本文说明的是Kafka的客户端(生产者、消费者)与broker之前的限流,不是kafka的broker间topic副本同步的限流。
在kafka的官方文档,不叫限流,叫做资源配额:通过对客户端请求进行配额,控制集群资源的使用。
主要支持以下两种类型:
带宽就是基于每秒传输多少个字节来进行限制;但是,注意,请求速率并不是每秒客户端可以发起多少个请求,而是网络和 I/O线程 cpu利用率的百分比。
kafka 客户端以“组”来进行配额限流。同组下的所有客户端共享带宽配置,比如:配置带宽10M/秒,则该组所有客户端限制总带宽使用为10M每秒;但是请求速率指的是每个组的client 使用broker上的cpu的百分比。
组的分类规则如下:
client-id: 客户端ID,这个比较熟悉,比如在启动一个消费者的时候,配置的一个属性:
// client.id
props.put(ConsumerConfig.CLIENT_ID_CONFIG, "test-consumer-id");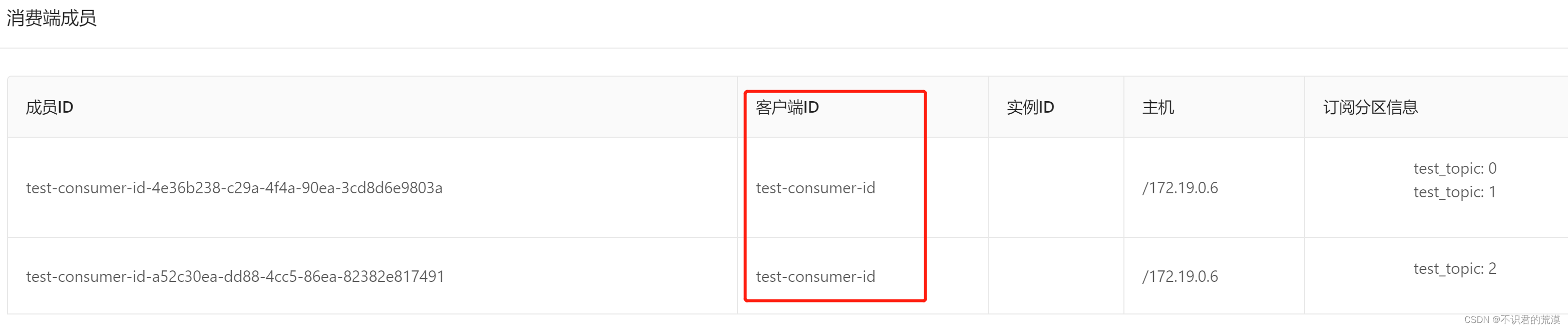 如果不配置,会生成一个默认的:
如果不配置,会生成一个默认的:

User需要是开启ACL之后的一个用户主体标识,很多同学如果没用过kafka的ACL,可能对这个不太了解,可以看下这个:kafka快速配置启用ACL示例_不识君的荒漠的博客-CSDN博客_kafka-acls.sh --bootstrap-server
而(user, client-id)这个二元组,就是需要同时指定用户主体标识和客户端ID作为一组分类。
我目前查看官方3.3的文档 Kafka 3.3 Documentation这些配置信息还是在zookeeper上:
数字越小,优先级越高。
注意:支持broker级别的配置,但是未验证(我目前用来测试的版本是2.8)。
1. 基于(user, client-id)限流配置
sh bin/kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-type users --entity-name userName --entity-type clients --entity-name clientId2. 指定用户
sh bin/kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-type users --entity-name userName3. 用户级默认配置
sh bin/kafka-configs.sh --bootstrap-server localhost:9092 --alter --add-config 'producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200' --entity-type users --entity-default
4. 指定客户端ID
sh bin/kafka-configs.sh --bootstrap-server localhost:9092 --alter --add-config 'producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200' --entity-type clients --entity-name clientId
5. 客户端ID级默认配置
sh bin/kafka-configs.sh --bootstrap-server localhost:9092 --alter --add-config 'producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200' --entity-type clients --entity-default
6. (user, client-id)级默认配置
sh bin/kafka-configs.sh --bootstrap-server localhost:9092 --alter --add-config 'producer_byte_rate=1024,consumer_byte_rate=2048,request_percentage=200' --entity-type users --entity-name userName --entity-type clients --entity-default
7. 查看(user, client-id)级配置
sh bin/kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-type users --entity-name userName --entity-type clients --entity-name clientId
8. 查看用户级配置
sh bin/kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-type users --entity-name userName
如果不指定--entity-name,则是查看所有用户
9. 查看客户端ID级配置
sh bin/kafka-configs.sh --bootstrap-server localhost:9092 --describe --entity-type clients --entity-name clientId如果不指定--entity-name,则是查看所有客户端ID的配置
注意:
推荐查看:
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我真的为这个而疯狂。我一直在搜索答案并尝试我找到的所有内容,包括相关问题和stackoverflow上的答案,但仍然无法正常工作。我正在使用嵌套资源,但无法使表单正常工作。我总是遇到错误,例如没有路线匹配[PUT]"/galleries/1/photos"表格在这里:/galleries/1/photos/1/edit路线.rbresources:galleriesdoresources:photosendresources:galleriesresources:photos照片Controller.rbdefnew@gallery=Gallery.find(params[:galle
我正在尝试将一个资源属性的默认值设置为另一个属性的值。我正在为我正在构建的tomcat说明书定义一个资源,其中包含以下定义。我想要可以独立设置的“名称”和“服务名称”属性。当未设置服务名称时,我希望它默认为为“名称”提供的任何内容。以下不符合我的预期:attribute:name,:kind_of=>String,:required=>true,:name_attribute=>trueattribute:service_name,:kind_of=>String,:default=>:name注意第二行末尾的“:default=>:name”。当我在Recipe的新block中引用我
我想在Ruby的TCPServer中获取客户端的IP地址。以及(如果可能的话)MAC地址。例如,Ruby中的时间服务器,请参阅评论。tcpserver=TCPServer.new("",80)iftcpserverputs"Listening"loopdosocket=tcpserver.acceptifsocketThread.newdoputs"Connectedfrom"+#HERE!HowcanigettheIPAddressfromtheclient?socket.write(Time.now.to_s)socket.closeendendendend非常感谢!
我有一个模型User,它在创建后的回调中创建了选项#Userhas_one:user_optionsafter_create:create_optionsprivatedefcreate_optionsUserOptions.create(user:self)end我对此有一些简单的Rspec覆盖:describe"newuser"doit"createsuser_optionsaftertheuseriscreated"douser=create(:user)user.user_options.shouldbe_kind_of(UserOptions)endend一切正常,直到我将自
假设我们有两个资源:template'template1'doowner'root'group'root'endtemplate'template2'doowner'root'group'root'end我想在资源中重用代码。但是,如果我在配方中定义了一个过程,您会得到owner、group等的NoMethodError。为什么会这样?词法范围没有什么不同,是吗?因此,我必须使用self.instance_eval&common_cfg。common_cfg=Proc.new{owner'root'group'root'}template'template1'docommon_cfg.
当我尝试使用“套接字”库中的方法“read_nonblock”时出现以下错误IO::EAGAINWaitReadable:Resourcetemporarilyunavailable-readwouldblock但是当我通过终端上的IRB尝试时它工作正常如何让它读取缓冲区? 最佳答案 IgetthefollowingerrorwhenItrytousethemethod"read_nonblock"fromthe"socket"library当缓冲区中的数据未准备好时,这是预期的行为。由于异常IO::EAGAINWaitReadab
我正在尝试使用RubyEventMachine访问使用SSL证书身份验证的HTTPSWeb服务,但我没有让它工作。我编写了以下简单代码块来对其进行端到端测试:require'rubygems'require'em-http'EventMachine.rundourl='https://foobar.com/'ssl_opts={:private_key_file=>'/tmp/private.key',:cert_chain_file=>'/tmp/ca.pem',:verify_peer=>false}http=EventMachine::HttpRequest.new(url).g
我正在为需要与API建立SSL连接的客户端开发应用程序。我得到了三个文件;一个信任根证书(.cer)文件、一个中间证书(.cer)文件和一个签名的响应文件。我得到的安装说明与IIS或Javakeytool程序有关;我正在用RubyonRails构建应用程序,所以这两种方法都不是一个选项(据我所知)。证书由运行API服务的组织自签名,看来我获得了客户端证书以相互验证https连接。我不确定如何使用我的应用程序中的证书连接和使用API签名响应文件的作用我读过"Usingaself-signedcertificate"和thisarticleonOpenSSLinRuby但两者似乎都不是很到
我很难给出正确的答案,所以我会在这里征求我的问题。我正在研究RESTFulAPI。自然地,我有多种资源,其中一些由父子关系组成,一些是独立资源。我有点困难的地方是弄清楚如何让那些将根据我的API构建客户端的人更容易。情况是这样的。假设我有一个“街道”资源。每条街道都有多个住宅。SoStreet:has_manytoHomes和Homes:belongs_toStreet。如果用户想要在特定的home资源上请求HTTPGET,以下应该可行:http://mymap/streets/5/homes/10这允许用户获取ID为10的房屋的信息。直截了当。我的问题是,我授予用户访问权限是否违反了