常规卷积操作会对输入各个通道做卷积,然后对个通道的卷积结果进行求和,这种操作将卷积学习到的空间特征和通道特征混合在一起;而 SE 模块就是为了抽离这种混杂,让模型直接学习通道特征。
SE 模块显式地建模特征通道之间的相互依赖关系,通过学习的方式获取每个 channel 的重要程度,然后依照这个重要程度来对各个通道上的特征进行加权,从而突出重要特征,抑制不重要的特征。简单说就是训练一组权重,对各个 channel 的特征图加权。
本质上,SE 模块是在 channel 维度上做 attention 或者 gating 操作,这种注意力机制让模型可以更加关注重要的 channel 的特征。SE模块可以轻松的移植到其他网络架构,能够以轻微的计算性能损失带来极大的准确率提升。
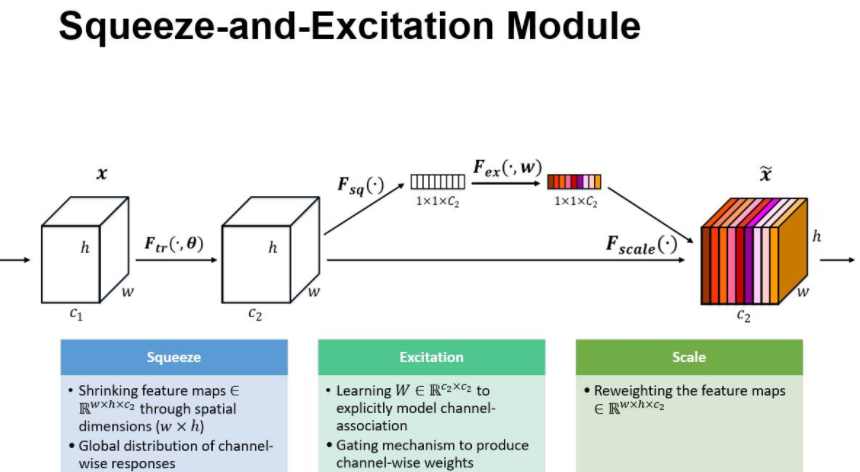
Ftr 是常规的卷积操作;U 后面是SE模块,包含 squeeze 和 excitation 两步;
由于卷积只是在局部空间内进行操作(没有全局感受野),很难获得做够的信息来提取 channel 之间的关系特征。 为了提取 channel 之间的关系,首先要将每个 channel 上的空间特征编码(压缩)为一个全局特征(可以理解为对每个 channel 的特征信息的进行融合),采用全局平局池化来实现,输出维度为1x1xC。

得到Squeeze的1x1xC全局特征后,加入一个FC全连接层(Fully Connected),对每个通道的重要性进行预测,得到不同channel的重要性大小后再作用(激励)到之前的feature map的对应channel上,再进行后续操作。

由两个全连接层组成,其中SERatio是一个缩放参数,这个参数的目的是为了减少通道个数从而降低计算量。 第一个全连接层有C*SERatio个神经元,输入为1×1×C,输出1×1×C×SERadio,起到降维作用。 第二个全连接层有C个神经元,输入为1×1×C×SERadio,输出为1×1×C。
最后是scale操作,在得到1×1×C向量之后,就可以对原来的特征图进行scale操作了。很简单,就是通道权重相乘,原有特征向量为W×H×C,将SE模块计算出来的各通道权重值分别和原特征图对应通道的二维矩阵相乘,得出的结果输出。
这里我们可以得出SE模块的属性:
参数量 = 2×C×C×SERatio
计算量 = 2×C×C×SERatio
总体来讲SE模块会增加网络的总参数量,总计算量,因为使用的是全连接层计算量相比卷积层并不大,但是参数量会有明显上升,所以MobileNetV3-Large中的总参数量比MobileNetV2多了2M。
SE实现注意力机制原因:
SE可以实现注意力机制最重要的两个地方一个是全连接层,另一个是相乘特征融合;
假设输入图像H×W×C,通过global pooling+FC层,拉伸成1×1×C,然后再与原图像相乘,将每个通道赋予权重。在去噪任务中,将每个噪声点赋予权重,自动去除低权重的噪声点,保留高权重噪声点,提高网络运行时间,减少参数计算。这也就是SE模块具有attention机制的原因。
SE模块的使用是很灵活的,可以在已有网络上添加而不打乱网络原有的主体结构。
ResNet中添加SE模块形成SE-ResNet网络,SE模块是在bottleneck结构之后加入的,如下图左边所示。

MobileNetV3版本中SE模块加在了bottleneck结构的内部,在深度卷积后增加SE块,scale操作后再做逐点卷积,如上图右边所示。MobileNetV3版本的SERadio系数为0.25。使用SE模块后的MobileNetV3的参数量相比MobileNetV2多了约2M,达到5.4M,但是MobileNetV3的精度得到了很大的提升,在图像分类和目标检测中准确率都有明显提升。
import torch
import torch.nn as nn
# 定义residual
class RB(nn.Module):
def __init__(self, nin, nout, ksize=3, stride=1, pad=1):
super(RB, self).__init__()
self.rb = nn.Sequential(nn.Conv2d(nin, nout, ksize, stride, pad),
nn.BatchNorm2d(nout),
nn.ReLU(inplace=True),
nn.Conv2d(nout, nout, ksize, stride, pad),
nn.BatchNorm2d(nout))
def forward(self, input):
x = input
x = self.rb(x)
return nn.ReLU(input + x)
# 定义SE模块
class SE(nn.Module):
def __init__(self, nin, nout, reduce=16):
super(SE, self).__init__()
self.gp = nn.AvgPool2d(1)
self.rb1 = RB(nin, nout)
self.se = nn.Sequential(nn.Linear(nout, nout // reduce),
nn.ReLU(inplace=True),
nn.Linear(nout // reduce, nout),
nn.Sigmoid())
def forward(self, input):
x = input
x = self.rb1(x)
b, c, _, _ = x.size()
y = self.gp(x).view(b, c)
y = self.se(y).view(b, c, 1, 1)
y = x * y.expand_as(x)
out = y + input
return out
net=SE(64,64)
print(net)
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
我一直致力于让我们的Rails2.3.8应用程序在JRuby下正确运行。一切正常,直到我启用config.threadsafe!以实现JRuby提供的并发性。这导致lib/中的模块和类不再自动加载。使用config.threadsafe!启用:$rubyscript/runner-eproduction'pSim::Sim200Provisioner'/Users/amchale/.rvm/gems/jruby-1.5.1@web-services/gems/activesupport-2.3.8/lib/active_support/dependencies.rb:105:in`co
我有一个Controller,我想为这个Controller创建一个助手,我可以在不包含它的情况下使用它。我尝试像这样创建一个与Controller同名的助手classCars::EnginesController我创建的助手是moduleCars::EnginesHelperdefcheck_fuellogger.debug("chekingfuel")endend我得到的错误是undefinedlocalvariableormethod`check_fuel'for#有没有我遗漏的约定? 最佳答案 如果你真的想在Controll
我有一个模块stat存在于目录结构中:lib/stat_creator/stat/在lib/stat_creator/stat.rb中,我在lib/stat_creator/stat/目录中有我需要的文件,以及:moduleStatCreatormoduleStatendend当我使用该模块时,我将这些类称为StatCreator::Stat::Foo.new现在我想要一个存在于应用程序中的根Stat类。我在app/models中制作了我的Stat类,并在routes.rb中进行了设置。但是,如果我转到Rails控制台并尝试在应用程序/模型中使用Stat类,例如:Stat.by_use
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Testingmodulesinrspec目前我正在使用rspec成功测试我的模块,如下所示:require'spec_helper'moduleServicesmoduleAppServicedescribeAppServicedodescribe"authenticate"doit"shouldauthenticatetheuser"dopending"authenticatetheuser"endendendendend我的模块位于应用程序/服务/services.rb应用程序/服务/app_servi