目录
本文介绍的函数的函数声明都在头文件string.h中。
(1)memcpy( )函数
函数声明:void* memcpy(void* dest,const void* src,size_t num)
作用:把一片内存空间的字节拷贝到另一片内存空间。
函数参数的意义:
①dest指向用于存储复制内容的目标数组,类型强制转换为 void* 指针。
②src指向要复制的数据源,类型强制转换为 void* 指针。同时我们只是拷贝这一片空间的数据到目标空间而不是修改,所以用const进行修饰。
③num(无符号整型)表示要拷贝的字节数。
函数返回值:
函数调用结束后为了方便我们判断是否拷贝成功,我们把目标地址返回。
调用:
模拟实现的思路:
要一个个字节进行交换,我们可以把传过来的指针强行转换为char*类型并进行解引用,拿到
一个字节进行交换,然后继续迭代,通过传入的num来控制循环。
注意:
①*(char*)dest++是不可以的,因为++的优先级大于强制类型转换,对空类型++是非法的。
②*((char*)dest)++在C里面是可以的,但是在C++里面不可以,因为强制转换产生的临时变量在C++里面不能进行++操作。
代码:
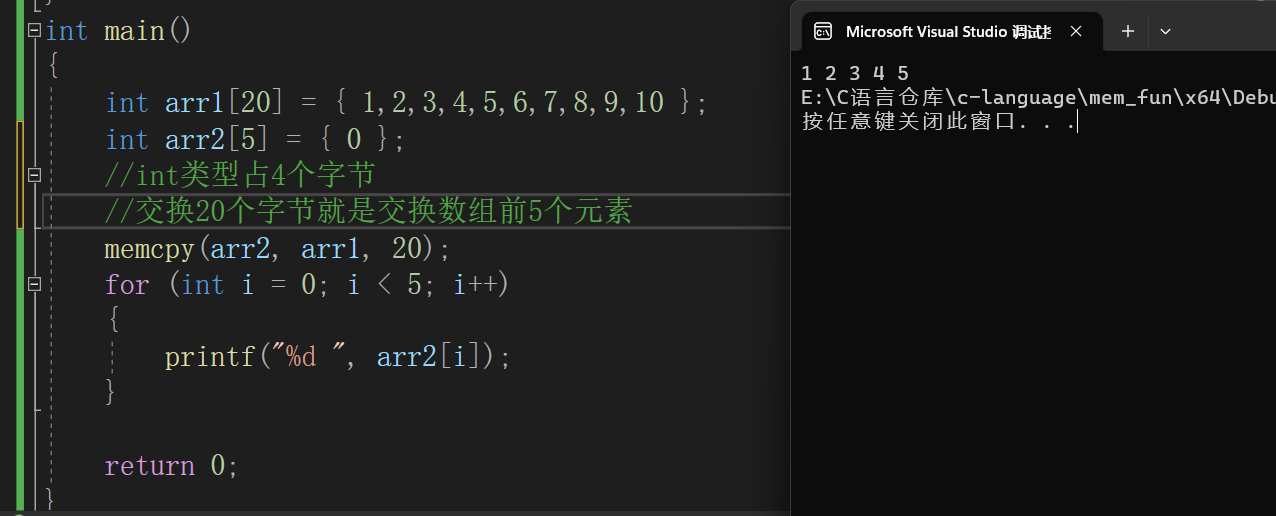
//内存拷贝函数(拷贝不重叠)加测试 void* my_memcpy(void* dest, const void* src, size_t num) { //断言,不能传空指针进来 assert(dest && src); //记录目标地址 void* ret = dest; while (num--) { *(char*)dest = *(char*)src; //对空类型计算是不符合规则的 dest = (char*)dest + 1; src = (char*)src + 1; } return ret; } int main() { int arr1[20] = { 1,2,3,4,5,6,7,8,9,10 }; int arr2[5] = { 0 }; //int类型占4个字节 //交换20个字节就是交换数组前5个元素 my_memcpy(arr2, arr1, 20); for (int i = 0; i < 5; i++) { printf("%d ", arr2[i]); } return 0; }
(2)memove( )函数
函数声明:void* memove(void* dest,const void* src,size_t num)
作用:用来拷贝重叠的两片内存空间。
函数参数的意义:
①dest指向用于存储复制内容的目标数组,类型强制转换为 void* 指针。
②src指向要复制的数据源,类型强制转换为 void* 指针。同时我们只是拷贝这一片空间的数据到目标空间而不是修改,所以用const进行修饰。
③num(无符号整型)表示要拷贝的字节数。
函数返回值:
函数调用结束后为了方便我们判断是否拷贝成功,我们把目标地址返回。
调用:
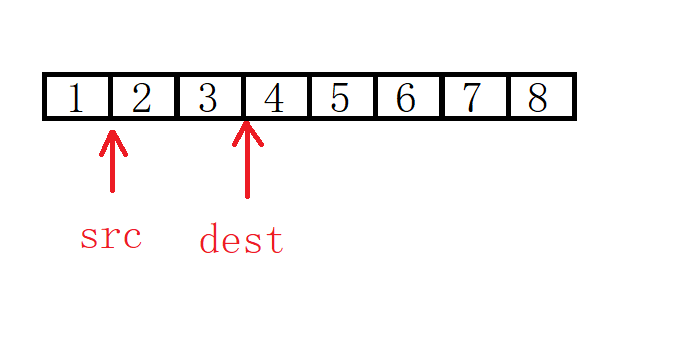
为什么要把重叠的情况单独拿出来?我们看下面这种情况:
这种目标地址大于源地址的情况,如果要拷贝的数据只有2和3,是没有问题的。
但是如果要拷贝2,3,4,5的话,我们希望的情况的1,2,3,2,3,4,5,8。但实际上我们进行第一次拷贝的时候就已经把4给覆盖掉了。
要防止后面的数据被提前覆盖,我们可以从后面往前拷贝,即先把5赋给7,然后4赋给6,这样就很好的解决了数值被覆盖的问题。
模拟实现的思路:
①进行分类,如果目标地址小于源地址,前向后拷贝;如果目标地址大于或者等于源地址,后向前拷贝。
②一个个字节进行交换,我们可以把传过来的指针强行转换为char*类型并进行解引用,拿到
一个字节进行交换,然后继续迭代,通过传入的num来控制循环。
代码:
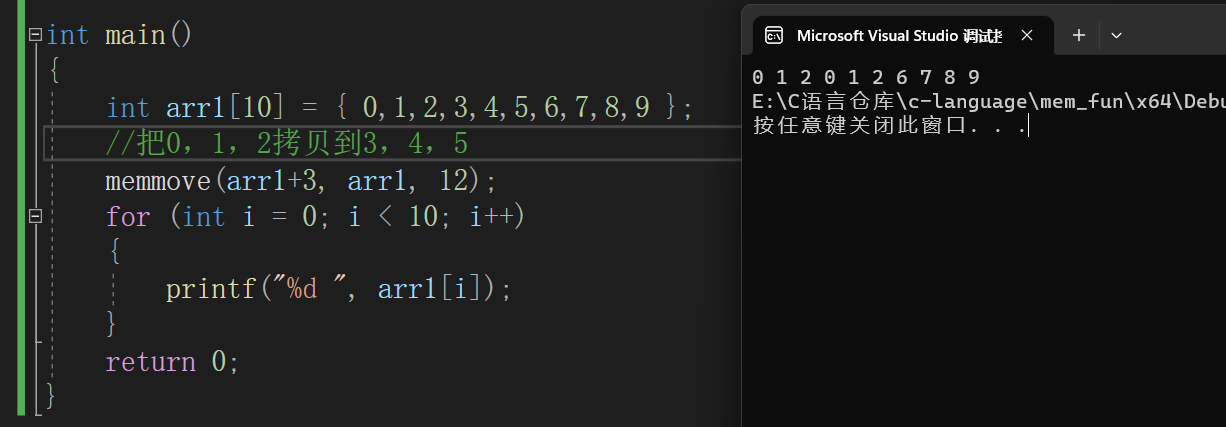
//内存拷贝函数(重叠)和测试 void* my_memmove(void* dest, const void* src, size_t num) { // 断言,不能传空指针进来 assert(dest && src); void* ret = dest; //如果目标地址小于源地址,前向后拷贝 if (dest < src) { while (num--) { *(char*)dest = *(char*)src; //对空类型计算是不符合规则的 dest = (char*)dest + 1; src = (char*)src + 1; } } //如果目标地址大于或者等于源地址,后向前拷贝 else { while (num--) { *((char*)dest + num) = *((char*)src + num); } } return ret; } int main() { int arr1[10] = { 0,1,2,3,4,5,6,7,8,9 }; //把0,1,2拷贝到3,4,5 my_memmove(arr1+4, arr1, 20); for (int i = 0; i < 10; i++) { printf("%d ", arr1[i]); } return 0; }
memcmp( )函数
函数声明:int memcmp(const void* ptr1,const void* ptr2,size_t num)
作用:用来比较两片内存空间,这里的比较不是比较数据,而是一个个字节进行比较,遇到不同的字节就判断大小。
函数参数的意义:
①ptr1和ptr2指向待比较的目标数组,类型强制转换为 void* 指针。同时我们只是比较而不是修改,所以用const进行修饰。
②num(无符号整型)表示要比较的字节数。
函数返回值:
如果两片空间的每一个字节都相同就返回0,如果前面的大就返回大于0的数,前面的小就返回小于0的数。
调用:
模拟实现的思路:
①一个个字节进行比较,用num来控制循环次数。
②如果不相同就直接返回两个字节的差值。
③如果循环结束就代表前num个字节相同,返回0。
代码:
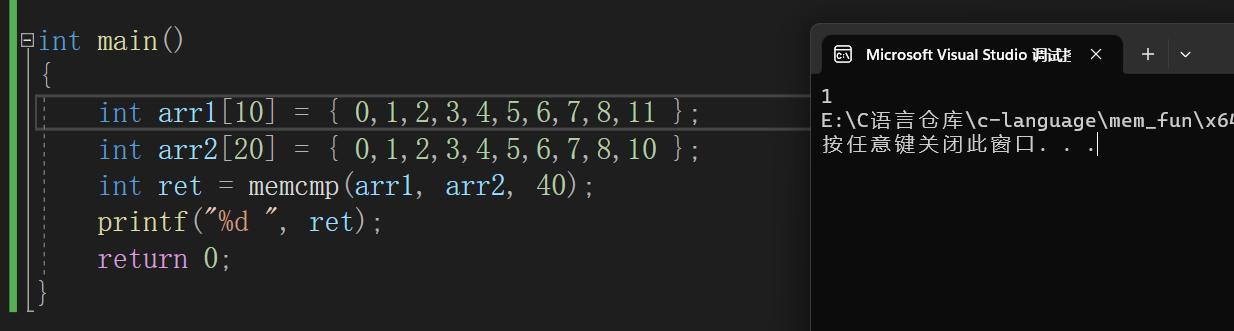
//内存比较函数和测试 int my_memcmp(const void* ptr1, const void* ptr2, size_t num) { //断言,不能传空指针进来 assert(ptr1 && ptr2); while (num--) { if (*(char*)ptr1 != *(char*)ptr2) return *(char*)ptr1-*(char*)ptr2; //如果相等,迭代 ptr1 = (char*)ptr1 + 1; ptr2 = (char*)ptr2 + 1; } return 0; } int main() { int arr1[10] = { 0,1,2,3,4,5,6,7,8,1 }; int arr2[20] = { 0,1,2,3,4,5,6,7,8,10 }; int ret = my_memcmp(arr1, arr2, 40); printf("%d ", ret); return 0; }
memset( )函数
函数声明:void* memset(void* ptr,int value,size_t num)
作用:用来初始化内存空间(以字节为单位)。
函数参数的意义:
①ptr指向待初始化的目标数组,类型强制转换为 void* 指针。
②value表示要被设置的值。该值以 int 形式传递,但是函数在填充内存块时是使用该值的无符号字符形式。
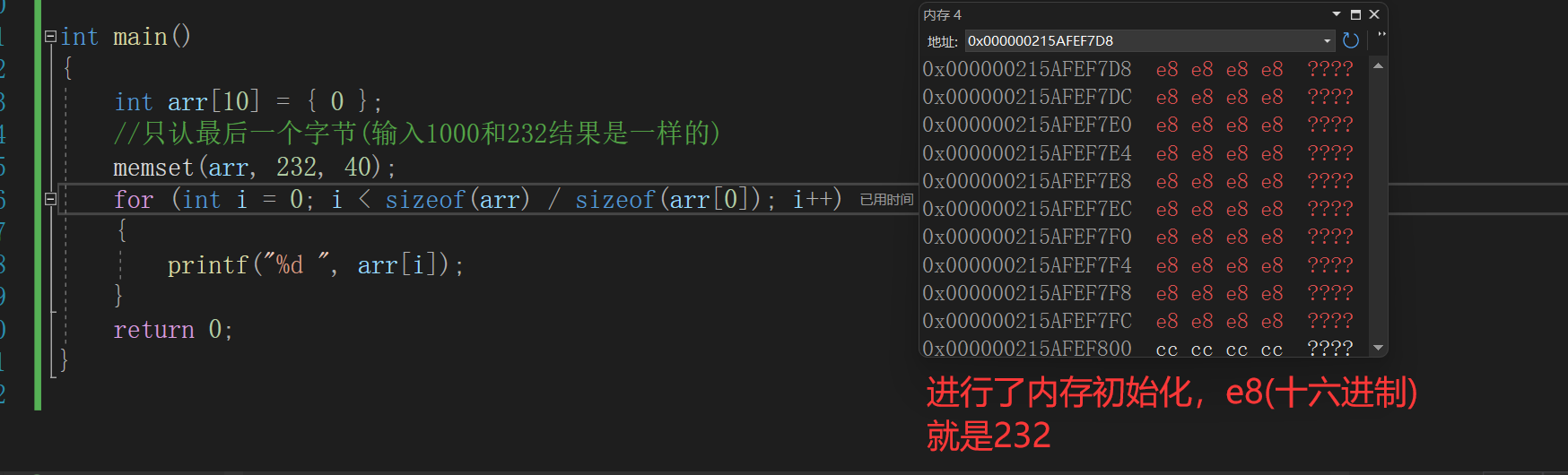
重点讲一下value这个参数,要知道我们是对每一个字节进行初始化,一个字节是无法存储像1000这样较大的数据的,这种情况初始化是取1000最后的一个字节进行初始化。
比如传入1000和232初始化的结果是一致的。
③num(无符号整型)表示要初始化的字节数。
函数返回值:
函数调用结束后为了方便我们判断是否初始化成功,我们把目标地址返回。
调用:
模拟实现的思路:
一个个字节进行初始化,我们可以把传过来的指针强行转换为char*类型并进行解引用,拿到
一个字节进行初始化,然后继续迭代,通过传入的num来控制循环。
代码:
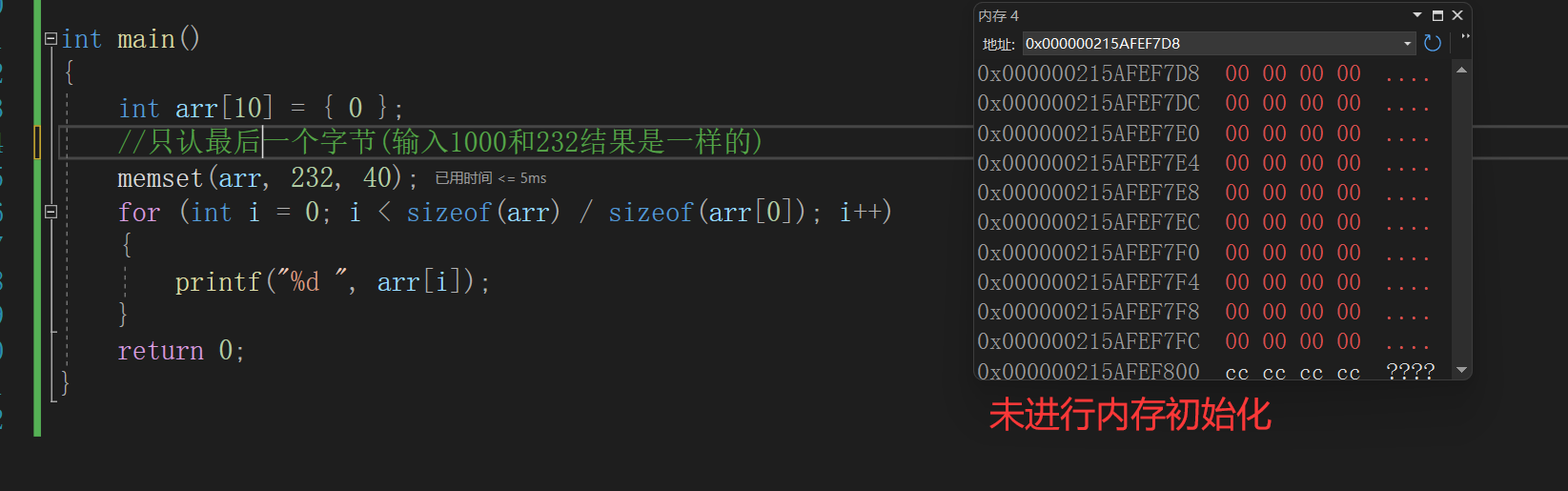
//内存设置函数(初始化) void* my_memset(void* ptr, int value, size_t num) { //断言,不能传空指针进来 assert(ptr); void* ret = ptr; while (num--) { *(char*)ptr = value; (char*)ptr = (char*)ptr + 1; } return ret; } int main() { int arr[10] = { 0 }; //只认最后一个字节(输入1000和232结果是一样的) my_memset(arr, 232, 40); for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++) { printf("%d ", arr[i]); } return 0; }

作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我想在一个没有Sass引擎的类中使用Sass颜色函数。我已经在项目中使用了sassgem,所以我认为搭载会像以下一样简单:classRectangleincludeSass::Script::FunctionsdefcolorSass::Script::Color.new([0x82,0x39,0x06])enddefrender#hamlengineexecutedwithcontextofself#sothatwithintemlateicouldcall#%stop{offset:'0%',stop:{color:lighten(color)}}endend更新:参见上面的#re
我正在尝试用ruby中的gsub函数替换字符串中的某些单词,但有时效果很好,在某些情况下会出现此错误?这种格式有什么问题吗NoMethodError(undefinedmethod`gsub!'fornil:NilClass):模型.rbclassTest"replacethisID1",WAY=>"replacethisID2andID3",DELTA=>"replacethisID4"}end另一个模型.rbclassCheck 最佳答案 啊,我找到了!gsub!是一个非常奇怪的方法。首先,它替换了字符串,所以它实际上修改了
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我有一些代码在几个不同的位置之一运行:作为具有调试输出的命令行工具,作为不接受任何输出的更大程序的一部分,以及在Rails环境中。有时我需要根据代码的位置对代码进行细微的更改,我意识到以下样式似乎可行:print"Testingnestedfunctionsdefined\n"CLI=trueifCLIdeftest_printprint"CommandLineVersion\n"endelsedeftest_printprint"ReleaseVersion\n"endendtest_print()这导致:TestingnestedfunctionsdefinedCommandLin
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
如何在Ruby中按名称传递函数?(我使用Ruby才几个小时,所以我还在想办法。)nums=[1,2,3,4]#Thisworks,butismoreverbosethanI'dlikenums.eachdo|i|putsiend#InJS,Icouldjustdosomethinglike:#nums.forEach(console.log)#InF#,itwouldbesomethinglike:#List.iternums(printf"%A")#InRuby,IwishIcoulddosomethinglike:nums.eachputs在Ruby中能不能做到类似的简洁?我可以只