在原有单一节点(node-1)中进行构建双节点集群
node-1的elasticsearch.yml的配置信息如下
cluster.name: elasticsearch
node.name: node-1
node.master: true
node.data: true
network.host: 192.168.3.147
http.port: 9200
transport.tcp.port: 9300 ###在构建集群通信时必须有这个配置,否则无法建立通信
discovery.seed_hosts: ["192.168.3.147:9300","192.168.3.211:9300"]
cluster.initial_master_nodes: ["node-1"]
http.cors.enabled: true
http.cors.allow-origin: "*"
indices.breaker.fielddata.limit: 60%
indices.fielddata.cache.size: 40%
path.repo: ["/usr/local/elasticsearch/backups/es_backup"]
#indices.requests.cache.size: 5%
#indices.memory.index_buffer_size: 70%
#index.refresh_interval: 30s ###此项设置,建议使用API动态设置
xpack.security.enabled: false
search.max_open_scroll_context: 1000000
cluster.routing.allocation.disk.threshold_enabled: false
#cluster.routing.allocation.disk.watermark.low: 90%
#cluster.routing.allocation.disk.watermark.high: 95%
#cluster.routing.allocation.disk.watermark.flood_stage: 98%
cluster.name: 集群名称node.master: 主节点 (默认true) 主要用来创建或者删除索引,以及决定哪些分片分配给相关的节点.node.data: 数据节点,主要用来存储索引数据的节点,即对文档增删改查、聚合等操作。node.ingest: 预处理节点(一般情况是不会去配置这个节点的)在索引数据之前可以先对数据做预处理操作,所有节点其实默认都是支持 Ingest 操作的,也可以专门将某个节点配置为 Ingest 节点。http.port: http请求端口transport.tcp.port:集群中节点通信的端口discovery.seed_hosts: 提供集群中其他的节点列表进行发现cluster.initial_master_nodes: 第一次启动elasticsearch集群时,集群引导步骤会确定符合主节点资格的节点集。indices.breaker.fielddata.limit: 断路器配置,用来防止操作时造成OutOfMemoryError,指定可以使用多少内存限制。详见此path.repo: 快照存放目录,还需要用API进行创建仓库responsitry,具体可见另一篇文档,有对快照备份的详细操作,个人亲测有效cluster.routing.allocation.disk.threshold_enabled: 磁盘分配设置,用来修改磁盘使用率。增加节点node-2,配置如下
cluster.name: elasticsearch
node.name: node-2
node.master: false
node.data: true
network.host: 192.168.3.211
http.port: 9200
transport.tcp.port: 9300
discovery.seed_hosts: ["192.168.3.147:9300","192.168.3.211:9300"]
cluster.initial_master_nodes: ["node-1"]
http.cors.enabled: true
http.cors.allow-origin: "*"
xpack.security.enabled: false
search.max_open_scroll_context: 1000000
cluster.routing.allocation.disk.threshold_enabled: false
本机测试及其他服务器上测试中如上配置是可以稳定的进行节点扩容。
出现这个问题的原因主要是: cluster.name不同导致的cluster.uuid不同。产生的原因是node-1有与其他节点构成一个集群的部署,cluster.name: elasticsearch. 之后node-1又与其他节点构成一个集群,cluster.name: elasticsearch_prod. node-1因为前后cluster.name不一致造成的。还可能产生的原因是cluster.name后面有空格.
解决该问题的最好的方式就是:采用其默认的cluster.name: elasticsearch
出现上述问题可参考如下方式去排查
transport.tcp.port: 9300这个配置是否有network.host: 127.0.0.1 改为 192.168.3.211discovery.seed_hosts 集群节点列表是否配置该问题属于常见问题,elastsearch允许的虚拟内存不足
sudo vim /etc/sysctl.conf
vm.max_map_count = 262144
sudo sysctl -w vm.max_map_count=262144
集群通信建立,但是分片未进行分配
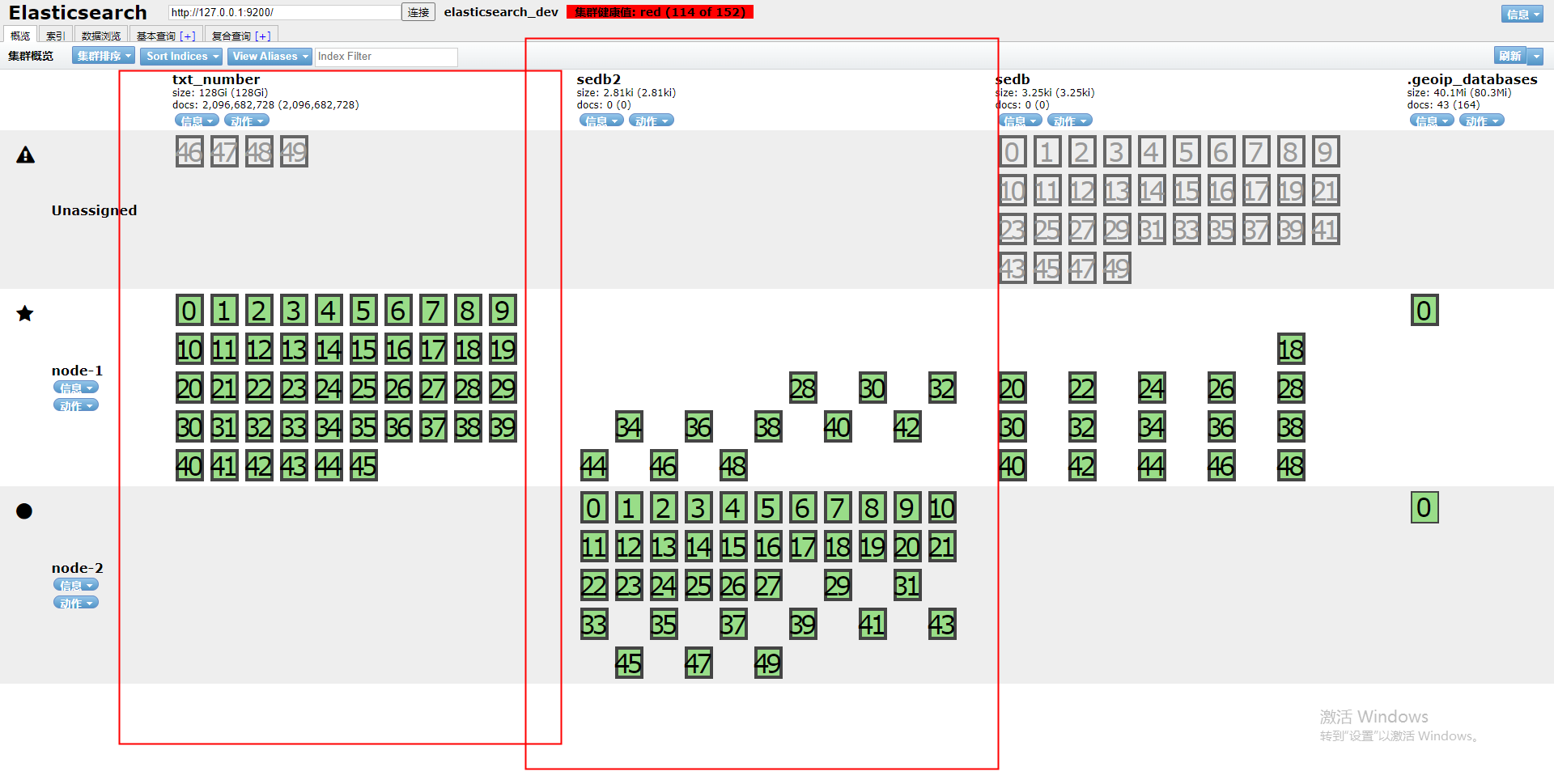
双节点集群搭建完成,由于之前的分片未恢复而导致分片无法进行再平衡设置时,可以参考官网的集群级分片和路由设置
cluster.routing.allocation.enable
(动态)为特定类型的分片启用或禁用分配:
all - (默认)允许为所有类型的分片分配分片。primaries - 只允许对主分片进行分片分配。new_primaries - 仅允许为新索引的主分片分配分片。none - 不允许对任何索引进行任何类型的分片分配。cluster.routing.allocation.allow_rebalance
(动态)指定何时允许分片重新平衡:
always - 始终允许重新平衡。indices_primaries_active - 仅当分配了集群中的所有主节点时。indices_all_active - (默认)仅当集群中的所有分片(主分片和副本)都已分配时。****该设置不影响重启节点时本地主分片的恢复。具有未分配主分片副本的重新启动节点将立即恢复该主分片,假设其分配 id 与集群状态中的活动分配 id 之一匹配。
put /_cluster/settings
{
"transient": {
"cluster.routing.allocation.enable": "all", //为所有类型的分片分配分配
"cluster.routing.allocation.allow_rebalance": "always", //始终允许重新平衡
// "cluster.routing.rebalance.enable": "all" //为所有类型的分配进行分片进行再平衡设置
}
}
transient: 暂时性的配置,ES服务重启后就失效了
persistent: 永久性的。
通过如上API设置,可以实现分片的再平衡设置。
分片未恢复
CLUSTER_RECOVERED: 完全集群导致分片未分配
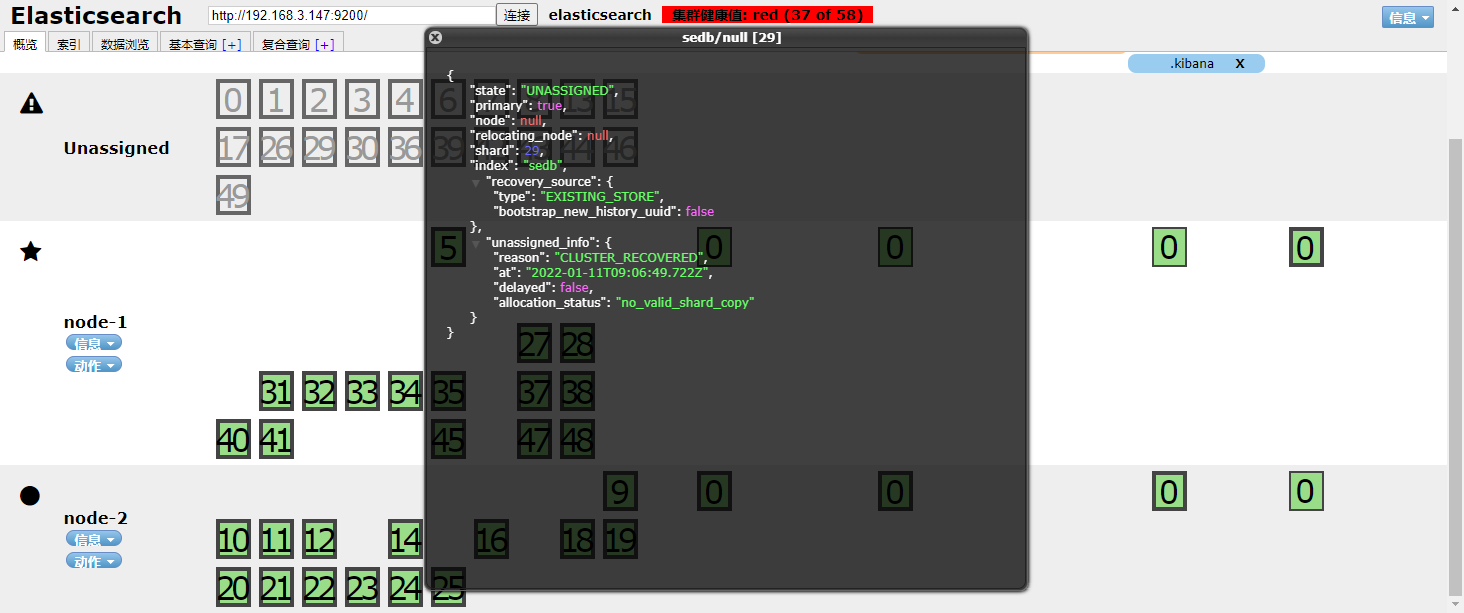
通过**GET _cluster/allocation/explain** 对分片未分配原因进行分析
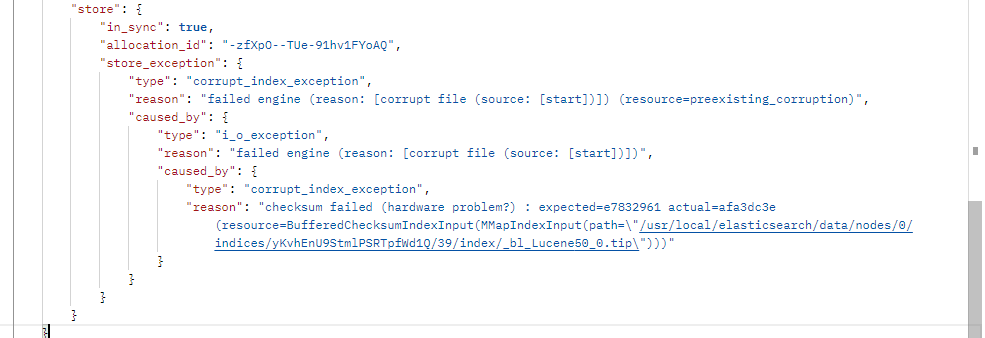
报错原因是checksum failed (hardware problem?) : expected=cdd45b03 actual=4ff129f6 (resource=BufferedChecksumIndexInput(MMapIndexInput(path=\"/usr/local/elasticsearch/data/nodes/0/indices/yKvhEnU9StmlPSRTpfWd1Q/46/index/_3g_Lucene50_0.tip\")))"硬件问题 磁盘损坏,文档丢失,磁盘空间不足等等情况都可以能导致该错误的发生。
可以通过Luence-core-8.20.1.jar包对分片的segements运行CheckIndex程序。如下命令会对分段进行验证校验和,还会确保索引实际上可以被读取并且使其数据结构彼此一致(对于这个使其数据结构彼此一致的说法个人是保持怀疑态度的,因为我进行如下命令也没发现有进行修复)。这个程序运行时间可能会有点久,这个主要根据分片大小决定。31G分片执行校验在400~500s这个范围。
java -cp /usr/share/elasticsearch/lib/lucene-core-4.10.4.jar -ea:org.apache.lucene... org.apache.lucene.index.CheckIndex $datadir/nodes/0/indices/$index/$shard/index/
这程序执行完之后。会显示该分片是否损坏。结果如下。虽然提示的结果显示segments文档损坏,通过附加-exorcise参数可以对segemetns进行文档的修改,但是会丢失对应的文档。个人建议谨慎操作。再进行该项操作时可以看该目录下是否有corrupted_*这个文件,这个文件是对该分片的标识文件,可以将该文件进行移除,然后重启ES服务。个人亲测有效。
如果要进行-exoricise参数对分段进行文档修复(这是在允许文档数据丢失情况下)之前最好做好备份。
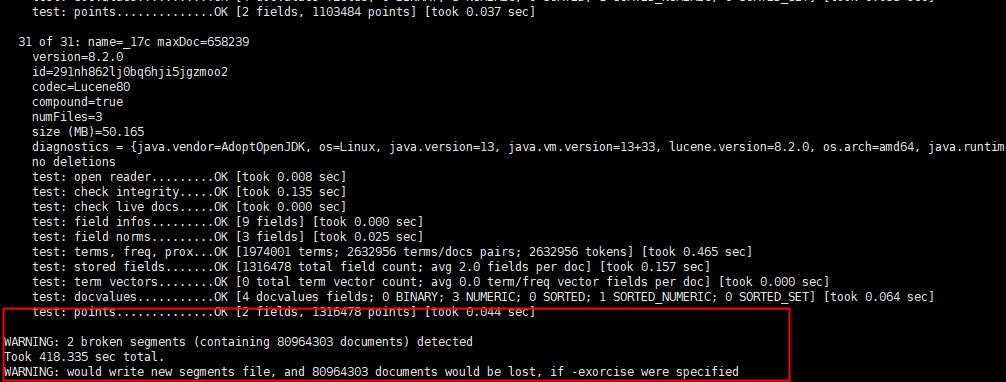
在对corrupted_*损坏文件进行移除后,集群恢复如下
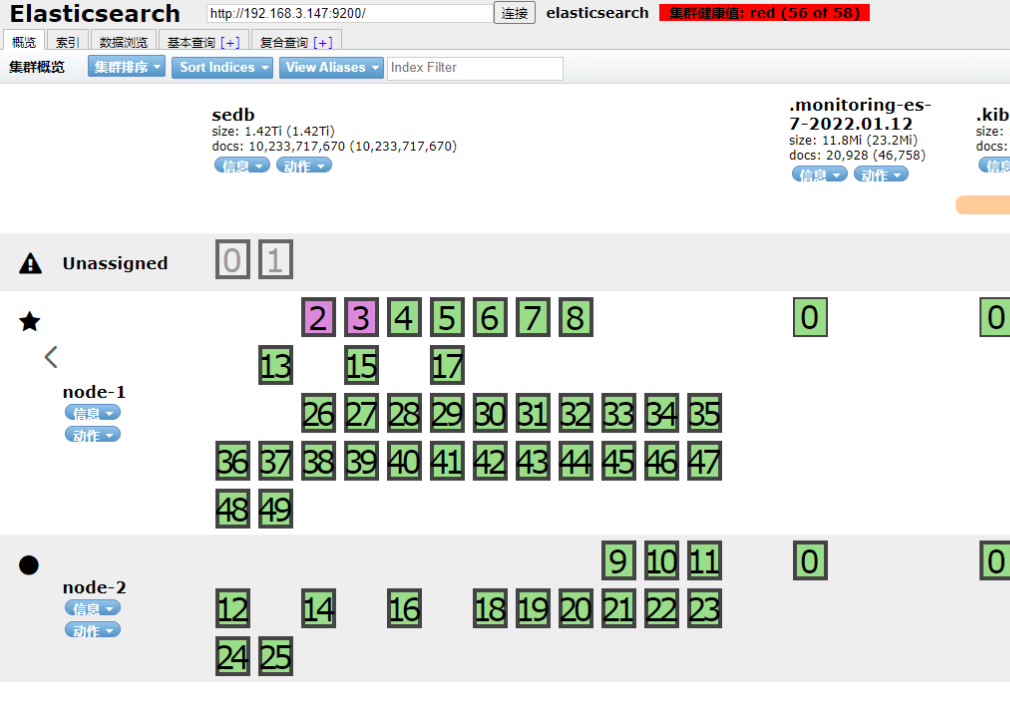
发现还有2个节点未恢复,根据**GET _cluster/allocation/explain**在进行分片未分配原因分析
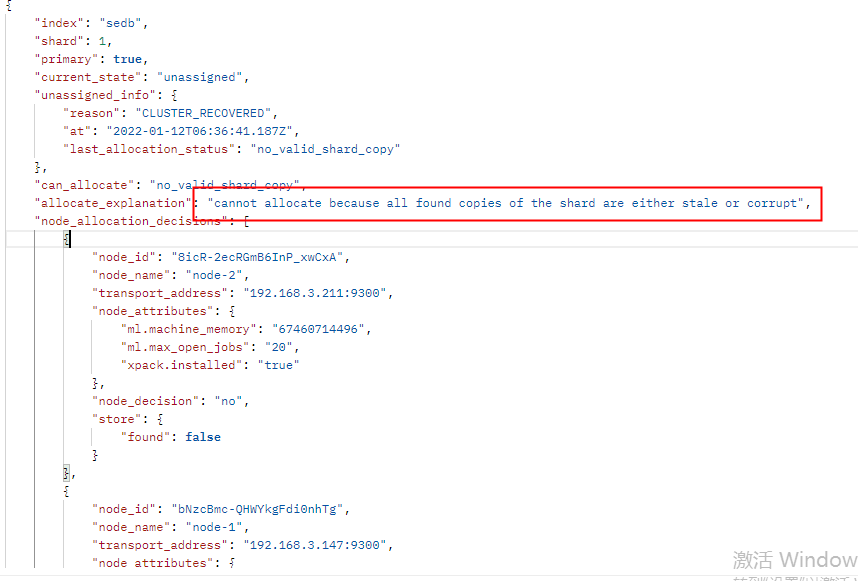
通过上述分析,没有报错原因。则可以尝试进行分片的重新路由
cannot allocate because all found copies of the shard are either stale or corrupt这个问题是毫无参考价值的,基本上分片只要未分配都是给你这个提示。
重新路由命令可以手动的将未分配的分片进行分配到节点上。主要有3个参数
allocate_stale_primary对主分片进行操作。accept_data_loss:允许数据丢失,所以谨慎操作,最好能对索引进行备份。Elasticserch7.0以后官方都推荐使用快照的形式对索引进行数据备份操作。POST /_cluster/reroute
{
"commands": [
{
"allocate_stale_primary": {
"index": "sedb",
"shard": 0,
"node": "node-1",
"accept_data_loss": true
}
}
]
}
在进行分片重新路由时,必须确保分片目录下没有corrupted_*这个损坏文件的标识,否则是不会进行分片强制分配的。
个人认为:对于分片数据恢复或者说未分配的解决思路是:可以先对分片未分配原因进行分析,ES的这个API GET _cluster/allocation/explain 是非常不错的工具。步骤如下:
1、检查分片文件的损坏文档情况 采用Lucence 库 Luence-core-8.20.1.jar 对segments进行校验。
2、分片中的存在的损坏文件进行移除,重启ES服务
3、对未分配的分片进行重新路由的方式,手动分配。
4、重新索引(这种方式没有测试过对未分配的分片是否有效)
cd elasticsearch/data/node/0/indices/xxxx/$shard/index某个目录下,存放分片的多个segments。如下所示
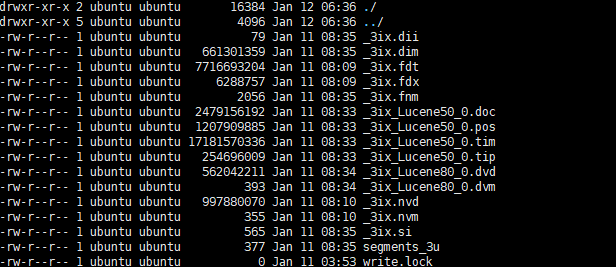
| Name | Extension | Description |
|---|---|---|
| Term Index | .tip | 词典索引(需加载进内存) |
| Term Dictionary | .tim | 倒排表指针 |
| Frequencies | .doc | 包含Term和频率的文档列表(倒排表) |
| Fields | .fnm | Field数据元信息 |
| Field Index | .fdx | 文档位置索引(需加载进内存) |
| Field Data | .fdt | 文档值 |
| Per-Document Values | .dvd .dvm | .dvm为DocValues元信息 .dvd为DocValue值 (默认情况下elasticsearch开启该功能用于快速排序、聚合等操作) |
cluster.name: elasticsearch
node.name: node-3 ###依次修改
node.master: true ###当节点数>=3时 改为true 实现高可用。
node.data: true
network.host: 192.168.3.xxx
bootstrap.memory_lock: true ###禁用SWAP,防止内存与磁盘进行交互,造成ES性能问题
http.port: 9200
transport.tcp.port: 9300
discovery.seed_hosts: ["192.168.3.147:9300","192.168.3.211:9300","192.168.3.xxx"] ###所有节点加入该列表
cluster.initial_master_nodes: ["node-1","node-2","node-3"] ##node.master:true 的节点都加入
discovery.zen.minimum_master_nodes:2 ###节点数>=3时,增加该配置防止脑裂问题
http.cors.enabled: true
http.cors.allow-origin: "*"
xpack.security.enabled: false
search.max_open_scroll_context: 1000000
om/developer/news/362991 “Elasticsearch搜索引擎性能调优”
3: https://www.cnblogs.com/technologykai/articles/11940806.html?ivk_sa=1024320u “Elasticsearch亿级数据检索案例与原理”
4: https://mincong.io/cn/elasticsearch-corrupted-index/ “修复elasticsearch中损坏的索引”
5: https://segmentfault.com/a/1190000004504225 “如何防止脑裂问题”
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我有两个Rails模型,即Invoice和Invoice_details。一个Invoice_details属于Invoice,一个Invoice有多个Invoice_details。我无法使用accepts_nested_attributes_forinInvoice通过Invoice模型保存Invoice_details。我收到以下错误:(0.2ms)BEGIN(0.2ms)ROLLBACKCompleted422UnprocessableEntityin25ms(ActiveRecord:4.0ms)ActiveRecord::RecordInvalid(Validationfa
我正在尝试将以下SQL查询转换为ActiveRecord,它正在融化我的大脑。deletefromtablewhereid有什么想法吗?我想做的是限制表中的行数。所以,我想删除少于最近10个条目的所有内容。编辑:通过结合以下几个答案找到了解决方案。Temperature.where('id这给我留下了最新的10个条目。 最佳答案 从您的SQL来看,您似乎想要从表中删除前10条记录。我相信到目前为止的大多数答案都会如此。这里有两个额外的选择:基于MurifoX的版本:Table.where(:id=>Table.order(:id).
我目前正在用Ruby编写一个项目,它使用ActiveRecordgem进行数据库交互,我正在尝试使用ActiveRecord::Base.logger记录所有数据库事件具有以下代码的属性ActiveRecord::Base.logger=Logger.new(File.open('logs/database.log','a'))这适用于迁移等(出于某种原因似乎需要启用日志记录,因为它在禁用时会出现NilClass错误)但是当我尝试运行包含调用ActiveRecord对象的线程守护程序的项目时脚本失败并出现以下错误/System/Library/Frameworks/Ruby.frame
我有一个应用需要发送用户事件邀请。当用户邀请friend(用户)参加事件时,如果尚不存在将用户连接到该事件的新记录,则会创建该记录。我的模型由用户、事件和events_user组成。classEventdefinvite(user_id,*args)user_id.eachdo|u|e=EventsUser.find_or_create_by_event_id_and_user_id(self.id,u)e.save!endendend用法Event.first.invite([1,2,3])我不认为以上是完成我的任务的最有效方法。我设想了一种方法,例如Model.find_or_cr
在许多ruby类之间共享记录器实例的最佳(正确)方法是什么?现在我只是将记录器创建为全局$logger=Logger.new变量,但我觉得有更好的方法可以在不使用全局变量的情况下执行此操作。如果我有以下内容:moduleFooclassAclassBclassC...classZend在所有类之间共享记录器实例的最佳方式是什么?我是以某种方式在Foo模块中声明/创建记录器还是只是使用全局$logger没问题? 最佳答案 在模块中添加常量:moduleFooLogger=Logger.newclassAclassBclassC..
如何在出现异常时指定全局救援,如果您将Sinatra用于API或应用程序,您将如何处理日志记录? 最佳答案 404可以在not_found方法的帮助下处理,例如:not_founddo'Sitedoesnotexist.'end500s可以通过调用带有block的错误方法来处理,例如:errordo"Applicationerror.Plstrylater."end错误的详细信息可以通过request.env中的sinatra.error访问,如下所示:errordo'Anerroroccured:'+request.env['si
例如,假设我有一个名为Products的模型,并且在ProductsController中,我有以下代码用于product_listView以显示已排序的产品。@products=Product.order(params[:order_by])让我们想象一下,在product_listView中,用户可以使用下拉菜单按价格、评级、重量等进行排序。数据库中的产品不会经常更改。我很难理解的是,每次用户选择新的order_by过滤器时,rails是否必须查询,或者rails是否能够以某种方式缓存事件记录以在服务器端重新排序?有没有一种方法可以编写它,以便在用户排序时rails不会重新查询结果
在我的Rails项目中,我有三个模型:classRecipe:recipe_categorizationsaccepts_nested_attributes_for:recipe_categories,allow_destroy::trueendclassCategory:recipe_categorizationsendclassRecipeCategorization通过这个简单的has_many:through设置,我怎样才能像这样获取给定的食谱:@recipe=Recipe.first并根据现有类别向此食谱添加类别,并在相应类别上对其进行更新。所以:@category=#Exi
我有一个帖子属于城市的关系,城市又属于一个州,例如:classPost现在我想找到所有帖子及其所属的城市和州。我编写了以下查询来获取带有城市的帖子,但不知道如何在同一查找器中获取带有城市的相应州:@post=Post.find:all,:include=>[:city]感谢任何帮助。谢谢。 最佳答案 Post.all(:include=>{:city=>:state}) 关于ruby-on-rails-使用Rails事件记录获取二级模型,我们在StackOverflow上找到一个类似的问