关系型数据库还有一个重要的概念:Join(连接)。使用Join有好处,也会坏处,只有我们明白了其中的原理,才能更多的使用Join。切记不可以:
业务之上,再复杂的查询也在一个连表语句中完成。
敬而远之,DBA每次上报的慢查询都是连接查询导致的,我再也不用了。
我们先来创建两个简单的表,再初始化一些数据
CREATE TABLE t1 (m1 int, n1 varchar(1));
CREATE TABLE t2 (m2 int, n2 varchar(1));
INSERT INTO t1 VALUES(1, 'a'), (2 , 'b') ,(3 ,'c') ;
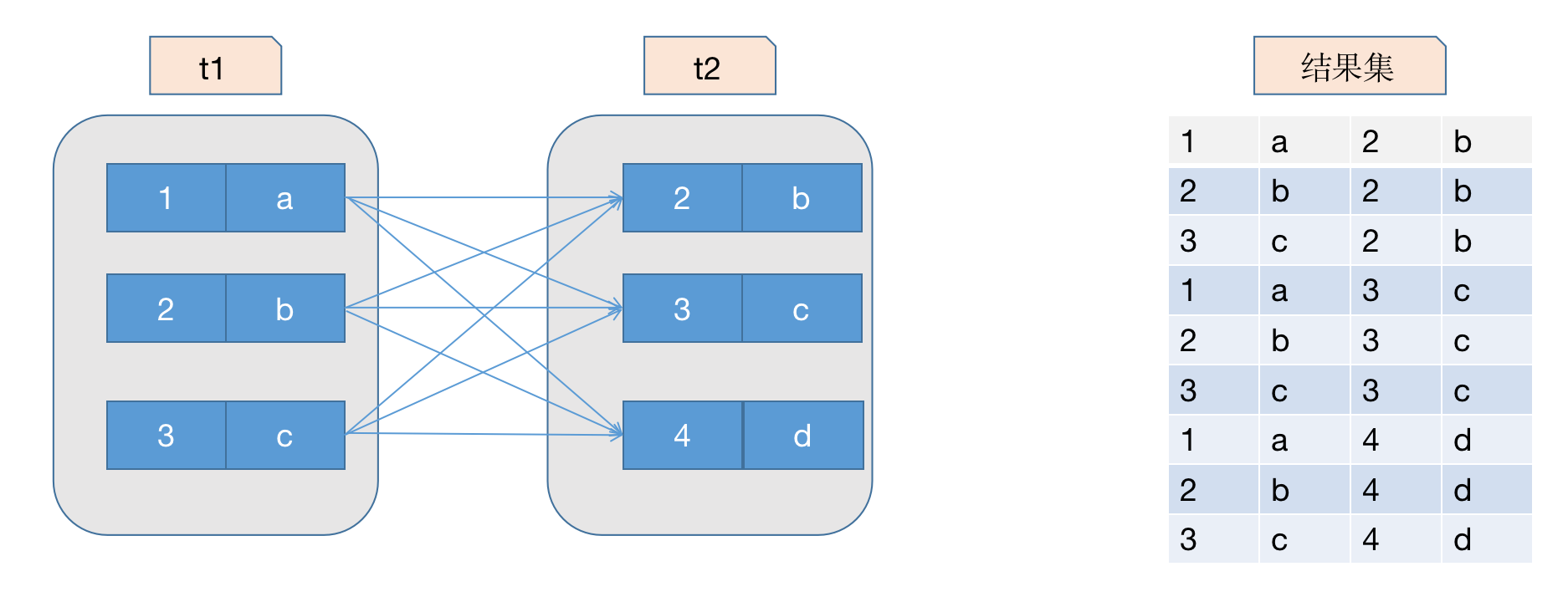
INSERT INTO t2 VALUES(2 , 'b'), (3 , 'c '),(4 , 'd');从本质上来说,连接就是把各个表的数据都取出来进行匹配,t1 和 t2 的两个表连接起来就是这样的:
连接语法:
select * from t1, t2;如果乐意,我们可以连接任意数量的表。但是如果不加任何限制条件的话,这个数据量是非常大的,我们现实中使用都是会加上限制条件的。我们来看下下面这条语句
select * from t1,t2 where t1.m1 > 1 and t1.m1 = t2.m2 and t2.n2 = 'c';这个连接查询的执行过程大致如下
首先确定第一个需要查询 表称为驱动表(t1)
步骤1中从驱动表 (t1) 中每获得一条记录,都要去被驱动表 (t2) 中查询匹配。
从上面的步骤,可以看出上述的连表查询我们需要查询一次t1,两次t2。也就是说,两表的连接查询中,需要查询一次驱动表,被驱动表需要查询多次。
这里需要注意下,并不是将所有满足条件的驱动表记录先查询出来放到一个地方,然后再去被驱动表中查询,(如果满足条件的驱动表中的数据非常多,那要需要多大的内存呀。) 所以是每获得一条驱动表记录就去被驱动表中查询。
我们再来创建两个表,并插入一些数据
CREATE TABLE student (
number INT NOT NULL Auto_increment comment'学号',
name varchar (5) COMMENT '姓名',
major varchar (30) comment '专业',
PRIMARY KEY (number));
CREATE TABLE score (
number INT comment'学号',
subject varchar (30) COMMENT '科目',
score TINYINT comment '成绩',
PRIMARY KEY (number, subject));
INSERT INTO `student` (`number`, `name`, `major`)
VALUES ('20230301', '小赵', '计算机科学');
INSERT INTO `student` (`number`, `name`, `major`)
VALUES ('20230302', '小钱', '通信');
INSERT INTO `student` (`number`, `name`, `major`)
VALUES ('20230303', '小孙', '土木工程');
INSERT INTO `score` (`number`, `subject`, `score`)
VALUES ('20230301', '高等数学', '60');
INSERT INTO `score` (`number`, `subject`, `score`)
VALUES ('20230301', '英语', '70');
INSERT INTO `score` (`number`, `subject`, `score`)
VALUES ('20230302', '高等数学', '80');
INSERT INTO `score` (`number`, `subject`, `score`)
VALUES ('20230302', '英语', '90');如果我们想把所有的学生的成绩都查出来,只需要这样执行:
select s1.number, s1.name, s1.major, s2.subject, s2.score
from student as s1 , score as s2
where s1.number = s2.number;有个问题就是小孙因为某些原因没有参加考试,所以在结果表中没有对应 的成绩记录。如果老师想查看所有学生的考试成绩,即使是缺考的学生 他们的成绩也应该展示出来。
为了解决这个问题,就有了内连接和外连接的概念:
MySQL 中,根据选取的驱动表的不同,外连接可以细分为
当我们使用外连接的时候 有时候我们也不想把驱动表的全部记录都加入到最后的结果集中,这个时候我们就要使用过滤条件了。
• WHERE 子句中的过滤条件:不论是内连接还是外连接 凡是不符合 WHERE 子句中过滤条件的记录都不会被加入到最后的结果集。
• ON 子句中的过滤条件:对于外连接的驱动表中的记录来说,如果无法在被驱动表中找到匹配 ON 子句 中过滤条件的记录 那么该驱动表记录仍然会被加入到结果集中,对应的被驱动表记录的各个字段使用NULL 值填充。
所以上述的需求我们可以左查询这样来做:
select s1.number, s1.name, s1.major, s2.subject, s2.score
from student as s1 left join score as s2
on s1.number = s2.number;语法:
#左连接
select * from t1 left join t2 on '连接条件' where '普通过滤条件'
#右连接
select * from t1 right join t2 on '连接条件' where '普通过滤条件'内连接的另一种写法,也是常用写法
select s1.number, s1.name, s1.major, s2.subject, s2.score
from student as s1 inner join score as s2
where s1.number = s2.number;语法:
select * from t1 inner join t2 on '连接条件' where '过滤条件'上述说了这么多,知识简单回顾一下连接,左连接,右连接这些概念。接下来我们重点说一下 MySQL 采用了什么样的算法来进行表与表之前的连接。
前面我们已经介绍过了执行连接查询的大致步骤了,我们再来简单回顾一下
整个过程就像是一个嵌套循环,所以这种连接方式称为 嵌套循环连接 ,这是最简单也是最笨的一种连接查询算法。大致处理过程如下:
for each row in t1 matching range {
for each row in t2 matching reference key {
for each row in t3 {
if row satisfies join conditions, send to client
}
}
}需要注意的是对于获套循环连接算法法来说,每当我们从驱动表中得到了一条记录时,就根据这条记录立时到被驱动表中查询一次,如果得到了匹配的记录, 就把组合后 的记录发送给客户端,然后再到驱动表中获取下一条记录。这个过程将重复进行。
这个是我们比较熟悉的方式,也是相对来说最有用的方式,在被驱动表上创建合适的索引,只返回必要的字段等都可以起到一些优化的作用。
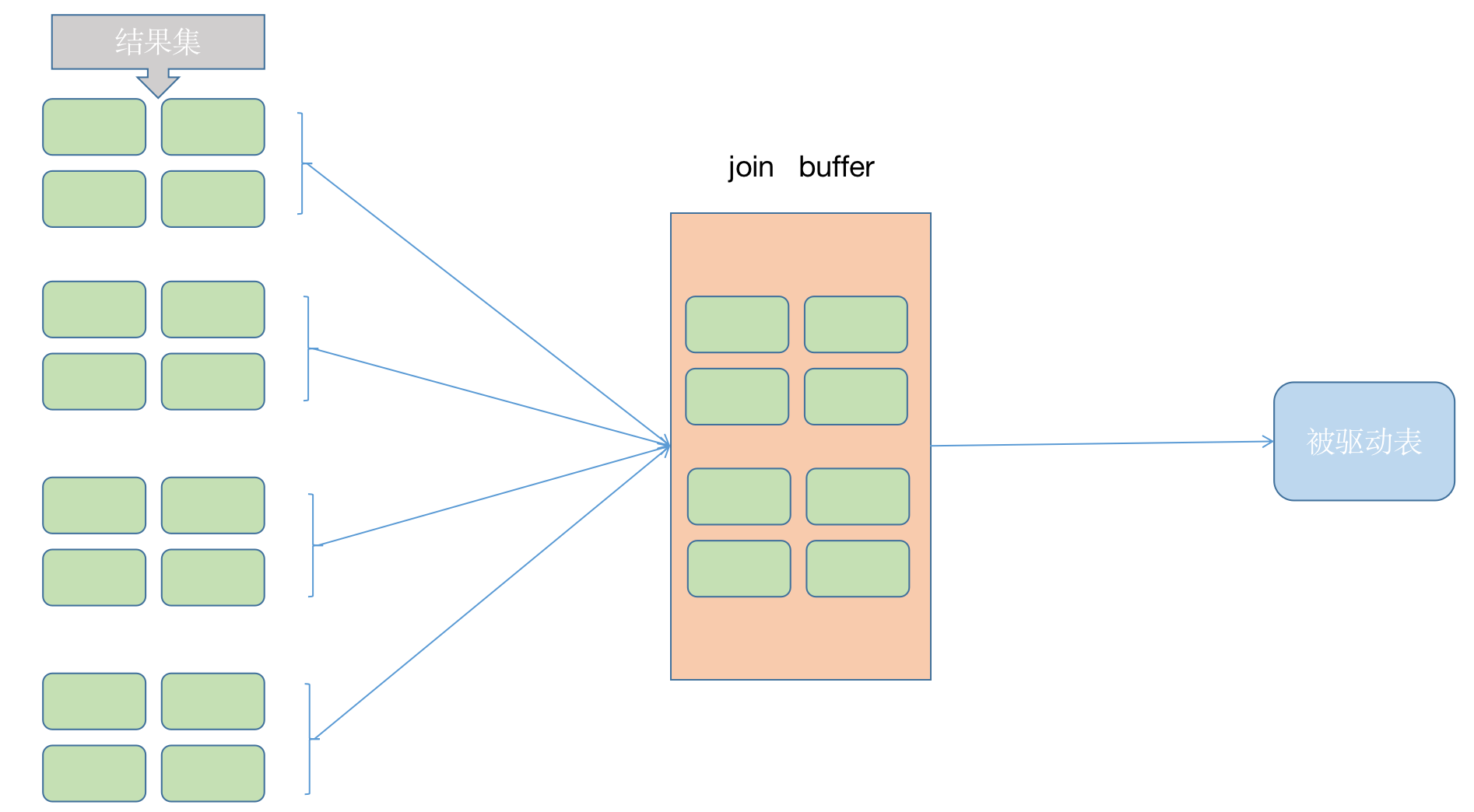
每次访问被驱动表,其表中的记录都会被加载到内存中,然后再从驱动表中取出一条与其匹配,匹配结束后清楚内存,然后再从驱动表中加载一条记录,然后把被驱动表的记录加载到内存匹配,如果这个被驱动表中的数据特别多而且不能使用索引进行访问,那就相当于要从磁盘上读这个表好多次,这个IO的代价就非常大了。所以我们得想办法,尽量减少被驱动表的访问次数,于是就出现了下面这种方式。
不再是逐条获取驱动表的数据,而是一块一块的获取,引入join buffer 缓冲区, 将驱动表join 相关的部分数据列(大小受join buffer的限制)缓存到 join buffer中,然后开始扫描被驱动表,被驱动表的每一条记录一次性和join buffer中所有的驱动表记录进行匹配(内存中操作)。将简单嵌套循环中的多次比较合并成一次,降低了备驱动表的访问频率。
这里缓存的不只是关联表的列,select后面的列也会缓存起来。所以查询的时候尽量减少不必要的字段,可以让join buffer中可以存放更多的列。
join_buffer_size的最大值在32为系统中可以申请4G,在64为操作系统中可以申请大于4G的空间。
MySQL对于被驱动表的关联字段没索引的关联查询,一般都会使用 BNL 算法。如果有索引一般选择 NLJ 算法,有 索引的情况下 NLJ 算法比 BNL算法性能更高。
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我正在使用Sequel构建一个愿望list系统。我有一个wishlists和itemstable和一个items_wishlists连接表(该名称是续集选择的名称)。items_wishlists表还有一个用于facebookid的额外列(因此我可以存储opengraph操作),这是一个NOTNULL列。我还有Wishlist和Item具有续集many_to_many关联的模型已建立。Wishlist类也有:selectmany_to_many关联的选项设置为select:[:items.*,:items_wishlists__facebook_action_id].有没有一种方法可以
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我使用的是Firefox版本36.0.1和Selenium-Webdrivergem版本2.45.0。我能够创建Firefox实例,但无法使用脚本继续进行进一步的操作无法在60秒内获得稳定的Firefox连接(127.0.0.1:7055)错误。有人能帮帮我吗? 最佳答案 我遇到了同样的问题。降级到firefoxv33后一切正常。您可以找到旧版本here 关于ruby-无法在60秒内获得稳定的Firefox连接(127.0.0.1:7055),我们在StackOverflow上找到一个类
我正在阅读一本关于Ruby的书,作者在编写类初始化定义时使用的形式与他在本书前几节中使用的形式略有不同。它看起来像这样:classTicketattr_accessor:venue,:datedefinitialize(venue,date)self.venue=venueself.date=dateendend在本书的前几节中,它的定义如下:classTicketattr_accessor:venue,:datedefinitialize(venue,date)@venue=venue@date=dateendend在第一个示例中使用setter方法与在第二个示例中使用实例变量之间是
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我从用户Hirolau那里找到了这段代码:defsum_to_n?(a,n)a.combination(2).find{|x,y|x+y==n}enda=[1,2,3,4,5]sum_to_n?(a,9)#=>[4,5]sum_to_n?(a,11)#=>nil我如何知道何时可以将两个参数发送到预定义方法(如find)?我不清楚,因为有时它不起作用。这是重新定义的东西吗? 最佳答案 如果您查看Enumerable#find的文档,您会发现它只接受一个block参数。您可以将它发送两次的原因是因为Ruby可以方便地让您根据它的“并行赋
require"socket"server="irc.rizon.net"port="6667"nick="RubyIRCBot"channel="#0x40"s=TCPSocket.open(server,port)s.print("USERTesting",0)s.print("NICK#{nick}",0)s.print("JOIN#{channel}",0)这个IRC机器人没有连接到IRC服务器,我做错了什么? 最佳答案 失败并显示此消息::irc.shakeababy.net461*USER:Notenoughparame