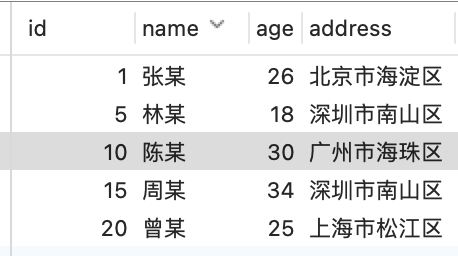
 发现事务 B 的 update 不会阻塞,而事务 C 的 update 会阻塞,都是对 id = 10 这条记录进行 update, 为什么一个会阻塞,一个不会阻塞?
发现事务 B 的 update 不会阻塞,而事务 C 的 update 会阻塞,都是对 id = 10 这条记录进行 update, 为什么一个会阻塞,一个不会阻塞?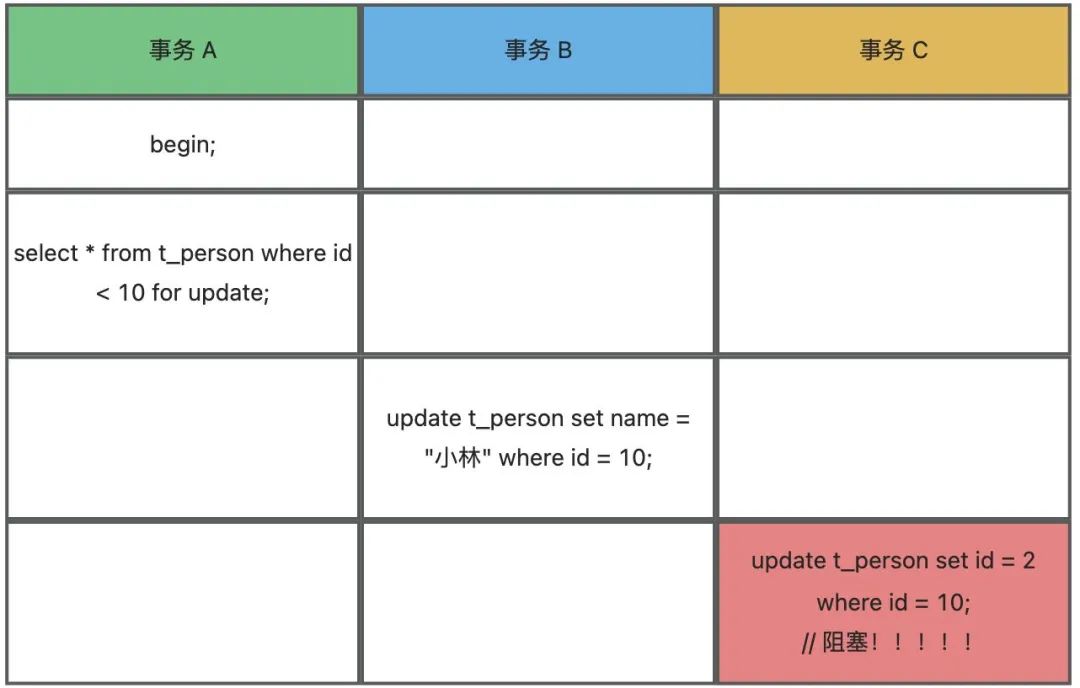 首先,我们先来分析下,事务 A 这条 SQL 加了什么锁。
首先,我们先来分析下,事务 A 这条 SQL 加了什么锁。// 事务 A
select * from t_person where id < 10 for update;// 事务 B
update t_person set name = "小林" where id = 10;事务 C 的 update 语句为什么会阻塞?事务 C 的 update 语句是将 id = 10 的行记录的 id 更新为 2。
// 事务 C
update t_person set id = 2 where id = 10;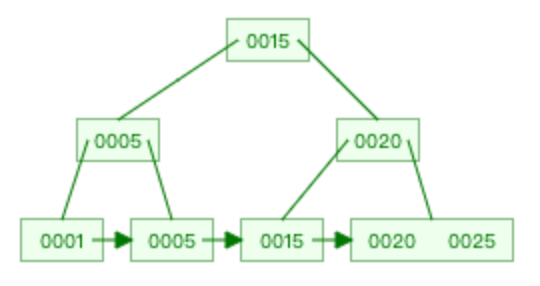 假设这时候需要将索引值为 25 更新为 3,如果直接索引值为 25 的位置上,将值改为 3 的话。
假设这时候需要将索引值为 25 更新为 3,如果直接索引值为 25 的位置上,将值改为 3 的话。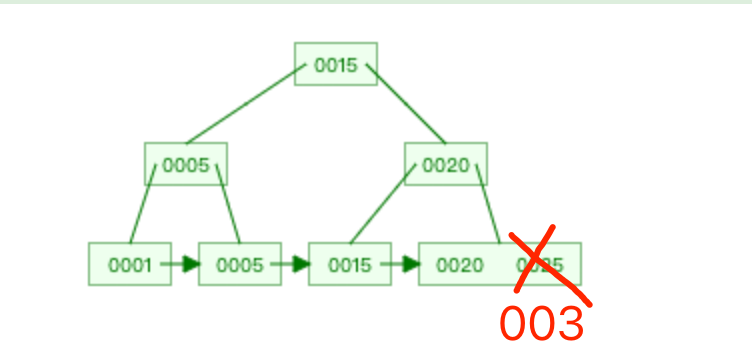 这时候你就会发现这棵 B+ 树不满足顺序性了!所以更新索引的值,不能只是修改一个索引值就完事,而是还要保证更新后的索引值能继续满足 B+ 树的顺序性。解决的方法就是,先删除索引值为 25 的节点,再插入索引值为 3 的节点,这样,这颗 B+ 树才能满足顺序性。
这时候你就会发现这棵 B+ 树不满足顺序性了!所以更新索引的值,不能只是修改一个索引值就完事,而是还要保证更新后的索引值能继续满足 B+ 树的顺序性。解决的方法就是,先删除索引值为 25 的节点,再插入索引值为 3 的节点,这样,这颗 B+ 树才能满足顺序性。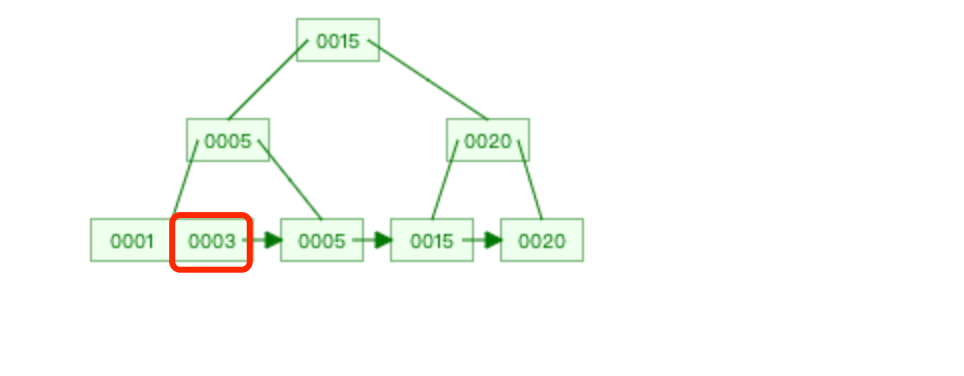 事务 C 的 update 语句具体阻塞在哪个「操作」?现在我们知道,事务 C 的 update 特殊语句背后执行了两个操作,分别是删除和插入操作,那具体是阻塞在哪个「操作 」?「操作 1 」是删除 id = 10 的记录,事务 C 是会在 id = 10 的主键索引上加 X 型记录锁,而事务 A 并没有对 id = 10 的主键索引上加 X 型记录锁,而是对 id = 10 的主键索引上加 X 型间隙锁。间隙锁和记录锁之间是没有互斥关系的,所以「操作 1 」不会阻塞。根据排除法,既然 「操作 1 」不会阻塞,那事务 C 的 update 语句阻塞的原因就是因为 「操作 2」发生了阻塞。为什么「操作2」会发生阻塞呢?我们先要知道,插入操作什么时候会发生阻塞:插入语句在插入一条新记录之前,需要先定位到该记录在 B+树的位置,如果插入的位置的下一条记录的索引上有间隙锁,此时会生成一个插入意向锁,然后锁的状态设置为等待状态,现象就是插入语句会被阻塞。「操作 2」插入的是 id = 2 的新记录,在主键索引的 B+树定位到插入的位置如下图。
事务 C 的 update 语句具体阻塞在哪个「操作」?现在我们知道,事务 C 的 update 特殊语句背后执行了两个操作,分别是删除和插入操作,那具体是阻塞在哪个「操作 」?「操作 1 」是删除 id = 10 的记录,事务 C 是会在 id = 10 的主键索引上加 X 型记录锁,而事务 A 并没有对 id = 10 的主键索引上加 X 型记录锁,而是对 id = 10 的主键索引上加 X 型间隙锁。间隙锁和记录锁之间是没有互斥关系的,所以「操作 1 」不会阻塞。根据排除法,既然 「操作 1 」不会阻塞,那事务 C 的 update 语句阻塞的原因就是因为 「操作 2」发生了阻塞。为什么「操作2」会发生阻塞呢?我们先要知道,插入操作什么时候会发生阻塞:插入语句在插入一条新记录之前,需要先定位到该记录在 B+树的位置,如果插入的位置的下一条记录的索引上有间隙锁,此时会生成一个插入意向锁,然后锁的状态设置为等待状态,现象就是插入语句会被阻塞。「操作 2」插入的是 id = 2 的新记录,在主键索引的 B+树定位到插入的位置如下图。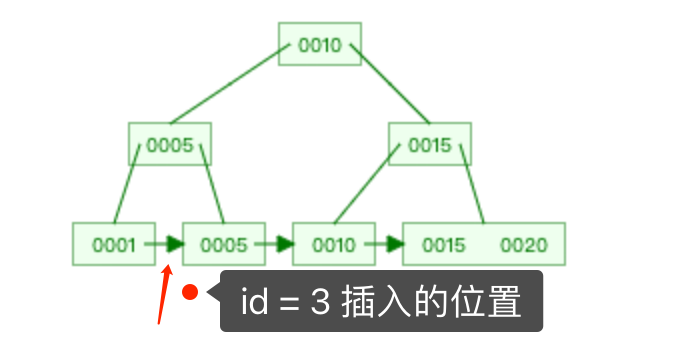 插入位置的下一条记录是 id = 5 的记录,而事务 A 在 id 为 5 的主键索引上已经加了 X 型的 next-key 锁,这里面包含了间隙锁。所以「操作 2」的插入操作会发生阻塞,这就是事务 C 的 update 语句阻塞的原因。从这我们也可以知道间隙锁的作用,就是阻止其他事务在间隙锁的范围内插入新记录,从而避免可重复读隔离级别下幻读的现象。我们也可以通过 select * from performance_schema.data_locks\G; 这条语句,查看事务 C 在加什么锁的时候导致阻塞。
插入位置的下一条记录是 id = 5 的记录,而事务 A 在 id 为 5 的主键索引上已经加了 X 型的 next-key 锁,这里面包含了间隙锁。所以「操作 2」的插入操作会发生阻塞,这就是事务 C 的 update 语句阻塞的原因。从这我们也可以知道间隙锁的作用,就是阻止其他事务在间隙锁的范围内插入新记录,从而避免可重复读隔离级别下幻读的现象。我们也可以通过 select * from performance_schema.data_locks\G; 这条语句,查看事务 C 在加什么锁的时候导致阻塞。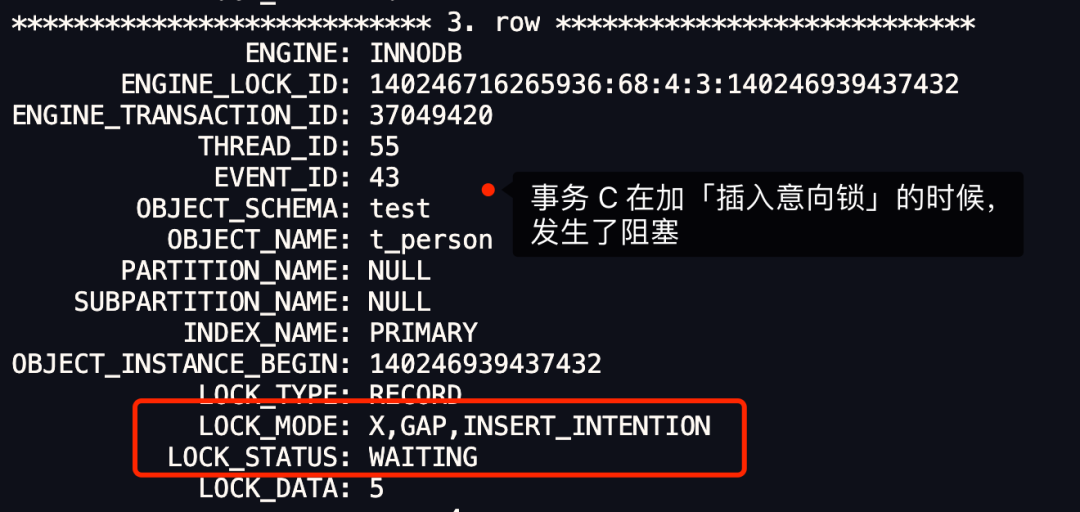 从上面的输出信息,可以看到事务 C 在加「插入意向锁」的时候,发生了阻塞。插入意向锁是插入操作才会有的锁,而事务 C 只是执行 update 语句,却出现了插入意向锁,从这里也可以证明,事务 C 这条特殊的 update 语句运行的时候,被拆分成了两个操作,一个是删除,另一个是插入。总之,如果 update 语句更新的是普通字段的值,就会对发生更新的记录加 X 型记录锁。但是,如果 update 语句更新的是索引的值,那么在运行的时候会被拆分成删除和插入操作,这时候分析锁的时候,要从这两个操作的角度去分析。完啦!怎么样,够不够细节?
从上面的输出信息,可以看到事务 C 在加「插入意向锁」的时候,发生了阻塞。插入意向锁是插入操作才会有的锁,而事务 C 只是执行 update 语句,却出现了插入意向锁,从这里也可以证明,事务 C 这条特殊的 update 语句运行的时候,被拆分成了两个操作,一个是删除,另一个是插入。总之,如果 update 语句更新的是普通字段的值,就会对发生更新的记录加 X 型记录锁。但是,如果 update 语句更新的是索引的值,那么在运行的时候会被拆分成删除和插入操作,这时候分析锁的时候,要从这两个操作的角度去分析。完啦!怎么样,够不够细节? 目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我今天看到了一个ruby代码片段。[1,2,3,4,5,6,7].inject(:+)=>28[1,2,3,4,5,6,7].inject(:*)=>5040这里的注入(inject)和之前看到的完全不一样,比如[1,2,3,4,5,6,7].inject{|sum,x|sum+x}请解释一下它是如何工作的? 最佳答案 没有魔法,符号(方法)只是可能的参数之一。这是来自文档:#enum.inject(initial,sym)=>obj#enum.inject(sym)=>obj#enum.inject(initial){|mem
我真的只是不确定这意味着什么或我应该做什么才能让网页在我的本地主机上运行。现在它只是显示一个错误,上面写着“我们很抱歉,但出了点问题。”当我运行railsserver并在chrome中打开localhost:3000时。这是控制台输出:StartedGET"/users/sign_in"for127.0.0.1at2013-07-0512:07:07-0400ProcessingbyDevise::SessionsController#newasHTMLCompleted500InternalServerErrorin55msNoMethodError(undefinedmethod`
我找到了这样的东西:Rails:Howtolistdatabasetables/objectsusingtheRailsconsole?这一行没问题:ActiveRecord::Base.connection.tables并返回所有表但是ActiveRecord::Base.connection.table_structure("users")产生错误:ActiveRecord::Base.connection.table_structure("projects")我认为table_structure不是Postgres方法。如何列出Postgres数据库的Rails控制台中表中的所有
好的,所以我有了我正在使用的应用程序的这种方法,它可以在生产中使用。我的问题为什么这行得通?这是新的Ruby语法吗?defeditload_elements(current_user)unlesscurrent_user.role?(:admin)respond_todo|format|format.json{render:json=>@user}format.xml{render:xml=>@user}format.htmlendrescueActiveRecord::RecordNotFoundrespond_to_not_found(:json,:xml,:html)end
你能解释一下吗?我想评估来自两个不同来源的值和计算。一个消息来源为我提供了以下信息(以编程方式):'a=2'第二个来源给了我这个表达式来评估:'a+3'这个有效:a=2eval'a+3'这也有效:eval'a=2;a+3'但我真正需要的是这个,但它不起作用:eval'a=2'eval'a+3'我想了解其中的区别,以及如何使最后一个选项起作用。感谢您的帮助。 最佳答案 您可以创建一个Binding,并将相同的绑定(bind)与每个eval相关联调用:1.9.3p194:008>b=binding=>#1.9.3p194:009>eva
Ruby中防止SQL注入(inject)的好方法是什么? 最佳答案 直接使用ruby?使用准备好的语句:require'mysql'db=Mysql.new('localhost','user','password','database')statement=db.prepare"SELECT*FROMtableWHEREfield=?"statement.execute'value'statement.fetchstatement.close 关于ruby-防止SQL注入(inject
我正在编写一个Rails应用程序,它将监视某些特定数据库的数据质量。为了做到这一点,我需要能够对这些数据库执行直接SQL查询——这当然与用于驱动Rails应用程序模型的数据库不同。简而言之,这意味着我无法使用通过ActiveRecord基础连接的技巧。我需要连接的数据库在设计时是未知的(即:我不能将它们的详细信息放在database.yaml中)。相反,我有一个模型“database_details”,用户将使用它来输入应用程序将在运行时执行查询的数据库的详细信息。因此与这些数据库的连接实际上是动态的,细节仅在运行时解析。 最佳答案
(跟进我之前的问题,Ruby:howcanIcopyavariablewithoutpointingtothesameobject?)我正在编写一个简单的Ruby程序来在.svg文件中进行一些替换。第一步是从文件中提取信息并将其放入数组中。为了避免每次调用此函数时都从磁盘读取文件,我尝试使用memoize设计模式-在第一次调用后的每次调用中都使用缓存结果。为此,我使用了一个在函数之前定义的全局变量。但是,即使我在返回局部变量之前将该变量.dup为局部变量,调用该变量的函数仍在修改全局变量。这是我的实际代码:#memoizetokeepfromhavingtoreadoriginalfi