yolo无痛涨点trick,简单实用
先贴一张最近一篇论文的结果
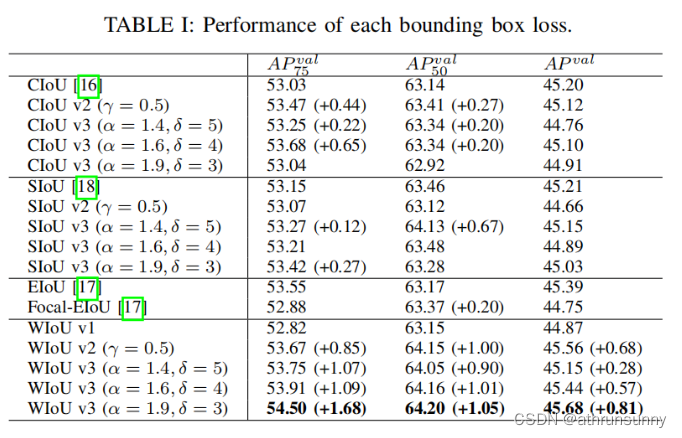
后来的几种iou的消融实验结果在一定程度上要优于CIoU。
本文将在yolov5的基础上增加SIoU,EIoU,Focal-XIoU(X为C,D,G,E,S等)以及AlphaXIoU。
在yolov5的utils文件夹下新增iou.py文件
import math
import torch
def bbox_iou(box1,
box2,
xywh=True,
GIoU=False,
DIoU=False,
CIoU=False,
SIoU=False,
EIoU=False,
WIoU=False,
Focal=False,
alpha=1,
gamma=0.5,
scale=False,
monotonous=False,
eps=1e-7):
"""
计算bboxes iou
Args:
box1: predict bboxes
box2: target bboxes
xywh: 将bboxes转换为xyxy的形式
GIoU: 为True时计算GIoU LOSS (yolov5自带)
DIoU: 为True时计算DIoU LOSS (yolov5自带)
CIoU: 为True时计算CIoU LOSS (yolov5自带,默认使用)
SIoU: 为True时计算SIoU LOSS (新增)
EIoU: 为True时计算EIoU LOSS (新增)
WIoU: 为True时计算WIoU LOSS (新增)
Focal: 为True时,可结合其他的XIoU生成对应的IoU变体,如CIoU=True,Focal=True时为Focal-CIoU
alpha: AlphaIoU中的alpha参数,默认为1,为1时则为普通的IoU,如果想采用AlphaIoU,论文alpha默认值为3,此时设置CIoU=True则为AlphaCIoU
gamma: Focal_XIoU中的gamma参数,默认为0.5
scale: scale为True时,WIoU会乘以一个系数
monotonous: 3个输入分别代表WIoU的3个版本,None: origin v1, True: monotonic FM v2, False: non-monotonic FM v3
eps: 防止除0
Returns:
iou
"""
# Returns Intersection over Union (IoU) of box1(1,4) to box2(n,4)
# Get the coordinates of bounding boxes
if xywh: # transform from xywh to xyxy
(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)
w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2
b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_
b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_
else: # x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
w1, h1 = b1_x2 - b1_x1, (b1_y2 - b1_y1).clamp(eps)
w2, h2 = b2_x2 - b2_x1, (b2_y2 - b2_y1).clamp(eps)
# Intersection area
inter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp(0) * \
(b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp(0)
# Union Area
union = w1 * h1 + w2 * h2 - inter + eps
if scale:
wise_scale = WIoU_Scale(1 - (inter / union), monotonous=monotonous)
# IoU
# iou = inter / union # ori iou
iou = torch.pow(inter / (union + eps), alpha) # alpha iou
if CIoU or DIoU or GIoU or EIoU or SIoU or WIoU:
cw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1) # convex (smallest enclosing box) width
ch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1) # convex height
if CIoU or DIoU or EIoU or SIoU or WIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
c2 = (cw ** 2 + ch ** 2) ** alpha + eps # convex diagonal squared
rho2 = (((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (
b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4) ** alpha # center dist ** 2
if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
v = (4 / math.pi ** 2) * (torch.atan(w2 / h2) - torch.atan(w1 / h1)).pow(2)
with torch.no_grad():
alpha_ciou = v / (v - iou + (1 + eps))
if Focal:
return iou - (rho2 / c2 + torch.pow(v * alpha_ciou + eps, alpha)), torch.pow(inter / (union + eps),
gamma) # Focal_CIoU
return iou - (rho2 / c2 + torch.pow(v * alpha_ciou + eps, alpha)) # CIoU
elif EIoU:
rho_w2 = ((b2_x2 - b2_x1) - (b1_x2 - b1_x1)) ** 2
rho_h2 = ((b2_y2 - b2_y1) - (b1_y2 - b1_y1)) ** 2
cw2 = torch.pow(cw ** 2 + eps, alpha)
ch2 = torch.pow(ch ** 2 + eps, alpha)
if Focal:
return iou - (rho2 / c2 + rho_w2 / cw2 + rho_h2 / ch2), torch.pow(inter / (union + eps), gamma) # Focal_EIou
return iou - (rho2 / c2 + rho_w2 / cw2 + rho_h2 / ch2) # EIou
elif SIoU:
# SIoU Loss https://arxiv.org/pdf/2205.12740.pdf
s_cw, s_ch = (b2_x1 + b2_x2 - b1_x1 - b1_x2) * 0.5 + eps, (b2_y1 + b2_y2 - b1_y1 - b1_y2) * 0.5 + eps
sigma = torch.pow(s_cw ** 2 + s_ch ** 2, 0.5)
sin_alpha_1, sin_alpha_2 = torch.abs(s_cw) / sigma, torch.abs(s_ch) / sigma
threshold = pow(2, 0.5) / 2
sin_alpha = torch.where(sin_alpha_1 > threshold, sin_alpha_2, sin_alpha_1)
angle_cost = torch.cos(torch.arcsin(sin_alpha) * 2 - math.pi / 2)
rho_x, rho_y = (s_cw / cw) ** 2, (s_ch / ch) ** 2
gamma = angle_cost - 2
distance_cost = 2 - torch.exp(gamma * rho_x) - torch.exp(gamma * rho_y)
omiga_w, omiga_h = torch.abs(w1 - w2) / torch.max(w1, w2), torch.abs(h1 - h2) / torch.max(h1, h2)
shape_cost = torch.pow(1 - torch.exp(-1 * omiga_w), 4) + torch.pow(1 - torch.exp(-1 * omiga_h), 4)
if Focal:
return iou - torch.pow(0.5 * (distance_cost + shape_cost) + eps, alpha), torch.pow(
inter / (union + eps), gamma) # Focal_SIou
return iou - torch.pow(0.5 * (distance_cost + shape_cost) + eps, alpha) # SIou
elif WIoU:
if scale:
return getattr(WIoU_Scale, '_scaled_loss')(wise_scale), (1 - iou) * torch.exp((rho2 / c2)), iou # WIoU v3 https://arxiv.org/abs/2301.10051
return iou, torch.exp((rho2 / c2)) # WIoU v1
if Focal:
return iou - rho2 / c2, torch.pow(inter / (union + eps), gamma) # Focal_DIoU
return iou - rho2 / c2 # DIoU
c_area = cw * ch + eps # convex area
if Focal:
return iou - torch.pow((c_area - union) / c_area + eps, alpha), torch.pow(inter / (union + eps), gamma) # Focal_GIoU https://arxiv.org/pdf/1902.09630.pdf
return iou - torch.pow((c_area - union) / c_area + eps, alpha) # GIoU https://arxiv.org/pdf/1902.09630.pdf
if Focal:
return iou, torch.pow(inter / (union + eps), gamma) # Focal_IoU
return iou # IoU
class WIoU_Scale:
"""
monotonous: {
None: origin v1
True: monotonic FM v2
False: non-monotonic FM v3
}
momentum: The momentum of running mean
"""
iou_mean = 1.
_momentum = 1 - pow(0.5, exp=1 / 7000)
_is_train = True
def __init__(self, iou, monotonous=False):
self.iou = iou
self.monotonous = monotonous
self._update(self)
@classmethod
def _update(cls, self):
if cls._is_train: cls.iou_mean = (1 - cls._momentum) * cls.iou_mean + \
cls._momentum * self.iou.detach().mean().item()
@classmethod
def _scaled_loss(cls, self, gamma=1.9, delta=3):
if isinstance(self.monotonous, bool):
if self.monotonous:
return (self.iou.detach() / self.iou_mean).sqrt()
else:
beta = self.iou.detach() / self.iou_mean
alpha = delta * torch.pow(gamma, beta - delta)
return beta / alpha
return 1
在调用bbox_iou函数的地方做如下修改(主要是__call__中):
class ComputeLoss:
sort_obj_iou = False
# Compute losses
def __init__(self, model, autobalance=False):
device = next(model.parameters()).device # get model device
h = model.hyp # hyperparameters
# Define criteria
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
# Focal loss
g = h['fl_gamma'] # focal loss gamma
if g > 0:
BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
m = de_parallel(model).model[-1] # Detect() module
self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
self.ssi = list(m.stride).index(16) if autobalance else 0 # stride 16 index
self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
self.na = m.na # number of anchors
self.nc = m.nc # number of classes
self.nl = m.nl # number of layers
self.anchors = m.anchors
self.device = device
def __call__(self, p, targets): # predictions, targets
lcls = torch.zeros(1, device=self.device) # class loss
lbox = torch.zeros(1, device=self.device) # box loss
lobj = torch.zeros(1, device=self.device) # object loss
tcls, tbox, indices, anchors = self.build_targets(p, targets) # targets
# Losses
for i, pi in enumerate(p): # layer index, layer predictions
b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
tobj = torch.zeros(pi.shape[:4], dtype=pi.dtype, device=self.device) # target obj
n = b.shape[0] # number of targets
if n:
# pxy, pwh, _, pcls = pi[b, a, gj, gi].tensor_split((2, 4, 5), dim=1) # faster, requires torch 1.8.0
pxy, pwh, _, pcls = pi[b, a, gj, gi].split((2, 2, 1, self.nc), 1) # target-subset of predictions
# Regression
pxy = pxy.sigmoid() * 2 - 0.5
pwh = (pwh.sigmoid() * 2) ** 2 * anchors[i]
pbox = torch.cat((pxy, pwh), 1) # predicted box
# iou = bbox_iou(pbox, tbox[i], CIoU=True).squeeze() # iou(prediction, target)
# lbox += (1.0 - iou).mean() # iou loss
# //
iou = bbox_iou(pbox, tbox[i], WIoU=True, scale=True)
if isinstance(iou, tuple):
if len(iou) == 2:
lbox += (iou[1].detach().squeeze() * (1 - iou[0].squeeze())).mean()
iou = iou[0].squeeze()
else:
lbox += (iou[0] * iou[1]).mean()
iou = iou[2].squeeze()
else:
lbox += (1.0 - iou.squeeze()).mean() # iou loss
iou = iou.squeeze()
# /
# Objectness
iou = iou.detach().clamp(0).type(tobj.dtype)
if self.sort_obj_iou:
j = iou.argsort()
b, a, gj, gi, iou = b[j], a[j], gj[j], gi[j], iou[j]
if self.gr < 1:
iou = (1.0 - self.gr) + self.gr * iou
tobj[b, a, gj, gi] = iou # iou ratio
# Classification
if self.nc > 1: # cls loss (only if multiple classes)
t = torch.full_like(pcls, self.cn, device=self.device) # targets
t[range(n), tcls[i]] = self.cp
lcls += self.BCEcls(pcls, t) # BCE
# Append targets to text file
# with open('targets.txt', 'a') as file:
# [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
obji = self.BCEobj(pi[..., 4], tobj)
lobj += obji * self.balance[i] # obj loss
if self.autobalance:
self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
if self.autobalance:
self.balance = [x / self.balance[self.ssi] for x in self.balance]
lbox *= self.hyp['box']
lobj *= self.hyp['obj']
lcls *= self.hyp['cls']
bs = tobj.shape[0] # batch size
return (lbox + lobj + lcls) * bs, torch.cat((lbox, lobj, lcls)).detach()
def build_targets(self, p, targets):
# Build targets for compute_loss(), input targets(image,class,x,y,w,h)
na, nt = self.na, targets.shape[0] # number of anchors, targets
tcls, tbox, indices, anch = [], [], [], []
gain = torch.ones(7, device=self.device) # normalized to gridspace gain
ai = torch.arange(na, device=self.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
targets = torch.cat((targets.repeat(na, 1, 1), ai[..., None]), 2) # append anchor indices
g = 0.5 # bias
off = torch.tensor(
[
[0, 0],
[1, 0],
[0, 1],
[-1, 0],
[0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
],
device=self.device).float() * g # offsets
for i in range(self.nl):
anchors, shape = self.anchors[i], p[i].shape
gain[2:6] = torch.tensor(shape)[[3, 2, 3, 2]] # xyxy gain
# Match targets to anchors
t = targets * gain # shape(3,n,7)
if nt:
# Matches
r = t[..., 4:6] / anchors[:, None] # wh ratio
j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
t = t[j] # filter
# Offsets
gxy = t[:, 2:4] # grid xy
gxi = gain[[2, 3]] - gxy # inverse
j, k = ((gxy % 1 < g) & (gxy > 1)).T
l, m = ((gxi % 1 < g) & (gxi > 1)).T
j = torch.stack((torch.ones_like(j), j, k, l, m))
t = t.repeat((5, 1, 1))[j]
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
else:
t = targets[0]
offsets = 0
# Define
bc, gxy, gwh, a = t.chunk(4, 1) # (image, class), grid xy, grid wh, anchors
a, (b, c) = a.long().view(-1), bc.long().T # anchors, image, class
gij = (gxy - offsets).long()
gi, gj = gij.T # grid indices
# Append
indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
anch.append(anchors[a]) # anchors
tcls.append(c) # class
return tcls, tbox, indices, anch注意需要从对应的py文件中import对应的函数,并需要注释原始函数
# from utils.metrics import bbox_iou
from utils.iou import bbox_iou
如果需要应用对应的IoU loss的变体,即可将Focal设置为True,并将对应的IoU也设置为True,如CIoU=True,Focal=True时为Focal-CIoU,此时可以调整gamma,默认设置为0.5。
如果想要使用AlphaXIoU,将alpha设置为3同时将对应的IoU也设置为True即可,alpha默认设置为1。
更新WIoU,monotonous有3个输入分别代表WIoU的3个版本,None: origin v1, True: monotonic FM v2, False: non-monotonic FM v3,同时需要设置scale,scale为True时,WIoU会乘以一个系数,结合monotonous即会对应WIoU的3个版本。
yolov7的代码结构也是一样的,也可以替换到yolov7中,__call__中的bbox_iou函数要改成yolov5的调用方式(pbox不用矩阵转置(T))。
这个问题在这里已经有了答案:Checktoseeifanarrayisalreadysorted?(8个答案)关闭9年前。我只是想知道是否有办法检查数组是否在增加?这是我的解决方案,但我正在寻找更漂亮的方法:n=-1@arr.flatten.each{|e|returnfalseife
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使
我有一个页面,有时加载时间超过一分钟。假设这是预期的行为并且不会改变。在这些情况下,我得到Net::ReadTimeout。请注意,这是在通过单击上一页上的按钮导航到页面之后,而不是ajax请求。因此Capybara.using_wait_time没有帮助。我尝试了一些激进的方法(其中一些我知道行不通),例如:设置page.driver.browser.manage.timeouts的implicit_wait、script_timeout和page_load。遍历整个对象空间并设置所有Selenium::WebDriver::Remote::Http::Default的timeout
如果我尝试增加哈希中尚不存在的键的值,就像这样h=Hash.newh[:ferrets]+=1我收到以下错误:NoMethodError:undefinedmethod`+'fornil:NilClass这对我来说很有意义,而且我知道这一定是一个非常简单的问题,但我在SO上找不到它。如果我什至事先不知道我将拥有哪些key,我该如何添加和递增此类key? 最佳答案 可以在构造函数中设置hash的默认值h=Hash.new(0)h[:ferrets]+=1ph[:ferrets]请注意,设置默认值有一些缺陷,因此您必须谨慎使用。h=Ha
我正在使用rest-client发布到一个非常慢的网络服务。我将timeout设置为600秒,并且我已经确认它正在传递给Net::HTTP的@read_timeout和@open_timeout.但是,大约两分钟后,我收到一个低级超时错误,Errno::ETIMEDOUT:Connectiontimedout-connect(2):回溯的相关部分是Operationtimedout-connect(2)for[myhost]port[myport]/Users/dmoles/.rvm/rubies/ruby-2.2.5/lib/ruby/2.2.0/net/http.rb:879:in
这个问题在这里已经有了答案:Whydoesn'tRubysupporti++ori--(increment/decrementoperators)?(9个回答)关闭9年前。是什么导致了以下代码中的错误?ruby-e"puts1++"-e:1:syntaxerror,unexpected$end或ruby-e"x=1;putsx++;"-e:1:syntaxerror,unexpected';'
我如何在Ruby中简化它:x=(x||0)+1? 最佳答案 您可以使用to_i将nil转换为0x=x.to_i+1或者你可以使用succx=x.to_i.succ 关于Ruby:如何增加一个可能为零的数字?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/7440954/
在stackoverflow.com上发布一个堆栈溢出问题,多么有趣:-)我正在运行一些递归Ruby代码,我得到:“堆栈级别太深(SystemStackError)”(我很确定代码有效,我没有陷入无限递归的死亡螺旋,但这不是重点)是否可以更改我的Ruby应用程序允许的堆栈深度/大小?如果这是Ruby中的限制,我不太明白,因为错误显示“堆栈级别”,这给我的印象是Ruby以某种方式计算堆栈的“级别”,或者它只是意味着堆栈满了。我已经尝试在Vista和Ubuntu下运行这个程序,结果相同。在Ubuntu下,我尝试使用“ulimit-s”将堆栈大小从8192更改为16000,但这并没有改变任何
趁着寒假期间稍微尝试跑了一下yolov5和yolov7的代码,由于自己用的笔记本没有独显,台式机虽有独显但用起来并不顺利,所以选择了租云服务器的方式,选择的平台是矩池云(价格合理,操作便捷)需要特别指出的是,如果需要用pycharm链接云服务器训练,必须要使用pycharm的专业版而不是社区版,专业版可以使用SSH服务连接云服务器。关于专业版的获取,据我所知一是可以买,二是如果你是在校大学生,可以用学生证向JetBrain申请专业版使用权,我就是通过这种方式激活专业版账户的,我记得当时两三天官方就发激活邮件了,还是很人性化的,使用期一年。下面开始正题本教程只涉及将yolov5及yolov7跑通
有没有办法让Rails打印出一个带逗号的数字?例如,如果我有一个数字54000000.34,我可以运行,它会打印出“54,000,000.34”谢谢! 最佳答案 你想要number_with_delimiter方法。例如:',')%>或者,您可以使用number_with_precision确保数字始终以小数点后两位精度显示的方法:2,:delimiter=>',')%> 关于ruby-on-rails-rails:Istherearailstricktoaddingcommastola