本博客基于Windows系统,以下命令建议在Anaconda Prompt命令行窗口中执行:
使用 conda create -n your_env_name python=X.X(2.7、3.6等),anaconda 命令创建python版本为X.X、名字为your_env_name的虚拟环境。your_env_name文件可以在Anaconda安装目录envs文件下找到。 指定python版本为2.7,注意至少需要指定python版本或者要安装的包, 在不指定python版本时,自动安装最新python版本
conda create -n env_name python=2.7
# 同时安装必要的包(如numpy和matplotlib)
conda create -n env_name numpy matplotlib python=2.7使用如下命令即可激活创建的虚拟环境
activate your_env_name(虚拟环境名称)激活完当前环境后再使用python --version可以检查当前python版本是否为想要的(即虚拟环境的python版本)。
直接使用如下命令退回到默认虚拟环境(视具体情况而定,如果Anaconda安装时没有自己命名虚拟环境,那么默认环境应该是称为base)
conda deactivateconda remove -n your_env_name(虚拟环境名称) --all要查询、增加、删除虚拟环境中的包,需要先按照上述命令激活你想要进行操作的环境
当前环境激活后在命令行窗口中输入conda list或者pip list,但是推荐conda list,能够给出各个包的Build Channel
conda listconda install -n 虚拟环境名称 包名==包版本不强调虚拟环境也可:
conda install 包名==包版本也可以用pip命令,直接将上面的conda命令中的conda换成pip就行
conda remove package_name或者·:
pip uninstall package_name查看所有环境: conda env list或 conda info -e
在当前环境更新包: pip/conda update 包名
搜索特定包:conda search package_name
导出与还原:
a.导出当前虚拟环境的命令格式为conda env export --file 路径/文件名.yaml
注意!文件名与环境名无关。当前路径情况下为:conda env export --file ./文件名.yaml
b.还原导出的虚拟环境的命令格式为:conda env create -f 路径/文件名.yaml
(还原时,不能存在与原环境重复的环境)
requirements.txt 用来记录项目所有的依赖包和版本号,只需要一个简单的 pip 命令就能完成:
pip freeze > requirements.txt
或者:
conda list -e > requirement.txt
生成的文件会像这个样子:
xgboost==0.90
pandas==1.1.5
geatpy==2.2.2
statsmodels==0.10.1
scipy==1.3.1
tensorflow==1.12.0
minepy==1.2.4再用如下命令来一次性安装 requirements.txt 里面所有的依赖包:
pip install -r requirements.txta.直接使用网站上给出的conda命令安装:(适合大部分常见包):: Anaconda.org![]() https://anaconda.org/,直接在搜索框搜索制定包,找到符合你的版本和系统要求的那个进入详情页,直接复制详情页的conda命令去命令行粘贴,一般都是可行的
https://anaconda.org/,直接在搜索框搜索制定包,找到符合你的版本和系统要求的那个进入详情页,直接复制详情页的conda命令去命令行粘贴,一般都是可行的
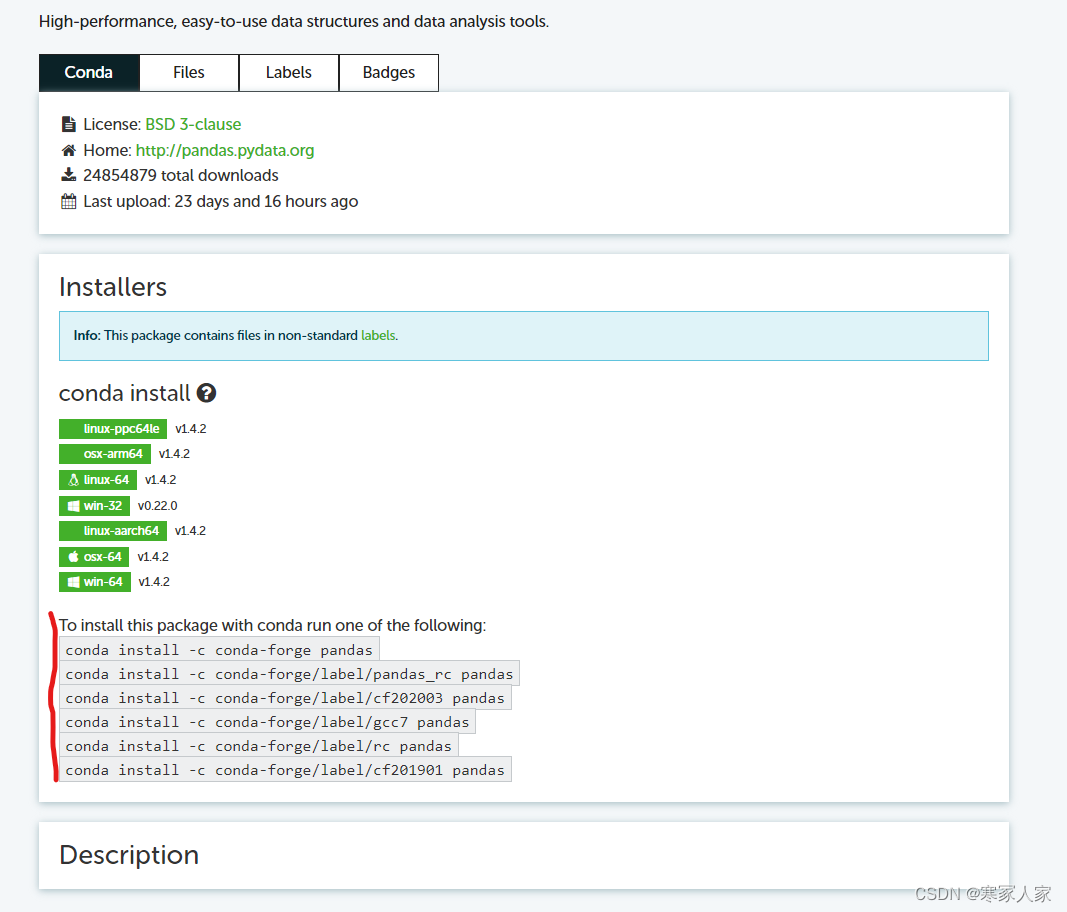
b.从国内镜像源仓库中找到该Python版本对应的.whl格式或者tar.gz的包,下载到本地,然后在已经激活的环境中使用如下命令安装:
pip install whl文件存放路径\whl文件名例如:pip install D:\Python依赖包\xgboost-0.90-py2.py3-none-win_amd64.whl
也可以直接切换为whl文件所在文件夹后pip install 文件名
PS:python依赖包的下载网站有:
Python Extension Packages for Windows - Christoph Gohlke (uci.edu)![]() https://www.lfd.uci.edu/~gohlke/pythonlibs/#pandas Simple Index (aliyun.com)
https://www.lfd.uci.edu/~gohlke/pythonlibs/#pandas Simple Index (aliyun.com)![]() http://mirrors.aliyun.com/pypi/simple/
http://mirrors.aliyun.com/pypi/simple/
PyPI · The Python Package Index![]() https://pypi.org/ Simple Index (doubanio.com)
https://pypi.org/ Simple Index (doubanio.com)![]() http://pypi.doubanio.com/simple/
http://pypi.doubanio.com/simple/
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我想用ruby编写一个小的命令行实用程序并将其作为gem分发。我知道安装后,Guard、Sass和Thor等某些gem可以从命令行自行运行。为了让gem像二进制文件一样可用,我需要在我的gemspec中指定什么。 最佳答案 Gem::Specification.newdo|s|...s.executable='name_of_executable'...endhttp://docs.rubygems.org/read/chapter/20 关于ruby-在Ruby中编写命令行实用程序
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为