内网穿透作为程序员常用的调试手段之一,我们可以通过在个人电脑上运行花生壳或者 frp 等方式,让他人访问我们本地启动的服务,而且这种访问可以不受局域网的限制,当我们使用ngrok,frp等开源框架时,你是否有好奇过它神奇的作用?明明没有将服务部署到服务器,程序员们究竟是怎么通过这种特殊方式让所有人访问自己的主机的?本文将以frp开源框架为例,介绍内网穿透的原理。
能否在公网中访问服务器的决定性因素:公网 IP
众所周知, IP 地址是每一位使用互联网的网民都会拥有的标识, IP 地址在互联网中起到的作用是定位,通过 IP 地址我们可以精确的定位到所需资源所在的服务器,这是对于一般用户来讲的,而对于程序员而言,我们需要的则是让用户通过 IP 地址定位到我们部署的资源,既然每个互联网用户都拥有 IP 地址,为什么用户无法直接访问部署在个人PC上的服务呢?
事实上, IP 地址分为两种:公网 IP 和内网 IP
内网 IP : 内网 IP 是用户在使用局域网时,由局域网的网关所分配的 IP 地址,每一个内网 IP 实际上都可以映射到当前所在局域网网关的某一端口( IPV4 地址通过 NAT 与端口映射方式实现,具体原理下文详解),拥有内网 IP 可以被同一局域网下的其他设备所访问到;
公网 IP : 内网的设备想要访问非同一局域网下的资源则必须通过公网 IP ,公网 IP 是没有经过 NAT 转换的由互联网供应商(ISP)提供的最原始的 IP 地址,每一个公网 IP 都可以直接在互联网中被直接定位到。
一个最简单的例子(以前端开发为例) :
当我们使用 webpack-dev-server 来启动一个 node 项目时,我们除了通过localhost:[端口号]的方式以外,与我们的开发设备处于同一局域网下的设备可以通过内网 IP :[端口号]的方式对我们的项目进行访问,但当我们使用自己的流量或者连接其他非当前开发设备所在局域网的设备使用内网 IP :[端口号]的方式进行进行访问时,则无法访问。
原因:
内网 IP 地址仅在当前局域网下可以被定位并访问到,而当我们想要跨局域网访问时,我们的访问请求则需要先映射为公网 IP 然后访问到另一局域网的公网 IP ,最后由另一局域网的网关将其映射到相应的局域网设备,但我们访问的地址属于局域网中的内网 IP ,因此无法定位到其相应的公网 IP
综上所述,当我们想要让处于其他局域网下的设备访问到我们本地资源,必不可缺的就是公网 IP 。
相较于内网 IP ,公网 IP 明显比内网 IP 更加有用,为什么不可以人手一个公网 IP 呢?
尽管 IPV6 的概念在几年前已经被提出,但实际的普及程度并没有很高,现在大部分网络用户使用的依旧是 IPV4 的 IP 地址,这也是限制公网 IP 个数的最大原因。
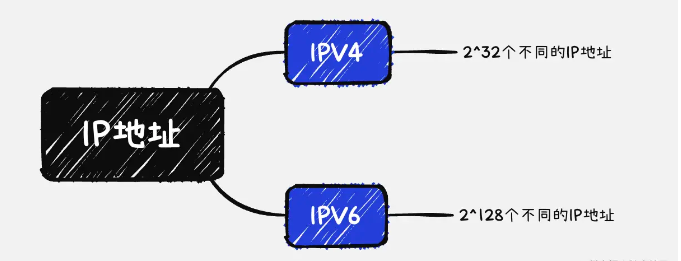
** IPV4:** IPV4 由 32 位二进制数组成,一共有 2^32 个不同的 IPV4 地址
** IPV6**: IPV6 由 128 位二进制数组成,理论上共有 2^128 个不同的 IPV6 地址
由此可见, IPV4地址的个数并不足以满足当前全世界网络用户的人手一个 IP 地址的需求,那么当前的网络为什么可以让这么多用户同时在网络上冲浪呢?
网络地址转化技术的核心作用在于实现对公网 IP 地址的复用,即所有的内网主机共用同一个 IP 地址,NAT 的实现方式共有三种:



可以看出以上三种形式中端口多路复用(PAT)技术可以最大程度上缓解 IPV4 地址紧张的现状,也是最为广泛使用的实现方式,三种 NAT 实现方式共同点在于:对于内网用户来说自己对应的公网 IP 是不可知的,就好像我们可以知道自己的门牌号但无法知道自己所在的小区,因此无法准确告诉别人我们的具体地址。
在已知了当前内外网工作方式后,我们再来看一看作为程序员常用的技术手段内网穿透
在此之前或许很多人都曾使用过如花生壳、ngrok、frp等方式在没有服务器的情况下将一些服务部署到网络上让别人使用
那么内网穿透的原理究竟是怎么样的呢?
目前市面上主流的内网穿透工具实现的原理如下:
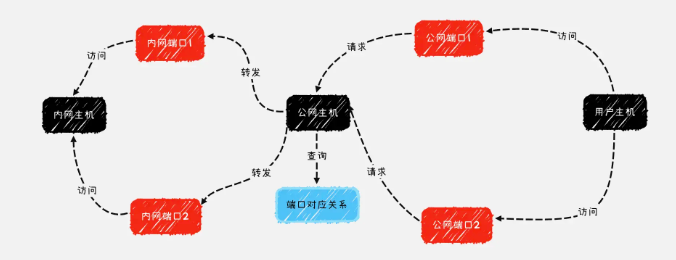
可见,内网穿透的核心原理在于将外网 IP 地址与内网 IP 地址建立联系,市面上常用的如花生壳工具其核心原理就是依靠一台具有公网 IP 的服务器作为请求的中转站以此来达到从公网访问内网主机的目的。
当我们启动花生壳的服务时,花生壳会将本地配置好的端口和服务器上的端口进行映射,告知服务器请求转发的路径,花生壳的公网服务器则会监听相应端口的请求,当用户访问花生壳提供的 IP 地址时,花生壳的对应 IP 地址的公网主机将会根据访问的端口映射到相应的内网主机,并通过预先配置好的服务端口将请求转发,以达到访问内网主机相应服务的效果。
更多C++后台开发技术点知识内容包括C/C++,Linux,Nginx,ZeroMQ,MySQL,Redis,MongoDB,ZK,流媒体,音视频开发,Linux内核,TCP/IP,协程,DPDK多个高级知识点。
C/C++Linux服务器开发高级架构师/C++后台开发架构师免费学习地址
【文章福利】另外还整理一些C++后台开发架构师 相关学习资料,面试题,教学视频,以及学习路线图,免费分享有需要的可以点击领取

花生壳作为一款商业产品,对于配置端口等一系列工作进行了封装,使得用户可以更快捷的使用内网穿透,但我们在了解原理后完全可以通过一些开源的框架以及一台公网服务器实现对应的内网穿透功能,我们以 frp 为例。
服务端设置(frps.ini):
[common]
bind_port = 7000 //此处填写客户端监听的服务端端口号
vhost_http_port = 8080 //此处填写用户访问的端口号
客户端配置(frpc.ini):
[common]
server_addr = x.x.x.x //此处填写服务端 IP 地址
server_port = 7000 //此处填写服务端配置的bind_port
[web]
type = http //此处规定转发请求的协议类型
local_port = 80 //此处规定本地服务启动的地址
custom_domains = www.example.com //此处可以填写自定义域名(需要在 IP 地址下配置域名解析)当我们配置完上述的文件后,用户的访问请求将会经过如下的步骤:
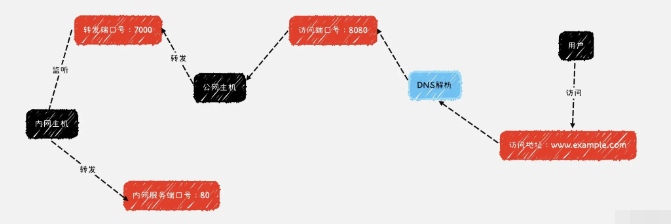
用户的请求将会经过域名解析,公网端口的转发以及内网主机的监听三个步骤成功将请求发送到对应的内网服务,当然 frp 相较于花生壳提供了更多的自定义配置项,此处不做详细讲解,有兴趣的读者可以访问:frp中文文档
当我们使用 frp 去配置我们自己的内网穿透服务时,我们可以使用一台服务器为大量的内网主机提供公网访问的功能,以此来实现公网 IP 的复用,其原理与上文提到的 PAT 端口多路复用技术相类似,当我们临时需要使用服务器时,只需要向拥有公网服务器的朋友申请两个闲置端口即可。
本文以 http 请求为例解析当一个公网请求发送到frp服务器后究竟会经过哪些步骤
func runServer(cfg config.ServerCommonConf) (err error) {
log.InitLog(cfg.LogWay, cfg.LogFile, cfg.LogLevel, cfg.LogMaxDays, cfg.DisableLogColor)
if cfgFile != "" {
log.Info("frps uses config file: %s", cfgFile)
} else {
log.Info("frps uses command line arguments for config")
}
// !important 核心代码1
svr, err := server.NewService(cfg)
if err != nil {
return err
}
log.Info("frps started successfully")
// !important 核心代码2
svr.Run()
return
}在frp/cmd/frps/root.go中
for{
// !important 核心代码3
conn, session, err := svr.login()
if err != nil {
xl.Warn("login to server failed: %v", err)
// if login_fail_exit is true, just exit this program
// otherwise sleep a while and try again to connect to server
if svr.cfg.LoginFailExit {
return err
}
util.RandomSleep(10*time.Second, 0.9, 1.1)
} else {
// login success
// !important 核心代码4
ctl := NewControl(svr.ctx, svr.runID, conn, session, svr.cfg, svr.pxyCfgs, svr.visitorCfgs, svr.serverUDPPort, svr.authSetter)
ctl.Run()
svr.ctlMu.Lock()
svr.ctl = ctl
svr.ctlMu.Unlock()
break
}
}在frp/cmd/client/service.go中
frps 发起连接
func (pxy *BaseProxy) GetWorkConnFromPool(src, dst net.Addr) (workConn net.Conn, err error) {
xl := xlog.FromContextSafe(pxy.ctx)
// try all connections from the pool
for i := 0; i < pxy.poolCount+1; i++ {
// !important 核心代码5
if workConn, err = pxy.getWorkConnFn(); err != nil {
xl.Warn("failed to get work connection: %v", err)
return
}
xl.Debug("get a new work connection: [%s]", workConn.RemoteAddr().String())
xl.Spawn().AppendPrefix(pxy.GetName())
workConn = frpNet.NewContextConn(pxy.ctx, workConn)
......
// !important 核心代码6
err := msg.WriteMsg(workConn, &msg.StartWorkConn{
ProxyName: pxy.GetName(),
SrcAddr: srcAddr,
SrcPort: uint16(srcPort),
DstAddr: dstAddr,
DstPort: uint16(dstPort),
Error: "",
})
}
}在frp/server/proxy.go中
frpc 响应连接
func (pxy *TCPProxy) InWorkConn(conn net.Conn, m *msg.StartWorkConn) {
// !important 核心代码7
HandleTCPWorkConnection(pxy.ctx, &pxy.cfg.LocalSvrConf, pxy.proxyPlugin, pxy.cfg.GetBaseInfo(), pxy.limiter,
conn, []byte(pxy.clientCfg.Token), m)
}在frp/client/proxy/proxy.go中
frps发送消息
func (ctl *Control) writer() {
xl := ctl.xl
defer func() {
if err := recover(); err != nil {
xl.Error("panic error: %v", err)
xl.Error(string(debug.Stack()))
}
}()
defer ctl.allShutdown.Start()
defer ctl.writerShutdown.Done()
encWriter, err := crypto.NewWriter(ctl.conn, []byte(ctl.serverCfg.Token))
if err != nil {
xl.Error("crypto new writer error: %v", err)
ctl.allShutdown.Start()
return
}
for {
m, ok := <-ctl.sendCh
if !ok {
xl.Info("control writer is closing")
return
}
// !important 核心代码8
if err := msg.WriteMsg(encWriter, m); err != nil {
xl.Warn("write message to control connection error: %v", err)
return
}
}
}在frp/server/control.go中
frpc 接收和响应
// !important 核心代码9
func (ctl *Control) reader() {
xl := ctl.xl
defer func() {
if err := recover(); err != nil {
xl.Error("panic error: %v", err)
xl.Error(string(debug.Stack()))
}
}()
defer ctl.readerShutdown.Done()
defer close(ctl.closedCh)
encReader := crypto.NewReader(ctl.conn, []byte(ctl.clientCfg.Token))
for {
m, err := msg.ReadMsg(encReader)
if err != nil {
if err == io.EOF {
xl.Debug("read from control connection EOF")
return
}
xl.Warn("read error: %v", err)
ctl.conn.Close()
return
}
ctl.readCh <- m
}
}到这里,我们的 frps 已经成功将公网中接收到的请求转发到 frpc 相应的端口了,这就是一个最简单的请求通过 frp 进行代理转发的流程。
本文所介绍的内网穿透技术相关的实现方式其实在我们的日常开发生活中有更多的使用场景,当我们深入了解了当前 IP 地址以及内外网的实现方式后,我们不难发现,当我们将内网穿透的图片稍加修改后就成为了我们常用的另一种功能的实现方式(VPN实现原理):
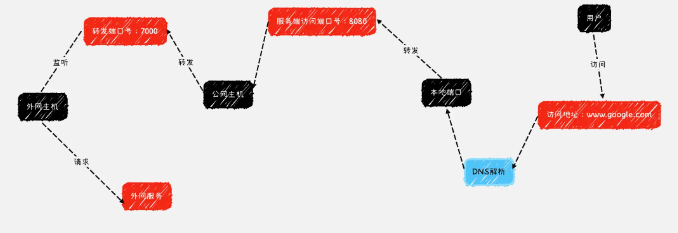
原文作者:内网穿透你真的了解吗? - 掘金
我的问题很简单:我是否必须在使用RubyonRails的类上require'csv'?如果我打开一个railsconsole并尝试使用CSVgem它可以工作,但我必须在文件中这样做吗? 最佳答案 CSVlibrary是ruby标准库的一部分;它不是gem(即第三方库)。与所有标准库(与核心库不同)一样,csv不会由ruby解释器自动加载。所以是的,在您的应用程序中某处您确实需要要求它:irb(main):001:0>CSVNameError:uninitializedconstantCSVfrom(irb):1from/Us
我经常将预配置的lambda插入可枚举的方法中,例如“map”、“select”等。但是“注入(inject)”的行为似乎有所不同。例如与mult4=lambda{|item|item*4}然后(5..10).map&mult4给我[20,24,28,32,36,40]但是,如果我制作一个2参数lambda用于像这样的注入(inject),multL=lambda{|product,n|product*n}我想说(5..10).inject(2)&multL因为“inject”有一个可选的单个初始值参数,但这给了我......irb(main):027:0>(5..10).inject
是否有self验证的问题列表。看着那个,我可以确定我知道。我应该复习一下。在学习的过程中,我列了一个这样的list,但它只包含我在某处听说过的项目。我需要一段时间才能找到新的东西。 最佳答案 以下是针对ruby和Rails的一些测试列表。证书名称:RubyonRails谁提供:oDeskIncorporation认证费用:免费网站:https://www.odesk.com/tests/985?pos=0证书名称:RubyonRails提供者:Techgig.com(TimesBusinessSolutionsLimited(T
我想覆盖store_accessor的getter。可以查到here.代码在这里:#Fileactiverecord/lib/active_record/store.rb,line74defstore_accessor(store_attribute,*keys)keys=keys.flatten_store_accessors_module.module_evaldokeys.eachdo|key|define_method("#{key}=")do|value|write_store_attribute(store_attribute,key,value)enddefine_met
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我最近开始学习Ruby,这是我的第一门编程语言。我对语法感到满意,并且我已经完成了许多只教授相同基础知识的教程。我已经写了一些小程序(包括我自己的数组排序方法,在有人告诉我谷歌“冒泡排序”之前我认为它非常聪明),但我觉得我需要尝试更大更难的东西来理解更多关于Ruby.关于如何执行此操作的任何想法?
Ruby是完全面向对象的语言。在ruby中,一切都是对象,因此属于某个类。例如5属于Objectclass1.9.3p194:001>5.class=>Fixnum1.9.3p194:002>5.class.superclass=>Integer1.9.3p194:003>5.class.superclass.superclass=>Numeric1.9.3p194:005>5.class.superclass.superclass.superclass=>Object1.9.3p194:006>5.class.superclass.superclass.superclass.su
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭10年前。我一直在Rails上做两个项目,它们运行良好,但在这个过程中重新发明了轮子,自来水(和热水)和止痛药,正如我随后了解到的那样,这些已经存在于框架中。那么基本上,正确了解框架中所有智能部分的最佳方法是什么,这将节省时间而不是自己构建已经实现的功能?从第1页开始阅读文档?是否有公开所有内容的特定示例应用程序?一个特定的开源项目?所有的rails交通?还是完全
假设我有一个函数defodd_or_evennifn%2==0return:evenelsereturn:oddendend我有一个简单的可枚举数组simple=[1,2,3,4,5]然后我用我的函数在map中运行它,使用一个do-endblock:simple.mapdo|n|odd_or_even(n)end#=>[:odd,:even,:odd,:even,:odd]如果不首先定义函数,我怎么能做到这一点?例如,#doesnotworksimple.mapdo|n|ifn%2==0return:evenelsereturn:oddendend#Desiredresult:#=>[
在以下示例中,我无法理解Ruby运算符的优先级:x=1&&y=2由于&&的优先级高于=,我的理解是类似于+和*运算符:1+2*3+4解析为1+(2*3)+4它应该等于:x=(1&&y)=2但是,所有Ruby源代码(包括内部语法解析器Ripper)都将其解析为x=(1&&(y=2))为什么?编辑[08.01.2016]让我们关注一个子表达式:1&&y=2根据优先规则,我们应该尝试将其解析为:(1&&y)=2这没有意义,因为=需要特定的LHS(变量、常量、[]数组项等)。但是既然(1&&y)是一个正确的表达式,那么解析器应该如何处理呢?我试过咨询Ruby的parse.y,但它太像意大利面条
有人知道为什么我的rails3.0.7cli这么慢吗?当我运行railss或railsg时,他大约需要5秒才能真正执行命令...有什么建议吗?谢谢 最佳答案 更新:我正在将我的建议从rrails切换到rails-sh,因为前者支持REPL,而rrails不是用例。此外,当与ruby环境结合使用时,修补似乎确实可以提高性能变量,现在反射(reflect)在答案中。一个可能的原因可能是这个performancebuginruby每当在ruby代码中使用“require”时,它就会调用一些代码(更多详细信息here)。在使用Rai