在前面知识点docker的就提到过k8s,相当于到docker的一个脚手架或者说是一个管理编排容器的工具,但这个脚手架是怎么来的呢?
最开始专门的运维工作很复杂,因此在运维工程师技术领域出现了一个技术叫Ansible,使得运维工程师很多工作可以定制化出来交给程序执行。
到2014年左右随着docker的出现,使得运维工作,可以让我们开发人员也参与进来,但是docker在早期,它的功能还不是很强大,只能对于单台docker host主机,进行容器的操作,同时它自带了一个管理工具docker compose,随着后期的发展,docker在docker host的基础上发展出了虚拟资源池的概念,也就是到docker swarm,但是使用起来还是不方便。因为所有资源池内的服务器不只要满足自身是docker的主机,还要满足加入swarm的条件,所以docker又出了一个预处理工具machine,可以让docker主机满足加入资源池的条件。
这三个玩意儿在当年业界被称为docker运维三剑客。但是后期k8s杀出重围,在大厂之间被广泛应用,甚至有很多的大厂能够将自己的k8s体系开放出去,让用户直接在其上做容器的托管,占据了80%多的市场份额,可想而知k8s当时是多么的强势。所以迫使docker官方在2017年底没有办法捏着鼻子认了,把k8s加入到自己的体系内,同时支持swarm和k8s两种容器编排方式。
k8s其实是个简称,它的全称叫kubernetes。根据官方的说法,k8s可以实现的技术特点有自动装箱,也就是前面docker知识中提到的容器的生成,不过K8s是自己根据配置好的约束生成。自我修复因为容器的轻量化,它的启动很快,所以k8s可以在一个容器崩了之后,在秒级内重启,但其实在实际使用上,会发现k8s很少会去重启某个容器,而是在一个容器崩了之后直接Kill掉,用备份的容器顶上,这也可以说是k8s的一种思想,抛弃对单个容器的关注,保证整个大集群本身的安全。自动实现水平扩展,就比如前面docker的知识点,提到过阿里双11,怎样保证服务器足够?这就是k8s的水平扩展100个,不行就扩展200个,200个不行再扩,只要你物理宿主机资源能够撑得住。自动实现服务发现和负载均衡,服务发现就是说在k8s里面的有运行的容器,都可以通过k8s查找到它的信息,而当一类服务对应的启动了多个容器,可以自动实现负载均衡。还可以实现自动发布和回滚。以及提供密钥和容器的配置管理的功能。
注意:K8s底层操作的最小可运行单元不是容器,而是pod,下面会解释pod,为了方便理解,这里暂时称作为容器。
从k8s技术本身来说,整个k8s也是使用高可用的搭建模式,主节点一般两到三个,其他的都是node节点,用来跑容器。和大数据hadoop差不多,也是有一个yarn那样的资源调度体系,所以docker本身其实不关注于资源的把控,只要宿主机就撑得住,就可以一直run容器,但有了k8s这样的容器编排技术之后,就显得更加完整。
在k8s的master节点里,有四个很重要的东西,一个叫API Server用来接收容器的操作请求,第二个叫Scheduler,和yarn一样是一个调度器,第三个叫Controller Manager叫做控制器管理器,这个组件比较绕,它是用来确保控制器健康,而控制器是用来确保容器处于健康状态。之所以看上去有点绕,是因为k8s支持不同种类的控制器,每种控制器是K8s对Pod操作的直接负责对象,比如Pod状态监控、筛选、水平扩容、容器的多退少补等等。当然还有最后一个保证k8s各节点任务运行的kubelet。
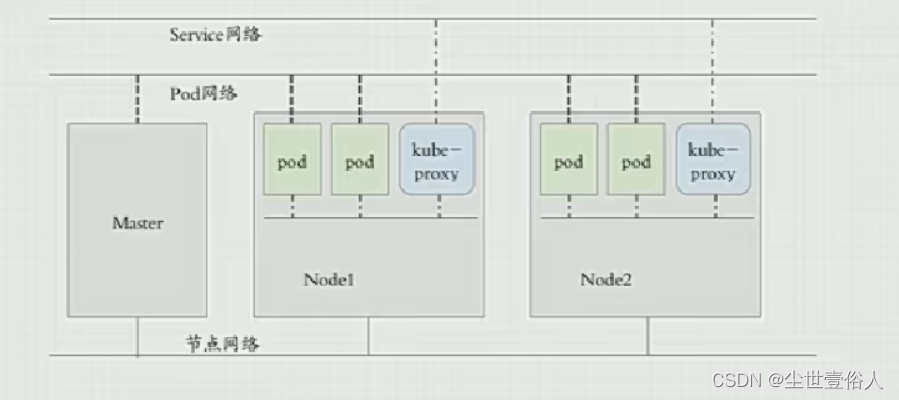
说完master节点,同样的node节点相对的也有几个角色,第一个是kubelet,这一点就和hadoop很像但又不同,hadoop节点之间的资源通讯主要是依靠yarn体系下的resourcemanager和nodemanager,而k8s是相对独立的kubelet和scheduler。第二个就是第三方容器引擎,比如docker。第三个是kule-proxy,它负责和主节点的API Server通信,维护所有Pod的所在地址。
上面提到过,对于k8s来说,最小可运行的逻辑单元,不再是单一的容器而是pod。不过在操作上仍然可以操作到容器这一层,是属于pod的一个部分。在k8s内部将容器用pod的概念管理,让一个pod下的容器有着密切的关系,且一个pod下的容器一定是在同一节点上的。如果这个pod整个崩掉,k8s会重新给node节点分配任务。pod和控制器依靠着心跳机制实现状态的通信。不过一般情况下项目上一个pod只运行一个容器,这样有利于pod的管理,当然也有多个的时候比如用另一个容器去查日志之类的辅助操作,总之一个pod下多个容器的情况很少发生,还有一个根本原因就是在实际使用中如果一个pod下多容器时,其中一个容器挂掉,你会发现k8s只会将这个容器的状态改为不可用,而不是去容灾这个容器,而我们通常会有很多pod,要在这么多的pod中找到哪个pod出了问题?再去想办法去修复它,这无论是在实操还是容器技术本身的用意上都是背道而驰的,所以除特殊情况外,我们都是一个pod中,只有一个容器,使得容器挂掉,整个pod就挂了让k8s去容灾,就连上面说到的负载均衡,其实本质上也是让k8s实例了很多pod副本。
Pod的也分三种,当然官方并没有给Pod分类,只是在我们使用上的划分,一种叫自主式Pod,当你使用配置清单方式操作时生成的pod通常就是自主式的,这类pod可以操作的颗粒度很细。另一种叫控制器管理的Pod,这种Pod出现在命令行操作时产生,操作起来非常方便,但是可配置性不高。第三种不是我们用户使用的,而是k8s中基础架构的一部分也就是附件类的Pod,这种Pod使得k8s的功能更健壮。是不是自主式如果大家无法区分,目前可以通俗地理解为,只要这个pod没有对应的控制器,它就是自主式的,K8s不会去管它的死活。
最后一个知识点是整个k8s集群,有三个网络概念,各节点之间系统通讯有着节点网路负责,比如master和node的通信。不同Pod之间有着Pod网络,使得同一节点下的Pod它们可以通过直接路由等方式通信,后面的知识点会提到这是依赖于宿主机上的虚拟网卡。不同节点Pod的通信,靠的是Service网络,本质上是一个k8s的附件Pod,它和各节点之间的kule-proxy配合,使得Pod可以跨节点通讯。
应该注意的是Service网络和Pod网络其实很相似,它们都是用来在集群内部使用,让Pod之间可以实现互通,不同的是,Pod网络是让pod拥有可通信地址,而service是用来代理pod网络的。我们在实际操作的时候,不同节点之间抛开service网络,k8s自己集群内部不同节点的pod是没有办法通讯的,但是我们实操的时候,可以发现在不同节点,我们通过ping命令可以发现不同节点的pod,这个能力不是k8s自身提供的,而是容器引擎基于虚拟网卡提供了直接路由的条件,如果k8s自己只使用pod网络,那么不同节点之间的pod通信是会出问题的,而Service是k8s提供的用来代理Pod网络,默认只面向所有Pod端,提供一个固定的能让不同节点上所有pod都可以访问到的DNS网络,并且解决了所有Pod之间由于Pod重启等原因造成的访问方式改变等问题。这一点后面的知识点会体现。不过默认情况下,service是不让非代理pod节点直接去使用的,这一点后面的知识点会有例子。
运行bundleinstall后出现此错误:Gem::Package::FormatError:nometadatafoundin/Users/jeanosorio/.rvm/gems/ruby-1.9.3-p286/cache/libv8-3.11.8.13-x86_64-darwin-12.gemAnerroroccurredwhileinstallinglibv8(3.11.8.13),andBundlercannotcontinue.Makesurethat`geminstalllibv8-v'3.11.8.13'`succeedsbeforebundling.我试试gemin
我已经通过提供MagickWand.h的路径尝试了一切,我安装了命令工具。谁能帮帮我?$geminstallrmagick-v2.13.1Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingrmagick:ERROR:Failedtobuildgemnativeextension./Users/ghazanfarali/.rvm/rubies/ruby-1.8.7-p357/bin/rubyextconf.rbcheckingforRubyversion>=1.8.5...yescheckingfor/
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我最近开始学习Ruby,这是我的第一门编程语言。我对语法感到满意,并且我已经完成了许多只教授相同基础知识的教程。我已经写了一些小程序(包括我自己的数组排序方法,在有人告诉我谷歌“冒泡排序”之前我认为它非常聪明),但我觉得我需要尝试更大更难的东西来理解更多关于Ruby.关于如何执行此操作的任何想法?
自从我将我的应用程序部署到heroku以来,在过去的几天里,我一直在断断续续地收到这个错误。它发生在我开始使用unicorn作为服务器之前和之后。有时我可以通过使用herokurunrakedb:migrate然后herokurestart让它恢复运行,但这只修复了几个小时,它又坏了。至于网页,它说“应用程序错误”。日志不是很有用,但每次发生此错误时都会显示以下内容:[2014-10-27T21:13:31.675956#2]ERROR--:worker=1PID:8timeout(16s>15s),killing[2014-10-27T21:13:31.731646#14]INFO-
文章目录一、污点(Taint)1、污点简介2、污点的组成3、污点的设置和去除二、容忍(Tolerations)1、容忍简介2、容忍的基本用法3、示例4、多污点与多容忍配置三、警戒(cordon)和转移(drain)四、Pod启动阶段(相位phase)五、故障排除步骤一、污点(Taint)节点亲和性,是Pod的一种属性(偏好或硬性要求),它使Pod被吸引到一类特定的节点Taint则相反,它使节点能够排斥一类特定的PodTaint和Toleration相互配合,可以用来避免Pod被分配到不合适的节点上。每个节点上都可以应用一个或多个taint,这表示对于那些不能容忍这些taint的Pod,是不会被
Asitcurrentlystands,thisquestionisnotagoodfitforourQ&Aformat.Weexpectanswerstobesupportedbyfacts,references,orexpertise,butthisquestionwilllikelysolicitdebate,arguments,polling,orextendeddiscussion.Ifyoufeelthatthisquestioncanbeimprovedandpossiblyreopened,visitthehelpcenter提供指导。已关闭8年。什么是学习ruby语言
考拉版本:2.2.0Errormessage:/scss/styles.scss/System/Library/Frameworks/Ruby.framework/Versions/2.3/usr/lib/ruby/2.3.0/rubygems/dependency.rb:319:into_specs':Couldnotfind'sass'(>=0)among15totalgem(s)(Gem::LoadError)Checkedin'GEM_PATH=/Users/monstercritic/.gem/ruby/2.3.0:/Library/Ruby/Gems/2.3.0:/Syst
当我尝试安装rmagic时:geminstallrmagic它给出了错误:Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingrmagick:ERROR:Failedtobuildgemnativeextension./home/biske/.rbenv/versions/2.0.0-p247/bin/rubyextconf.rbcheckingforRubyversion>=1.8.5...yescheckingforgcc...yescheckingforMagick-config...yesche
我最近注意到ActiveRecord对象上的方法changed?在Rails3.2.13和Rails4.0.1之间发生了变化。问题在于连接到数据库中整数字段的字段。假设我的模型Model带有number整数字段:#Rails3.2.13m=Model.lastm.number#=>5m.number='5hello'm.number#=>5m.number_changed?#=>truem.changed?#=>truem.changes#=>{:number=>[5,5]}#Rails4.0.1m=Model.lastm.number#=>5m.number='5hello'm.nu
我们有一个Rubyv.2.0.0-p247在Railsv4.0.1应用程序使用pggemv0.17.0.应用在MacOSXMavericksv10.9下顺利运行与PostgreSQLServerv9.2.4使用HomeBrew安装但它在Ubuntuv13.04下抛出以下异常使用PostgreSQLServer9.1:PG::UnableToSend:serverclosedtheconnectionunexpectedlyThisprobablymeanstheserverterminatedabnormallybeforeorwhileprocessingtherequest.异常发