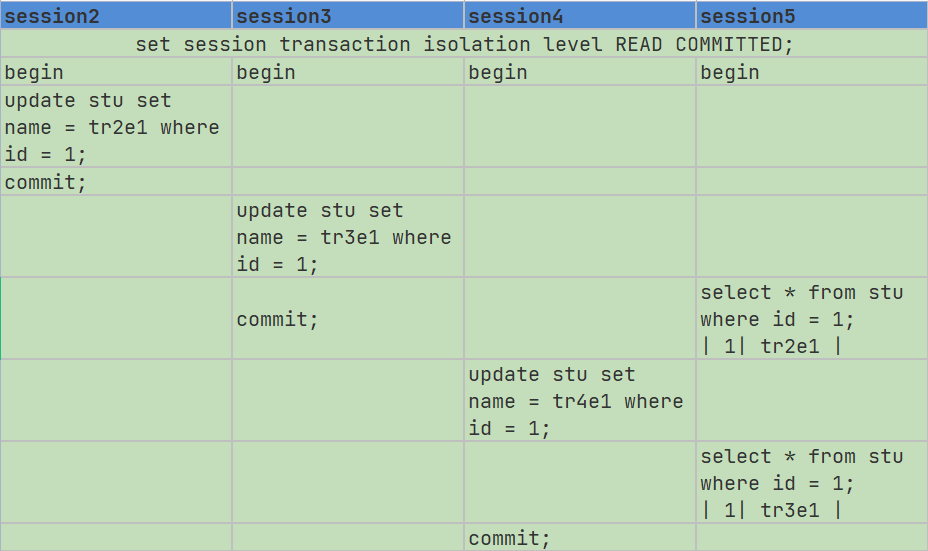
在上述并发事务中,事务5查询了两次id为1的数据,因为当前的隔离级别设置为了READ-COMMITTED,事务在每次快照读SQL执行时创建一个ReadView,每次生成的ReadView中的四个字段值都不同。那么三次快照读都会根据生成的ReadView中的字段进行规则匹配,从而决定返回的数据。接下来看看流程:
事务5第一次进行查询时生成的ReadView以及原数据如下图:
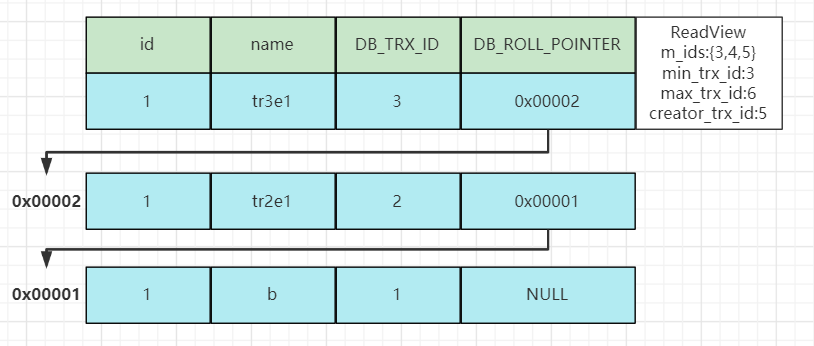
在匹配版本数据前,先与表中数据进行匹配:
该数据对应的DB_TRX_ID为3,此时MVCC就会通过ReadView带着这条数据去进行规则匹配:
首先是第一条规则db_trx_id == creator_trx_id,db_trx_id(3)不等于creator_trx_id(5)故不成立;
第二条规则db_trx_id < min_trx_id,db_trx_id(3)不小于min_trx_id(3)故不成立;
第三条规则db_trx_id > max_trx_id,db_trx_id(3)小于max_trx_id(6)故不成立;
第四条规则min_trx_id <= db_trx_id <= max_trx_id,db_trx_id(3)在min_trx(3)与max_trx_id(6)之间,但是同时处于m_ids(3,4,5)集合之中故也不成立。
经过这次匹配,表中最新的数据无法匹配,故要与MVCC版本链中最上面的数据进行规则匹配
与MVCC版本链中最上方的版本进行匹配:

第一条规则db_trx_id(2)不等于creator_trx_id(5)故不成立;
第二条规则db_trx_id(2)小于min_trx_id(3),该版本的数据满足匹配规则中的第二条,说明数据已经提交,此时匹配将终止并返回这个版本对应的数据。
因为当前事务的隔离级别为READ-COMMITTED(读已提交),所以在每次快照读的时候都会创建一个ReadView,所以事务5第二次进行查询时生成的ReadView以及原数据如下图:
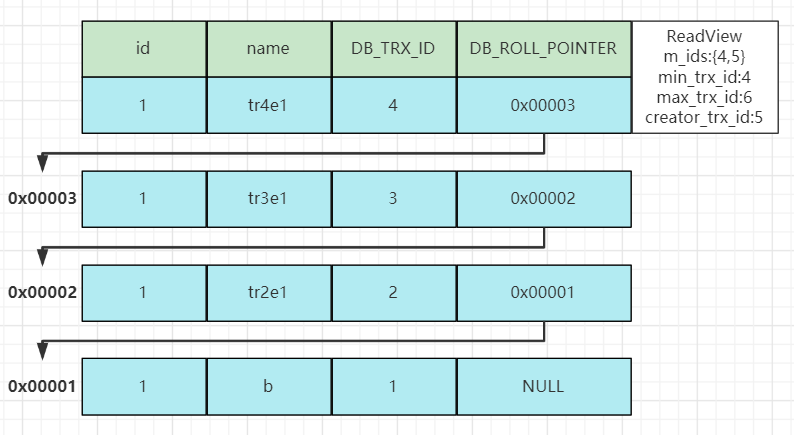
在匹配版本数据前,先与表中数据进行匹配:
该数据对应的DB_TRX_ID为4,此时MVCC就会通过ReadView带着这条数据去进行规则匹配:
首先是第一条规则db_trx_id == creator_trx_id,db_trx_id(4)不等于creator_trx_id(5)故不成立;
第二条规则db_trx_id < min_trx_id,db_trx_id(4)不小于min_trx_id(4)故不成立;
第三条规则db_trx_id > max_trx_id,db_trx_id(4)小于max_trx_id(6)故不成立;
第四条规则min_trx_id <= db_trx_id <= max_trx_id,db_trx_id(4)在min_trx(4)与max_trx_id(6)之间,但是同时处于m_ids(4,5)集合之中故也不成立。
经过这次匹配,表中最新的数据无法匹配,故要与MVCC版本链中最上面的数据进行规则匹配
与MVCC版本链中最上方的版本进行匹配:
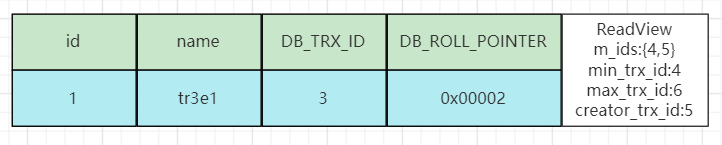
第一条规则db_trx_id(3)不等于creator_trx_id(5)故不成立;
第二条规则db_trx_id(3)小于min_trx_id(4),该版本的数据满足匹配规则中的第二条,说明数据已经提交,此时匹配将终止并返回这个版本对应的数据。
现在来看看REPEATABLE-READ可重复读隔离级别有什么不同的地方。同样,有四个并发事务同时访问一条数据:
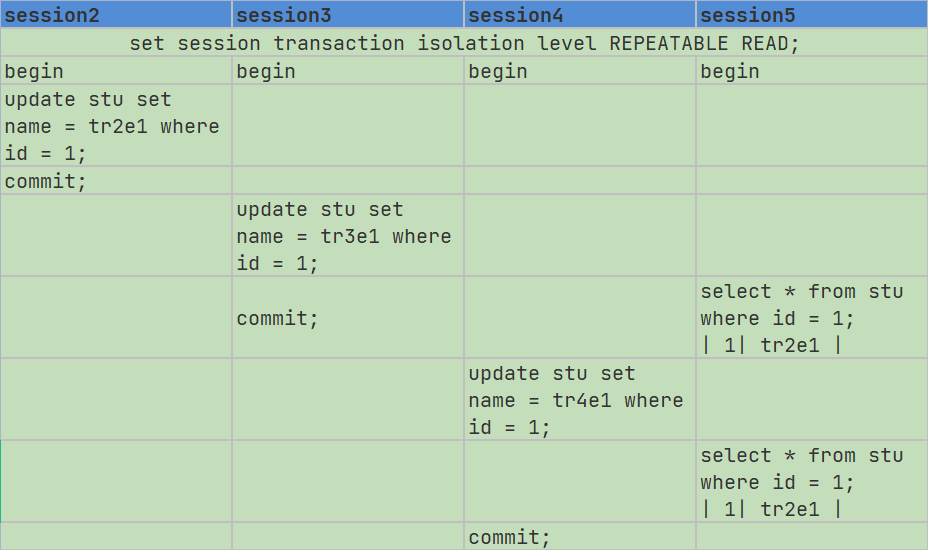
在上述并发事务中,事务5查询了两次id为1的数据,因为当前的隔离级别设置为了REPEATABLE-READ,事务在第一次快照读SQL执行时创建ReadView,后续该事务所有的快照读都复用该ReadView。接下来看看流程:
事务5第一次进行查询时生成的ReadView以及原数据如下图:
在匹配版本数据前,先与表中数据进行匹配:
该数据对应的DB_TRX_ID为3,此时MVCC就会通过ReadView带着这条数据去进行规则匹配:
首先是第一条规则db_trx_id == creator_trx_id,db_trx_id(3)不等于creator_trx_id(5)故不成立;
第二条规则db_trx_id < min_trx_id,db_trx_id(3)不小于min_trx_id(3)故不成立;
第三条规则db_trx_id > max_trx_id,db_trx_id(3)小于max_trx_id(6)故不成立;
第四条规则min_trx_id <= db_trx_id <= max_trx_id,db_trx_id(3)在min_trx(3)与max_trx_id(6)之间,但是同时处于m_ids(3,4,5)集合之中故也不成立。
经过这次匹配,表中最新的数据无法匹配,故要与MVCC版本链中最上面的数据进行规则匹配
与MVCC版本链中最上方的版本进行匹配:
第一条规则db_trx_id(2)不等于creator_trx_id(5)故不成立;
第二条规则db_trx_id(2)小于min_trx_id(3),该版本的数据满足匹配规则中的第二条,说明数据已经提交,此时匹配将终止并返回这个版本对应的数据。
因为当前事务的隔离级别为REPEATABLE-READ(可重复读),所以第二次快照读也会沿用第一次快照读时创建的ReadView,如下:
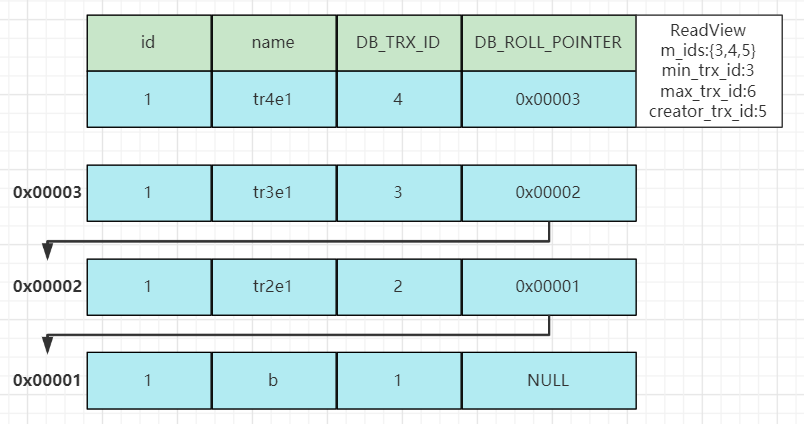
在匹配版本数据前,先与表中数据进行匹配:
该数据对应的DB_TRX_ID为4,此时MVCC就会通过ReadView带着这条数据去进行规则匹配:
首先是第一条规则db_trx_id == creator_trx_id,db_trx_id(4)不等于creator_trx_id(5)故不成立;
第二条规则db_trx_id < min_trx_id,db_trx_id(4)不小于min_trx_id(3)故不成立;
第三条规则db_trx_id > max_trx_id,db_trx_id(4)小于max_trx_id(6)故不成立;
第四条规则min_trx_id <= db_trx_id <= max_trx_id,db_trx_id(4)在min_trx(4)与max_trx_id(6)之间,但是同时处于m_ids(4,5)集合之中故也不成立。
经过这次匹配,表中最新的数据无法匹配,故要与MVCC版本链中最上面的数据进行规则匹配
与MVCC版本链中最上方的版本进行匹配:

第一条规则db_trx_id(3)不等于creator_trx_id(5)故不成立;
第二条规则db_trx_id(3)不小于min_trx_id(4)故不成立;
第三条规则db_trx_id小于max_trx_id(6)故不成立;
第四条规则db_trx_id(3)在min_trx(3)与max_trx_id(6)之间,但是同时处于m_ids(3,4,5)集合之中故也不成立。
经过第二次匹配,MVCC版本链中最上层的数据版本也无法匹配,故要与第二条版本进行匹配
与MVCC版本链中第二条版本进行匹配:

第一条规则db_trx_id(2)不等于creator_trx_id(5)故不成立;
Enjoy GreatSQL ?
GreatSQL是由万里数据库维护的MySQL分支,专注于提升MGR可靠性及性能,支持InnoDB并行查询特性,是适用于金融级应用的MySQL分支版本。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
欢迎来GreatSQL社区发帖提问
https://greatsql.cn/

微信:扫码添加
GreatSQL社区助手微信好友,发送验证信息加群。

我在开发的Rails3网站的一些搜索功能上遇到了一个小问题。我有一个简单的Post模型,如下所示:classPost我正在使用acts_as_taggable_on来更轻松地向我的帖子添加标签。当我有一个标记为“rails”的帖子并执行以下操作时,一切正常:@posts=Post.tagged_with("rails")问题是,我还想搜索帖子的标题。当我有一篇标题为“Helloworld”并标记为“rails”的帖子时,我希望能够通过搜索“hello”或“rails”来找到这篇帖子。因此,我希望标题列的LIKE语句与acts_as_taggable_on提供的tagged_with方法
很难说出这里要问什么。这个问题模棱两可、含糊不清、不完整、过于宽泛或夸夸其谈,无法以目前的形式得到合理的回答。如需帮助澄清此问题以便重新打开,visitthehelpcenter.关闭9年前。我需要从基于ruby的应用程序使用AmazonSimpleNotificationService,但不知道从哪里开始。您对从哪里开始有什么建议吗?
我有一个基本的Rails应用程序测试,其中包含一个用回形针处理的照片字段的用户模型。我创建了能够创建/编辑用户的View,并且照片上传工作正常。Editinguseruser_path(@user),:html=>{:method=>"put",:multipart=>true}do|f|%>|然后,我想将SWFUpload集成到我的应用程序中。我试着按照这个tutorial并运行testproject没有任何成功:浏览按钮不会打开文件对话框,并抛出错误#2176,这是关于selectFiles()方法的。首先,问题是Flashv.10与项目中包含的旧版本SWFUpload(2.1.0
我正在尝试使Authlogic和FacebookConnect(使用Facebook)发挥良好的作用,以便您可以通过正常注册方式或使用Facebookconnect创建帐户。我已经能够让连接以一种方式工作,但注销只会在facebook而不是我的网站上注销,我必须删除cookie才能使其正常工作。任何帮助都会很棒,谢谢! 最佳答案 这是我使用FacebookConnect扩展、authlogic和OpenID制作的示例应用程序。它仍然需要一些工作,但它确实起作用了。http://big-glow-mama.heroku.com/htt
【适用平台】私有云 说明:完成私有云部分是需要两台虚拟机的,分别为controller、compute两个节点,但我们只需配置一台,然后克隆就方便多啦!需要用到的映射文件:关于vm的安装我就不介绍的,毕竟挺简单的,下面让我们看看基于私有云模块中,虚拟机的搭建吧。1、创建新的虚拟机,这里一般我会选择自定义,毕竟后面的配置都要根据私有云相关来进行搭建,会比较复杂。(如果是基础的可以选择典型,典型的满足一般虚拟机的配置) 2、选择稍后安装操作系统会比较方便后续的选择,这里你也可以自己选择自己的映像文件(但不建议) 3、我们是基于Linux下操作的,所以选择Linux客户机操作系统,版本选择自己
亚马逊的documentation提供有关如何使用DynamoDBLocal的Java、.NET和PHP示例。你如何用AWSRubySDK做同样的事情??我的猜测是你在初始化时传入了一些参数,但我不知道它们是什么。dynamo_db=AWS::DynamoDB.new(:access_key_id=>'...',:secret_access_key=>'...') 最佳答案 您使用的是SDK的v1还是v2?您需要找出答案;从上面的简短片段来看,它看起来像v2。为了以防万一,我已经包含了这两个答案。v1答案:AWS.config(us
我想知道这个问题已经有一段时间了,但还没有真正找到答案。为什么要在Rails应用程序中使用Backbone.jsexaclty?是为了扩展功能、为您的JS提供更多MVC模式、构建更好的API......?目前我看不出你为什么要用它来做什么,因为我不认为我理解Backbone.js的概念 最佳答案 Rails的一大优势在于您拥有一个平台和一种语言,可以处理服务器代码并生成客户端代码(使用View)。毫无疑问,一旦您想使用javascript和jquery改善用户体验,这种理论上的优势就会迅速消失。所以实际上你还是要学习两种语言。但仍然
我正在尝试在数组中查找唯一元素并从中删除nil值。我的解决方案如下所示:@array=[1,2,1,1,2,3,4,nil,5,nil,5]@array.uniq.compact#=>[1,2,3,4,5]有没有一种方法可以同时完成这两种操作?如果不是,@array.uniq.compact或@array.compact.uniq哪个高效? 最佳答案 不,但是您可以按照您喜欢的任何顺序附加它们,即array.uniq.compactarray.compact.uniq正如phts所指出的,您可以将一个block传递给uniq,但我认
我正在考虑使用Sequel对于我发现在ActiveRecord中很难制作的一些较复杂的SQL。在同一个项目中使用Sequel和ActiveRecord有什么需要注意的吗?(除了明显的,比如续集中没有AR验证等......) 最佳答案 免责声明:我是Sequel的维护者。在使用Rails时,Sequel很容易与ActiveRecord一起使用或代替ActiveRecord。您必须手动设置数据库连接,但除此之外,用法类似。您的Sequel模型文件位于app/models中,其工作方式类似于ActiveRecord模型。设置数据库连接并不
我是那些没有在他的任何Ruby/RubyonRails工作中使用TextMate的开发人员之一。我在这个领域的特别忠诚在于vim。您最喜欢将vim与Ruby和/或RubyonRails结合使用以尽可能提高工作效率的提示/技巧是什么? 最佳答案 最重要获取rails.vim的副本它在数百万级别上很棒。Readthedoc.提示太多了,:Rviewcustomer,:RSmodelfoo,:Rinvert,gf,:Rextract,:Rake等等。您可能需要NERDTree以及轻松导航(您可以使用:Rtree访问)第二重要在推特上关注t