- 一:flink监控简介
- 二:Flink的Metric架构
- 三: prometheus + grafana 的 对 flink 的监控部署构建
Flink提供的Metrics可以在Flink内部收集一些指标,通过这些指标让开发人员更好地理解作业或集群的状态。由于集群运行后很难发现内部的实际状况,跑得慢或快,是否异常等,开发人员无法实时查看所有的Task日志,比如作业很大或者有很多作业的情况下,该如何处理?此时Metrics可以很好的帮助开发人员了解作业当前状况。对于很多大中型企业来讲,我们对进群的作业进行管理时,更多的是关心作业精细化实时运行状态。例如,实时吞吐量的同比环比、整个集群的任务运行概览、集群水位,或者监控利用 Flink 实现的 ETL 框架的运行情况等,这时候就需要设计专门的监控系统来监控集群的任务作业情况。
Flink Metrics是Flink实现的一套运行信息收集库,我们不但可以收集Flink本身提供的系统指标,比如CPU、内存、线程使用情况、JVM垃圾收集情况、网络和IO等,还可以通过继承和实现指定的类或者接口打点收集用户自定义的指标。
通过使用Flink Metrics我们可以轻松地做到:
• 实时采集Flink中的Metrics信息或者自定义用户需要的指标信息并进行展示;
• 通过Flink提供的Rest API收集这些信息,并且接入第三方系统进行展示。
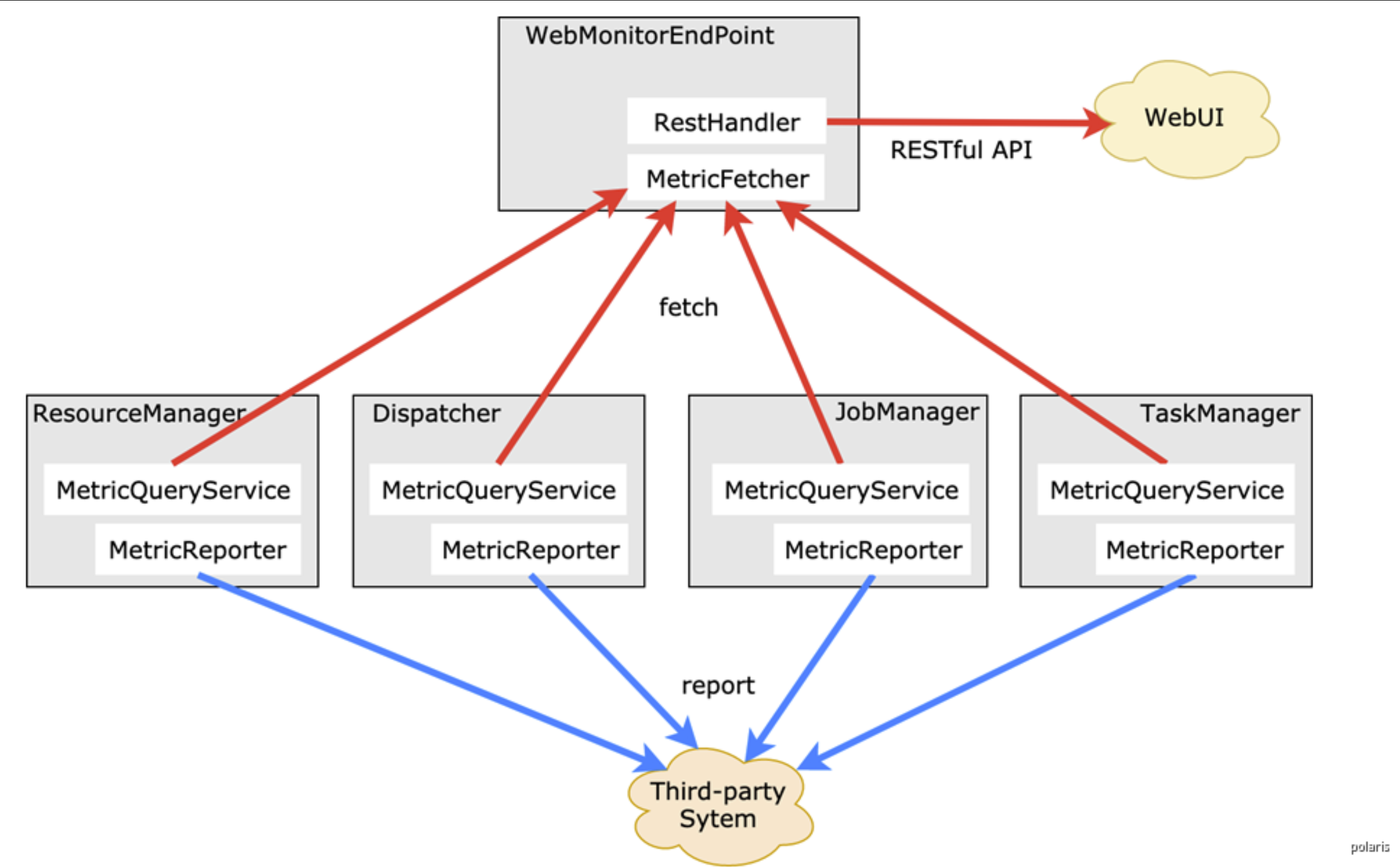
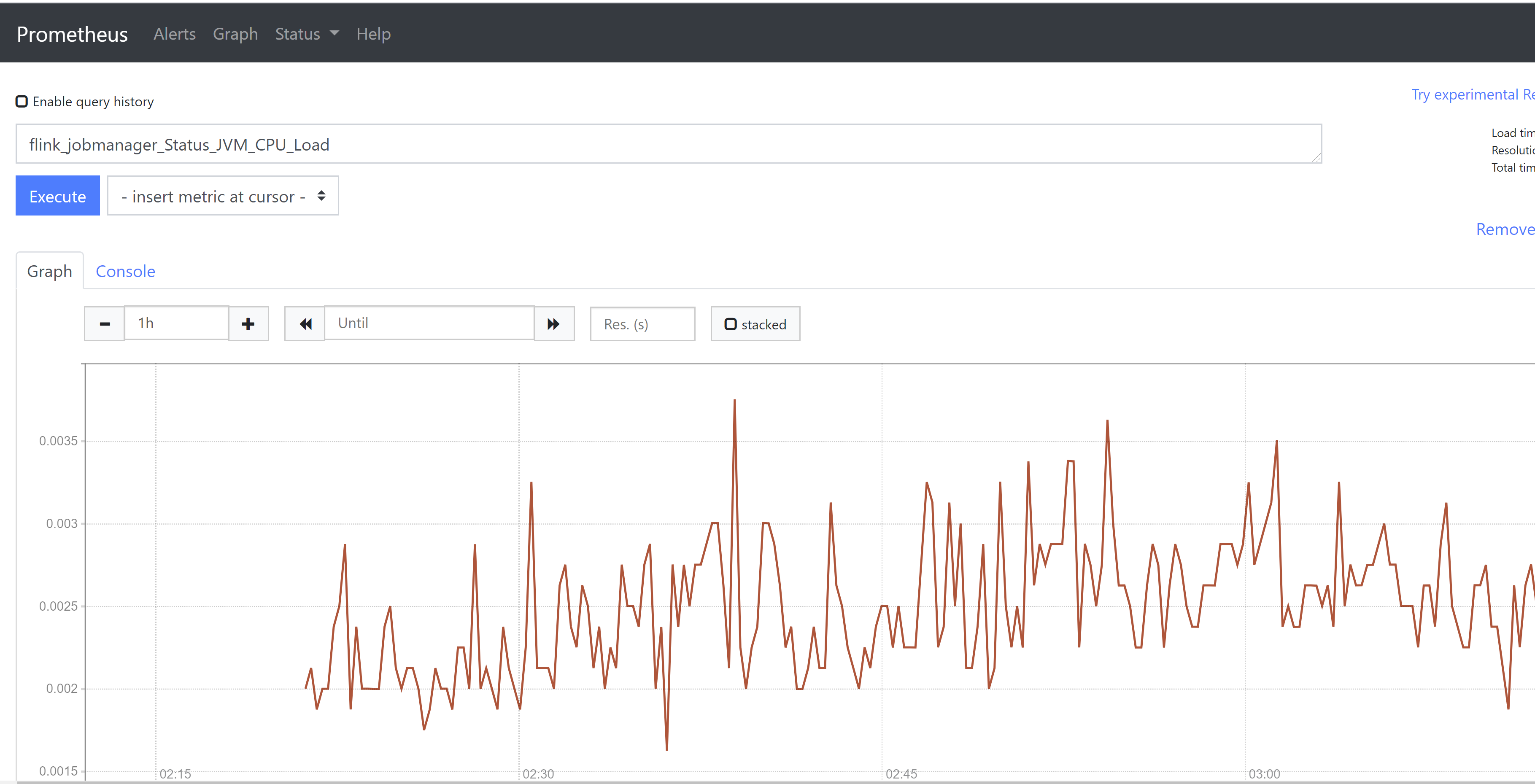
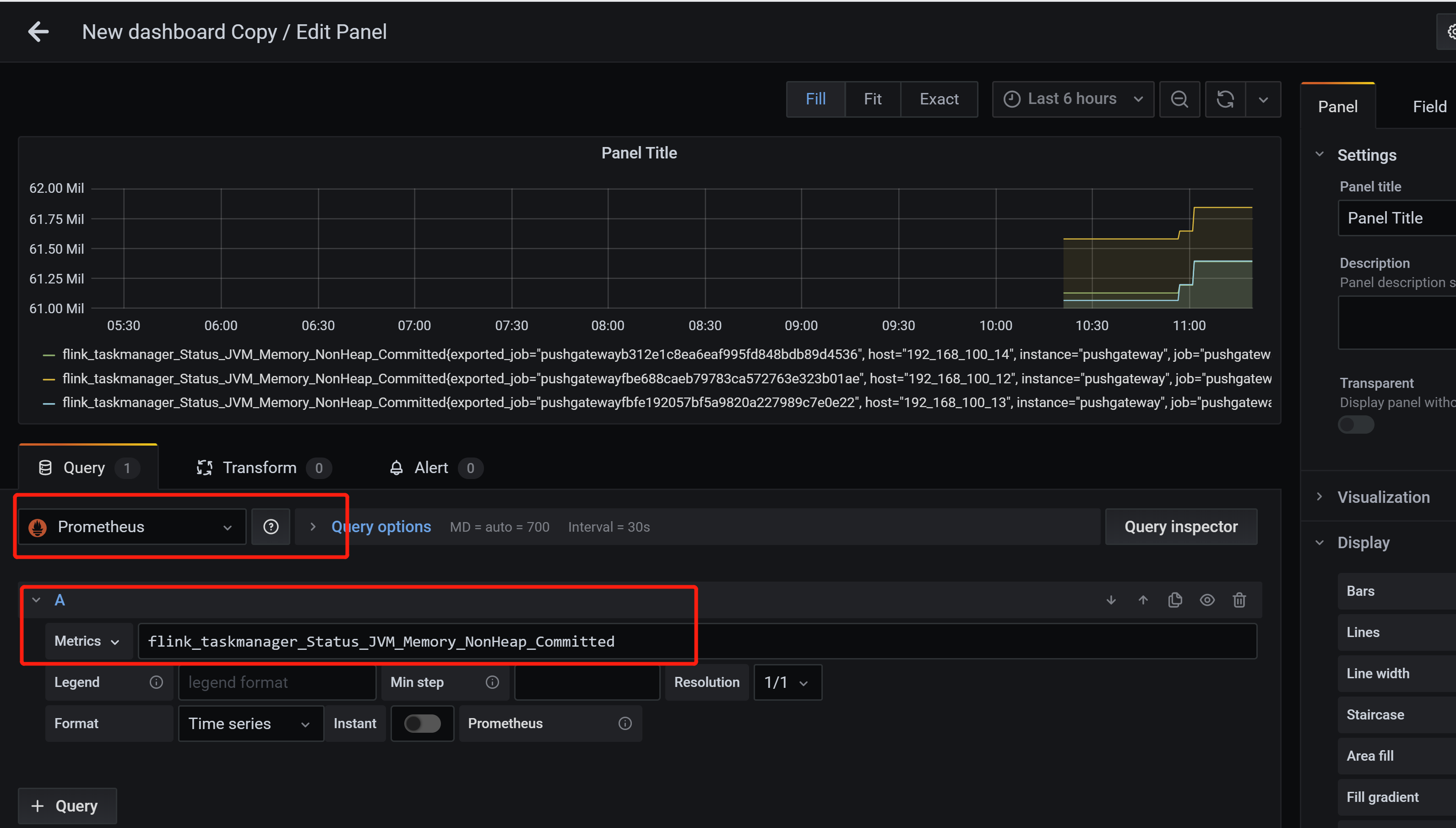
从Flink Metrics架构来看,指标获取方式有两种。一是REST-ful API,Flink Web UI中展示的指标就是这种形式实现的。二是reporter,通过reporter可以将metrics发送给外部系统。Flink内置支持JMX、Graphite、Prometheus等系统的reporter,同时也支持自定义reporter。
由于Flink Web UI所提供的metrics数量较少,也没有时序展示,无法满足实际生产中的监控需求。Prometheus+Grafana是业界十分普及的开源免费监控体系,上手简单,功能也十分完善。
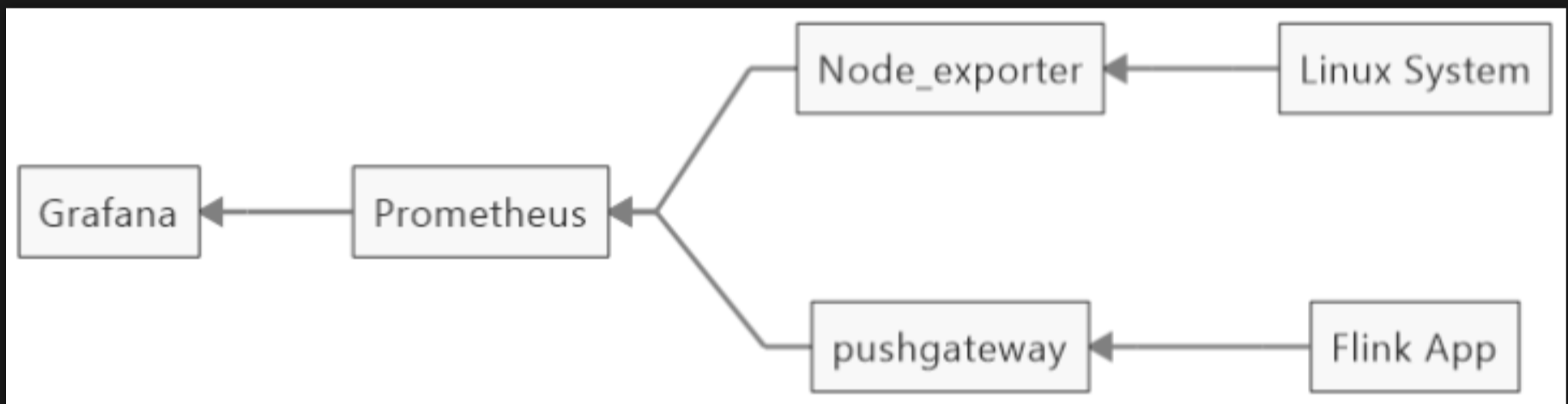
Prometheus本身也是一个导出器(exporter),提供了关于内存使用、垃圾收集以及自身性能
与健康状态等各种主机级指标。
prometheus官网下载址:
https://prometheus.io/download/
wget https://github.com/prometheus/prometheus/releases/download/v2.21.0/prometheus-2.21.0.linux-amd64.tar.gz
# tar zxvf prometheus-2.21.0.linux-amd64.tar.gz
# mv prometheus-2.21.0.linux-amd64 /usr/local/prometheus
# chmod +x /usr/local/prometheus/prom*
# cp -rp /usr/local/prometheus/promtool /usr/bin/
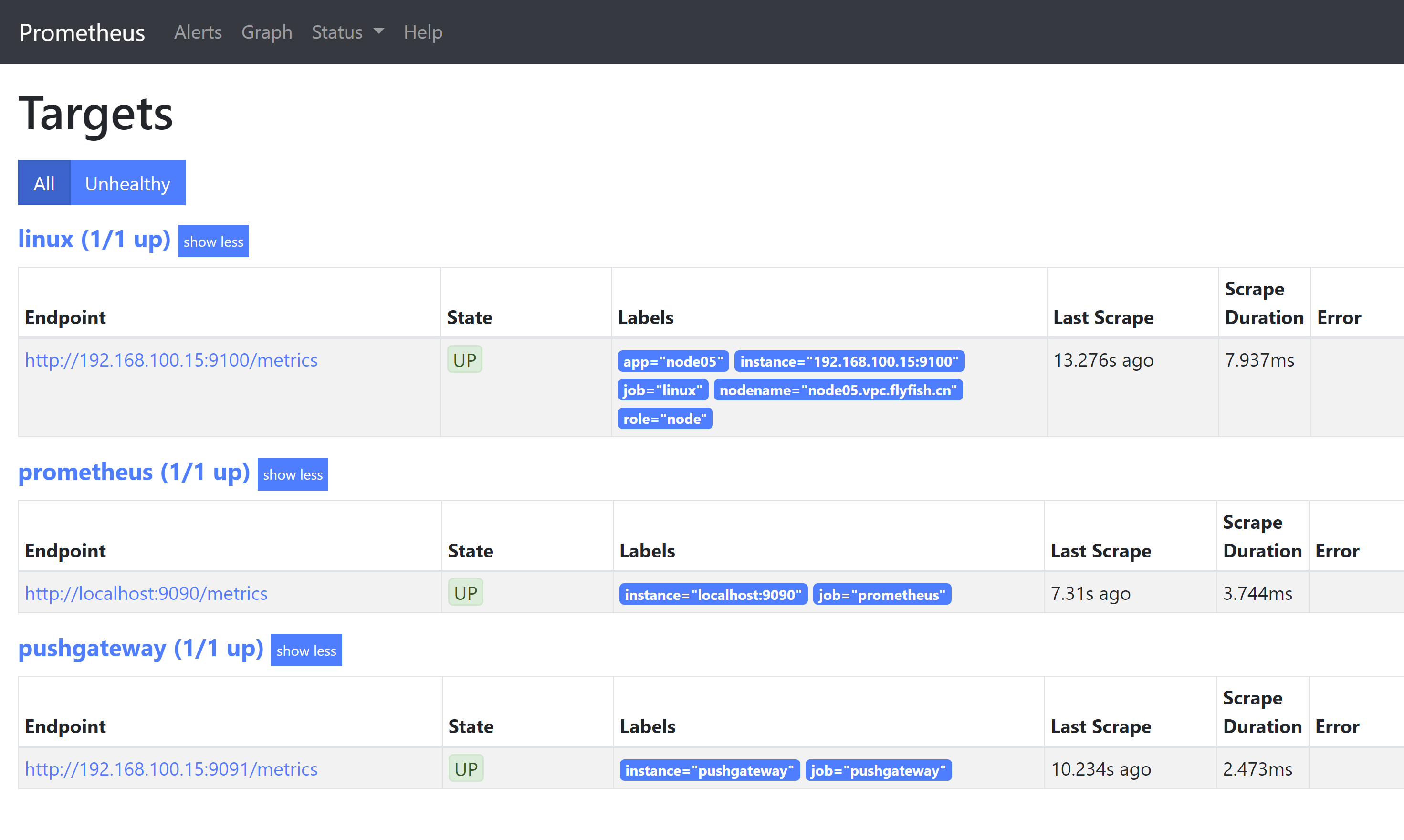
最后 加上pushgateway 收集:
此处将pushgateway 与 prometheus 安装在一台机器上面
- job_name: 'linux'
static_configs:
- targets: ['192.168.100.15:9100']
labels:
app: node05
nodename: node05.vpc.flyfish.cn
role: node
- job_name: 'pushgateway'
static_configs:
- targets: ['192.168.100.15:9091']
labels:
instance: 'pushgateway'
prometheus 的开机启动:
cat > /usr/lib/systemd/system/prometheus.service <<EOF
[Unit]
Description=Prometheus
[Service]
ExecStart=/usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml --
storage.tsdb.path=/usr/local/prometheus/data --web.enable-lifecycle --storage.tsdb.retention.time=180d
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
---
#service prometheus start
#chkconfig prometheus on
node_exporter :
#tar -zxvf node_exporter-1.0.1.linux-amd64.tar.gz
#mv node_exporter-1.0.1.linux-amd64 /usr/local/node_exporter
#/usr/local/node_exporter/node_exporter &
pushgateway:
#tar -zxvf pushgateway-1.2.0.linux-amd64.tar.gz
#mv pushgateway-1.2.0.linux-amd64 /usr/local/pushgateway/
# /usr/local/pushgateway/pushgateway &
flink-conf.yaml
到最后加上
----
metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter
metrics.reporter.promgateway.host: 192.168.100.15
metrics.reporter.promgateway.port: 9091
metrics.reporter.promgateway.jobName: pushgateway
metrics.reporter.promgateway.randomJobNameSuffix: true
metrics.reporter.promgateway.deleteOnShutdown: true
----
然后同步所有flink的 works 节点
重启flink 的集群
./stop-cluster.sh
./start-cluster.sh
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
在控制台中反复尝试之后,我想到了这种方法,可以按发生日期对类似activerecord的(Mongoid)对象进行分组。我不确定这是完成此任务的最佳方法,但它确实有效。有没有人有更好的建议,或者这是一个很好的方法?#eventsisanarrayofactiverecord-likeobjectsthatincludeatimeattributeevents.map{|event|#converteventsarrayintoanarrayofhasheswiththedayofthemonthandtheevent{:number=>event.time.day,:event=>ev
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
这是一道面试题,我没有答对,但还是很好奇怎么解。你有N个人的大家庭,分别是1,2,3,...,N岁。你想给你的大家庭拍张照片。所有的家庭成员都排成一排。“我是家里的friend,建议家庭成员安排如下:”1岁的家庭成员坐在这一排的最左边。每两个坐在一起的家庭成员的年龄相差不得超过2岁。输入:整数N,1≤N≤55。输出:摄影师可以拍摄的照片数量。示例->输入:4,输出:4符合条件的数组:[1,2,3,4][1,2,4,3][1,3,2,4][1,3,4,2]另一个例子:输入:5输出:6符合条件的数组:[1,2,3,4,5][1,2,3,5,4][1,2,4,3,5][1,2,4,5,3][
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
我有一个像这样的ruby类:require'logger'classTdefdo_somethinglog=Logger.new(STDERR)log.info("Hereisaninfomessage")endend测试脚本行如下:#!/usr/bin/envrubygem"minitest"require'minitest/autorun'require_relative't'classTestMailProcessorClasses当我运行这个测试时,out和err都是空字符串。我看到消息打印在stderr上(在终端上)。有没有办法让Logger和capture_io一起玩得
我正在构建一个小部件来显示奥运会的奖牌数。我有一个“国家”对象的集合,其中每个对象都有一个“名称”属性,以及奖牌计数的“金”、“银”、“铜”。列表应该排序:1.首先是奖牌总数2.如果奖牌相同,按类型分割(金>银>铜,即2金>1金+1银)3.如果奖牌和类型相同,则按字母顺序子排序我正在用ruby做这件事,但我想语言并不重要。我确实找到了一个解决方案,但如果感觉必须有更优雅的方法来实现它。这是我做的:使用加权奖牌总数创建一个虚拟属性。因此,如果他们有2个金牌和1个银牌,加权总数将为“3.020100”。1金1银1铜为“3.010101”由于我们希望将奖牌数排序为最高的,因此列表按降序排