文章目录
由于顺序表的插入删除操作需要移动大量的元素,影响了运行效率,因此引入了线性表的链式存储——单链表。单链表通过一组任意的存储单元来存储线性表中的数据元素,不需要使用地址连续的存储单元,因此它不要求在逻辑上相邻的两个元素在物理位置上也相邻。
单链表的特点:
对于每个链表结点,除了存放元素自身的信息外,还需要存放一个指向其后继的指针。
单链表中结点类型的描述:
typedef struct LNode{ //定义单链表结点类型
int data; //数据域,可以是别的各种数据类型,本文统一用int类型
struct LNode *next; //指针域
}LNode, *LinkList;
通常会用头指针来标识一个单链表,头指针为NULL时表示一个空表。但是,为了操作方便,会在单链表的第一个结点之前附加一个结点,称为头结点。头结点的数据域可以不设任何信息,也可以记录表长等信息。头结点的指针域指向线性表的第一个元素结点。如下图所示:

头结点和头指针的区分:不管带不带头结点,头指针始终指向单链表的第一个结点,而头结点是带头结点的单链表中的第一个结点,结点内通常不存储信息。
那么单链表的初始化操作就是申请一个头结点,将指针域置空。
void InitList(LinkList &L){
L = (LNode *)malloc(sizeof(LinkList));
L->next = NULL;
}
所谓头插法建立单链表是说将新结点插入到当前链表的表头,即头结点之后。如图所示:
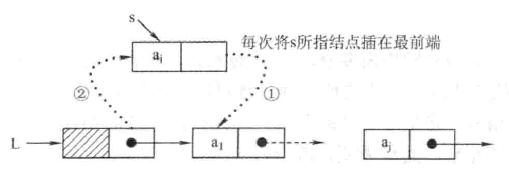
算法思想:首先初始化一个单链表,其头结点为空,然后循环插入新结点*s:将s的next指向头结点的下一个结点,然后将头结点的next指向s。
实现代码:
//头插法建立单链表
LinkList HeadInsert(LinkList &L){
InitList(L); //初始化
int x;
cin>>x;
while(x!=9999){ //输入9999表示结束
LNode *s = (LNode *)malloc(sizeof(LNode));
s->data = x;
s->next = L->next;
L->next = s;
cin>>x;
}
return L;
}
需要指出的是,头插法建立的单链表中结点的次序和输入数据的顺序不一致,是相反的。若希望两者的顺序是一致的,则可采用尾插法建立单链表。
所谓尾插法建立单链表,就是将新结点插入到当前链表的表尾。如下图所示:

算法思想:首先初始化一个单链表,然后声明一个尾指针r,让r始终指向当前链表的尾结点,循环向单链表的尾部插入新的结点*s,将尾指针r的next域指向新结点,再修改尾指针r指向新结点,也就是当前链表的尾结点。最后别忘记将尾结点的指针域置空。
实现代码:
//尾插法建立单链表
LinkList TailInsert(LinkList &L){
InitList(L);
LNode *s,*r=L;
int x;
cin>>x;
while(x!=9999){
s = (LNode *)malloc(sizeof(LNode));
s->data = x;
r->next = s;
r = s;
cin>>x;
}
r->next = NULL;
return L;
}
算法思想:声明一个指针p,从头结点指向的第一个结点开始,如果p不为空,那么就输出当前结点的值,并将p指向下一个结点,直到遍历到最后一个结点为止。
实现代码:
//遍历操作
void PrintList(LinkList L){
LNode *p = L->next;
while(p){
cout<<p->data<<" ";
p = p->next;
}
cout<<endl;
}
算法思想:声明一个指针p,p指向头结点指向的第一个结点,如果p指向的结点不为空,那么长度加一,将p指向下一个结点,直到遍历到最后一个结点为止。
实现代码:
//求单链表的长度
int Length(LinkList L){
LNode *p = L->next;
int len = 0;
while(p){
len++;
p = p->next;
}
return len;
}
查找值x在单链表L中的结点指针。
算法思想:从单链表的第一个结点开始,依次比较表中各个结点的数据域的值,若某结点数据域的值等于x,则返回该结点的指针;若整个单链表中没有这样的结点,则返回空。
实现代码:
//按值查找:查找x在L中的位置
LNode *LocateElem(LinkList L, int x){
LNode *p = L->next;
while(p && p->data != x){
p = p->next;
}
return p;
}
查找单链表L中第 i 个位置的结点指针。
算法思想:从单链表的第一个结点开始,顺着指针域逐个往下搜索,直到找到第 i 个结点为止,否则返回最后一个结点的指针域NULL。
实现代码:
//按位查找:查找在单链表L中第i个位置的结点
LNode *GetElem(LinkList L, int i){
int j=1;
LNode *p = L->next;
if(i==0)return L;
if(i<1)return NULL;
while(p && j<i){
p = p->next;
j++;
}
return p; //如果i大于表长,p=NULL,直接返回p即可
}
这里所说的插入是将值为x的新结点插入到单链表L的第i个位置上。(不包括头结点)
算法思想:从表头开始遍历,查找第 i-1个结点,即插入位置的前驱结点为p,然后令新结点s的指针域指向p的后继结点,再令结点p的指针域指向新结点*s。
实现代码:
//将x插入到单链表L的第i个位置上
void Insert(LinkList &L, int i, int x){
LNode *p = GetElem(L,i-1);
LNode *s = (LNode *)malloc(sizeof(LNode));
s->data = x;
s->next = p->next;
p->next = s;
}
将单链表的第 i 个结点删除。
算法思想:先检查删除位置的合法性,然后从头开始遍历,找到表中的第 i-1 个结点,即被删除结点的前驱结点*p,被删除结点为*q,修改*p的指针域,将其指向*q的下一个结点,最后再释放结点*q的存储空间。
实现代码:
//删除操作:将单链表中的第i个结点删除
void Delete(LinkList &L, int i){
if(i<1 || i>Length(L))
cout<<"delete failed: index is wrong."<<endl;
return;
LNode *p = GetElem(L,i-1);
LNode *q = p->next;
p->next = q->next;
free(q);
}
算法思想:要判断带头结点的单链表是否为空,只需要看头结点的指针域即可,如果头结点的指针域为空,即单链表中只有一个头结点,那么该单链表为空表。
实现代码:
//判空操作
bool Empty(LinkList L){
if(L->next == NULL){
cout<<"L is null"<<endl;
return true;
}else{
cout<<"L is not null"<<endl;
return false;
}
}
完整代码:
#include<bits/stdc++.h>
using namespace std;
typedef struct LNode{
int data;
struct LNode *next;
}LNode, *LinkList;
//初始化
void InitList(LinkList &L){
L = (LNode *)malloc(sizeof(LinkList));
L->next = NULL;
}
//遍历操作
void PrintList(LinkList L){
LNode *p = L->next;
while(p){
cout<<p->data<<" ";
p = p->next;
}
cout<<endl;
}
//求单链表的长度
int Length(LinkList L){
LNode *p = L->next;
int len = 0;
while(p){
len++;
p = p->next;
}
return len;
}
//头插法建立单链表
LinkList HeadInsert(LinkList &L){
InitList(L); //初始化
int x;
cin>>x;
while(x!=9999){
LNode *s = (LNode *)malloc(sizeof(LNode));
s->data = x;
s->next = L->next;
L->next = s;
cin>>x;
}
return L;
}
//尾插法建立单链表
LinkList TailInsert(LinkList &L){
InitList(L);
LNode *s,*r=L;
int x;
cin>>x;
while(x!=9999){
s = (LNode *)malloc(sizeof(LNode));
s->data = x;
r->next = s;
r = s;
cin>>x;
}
r->next = NULL;
return L;
}
//按值查找:查找x在L中的位置
LNode *LocateElem(LinkList L, int x){
LNode *p = L->next;
while(p && p->data != x){
p = p->next;
}
return p;
}
//按位查找:查找在单链表L中第i个位置的结点
LNode *GetElem(LinkList L, int i){
int j=1;
LNode *p = L->next;
if(i==0)return L;
if(i<1)return NULL;
while(p && j<i){
p = p->next;
j++;
}
return p; //如果i大于表长,p=NULL,直接返回p即可
}
//将x插入到单链表L的第i个位置上
void Insert(LinkList &L, int i, int x){
LNode *p = GetElem(L,i-1);
LNode *s = (LNode *)malloc(sizeof(LNode));
s->data = x;
s->next = p->next;
p->next = s;
}
//删除操作:将单链表中的第i个结点删除
void Delete(LinkList &L, int i){
if(i<1 || i>Length(L)){
cout<<"delete failed: index is wrong."<<endl;
return;
}
LNode *p = GetElem(L,i-1);
LNode *q = p->next;
p->next = q->next;
free(q);
}
int main(){
//初始化,尾插法建立单链表
LinkList L = TailInsert(L);
//插入:在第二个位置插入结点,数据域为888,并遍历单链表
Insert(L,2,888);
cout<<"在第二个位置插入888: ";
PrintList(L);
//删除:删除第四个结点
Delete(L,4);
cout<<"删除第四个结点后:";
PrintList(L);
//按位查找:查找第三个结点,并输出其数据域的值
LNode *p = GetElem(L,3);
cout<<"第三个结点的值为:"<<p->data<<endl;
//按值查找:查找数据域为2的结点的指针
LNode *q = LocateElem(L,2);
cout<<"数据为2的结点的下一个结点的值为:"<<q->next->data<<endl;
//输出单链表的长度
cout<<"单链表的长度:"<<Length(L)<<endl;
return 0;
}
执行结果:

在我的gem中,我需要yaml并且在我的本地计算机上运行良好。但是在将我的gem推送到rubygems.org之后,当我尝试使用我的gem时,我收到一条错误消息=>"uninitializedconstantPsych::Syck(NameError)"谁能帮我解决这个问题?附言RubyVersion=>ruby1.9.2,GemVersion=>1.6.2,Bundlerversion=>1.0.15 最佳答案 经过几个小时的研究,我发现=>“YAML使用未维护的Syck库,而Psych使用现代的LibYAML”因此,为了解决
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
查看Ruby的CSV库的文档,我非常确定这是可能且简单的。我只需要使用Ruby删除CSV文件的前三列,但我没有成功运行它。 最佳答案 csv_table=CSV.read(file_path_in,:headers=>true)csv_table.delete("header_name")csv_table.to_csv#=>ThenewCSVinstringformat检查CSV::Table文档:http://ruby-doc.org/stdlib-1.9.2/libdoc/csv/rdoc/CSV/Table.html
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我在Rails工作并有以下类(class):classPlayer当我运行时bundleexecrailsconsole然后尝试:a=Player.new("me",5.0,"UCLA")我回来了:=>#我不知道为什么Player对象不会在这里初始化。关于可能导致此问题的操作/解释的任何建议?谢谢,马里奥格 最佳答案 havenoideawhythePlayerobjectwouldn'tbeinitializedhere它没有初始化很简单,因为你还没有初始化它!您已经覆盖了ActiveRecord::Base初始化方法,但您没有调
我有用于控制用户任务的Rails5API项目,我有以下错误,但并非总是针对相同的Controller和路由。ActionController::RoutingError:uninitializedconstantApi::V1::ApiController我向您描述了一些我的项目,以更详细地解释错误。应用结构路线scopemodule:'api'donamespace:v1do#=>Loginroutesscopemodule:'login'domatch'login',to:'sessions#login',as:'login',via::postend#=>Teamroutessc
我正在阅读一本关于Ruby的书,作者在编写类初始化定义时使用的形式与他在本书前几节中使用的形式略有不同。它看起来像这样:classTicketattr_accessor:venue,:datedefinitialize(venue,date)self.venue=venueself.date=dateendend在本书的前几节中,它的定义如下:classTicketattr_accessor:venue,:datedefinitialize(venue,date)@venue=venue@date=dateendend在第一个示例中使用setter方法与在第二个示例中使用实例变量之间是
在Ruby中是否有Gem或安全删除文件的方法?我想避免系统上可能不存在的外部程序。“安全删除”指的是覆盖文件内容。 最佳答案 如果您使用的是*nix,一个很好的方法是使用exec/open3/open4调用shred:`shred-fxuz#{filename}`http://www.gnu.org/s/coreutils/manual/html_node/shred-invocation.html检查这个类似的帖子:Writingafileshredderinpythonorruby?
我正在尝试找到一种方法来规范化字符串以将其作为文件名传递。到目前为止我有这个:my_string.mb_chars.normalize(:kd).gsub(/[^\x00-\x7F]/n,'').downcase.gsub(/[^a-z]/,'_')但第一个问题:-字符。我猜这个方法还有更多问题。我不控制名称,名称字符串可以有重音符、空格和特殊字符。我想删除所有这些,用相应的字母('é'=>'e')替换重音符号,并将其余的替换为'_'字符。名字是这样的:“Prélèvements-常规”“健康证”...我希望它们像一个没有空格/特殊字符的文件名:“prelevements_routin
我正在写一篇关于在Ruby中几乎一切都是对象的博客文章,我试图通过以下示例来展示这一点:classCoolBeansattr_accessor:beansdefinitialize@bean=[]enddefcount_beans@beans.countendend所以从类中我们可以看出它有4个方法(当然,除非我错了):它可以在创建新实例时初始化一个默认的空bean数组它可以计算它有多少个bean它可以读取它有多少个bean(通过attr_accessor)它可以向空数组写入(或添加)更多bean(也通过attr_accessor)但是,当我询问类本身它有哪些实例方法时,我没有看到默认