1.参照课堂所讲示例,利用构建的词项文档关联矩阵进行布尔检索,要求分别针对AND,OR和NOT进行检索,并分别给出实际检索案例。课堂示例如下所示:
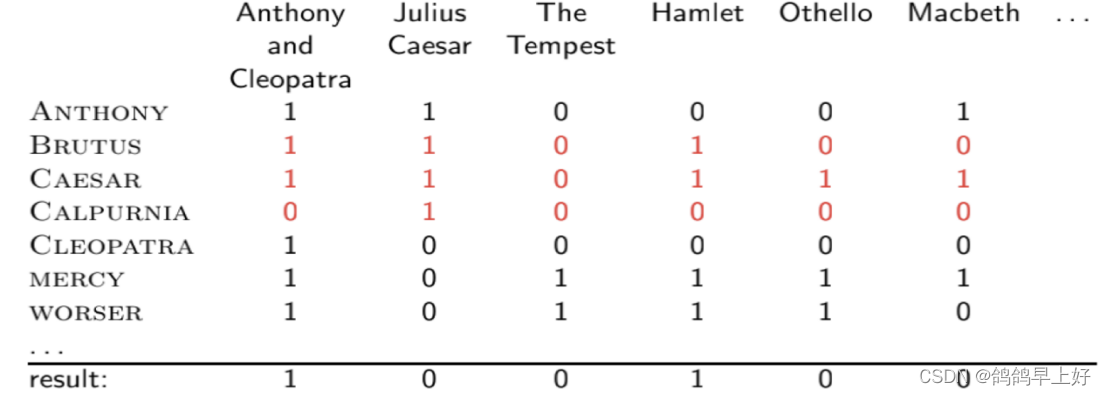
图1
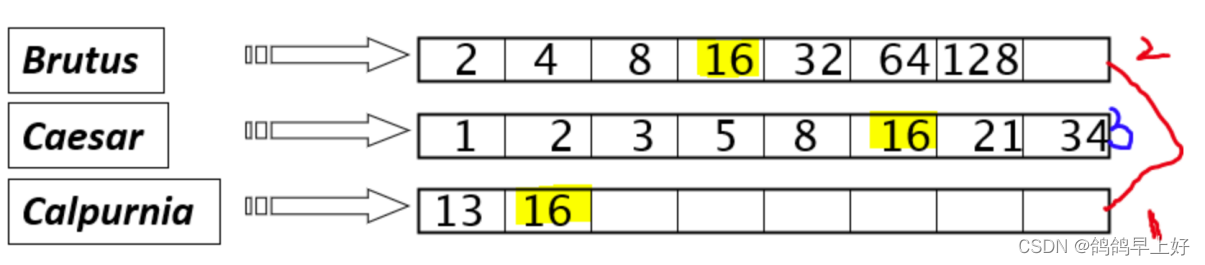
2.参照课堂所讲案例,利用构建的倒排索引进行布尔检索,支持AND操作,并给出实际检索案例。示例如下所示:
(1) 在词典中定位 Brutus;
(2) 返回其倒排记录表;
(3) 在词典中定位 Calpurnia;
(4) 返回其倒排记录表;
(5) 对两个倒排记录表求交集(如图2所示)。
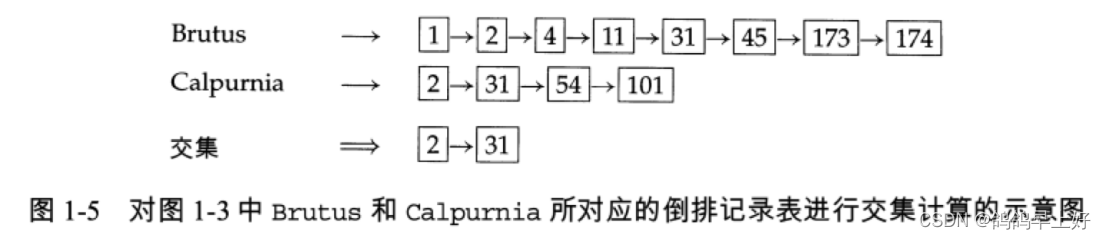 图2
图2
首先我们要明确,实现上述的功能需要有以下四个基本的步骤:
首先,明确词项-文档关联矩阵实际上具有高度的稀疏性。所以为了节省存储空间,引入倒排记录表(inverted index)。称为词项词典(dictionary,简称词典,有时也称为vocabulary或者lexicon。而vocabulary则指词汇表)。
每个词项都有一个记录出现该词项的所有文档的列表,该表中的每个元素记录的是词项在某文档中的一次出现信息(在后面的讨论中,该信息中往往还包括词项在文档中出现的位置),这个表中的每个元素通常称为倒排记录(posting)。
根据上讲内容,首先,可以把邮件转换为txt文件,将文档读取到一个一维数据之中;
然后,将每篇文档转换成一个个token的列表:
步骤:
a. 将文本全部转换成小写 b. 根据“非字符”对文本使用正则表达式进行切割(注:当出现两个连续非字符,会切割出现空串,需要手工删除);
最后,构建倒排索引
步骤:
a. 建立如下数据结构:
建立一个哈希表,key值为字符串,value值为列表。
其中key值中存储所有单词,并作为哈希表的索引;value值中第1位记录倒排索引长度,第2位开始记录每个单词出现文章的序号。
b. 遍历token列表:
如果单词出现过,就将文章序号添加到列表尾部,并且长度加一。
单词第一次出现时,将单词加入哈希表。
#sdnu 202011000106
# 打开文件
f = open('所需txt文档')
# 读取文章,并删除每行结尾的换行符
doc = pd.Series(f.read().splitlines())
# 转换为小写,并使用正则表达式进行切割
doc = doc.apply(lambda x: re.split('[^a-zA-Z]', x.lower()))
# 删除空串
for list in doc:
while '' in list:
list.remove('')
hashtable = {}
for index, list in enumerate(doc):
for word in list:
if word in hashtable:
hashtable[word].append(index+1)
hashtable[word][0] += 1
else:
hashtable[word] = [1, index+1]
hashtable = dict(
sorted(hashtable.items(), key=lambda kv: (kv[1][0], kv[0]), reverse=True))
(例如,Brutus AND Caesar)
应该在词典中定位 Brutus和Caesar,并返回两个词项的倒排表。
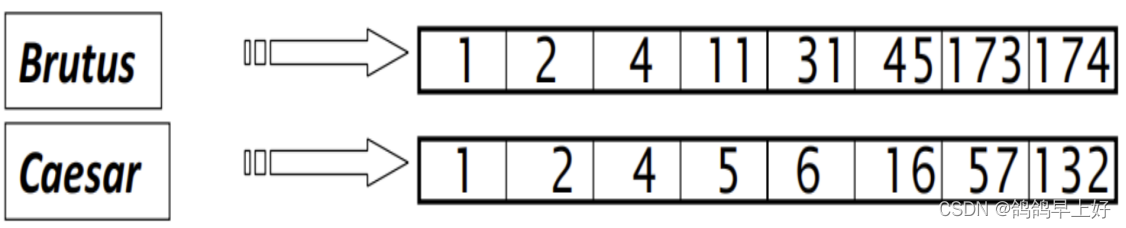
然后为每个倒排表定义一个定位指针,两个指针同时从前往后扫描,每次比较当前指针对应的倒排记录,然后再向后移动指向文档ID较小的那个指针或在文档ID相等时同时两个指针,直到某一个倒排表被检索完毕,
这样就能轻易找出符合Brutus AND Caesar的文档,有:文档a、文档b和文档c。
OR和NOT的同理类似,只是对倒排表的操作不同,详细的说明在后面展开。
注意:NOT操作不能简单理解为某一词项的补集,因为补集可能会很大,必须是两个倒排表的减集。
AND
思路:
参数为两个单词对应的倒排索引列表,返回值为完成AND操作后的结果列表。
需要完成的操作是将同时出现在list1,list2的index筛选出来。因为原先两个列表都是从小到大排序,因此,只需要不断地将指向较小数的指针不断向后移,遇到相同的index时,将index加入结果列表,直到一个指针走到底。
# sdnu 202011000106
def And(list1, list2):
i, j = 0, 0
res = []
while i < len(list1) and j < len(list2):
# 同时出现,加入结果列表
if list1[i] == list2[j]:
res.append(list1[i])
i += 1
j += 1
# 指向较小数的指针后移
elif list1[i] < list2[j]:
i += 1
else:
j += 1
return res
OR
思路:
参数为两个单词对应的倒排索引列表,返回值为完成OR操作后的结果列表。
需要完成的操作是将在list1,list2中出现的所有index合并筛选出来。思路与AND的解法大致类似,原先两个列表都是从小到大排序,因此,同样只需要不断地将指向较小数的指针不断向后移,区别是在index大小不相同时仍然需要将index加入结果列表,直到一个指针走到底。
因为OR操作是将两个列表合并,还需要将两个列表中剩余未遍历到的index加入结果列表之中。
#sdnu 202011000106
def Or(list1, list2):
i, j = 0, 0
res = []
while i < len(list1) and j < len(list2):
# 同时出现,只需要加入一次
if list1[i] == list2[j]:
res.append(list1[i])
i += 1
j += 1
# 指向较小数的指针后移,并加入列表
elif list1[i] < list2[j]:
res.append(list1[i])
i += 1
else:
res.append(list2[j])
j += 1
# 加入未遍历到的index
res.extend(list1[i:]) if j == len(list2) else res.extend(list2[j:])
return res
AND NOT
思路:
参数为两个单词对应的倒排索引列表,返回值为完成AND NOT操作后的结果列表。
需要完成的操作是将出现在list1,但是未出现在list2的index筛选出来。原先两个列表都是从小到大排序,因此,同样需要不断地将指向较小数的指针不断向后移,并且当指向list1的index较小时,将index加入结果列表,直到一个指针走到底。
假设list1未遍历完,list2已经结束,那么list1剩余的index一定不会出现在list2中,所以还需要将剩余未遍历到的index加入结果列表之中。
#sdnu 202011000106
def AndNot(list1, list2):
i, j = 0, 0
res = []
while i < len(list1) and j < len(list2):
# index相等时,同时后移
if list1[i] == list2[j]:
i += 1
j += 1
# 指向list1的index较小时,加入结果列表
elif list1[i] < list2[j]:
res.append(list1[i])
i += 1
else:
j += 1
# list1 未遍历完,加入剩余index
if i != len(list1):
res.extend(list1[i:])
return res
辅助函数:从哈希表中获取倒排索引列表,并删除第一个元素(用于记录元素个数)
def getList(word):
return hashtable[word][1:]
find函数用于返回用户所输入词项的倒排记录表用于合并计算。
def find(test, dict1, dict0):
ft0 = re.split('[()]', test)
ft = []
for i in range(len(ft0)):
ft = ft + ((ft0[i].replace(' ', '')).split("AND"))
ft = [i for i in ft if i != '']
p = []
for j in range(len(ft)):
p0 = []
if('OR' in ft[j]):
ft1 = ft[j].split('OR')
for k in range(len(ft1)):
if(ft1[k] in dict1):
p0 = p0 + dict1[ft1[k]]
p0 = list(set(p0))
elif('NOT' in ft[j]):
ft[j] = ft[j].replace('NOT', '')
if(ft[j] in dict1):
p0 = [y for y in dict0 if y not in dict1[ft[j]]]
else:
p0 = dict0
elif(ft[j] in dict1):
p0 = dict1[ft[j]]
p.append(p0)
return p
倒排记录表合并算法伪代码如下所示:
步骤:
首先输入两个倒排记录表p1,p2,然后判断两个倒排记录表的指针是否为空,若为空,则结束;
若不为空,判断是否相同,若相同,则p1,p2指针后移;
否则,判断p1指针所指元素是否>p2;
若是,则p2指针后移,否则p1后移。
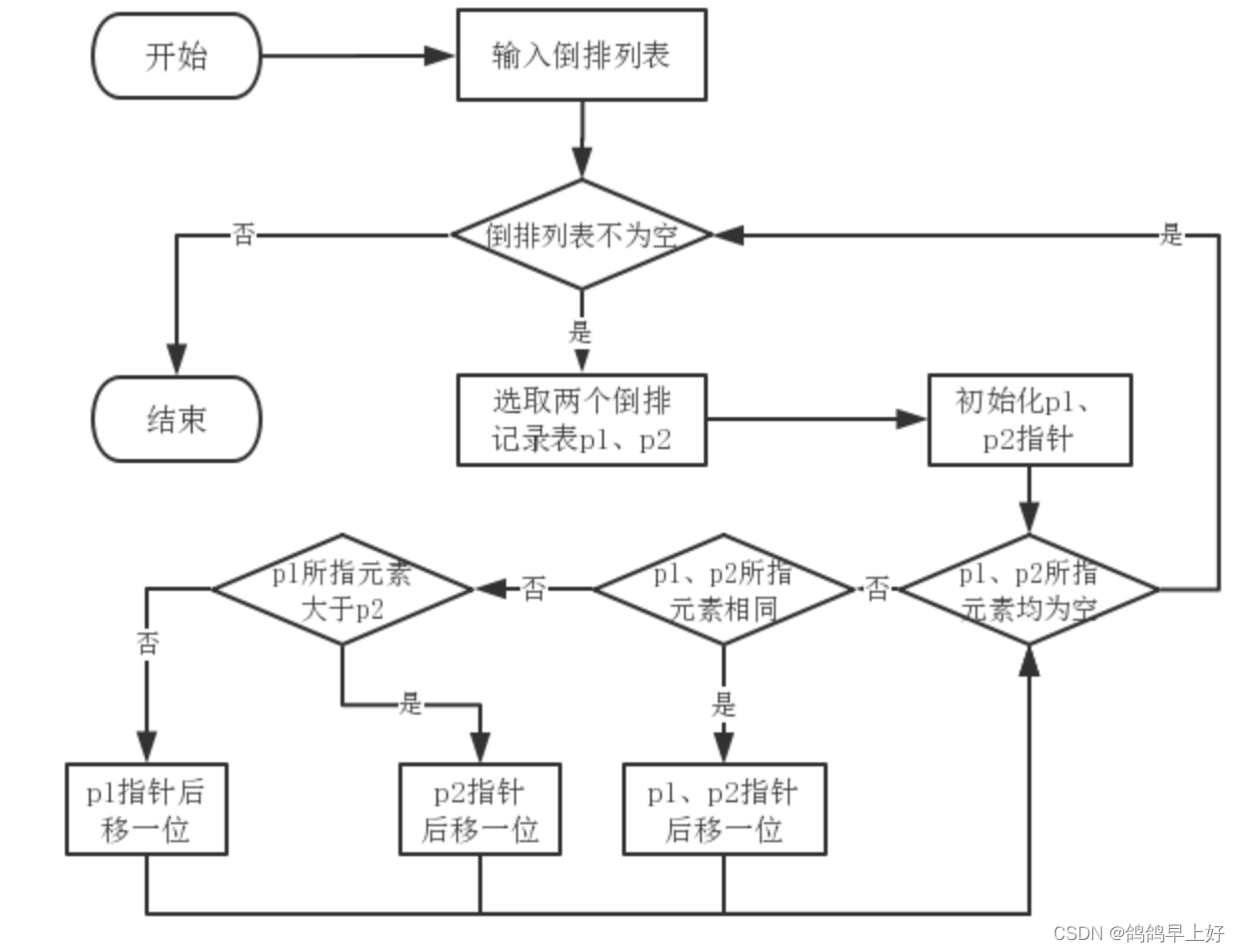
#sdnu 202011000106
def Intersect(p1, p2):
r = []
i, j = 0, 0
lp1, lp2 = len(p1), len(p2)
while(i < lp1 and j < lp2):
if(p1[i] == p2[j]):
r.append(p1[i])
i, j = i + 1, j + 1
elif(p1[i] > p2[j]):
j = j + 1
else:
i = i + 1
return r
print("输入第一个词项的倒排记录表,文档ID之间用“,”分隔:", end = '')
p1 = input().split(",")
p1 = [int(i) for i in p1]
print("输入第二个词项的倒排记录表,文档ID之间用“,”分隔:", end = '')
p2 = input().split(",")
p2 = [int(i) for i in p2]
#p1 = [1,2,3]
#p2 = [3,4,5]
print("合并结果为:", Intersect(p1, p2))
Intersect函数为倒排记录表计算模块,首先通过len函数获取倒排记录表长度,然后通过下标循环获取记录表元素,通过数值判断合并记录表并存储到新的列表中,最终返回该结果列表。
Input函数获取用户输入字符串,split(“,”)函数对字符串进行切分,[int]方法则将字符串转化为数值列表。
主函数省略,可供参考网址:【原创】python倒排索引之查找包含某主题或单词的文件 - 西西嘛呦 - 博客园 (cnblogs.com)
布尔检索模型简单实现 - 代码先锋网 (codeleading.com)
优点:构建简单,或许是构建IR系统的一种最简单方式;易被接收,仍是目前最主流的检索方式之一;操作专业化,对于非常清楚想要查什么、能得到什么的用户而言,布尔检索是个强有力的检索工具。
缺点:布尔查询构建复杂,不适合普通用户。如果构建不当, 检索结果就会过多或者过少;没有充分利用词项的频率信息;不能对检索结果进行排序。
有两个简单的优化方法:
倒排表的文档ID升序排列:正如在AND操作中演示的那样,文档ID升序排列可以尽量地提前结束对倒排表的操作,而不需要对两个倒排表从头到尾进行检索。
优先处理词频小的词项:在复杂布尔表达式中,例如(tangerine OR trees) AND (marmalade OR skies) AND (kaleidoscope OR eyes),优先合并词频小的词项,生成文档数量少的词项,有利于结合上面的优化方法尽量地提前结束对倒排表的操作。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案