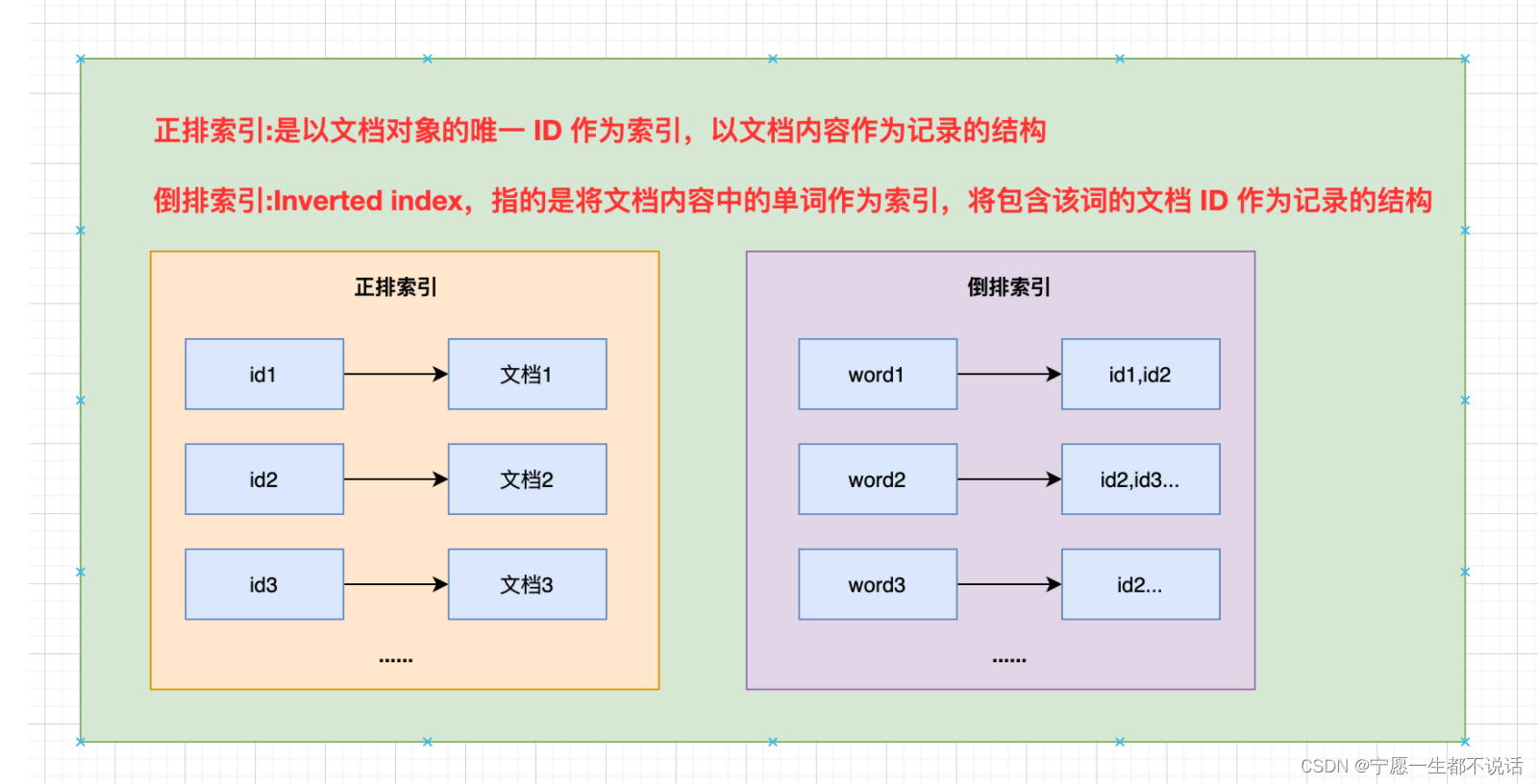
文章目录

假设要查询上图中title中包含"手机"的信息,那么sql语句是这样的
SELECT * FROM goods WHERE title LIKE '%手机%';
如果使用模糊查询,左边有通配符,不会走索引,会全表扫描,性能低
假设上表查询title检索内容为"我要买一部华为手机",无论sql语句怎么模糊匹配都只会查询到包含这整条句子的title,显然数据库中是不存在的。
关系型数据库提供的查询,功能太弱
所以需要用到ES的倒排索引,以关键词为索引库,而关键词又是对原有数据内容拆分出来的,比如"我要买一部华为手机"中华为和手机关键词拆分出来作为索引查询就会灵活很多。
就像使用新华字典查找汉字,先找到汉字的偏旁部首,再根据偏旁部首对应的目录(索引)找到目标汉字。
建立倒排索引的流程
1.首先对所有数据的内容进行拆分(分词),拆分成唯一的一个个词语(词条Term)。
2.然后建立词条和每条数据的对应关系(词条在文档出现的位置下标,出现频率)
| (Term 词条) | (Doc ID,Freq 频率) | (Pos 位置) |
|---|---|---|
| we | (0,1) (1,1) | (0,0)(1,0) |
| like | (0,1) (1,1) | (0,1)(1,1) |
| java | (0,3) | (2,3,4) |
| lucene | (1,3) | (2,3,4) |
| (Term 词条) | (Doc ID,Freq 频率) | (Pos 位置) |
|---|---|---|
| we | (0,1) (1,1) | (0,0)(1,3) |
| like | (0,1) (1,1) | (0,1)(1,4) |
| java | (0,3) (1,3) | (0,2,3,4) (1,0,1,2) |
| lucene | (1,3) | (2,3,4) |
假设只有1个文档有,Pos位置第一位就不需要标识是几号文档,假设是有多个文档有,Pos位置的第一位默认就是文档编号
倒排索引:将每条数据中的内容进行分词,形成词条。然后记录词条和数据的唯一标识(id)的对应关系,形成的产物。
我发现自己需要这个。假设cart是一个包含用户列表的模型。defindex_of_itemcart.users.each_with_indexdo|u,i|ifu==current_userreturniendend获取此类关联索引的更简单方法是什么? 最佳答案 indexArray上的方法与您的index_of_item方法相同,例如cart.users.index(current_user)返回数组中第一个对象的索引==给obj。如果未找到匹配项,则返回nil。 关于ruby-on-
因此,当我遵循MichaelHartl的RubyonRails教程时,我注意到在用户表中,我们为:email属性添加了一个唯一索引,以提高find的效率方法,因此它不会逐行搜索。到目前为止,我们一直在根据情况使用find_by_email和find_by_id进行搜索。然而,我们从未为:id属性设置索引。:id是否自动索引,因为它在默认情况下是唯一的并且本质上是顺序的?或者情况并非如此,我应该为:id搜索添加索引吗? 最佳答案 大多数数据库(包括sqlite,这是RoR中的默认数据库)会自动索引主键,对于RailsMigration
假设我有一个可枚举对象enum,现在我想获取第三个项目。我知道一种通用方法是转换成数组,然后使用索引访问,如:enum.to_a[2]但这种方式会创建一个临时数组,效率可能很低。现在我使用:enum.each_with_index{|v,i|breakvifi==2}但这非常丑陋和多余。执行此操作最有效的方法是什么? 最佳答案 你可以使用take剥离前三个元素,然后剥离last从take给你的数组中获取第三个元素:third=enum.take(3).last如果您根本不想生成任何数组,那么也许:#Ifenumisn'tanEnum
在我的场景中,Logstash收到的系统日志行的“时间戳”是UTC,我们在Elasticsearch输出中使用事件“时间戳”:output{elasticsearch{embedded=>falsehost=>localhostport=>9200protocol=>httpcluster=>'elasticsearch'index=>"syslog-%{+YYYY.MM.dd}"}}我的问题是,在UTC午夜,Logstash在外时区(GMT-4=>America/Montreal)结束前将日志发送到不同的索引,并且索引在20小时(晚上8点)之后没有日志,因为“时间戳”是UTC。我们已
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
我想从特定索引开始遍历数组。我该怎么做?myj.eachdo|temp|...end 最佳答案 执行以下操作:your_array[your_index..-1].eachdo|temp|###end 关于ruby-从特定索引开始迭代数组,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/44151758/
我一直在努力学习如何处理由数组组成的数组。假设我有这个数组:my_array=[['ORANGE',1],['APPLE',2],['PEACH',3]我将如何找到包含'apple'的my_array索引并删除该索引(删除子数组['APPLE',2]因为'apple'包含在该索引的数组中)?谢谢-我非常感谢这里的帮助。 最佳答案 您可以使用Array.select过滤掉项目:>>a=[['ORANGE',1],['APPLE',2],['PEACH',3]]=>[["ORANGE",1],["APPLE",2],["PEACH",3
我想使用部分字符串搜索数组,然后获取找到该字符串的索引。例如:a=["Thisisline1","Wehaveline2here","andfinallyline3","potato"]a.index("potato")#thisreturns3a.index("Wehave")#thisreturnsnil使用a.grep将返回完整的字符串,使用a.any?将返回正确的true/false语句,但都不会返回匹配的索引找到了,或者至少我不知道该怎么做。我正在编写一段代码,该代码读取文件、查找特定header,然后返回该header的索引,以便它可以将其用作future搜索的偏移量。如果
如何在rakedb:migrate:status中删除带有“**NOFILE**”的迁移ID列表?例如:StatusMigrationIDMigrationName--------------------------------------------------up20131017204224Createusersup20131218005823**********NOFILE**********up20131218011334**********NOFILE**********我不明白为什么当我自己手动删除它时它仍然保留旧的迁移文件,因为我正在研究迁移的工作原理。这是为了记录吗?但
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>