YOLOv8实操:环境配置/自定义数据集准备/模型训练/预测
源码链接:https://github.com/ultralytics/ultralytics
yolov8和yolov5是同一作者,相比yolov5,yolov8的集成性更好了,更加面向用户了
YOLO命令行界面(command line interface, CLI) 方便在各种任务和版本上训练、验证或推断模型。CLI不需要定制或代码,可以使用yolo命令从终端运行所有任务。
如果想了解yolo系列的更新迭代,以及yolov8的模型结构,推荐下面的链接:
YOLOv8详解 【网络结构+代码+实操】
笔者直接从实操入手
安装pytorch、torchvision和其他依赖库
环境配置部分可以参考笔者的博客
【YOLO】YOLOv5-6.0环境搭建(不定时更新)
安装ultralytics
git clone https://github.com/ultralytics/ultralytics
cd ultralytics
pip install -e .
针对检测的数据集准备可以参考笔者的博客,这里不再赘述了
【YOLO】训练自己的数据集
比起YOLOv5,YOLOv8的训练封装性更好了,有利有弊吧,参数默认值修改比较麻烦
训练指令如下:
yolo task=detect mode=train model=yolov8s.pt data=/media/ll/L/llr/DATASET/subwayDatasets/coco.yaml device=0 cache=True epochs=300 project=/media/ll/L/llr/mode name=yolov8
除了上述笔者使用的参数,其他参数说明
task: detect # 可选择:detect, segment, classify
mode: train #可选择: train, val, predict
# Train settings -------------------------------------------------------------------------------------------------------
model: # 设置模型。格式因任务类型而异。支持model_name, model.yaml,model.pt
data: # 设置数据,支持多数类型 data.yaml, data_folder, dataset_name
epochs: 300 # 需要训练的epoch数
patience: 50 # epochs to wait for no observable improvement for early stopping of training
batch: 16 # Dataloader的batch大小
imgsz: 640 # Dataloader中图像数据的大小
save: True # save train checkpoints and predict results
save_period: -1 # Save checkpoint every x epochs (disabled if < 1)
cache: True # True/ram, disk or False. Use cache for data loading
device: # device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu
workers: 8 # 每个进程使用的cpu worker数。使用DDP自动伸缩
project: /media/ll/L/llr/model # project name
name: yolov8 # experiment name
exist_ok: False # whether to overwrite existing experiment
pretrained: False # whether to use a pretrained model
optimizer: SGD # 支持的优化器:Adam, SGD, RMSProp
verbose: True # whether to print verbose output
seed: 0 # random seed for reproducibility
deterministic: True # whether to enable deterministic mode
single_cls: False # 将多类数据作为单类进行训练
image_weights: False # 使用加权图像选择进行训练
rect: False # 启用矩形训练
cos_lr: False # 使用cosine LR调度器
close_mosaic: 10 # disable mosaic augmentation for final 10 epochs
resume: False # resume training from last checkpoint
min_memory: False # minimize memory footprint loss function, choices=[False, True, <roll_out_thr>]
# Segmentation
overlap_mask: True # 分割:在训练中使用掩码重叠
mask_ratio: 4 # 分割:设置掩码下采样
# Classification
dropout: 0.0 # 分类:训练时使用dropout
# Val/Test settings ----------------------------------------------------------------------------------------------------
val: True # validate/test during training
split: val # dataset split to use for validation, i.e. 'val', 'test' or 'train'
save_json: False # save results to JSON file
save_hybrid: False # save hybrid version of labels (labels + additional predictions)
conf: # object confidence threshold for detection (default 0.25 predict, 0.001 val)
iou: 0.7 # intersection over union (IoU) threshold for NMS
max_det: 300 # maximum number of detections per image
half: False # use half precision (FP16)
dnn: False # 使用OpenCV DNN进行ONNX推断
plots: True # 在验证时保存图像
# Prediction settings --------------------------------------------------------------------------------------------------
source: # 输入源。支持图片、文件夹、视频、网址
show: False # 查看预测图片
save_txt: False # 保存结果到txt文件中
save_conf: False # save results with confidence scores
save_crop: False # save cropped images with results
hide_labels: False # hide labels
hide_conf: False # hide confidence scores
vid_stride: 1 # 输入视频帧率步长
line_thickness: 3 # bounding box thickness (pixels)
visualize: False # 可视化模型特征
augment: False # apply image augmentation to prediction sources
agnostic_nms: False # class-agnostic NMS
classes: # filter results by class, i.e. class=0, or class=[0,2,3]
retina_masks: False #分割:高分辨率掩模
boxes: True # Show boxes in segmentation predictions
# Export settings ------------------------------------------------------------------------------------------------------
format: torchscript # format to export to
keras: False # use Keras
optimize: False # TorchScript: optimize for mobile
int8: False # CoreML/TF INT8 quantization
dynamic: False # ONNX/TF/TensorRT: dynamic axes
simplify: False # ONNX: simplify model
opset: # ONNX: opset version (optional)
workspace: 4 # TensorRT: workspace size (GB)
nms: False # CoreML: add NMS
# Hyperparameters ------------------------------------------------------------------------------------------------------
lr0: 0.01 # 初始化学习率
lrf: 0.01 # 最终的OneCycleLR学习率
momentum: 0.937 # 作为SGD的momentum和Adam的beta1
weight_decay: 0.0005 # 优化器权重衰减
warmup_epochs: 3.0 # Warmup的epoch数,支持分数)
warmup_momentum: 0.8 # warmup的初始动量
warmup_bias_lr: 0.1 # Warmup的初始偏差lr
box: 7.5 # box loss gain
cls: 0.5 # cls loss gain (scale with pixels)
dfl: 1.5 # dfl loss gain
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
label_smoothing: 0.0 # label smoothing (fraction)
nbs: 64 # nominal batch size
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.5 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.0 # image mixup (probability)
copy_paste: 0.0 # segment copy-paste (probability)
# Custom config.yaml ---------------------------------------------------------------------------------------------------
cfg: # for overriding defaults.yaml
# Debug, do not modify -------------------------------------------------------------------------------------------------
v5loader: False # use legacy YOLOv5 dataloader
weight_path = "best.pt" # 自训练的模型
imgdir = r'/media/ll/L/llr/DATASET/subwayDatasets/bjdt/images'
img_path = r'/media/ll/L/llr/DATASET/subwayDatasets/bjdt/images/L_0000018.jpg'
model = YOLO(weight_path)
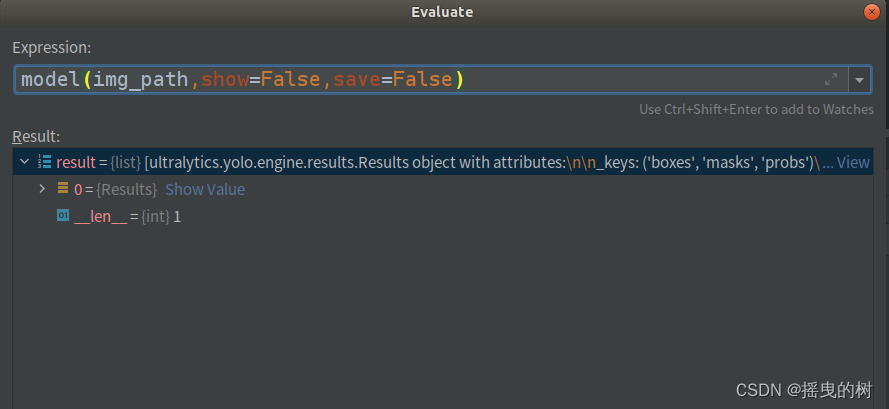
results = model(img_path,show=False,save=False) # 是否显示和保存结果数据
预测一张图片,results如下图所示:
预测文件夹目录,results如图所示:
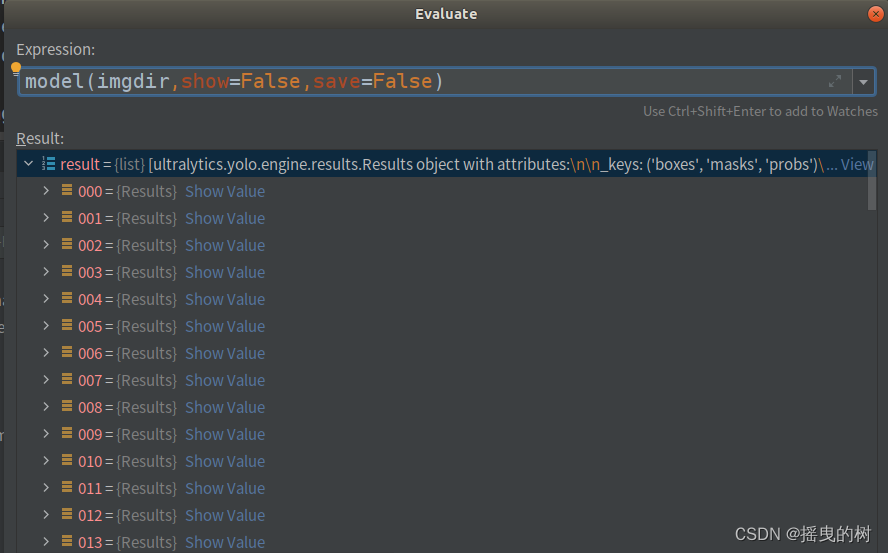
无论是一张图片还是图片目录,返回的results都是list
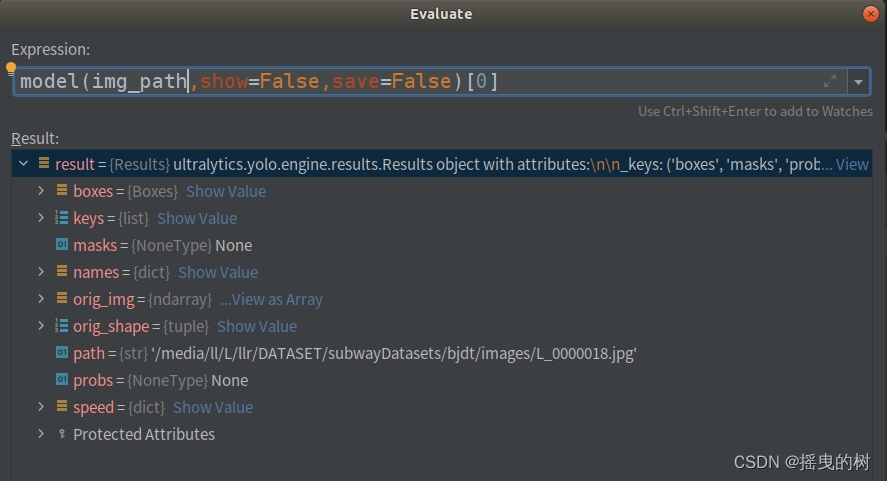
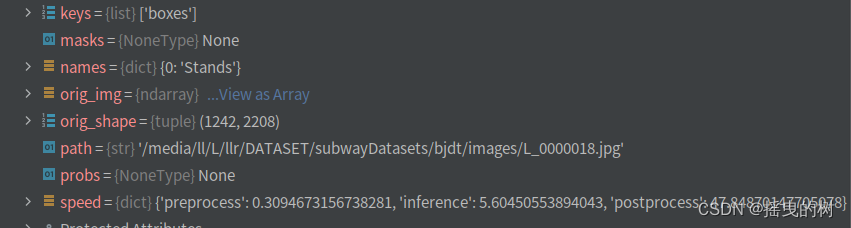
要对预测结果进行处理需要索引进去,如下图所示
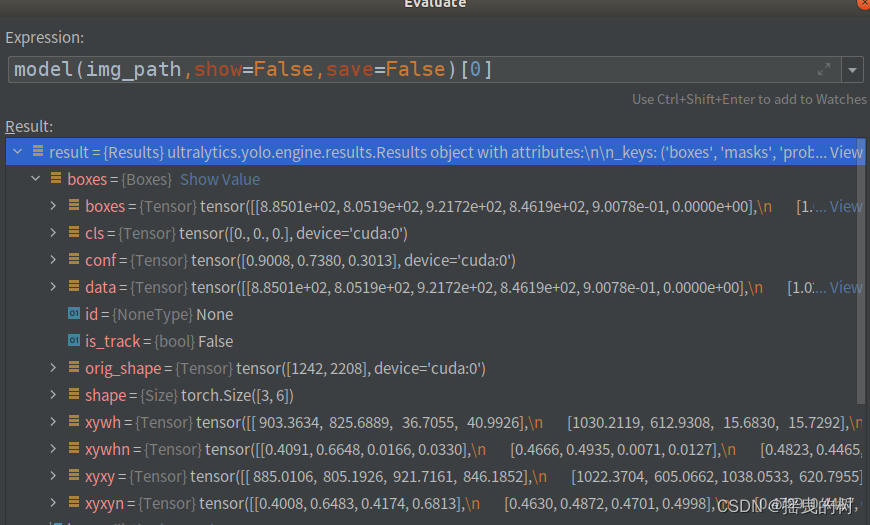
结果参数说明:
boxes:各种形式的检测框信息(xyxy、xywh、归一化的)、类别索引、置信度等
names:类别字典
orig_img:原图数组
orig_shape:原图尺寸
plots:在验证时保存图像(预测时一般为None)
speed:处理速度
基于上述模型提供的检测结果进行后处理算法等
上述即为yolov8的快速使用
我正在尝试设置一个puppet节点,但rubygems似乎不正常。如果我通过它自己的二进制文件(/usr/lib/ruby/gems/1.8/gems/facter-1.5.8/bin/facter)在cli上运行facter,它工作正常,但如果我通过由rubygems(/usr/bin/facter)安装的二进制文件,它抛出:/usr/lib/ruby/1.8/facter/uptime.rb:11:undefinedmethod`get_uptime'forFacter::Util::Uptime:Module(NoMethodError)from/usr/lib/ruby
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun
我有一些代码在几个不同的位置之一运行:作为具有调试输出的命令行工具,作为不接受任何输出的更大程序的一部分,以及在Rails环境中。有时我需要根据代码的位置对代码进行细微的更改,我意识到以下样式似乎可行:print"Testingnestedfunctionsdefined\n"CLI=trueifCLIdeftest_printprint"CommandLineVersion\n"endelsedeftest_printprint"ReleaseVersion\n"endendtest_print()这导致:TestingnestedfunctionsdefinedCommandLin
我有一个只接受一个参数的方法:defmy_method(number)end如果使用number调用方法,我该如何引发错误??通常,我如何定义方法参数的条件?比如我想在调用的时候报错:my_method(1) 最佳答案 您可以添加guard在函数的开头,如果参数无效则引发异常。例如:defmy_method(number)failArgumentError,"Inputshouldbegreaterthanorequalto2"ifnumbereputse.messageend#=>Inputshouldbegreaterthano
我使用Ember作为我的前端和GrapeAPI来为我的API提供服务。前端发送类似:{"service"=>{"name"=>"Name","duration"=>"30","user"=>nil,"organization"=>"org","category"=>nil,"description"=>"description","disabled"=>true,"color"=>nil,"availabilities"=>[{"day"=>"Saturday","enabled"=>false,"timeSlots"=>[{"startAt"=>"09:00AM","endAt"=>
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
我正在阅读一本关于Ruby的书,作者在编写类初始化定义时使用的形式与他在本书前几节中使用的形式略有不同。它看起来像这样:classTicketattr_accessor:venue,:datedefinitialize(venue,date)self.venue=venueself.date=dateendend在本书的前几节中,它的定义如下:classTicketattr_accessor:venue,:datedefinitialize(venue,date)@venue=venue@date=dateendend在第一个示例中使用setter方法与在第二个示例中使用实例变量之间是