作为全链路数字化技术与服务提供商,袋鼠云提供了从数据湖、大数据基础平台、离线开发、实时开发、数据服务、数据治理、指标管理、客户数据洞察、数据孪生可视化等全产品体系的服务。
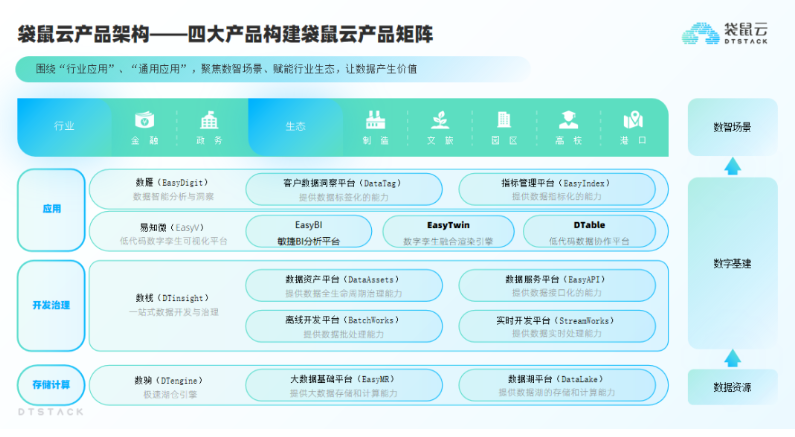
围绕着“行业应用”及“通用应用”,袋鼠云聚焦数智提供全维数字解决方案,帮助企业实现降本增效、快捷转型,迄今为止袋鼠云已服务超过5000家的客户。
面对如此庞大的客户,平台需要不断更新迭代,以适应最新的产品特性,给客户呈现更完备的功能,以达到客户使用平台的极佳体验效果。
为了高效部署和监控袋鼠云平台中的各个产品,袋鼠云自研了新产品大数据基础平台EasyMR,提供快速构建和运维大数据集群的能力,帮助提升大数据平台运维与交互能力。平台层的代码在面向客户升级部署时,需要定义标准化打包规范,以快速和标准化的输出平台层面代码的标准包,借助于大数据基础平台EasyMR,可进行一站式产品包服务的部署、升级、卸载、配置等操作,解放人工运维的成本。
在ToB的客户环境下,我们需要考虑从产品功能迭代到运维出包再到部署的提效优化。面对大型客户的场景,局域网化的部署必然涉及到平台增量包的传输大小限制,特别是在不断增量部署的情况下,客户需要不断审核产品包,而又因为产品包过大而耗费大量时间,大大影响了平台部署产品的效率
基于产品包内存过大影响平台部署效率的问题,袋鼠云技术团队不断探索实践,从平台对编译策略的优化,结合袋鼠云内部产品包的出包优化,来探讨如何在增量策略下,更优的解决产品包的内存大小问题,以解决增量升级的效率性。
袋鼠云平台层代码使用java开发语言,基于maven的module进行各个平台产品的模块划分,平台层关注的是代码层面功能性,产品的编译包通常基于简单的如:

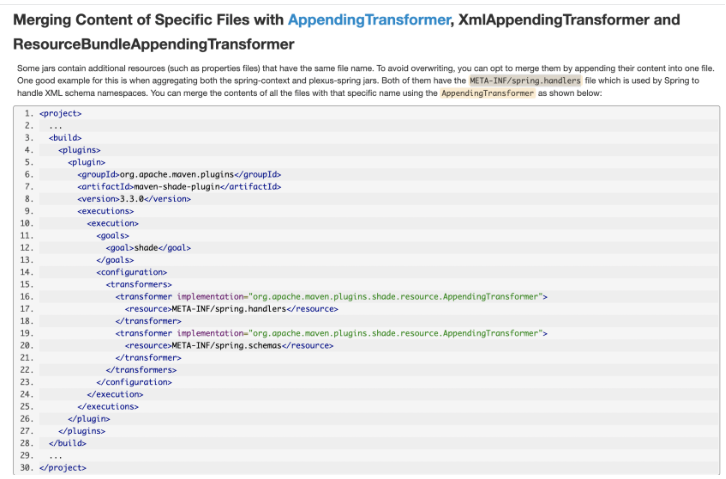
编译方式,通过内部的maven-shard-plugin插件编译 executable shard jar。
maven-shade-plugin内含有大量的资源转换器(Resource Transformers),可以通过追加的策略来避免因不版本相同属性资源的覆盖错误。
官方参考文档:
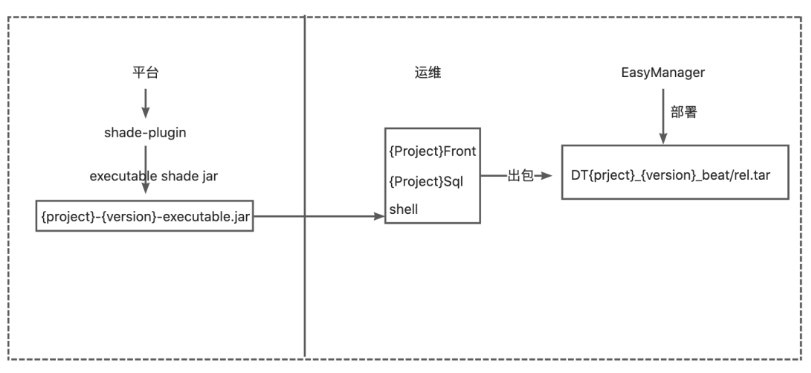
运维基于平台编译的可执行的jar包例如:
{project.name}-{project-version}-jar-with-dependency.jar
需要整合shell启停脚本和配置资源以及sql等输出标准的适配EasyMR部署的标准tar包,大致的整个平台编译的策略如下图:
通过上面的编译到产品包的具体步骤,我们会发现,平台层通过maven-shade-plugin编译为一个executable shard jar的策略下,我们可以思考下面几个问题:
漏洞修复
增量发布包的tar包大小
平台与EasyMR的直接联通
针对这个问题,目前的编译策略无法解决,只能在面对客户漏洞修复的场景下,将整体shade jar做整体产品部署包输出,进行全量升级来解决。
针对这个问题:通过编译可执行jar包的策略,即依赖jar和平台自身jar编译为一个整体的jar包的策略是无法解决最小代价的增量升级一个单一jar的问题,该问题势必会导致在toB客户升级场景下的增量jar升级的传包大小的问题。实际上在增量升级的策略下,对于不变的jar包无需做升级替换,对可变的jar包才需要做增量升级替换。
目前平台基于EasyMR部署的策略下,还需要通过运维层去出标准的产品包,这个内部无形增加了开发到部署的能力,未来平台会基于EasyMR的标准打包规范,直接能够联通EMR做标准产品tar的产品包编译。
本文主要针对目前平台的第一个问题,即通过拆分平台产品层面的的自身jar和第三方依赖jar的策略来解决。
基于拆分各个平台自身的jar和第三方依赖的jar的原则,我们可以约定平台层输出的编译包的制定统一路径,以便运维统一路径下的产品包的输出。

规范化的编译指定目录,将对于的平台服务层面的配置文件、脚本、依赖等相关的核心内容进行目录拆解,这个也是平台层面去统一抽离编译目录的核心部分。
基于规范化的编译目录的制定,我们通过assembly maven:
做指定依赖包的隔离,最终通过java -cp CLASSPATH 类加载器加载路径策略将对应的不同隔离jar加载到类加载器中。例如:
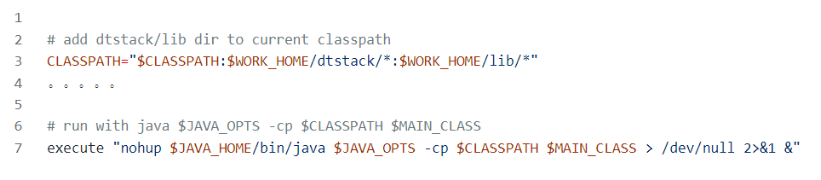
全量包策略下,目录下的lib和dtstack都需要加载到对应的classpath下。
下面分析在增量出包的前提下,一种基于项目为纬度产品出包策略:

即:基于客户A出增量包场景下,对于下次的增量升级策略下,我们可以通过MD5增量比对上次系统出包的lib/dtstack依赖的md5值,增量打包变更/新增的jar包。
基于增量打包的策略能更细粒度的对于升级包的大小和增量升级的维护,需要注意的是,系统运维出包需要维护当前内部jar包的md5值,以作为下次增量产品包输出的依据。
基于规范编译目录到平台编译策略的小优化小改造,再到从增量的角度去探讨增量包的出包策略,我们可以均衡的抽离出平台自研的jar包和平台依赖的jar包。
基于此我们能够为未来更细粒度的升级和部署运维袋鼠云平台产品打下基础,同时也是在toB场景下,对于运维部署效率的小提升。无论从引擎层面,平台层面或者是运维层面,袋鼠云持续的产品迭代以及功能特定的增强都是为了面向客户达到更好的运维,部署,以及平台使用的最好的体验。
袋鼠云开源框架钉钉技术交流qun(30537511),欢迎对大数据开源项目有兴趣的同学加入交流最新技术信息,开源项目库地址:https://github.com/DTStack/Taier
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
我不知道为什么,但是当我设置这个设置时它无法编译设置:static_cache_control,[:public,:max_age=>300]这是我得到的syntaxerror,unexpectedtASSOC,expecting']'(SyntaxError)set:static_cache_control,[:public,:max_age=>300]^我只想将“过期”header设置为css、javaascript和图像文件。谢谢。 最佳答案 我猜您使用的是Ruby1.8.7。Sinatra文档中显示的语法似乎是在Ruby1.
前言作为一名程序员,自己的本质工作就是做程序开发,那么程序开发的时候最直接的体现就是代码,检验一个程序员技术水平的一个核心环节就是开发时候的代码能力。众所周知,程序开发的水平提升是一个循序渐进的过程,每一位程序员都是从“菜鸟”变成“大神”的,所以程序员在程序开发过程中的代码能力也是根据平时开发中的业务实践来积累和提升的。提高代码能力核心要素程序员要想提高自身代码能力,尤其是新晋程序员的代码能力有很大的提升空间的时候,需要针对性的去提高自己的代码能力。提高代码能力其实有几个比较关键的点,只要把握住这些方面,就能很好的、快速的提高自己的一部分代码能力。1、多去阅读开源项目,如有机会可以亲自参与开源
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵