过了个双休来到公司,同时发现Linux终端的服务器状态中根目录空间直接爆满100%,周五走之前根目录仅仅使用了59%,同时项目服务的后台不停的有日志打印,而且测试的小伙伴说系统登录不上去了。下面记录一下个人排查并解决这个问题的全过程。
这个服务器部署了两个项目的后台服务,一个是在本机安装了.NET Runtime后部署的.NET Web API以及Dapr应用,另一个是Docker部署的Java项目(微服务),两组后台服务均使用到了消息队列,一组使用到了RabbitMQ,另一组则使用到了RabbitMQ和Kafka。
因为看到后台不停的打印出日志,后台日志服务使用到了Kafka,日志也显示Kafka的一些警告信息。因此我首先想到是不是队列一直消费失败,然后不断尝试、不断报错、不停打印日志写入导致空间爆满。
进入到项目后台的容器编排配置目录,使用 du -sh *查看空间占用,删除了Kafka、ES、RabbitMQ等一些中间件的日志后仅仅腾出了2G空间,服务部署也有俩月了,感觉这个大小属于正常情况,因此根目录爆满可能并非这个原因。
此处排查主要使用du -sh命令,大概介绍参考:
du -ach * #这个能看到当前目录下的所有文件占用磁盘大小和总大小
du -sh #查看当前目录总大小
du -sh * #查看所有子目录大小
du -sh ./* #查看当前目录下所有文件/文件夹的大小
lsof | grep delete #如果怀疑删掉的数据还在占用磁盘空间试试这个
kill -9 pid #结束掉进程就能释放磁盘空间了
du -sh命令介绍
使用du -sh *命令查看根目录下所有子目录的大小
[root@localhost /]# du -sh *
0 bin
149M boot
0 dev
41M dockercompose
8.8G dockerfile
37M etc
36G home
32K html
0 lib
0 lib64
0 media
0 mnt
0 opt
du: 无法访问"proc/3514/task/3514/fd/4": 没有那个文件或目录
du: 无法访问"proc/3514/task/3514/fdinfo/4": 没有那个文件或目录
du: 无法访问"proc/3514/fd/4": 没有那个文件或目录
du: 无法访问"proc/3514/fdinfo/4": 没有那个文件或目录
0 proc
1.2G publish
205M root
763M run
0 sbin
0 srv
0 sys
4.0K tmp
3.1G usr
51G var
这里需要关注的两个点:
(1)为什么出现"du: 无法访问"proc/3514/task/3514/fd/4": 没有那个文件或目录"的输出?(后面再看)
(2)哪些目录占用空间巨大?
为什么 /var 目录占用了51个G?本身根目录是/dev/mapper/centos-root的挂载点,因此我怀疑激增的数据就是在var目录中,使用du -sh *命令进行排查
[root@localhost /]# cd var
[root@localhost var]# ls
adm cache crash db empty games gopher kerberos lib local lock log mail nis opt preserve run spool tmp yp
[root@localhost var]# du -sh *
0 adm
204M cache
0 crash
8.0K db
0 empty
0 games
0 gopher
0 kerberos
51G lib
0 local
0 lock
41M log
0 mail
0 nis
0 opt
0 preserve
0 run
16K spool
0 tmp
0 yp
lib目录按照过往的经验一般就是”libraries“,存放一些库、依赖等,但是此处空间大小感觉不太对,上网搜了一下,对linux系统下var/lib的作用是这样描述的:
程序本身执行的过程中,需要使用到的数据文件放置的目录。在此目录下各自的软件应该要有各自的目录。 举例来说,MySQL的数据库放置到/var/lib/mysql/而rpm的数据库则放到/var/lib/rpm去
Linux 系统的/var目录 原创
进入到/var/lib下再次执行du -sh *命令进行排查
[root@localhost var]# cd lib/
[root@localhost lib]# ls
alternatives chrony dbus docker initramfs machines NetworkManager plymouth postfix rpm-state selinux systemd tuned yum
authconfig containerd dhclient games logrotate misc os-prober polkit-1 rpm rsyslog stateless tpm vmware zerotier-one
[root@localhost lib]# du -sh *
28K alternatives
0 authconfig
4.0K chrony
1.1M containerd
0 dbus
0 dhclient
51G docker
0 games
0 initramfs
4.0K logrotate
0 machines
0 misc
16K NetworkManager
0 os-prober
4.0K plymouth
0 polkit-1
4.0K postfix
110M rpm
0 rpm-state
4.0K rsyslog
0 selinux
0 stateless
64K systemd
0 tpm
0 tuned
0 vmware
11M yum
120K zerotier-one
发现docker目录空间占用巨大,同时服务器主要用于部署Java服务(使用Docker打包、发布、部署),现在就将主要问题定位到了docker上。
进入到var/lib/docker目录,再次执行du -sh *命令进行排查
[root@localhost lib]# cd docker
[root@localhost docker]# du -sh *
416K buildkit
18G containers
24M image
172K network
32G overlay2
0 plugins
0 runtimes
0 swarm
0 tmp
0 trust
1.4G volumes
为什么docker的overlay2这个目录空间达到32G?到这个环节时基本能够确定是Docker相关的问题了。
通过上面的逐项排查,两天内根目录的空间暴增这个情况基本定位到Docker上。
首先使用Docker内置命令进行Docker空间分布的分析。
docker system df
Docker 的内置 CLI 指令 docker system df ,可用于查询镜像(Images)、容器(Containers)和本地卷(Local Volumes)等空间使用大户的空间占用情况。
Docker 空间使用分析与清理
执行命令得到如下输出:
[root@localhost lib]# docker system df
TYPE TOTAL ACTIVE SIZE RECLAIMABLE
Images 34 24 13.85GB 6.31GB (45%)
Containers 24 24 1.128GB 0B (0%)
Local Volumes 14 9 2.086GB 536.9MB (25%)
Build Cache 13 0 0B 0B
其中”RECLAIMABLE“表示可回收的
很奇怪的一件事,一共有34个镜像,但是使用的只有24个,是不是说那些没有使用到的镜像就可以删除掉腾出空间了?
使用docker system df -v 命令查看docker空间占用的详细参数

通过”CONTAINERS“列(此镜像的容器数)发现一些镜像并没有使用到,出现这种未使用的镜像的原因是:
(1)项目需求制作服务的基础镜像时形成的冗余镜像,可删除
(2)原本由docker命令部署的容器改为了使用docker-compose部署后之前部署时拉取的重复镜像,可删除
但我觉得这些都不是一个周末后”/“目录从67%到100%爆满的原因。
先清理一下Docker的冗余吧,docker提供了docker system prune空间清理命令
docker system prune 自动清理说明:
- 该指令默认会清除所有如下资源:
- 已停止的容器(container)
- 未被任何容器所使用的卷(volume)
- 未被任何容器所关联的网络(network)
- 所有悬空镜像(image)。
- 该指令默认只会清除悬空镜像,未被使用的镜像不会被删除。
- 添加 -a 或 --all 参数后,可以一并清除所有未使用的镜像和悬空镜像。
- 可以添加 -f 或 --force 参数用以忽略相关告警确认信息。
- 指令结尾处会显示总计清理释放的空间大小
[root@localhost lib]# docker system prune
WARNING! This will remove:
- all stopped containers
- all networks not used by at least one container
- all dangling images
- all dangling build cache
Are you sure you want to continue? [y/N] y
Total reclaimed space: 0B
因为记录之前做了一次清理,当时清理腾出了不到1g的空间。添加-a参数清除所有未使用的镜像和悬空镜像,腾出大约2.49g的空间,但是距离两天前根目录69%的存储还是有一定距离。

此时再使用docker system df命令查看docker的空间分析信息是这样的,似乎镜像于容器本身没什么问题了
[root@localhost docker]# docker system df
TYPE TOTAL ACTIVE SIZE RECLAIMABLE
Images 24 24 11.36GB 796.3MB (7%)
Containers 24 24 1.129GB 0B (0%)
Local Volumes 14 9 2.086GB 536.9MB (25%)
Build Cache 0 0 0B 0B
再次执行du -sh *命令进行排查
[root@localhost docker]# du -sh *
404K buildkit
19G containers
21M image
172K network
30G overlay2
0 plugins
0 runtimes
0 swarm
0 tmp
0 trust
1.4G volumes
很奇怪的是,其中overlayer2目录仅仅比第一次少了2g,也清理了其它没用的镜像以及日志,那(92%-69%)的23%的根目录空间占用在哪里??问题很大可能就是overlayer2这个目录了。
Docker目录为:

科普内容就不一一罗列了,Docker的存储目录介绍参考 docker存储目录详解。
然后搜索了关于”docker overlayer2 目录空间暴增“的内容,在下面这篇帖子得到如下答案,Docker Overlay2磁盘空间占用过大清理的方法实现 帖子中第一种情况,对帖子内容进行了概括,大概如下:
情况1: docker中部署的系统中日志内容的不断扩大 。这种情况可以手动、定时进行清理。
对于/var/lib/docker/overlay2 空间占用,存在很多误导的方法是去迁移路径等。 其实磁盘空间的占用和overlay没关系,它的使用和真实的disk使用相同,overlay只是一个docker的虚拟文件系统,真实的文件系统是前者/dev/vda1,可以看到路径所指为根目录。所以,通过该目录去查找哪里占用资源过大。占用大量空间的日志文件位于containers下…
也就是说,containers目录下是以容器id为命名的目录,存放有该容器的一些配置文件以及日志文件

[root@localhost containers]# cd 8f64f9ed27cc12e5233f877a22a461b7b47d11525cd8069b087333835f9ff802/
[root@localhost 8f64f9ed27cc12e5233f877a22a461b7b47d11525cd8069b087333835f9ff802]# ls
8f64f9ed27cc12e5233f877a22a461b7b47d11525cd8069b087333835f9ff802-json.log config.v2.json hostname mounts resolv.conf.hash
checkpoints hostconfig.json hosts resolv.conf
其中日志文件以容器ID-json.log的结构命名,例如8f64f9ed27cc12e5233f877a22a461b7b47d11525cd8069b087333835f9ff802-json.log
在/var/libs/docker/container目录下,通过这个命令查看所有容器的日志文件大小
ls -lh $(find /var/lib/docker/containers/ -name *-json.log)
发现了异常文件!为什么这个容器的日志文件大小是18G?!

查看这个ID发现是PG数据库

查看容器的日志(最后100条),发现不断再刷新,提示组合键重复,我找到原因了。我在上周四部署了另一个项目的服务后台,这个后台服务消费RabbitMq消息失败了,由于MQ的ACK机制,一直重复传递推送,一直插入失败,一直记录日志,导致两天后存储爆满。
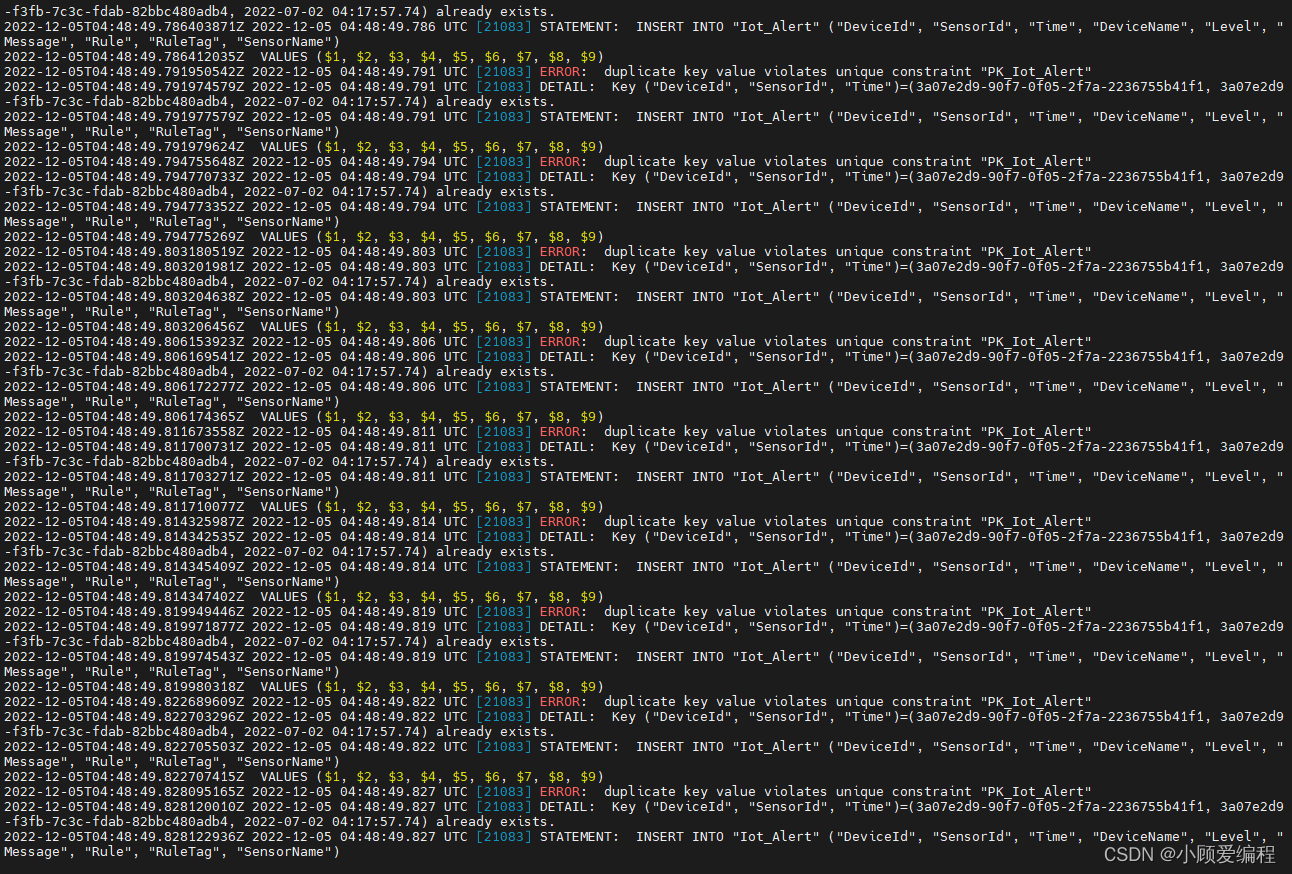
针对于这个问题的实际情况,我首先停止了另外一个Consumer服务,然后清空了容器的日志文件。当然后续也需要针对这个队列的消费者服务进行一些异常的处理,避免此类情况发生。
清空Docker容器的日志文件,truncate截断命令。
truncate -s 0 /var/lib/docker/containers/*/*-json.log
清理docker 容器下面的log
执行完后,空间已经腾出,根目录恢复到之前的水平。

这次事件暴露了很多个人的问题:
(1)消息队列的ACK机制,例如后台出现异常时不会进行确认,会重复发送执行,Consumer端的不当处理可能会导致服务器问题,因此需要加深对ACK机制的深入。
(2)Linux的磁盘分区和挂载需要加深学习。
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
我正在使用active_admin,我在Rails3应用程序的应用程序中有一个目录管理,其中包含模型和页面的声明。时不时地我也有一个类,当那个类有一个常量时,就像这样:classFooBAR="bar"end然后,我在每个必须在我的Rails应用程序中重新加载一些代码的请求中收到此警告:/Users/pupeno/helloworld/app/admin/billing.rb:12:warning:alreadyinitializedconstantBAR知道发生了什么以及如何避免这些警告吗? 最佳答案 在纯Ruby中:classA
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo