哈喽兄弟们,今天咱们来了解一下 fileinput 。
说到fileinput,可能90%的码农表示没用过,甚至没有听说过。
这不奇怪,因为在python界,既然open可以走天下,何必要fileinput呢?
但是,今天我还是要介绍fileinput这个方法,因为太奈斯了。
不止是香。是真香!
接下来,就跟着我,一起fileinput,对,就是这个feel。

基本用法
先来看一下fileinput的基本功能:
fileinput.filename():返回当前被读取的文件名。
—>在第一行被读取之前,返回 None。
fileinput.fileno():返回以整数表示的当前文件“文件描述符”。
—>当未打开文件时(处在第一行和文件之间),返回 -1。
fileinput.lineno():返回已被读取的累计行号。
—>在第一行被读取之前,返回 0。在最后一个文件的最后一行被读取之后,返回该行的行号。
fileinput.filelineno():返回当前文件中的行号。
—>在第一行被读取之前,返回 0。
—>在最后一个文件的最后一行被读取之后,返回此文件中该行的行号。
进阶用法
fileinput.isfirstline():如果刚读取的行是其所在文件的第一行则返回 True,否则返回 False。
fileinput.isstdin():如果最后读取的行来自 sys.stdin 则返回 True,否则返回 False。
fileinput.nextfile():关闭当前文件以使下次迭代将从下一个文件(如果存在)读取第一行;不是从该文件读取的行将不会被计入累计行数。直到下一个文件的第一行被读取之后文件名才会改变。
—>在第一行被读取之前,此函数将不会生效;它不能被用来跳过第一个文件。
—>在最后一个文件的最后一行被读取之后,此函数将不再生效。
fileinput.close():关闭序列。
代码示例
import fileinput
'当 Python 脚本没有传入任何参数时,fileinput 默认会以 stdin 作为输入源'
for line in fileinput.input():
print(f'{line}')
运行结果
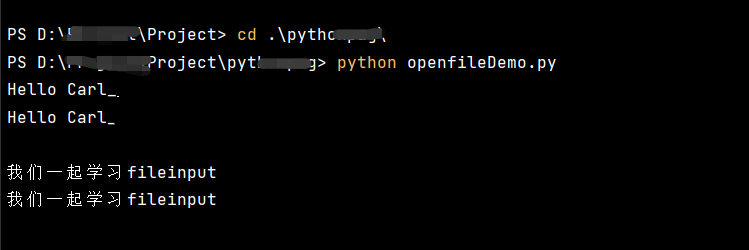
你输入的内容,程序都会读取并再输出。
俗称:复读机
代码示例
import fileinput
'files 输入打开文件的名称即可'
with fileinput.input(files=('output.txt',)) as file:
for line in file:
print(f'{fileinput.filename()} 第{fileinput.lineno()}行:{line}',end='')
运行结果
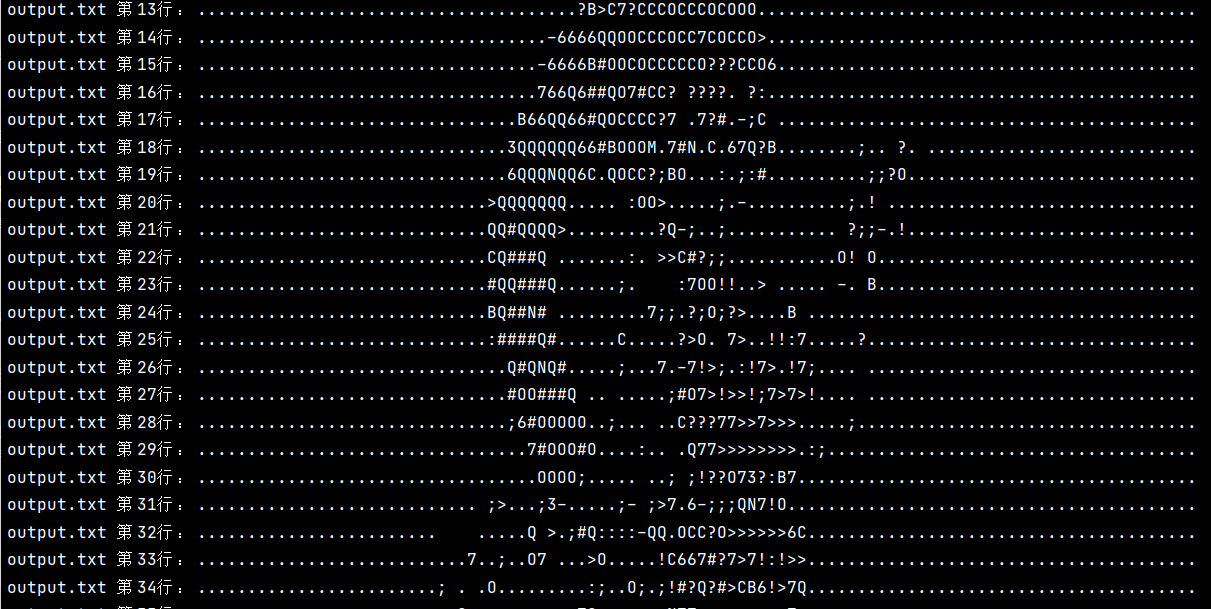
解析:
多文件序号连续排序
调用方法
代码示例
import fileinput
'files 输入打开文件的名称即可'
with fileinput.input(files=('output.txt','input.txt')) as file:
for line in file:
#fileinput.lineno() 把两个文件的整合陈一个文件对象file,需要排序输出
print(f'{fileinput.filename()} 第{fileinput.lineno()}行: {line}', end='')
# fileinput.filelineno()两个文件单独读取,需要单独排序
print(f'{fileinput.filename()} 第{fileinput.filelineno()}行: {line}', end='')
运行结果
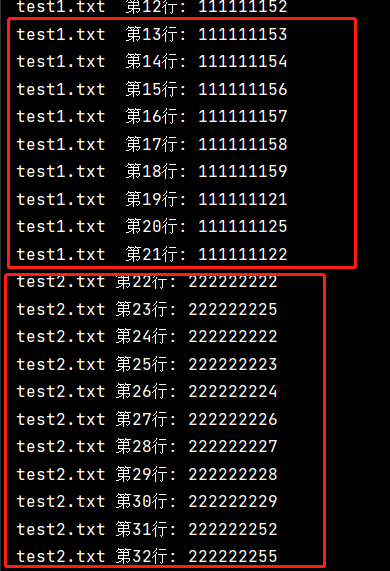
多文件序号单独排序
调用方法
代码示例
import fileinput
'files 输入打开文件的名称即可'
with fileinput.input(files=('test1.txt','test2.txt')) as file:
for line in file:
# fileinput.filelineno()两个文件单独读取,需要单独排序
print(f'{fileinput.filename()} 第{fileinput.filelineno()}行: {line}', end='')
运行结果
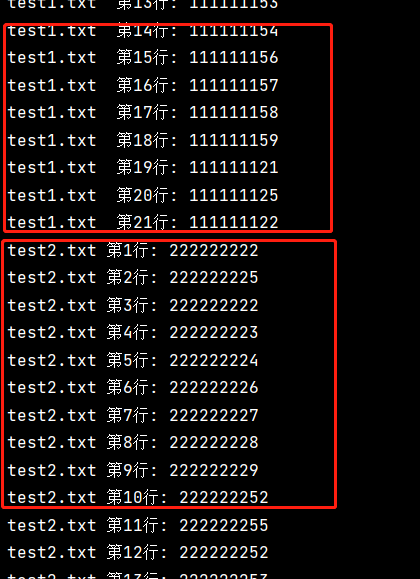
与glob配合用法
在颜值的时代,上面的输出样式,已经无法满足我们的需要了,于是乎,我们就想到了glob。
代码示例
import fileinput
import glob
#glob 匹配te开头的txt文件
for line in fileinput.input(glob.glob("te*.txt")):
if fileinput.isfirstline():
#输出读取文件
print('='*10,f'读取文件{fileinput.filename()}','='*10)
#fileinput.filelineno()方法读取
print(str(fileinput.filelineno())+ ':'+line.upper(),end='')
运行结果
就这颜值,哪个小姐姐能不喜欢呢。
调用方法
代码示例
import fileinput
#触发backup的动作,源文件内容被修改,对源文件进行backup
with fileinput.input(files=("test1.txt",), backup=".bak",inplace=1) as file:
for line in file:
print(line.rstrip().replace('111111', '222222'))
print(f'{fileinput.filename()} 第{fileinput.lineno()}行: {line}', end='')
运行结果

解析
代码示例:
import fileinput
#触发backup的动作,源文件内容被修改,对源文件进行backup
with fileinput.input(files=("test2.txt",), inplace=True) as file:
print("[INFO] task is started...")
for line in file:
print(f'{fileinput.filename()} 第{fileinput.lineno()}行: {line}', end='')
print("[INFO] task is closed...")
运行结果
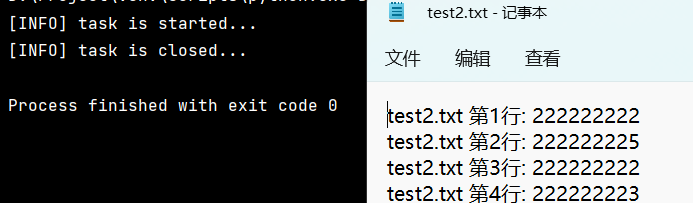
注
通过运行结果,可以看到:
openhook含义解析
方法介绍
fileinput 内置了两种勾子
1、fileinput.hook_compressed(filename, mode)
2、fileinput.hook_encoded(encoding, errors=None)
示例实战
假如我想要使用 fileinput 来读取网络上的文件,思路:
def online_open(url, mode):
import requests
r = requests.get(url)
filename = url.split("/")[-1]
with open(filename,'w') as f1:
f1.write(r.content.decode("utf-8"))
f2 = open(filename,'r')
return f2
直接将这个函数传给 openhook 即可:
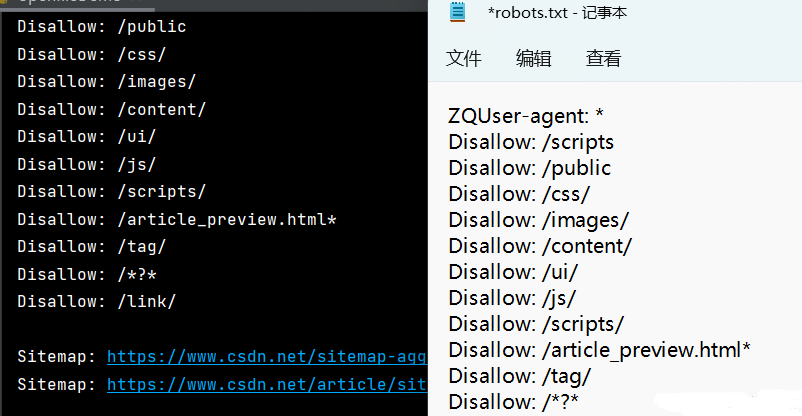
import fileinput
file_url = 'https://www.csdn.net/robots.txt'
with fileinput.input(files=(file_url,), openhook=online_open) as file:
for line in file:
print(line, end="")
代码整合:
def online_open(url, mode):
import requests
r = requests.get(url)
filename = url.split("/")[-1]
with open(filename,'w') as f1:
f1.write(r.content.decode("utf-8"))
f2 = open(filename,'r')
return f2
import fileinput
file_url = 'https://www.csdn.net/robots.txt'
with fileinput.input(files=(file_url,), openhook=online_open) as file:
for line in file:
print(line, end="")
# Python学习交流群 279199867
运行结果
关于fileinput的介绍,也就介绍到这里。
fileinput本身是对 open 函数的再次封装,所以在读取的cc部分,就比open显得更专业,更优雅,这也是仅限于读取的方面。
在写的方面,相对于open,就不是那么的强悍。
归根结底,fileinput还是一个不错的方法。值得你拥有。
最后,再给大家推荐一套Python爬虫教程:代码总是学完就忘记?100个爬虫实战项目!让你沉迷学习丨学以致用丨下一个Python大神就是你!
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
我正在尝试设置一个puppet节点,但rubygems似乎不正常。如果我通过它自己的二进制文件(/usr/lib/ruby/gems/1.8/gems/facter-1.5.8/bin/facter)在cli上运行facter,它工作正常,但如果我通过由rubygems(/usr/bin/facter)安装的二进制文件,它抛出:/usr/lib/ruby/1.8/facter/uptime.rb:11:undefinedmethod`get_uptime'forFacter::Util::Uptime:Module(NoMethodError)from/usr/lib/ruby
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl