目录
2、然后,配置application.yml,让微服务通过注册中心找到seata-tc-server:
1、修改application.yml文件(每个参与事务的微服务),开启XA模式:
2、给发起全局事务的入口方法添加@GlobalTransactional注解,
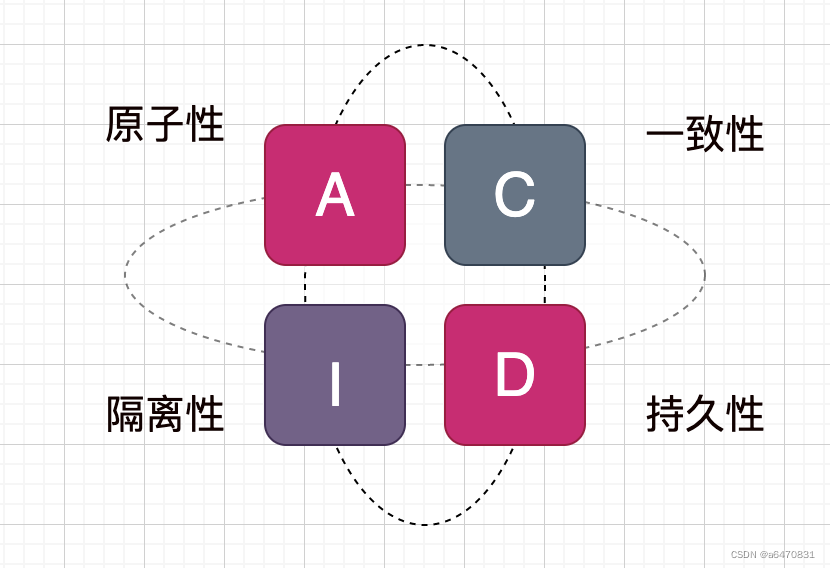
- 原子性:事务中的所有操作,要么全部成功,要么全部失败
- 一致性:要保证数据库内部完整性约束、声明性约束
- 隔离性:对同一资源操作的事务不能同时发生
- 持久性:对数据库做的一切修改将永久保存,不管是否出现故障
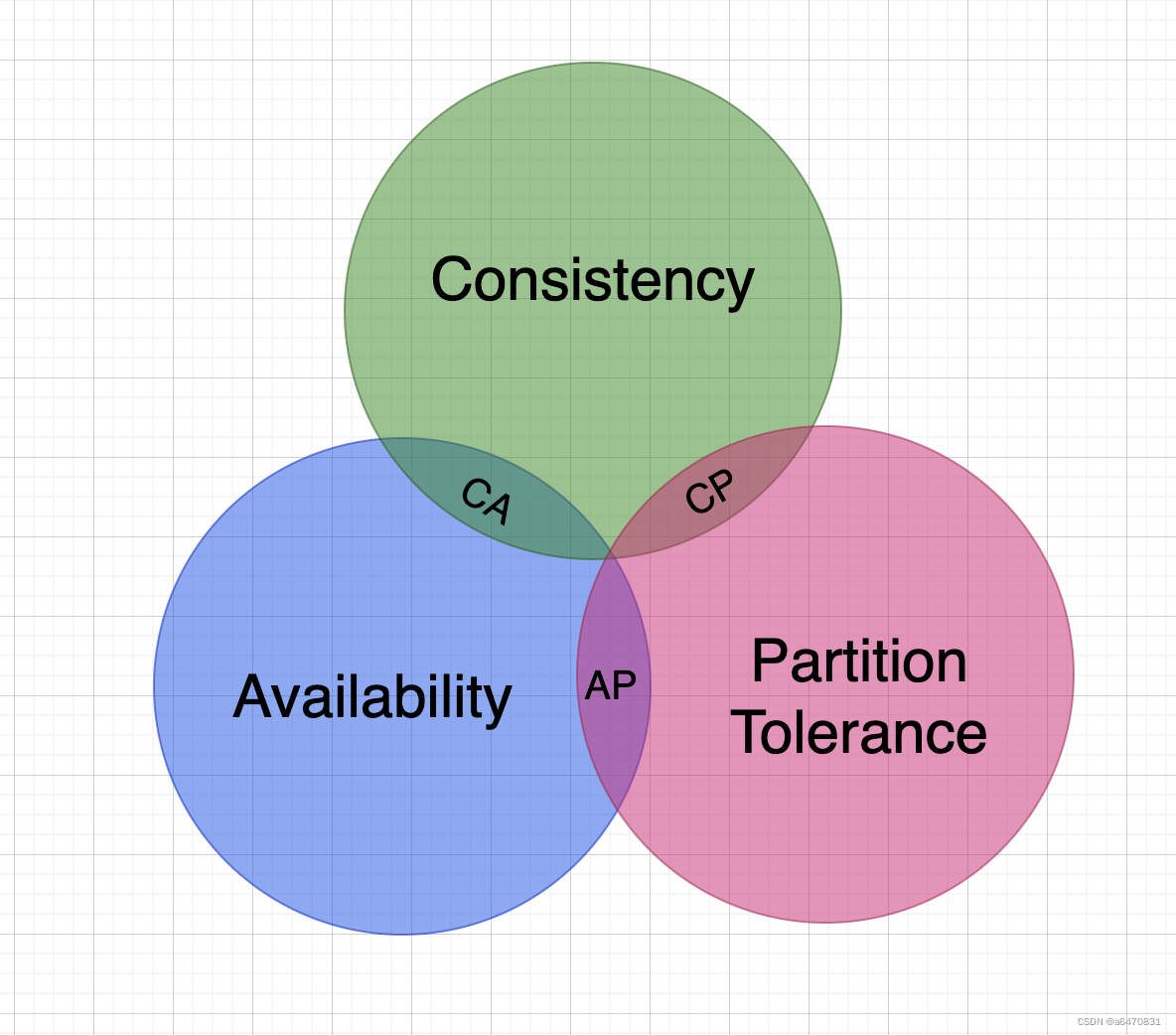
1998年,加州大学的计算机科学家 Eric Brewer 提出,分布式系统有三个指标:
- Consistency(一致性)
- Availability(可用性)
- Partition tolerance (分区容错性)
Eric Brewer 说,分布式系统无法同时满足这三个指标。 这个结论就叫做 CAP 定理。
Consistency(一致性):用户访问分布式系统中的任意节点,得到的数据必须一致
Availability (可用性):用户访问集群中的任意健康节点,必须能得到响应,而不是超时或拒绝
Partition(分区):因为网络故障或其它原因导致分布式系统中的部分节点与其它节点失去连接,形成独立分区。
Tolerance(容错):在集群出现分区时,整个系统也要持续对外提供服务
BASE理论是对CAP的一种解决思路,包含三个思想:
- Basically Available (基本可用):分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
- Soft State(软状态):在一定时间内,允许出现中间状态,比如临时的不一致状态。
- Eventually Consistent(最终一致性):虽然无法保证强一致性,但是在软状态结束后,最终达到数据一致。
而分布式事务最大的问题是各个子事务的一致性问题,因此可以借鉴CAP定理和BASE理论:
- AP模式:各子事务分别执行和提交,允许出现结果不一致,然后采用弥补措施恢复数据即可,实现最终一致。
- CP模式:各个子事务执行后互相等待,同时提交,同时回滚,达成强一致。但事务等待过程中,处于弱可用状态
Seata是 2019 年 1 月份蚂蚁金服和阿里巴巴共同开源的分布式事务解决方案。
致力于提供高性能和简单易用的分布式事务服务,为用户打造一站式的分布式解决方案。
官网地址:http://seata.io/,其中的文档、播客中提供了大量的使用说明、源码分析。
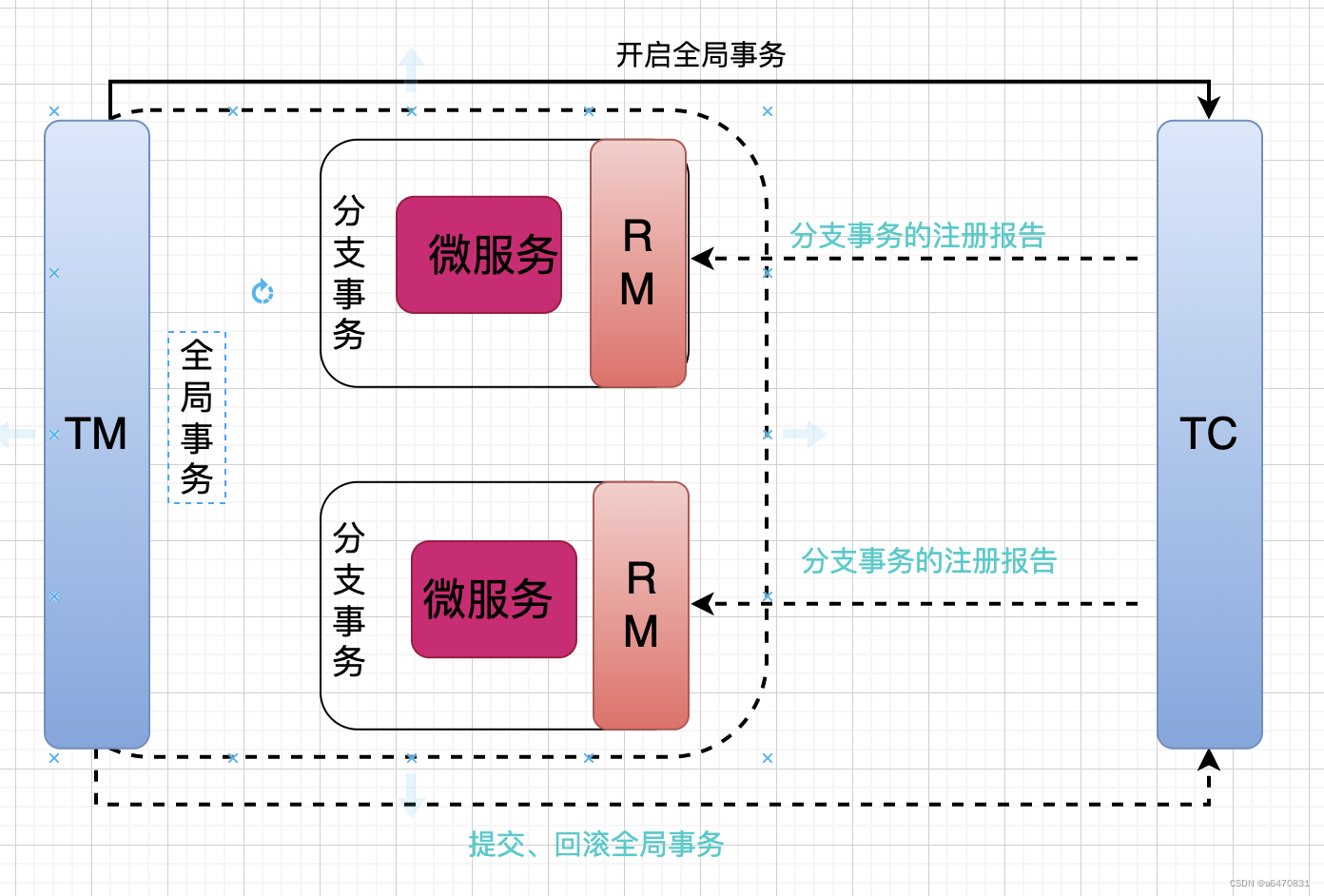
Seata事务管理中有三个重要的角色:
- TC (Transaction Coordinator) - 事务协调者:维护全局和分支事务的状态,协调全局事务提交或回滚。
- TM (Transaction Manager) - 事务管理器:定义全局事务的范围、开始全局事务、提交或回滚全局事务。
- RM (Resource Manager) - 资源管理器:管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
Seata提供了四种不同的分布式事务解决方案:
- XA模式:强一致性分阶段事务模式,牺牲了一定的可用性,无业务侵入
- TCC模式:最终一致的分阶段事务模式,有业务侵入
- AT模式:最终一致的分阶段事务模式,无业务侵入,也是Seata的默认模式
- SAGA模式:长事务模式,有业务侵入
1、首先,引入seata相关依赖:
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-seata</artifactId> <exclusions> <!--版本较低,1.3.0,因此排除--> <exclusion> <artifactId>seata-spring-boot-starter</artifactId> <groupId>io.seata</groupId> </exclusion> </exclusions> </dependency> <!--seata starter 采用1.4.2版本--> <dependency> <groupId>io.seata</groupId> <artifactId>seata-spring-boot-starter</artifactId> <version>${seata.version}</version> </dependency>2、然后,配置application.yml,让微服务通过注册中心找到seata-tc-server:
XA 规范 是 X/Open 组织定义的分布式事务处理(DTP,Distributed Transaction Processing)标准,
XA 规范 描述了全局的TM与局部的RM之间的接口,几乎所有主流的数据库都对 XA 规范 提供了支持。
seata的XA模式做了一些调整,但大体相似:
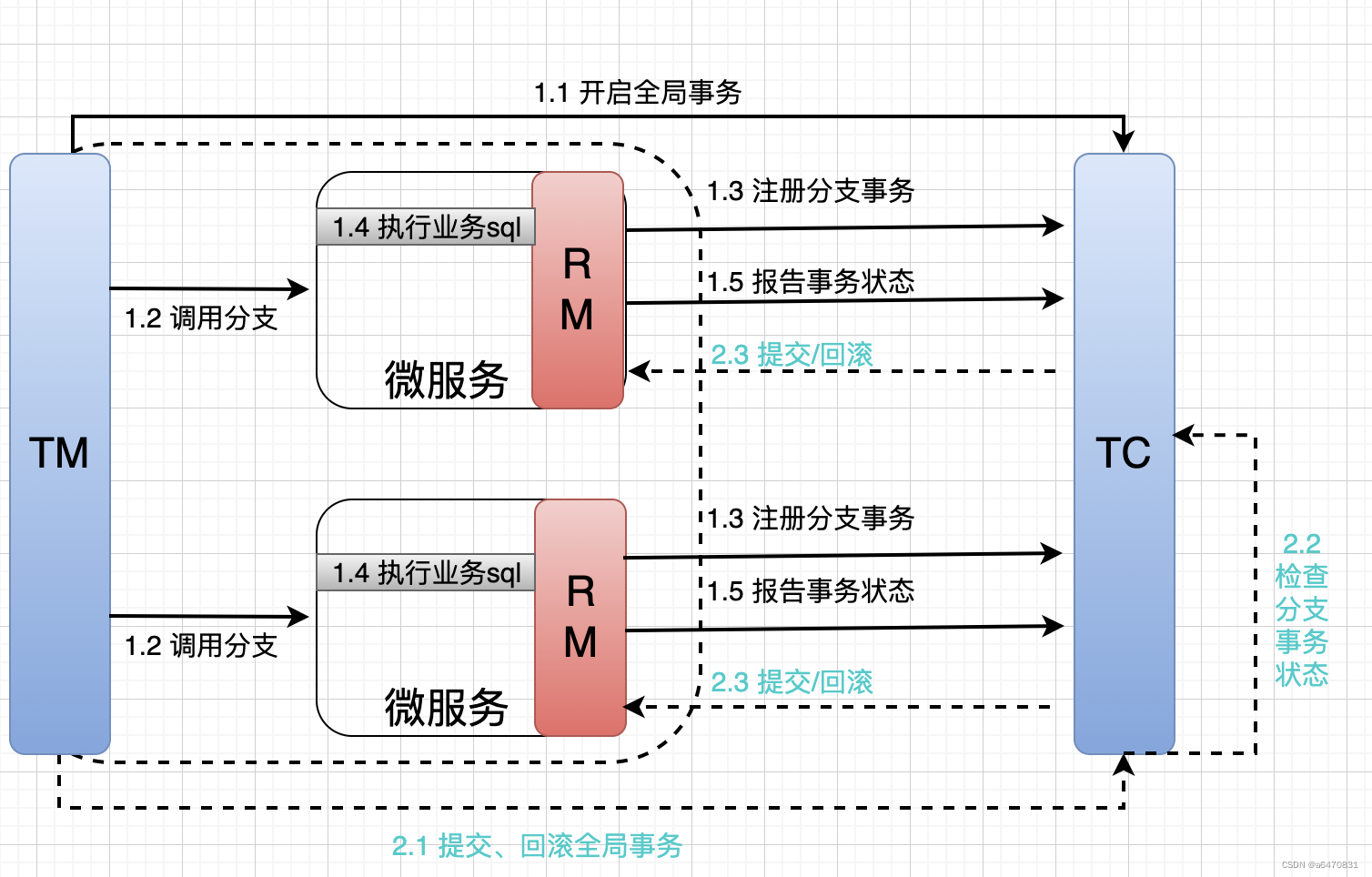
RM一阶段的工作:
- 注册分支事务到TC
- 执行分支业务sql但不提交
- 报告执行状态到TC
TC二阶段的工作:
TC检测各分支事务执行状态
- 如果都成功,通知所有RM提交事务
- 如果有失败,通知所有RM回滚事务
RM二阶段的工作:
- 接收TC指令,提交或回滚事务
Seata的starter已经完成了XA模式的自动装配,实现非常简单,步骤如下:
1、修改application.yml文件(每个参与事务的微服务),开启XA模式:
seata: data-source-proxy-mode: XA # 开启数据源代理的XA模式2、给发起全局事务的入口方法添加@GlobalTransactional注解,
本例中是OrderServiceImpl中的create方法:
@Override@GlobalTransactional public Long create(Order order) { // 创建订单 orderMapper.insert(order); // 扣余额 ...略 // 扣减库存 ...略 return order.getId(); }3、重启服务并测试
AT模式同样是分阶段提交的事务模型,不过缺弥补了XA模型中资源锁定周期过长的缺陷。
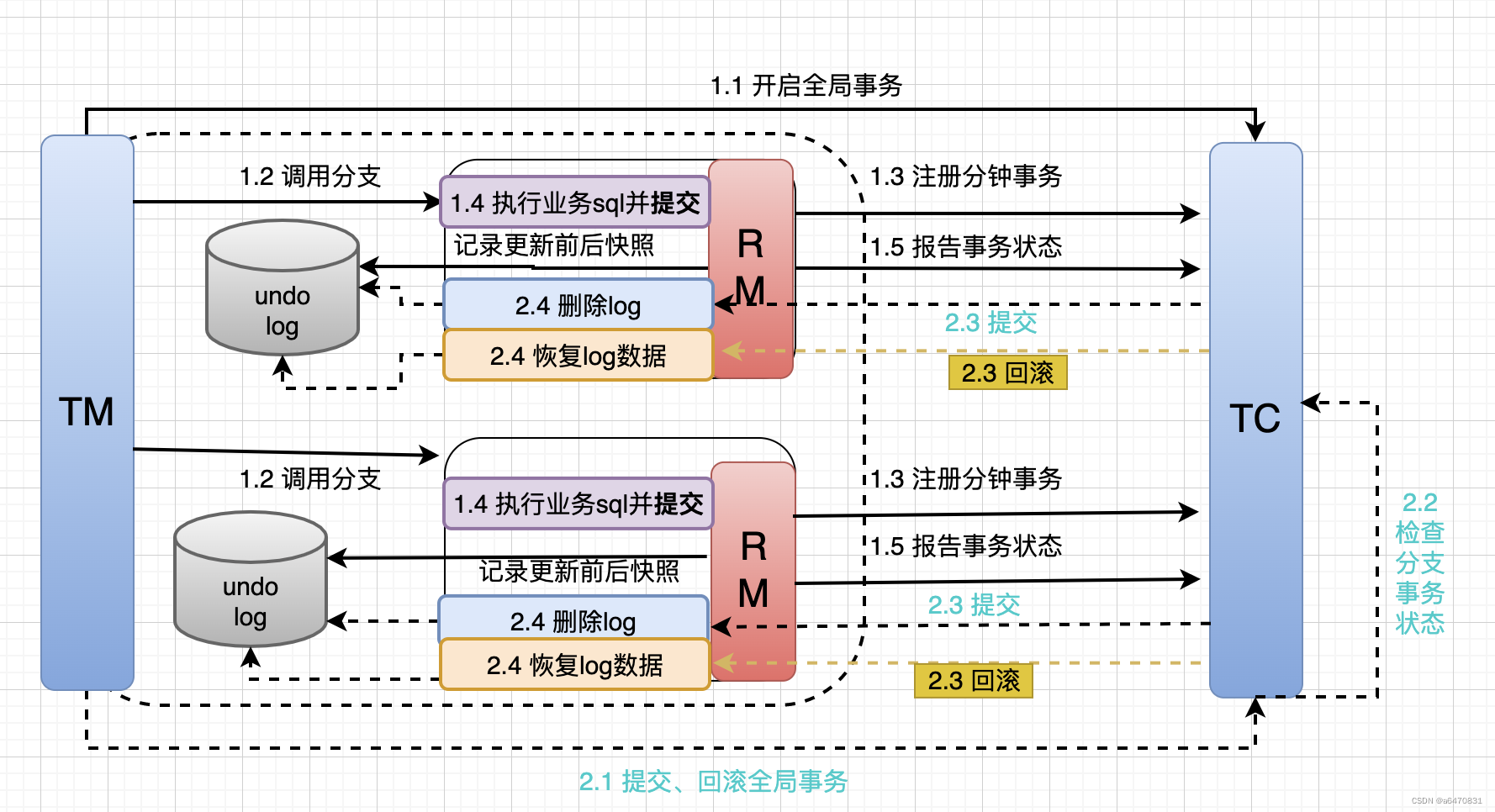
阶段一RM的工作:
- 注册分支事务
- 记录undo-log(数据快照)
- 执行业务sql并提交
- 报告事务状态
阶段二提交时RM的工作:
- 删除undo-log即可
阶段二回滚时RM的工作:
- 根据undo-log恢复数据到更新前
流程如下:
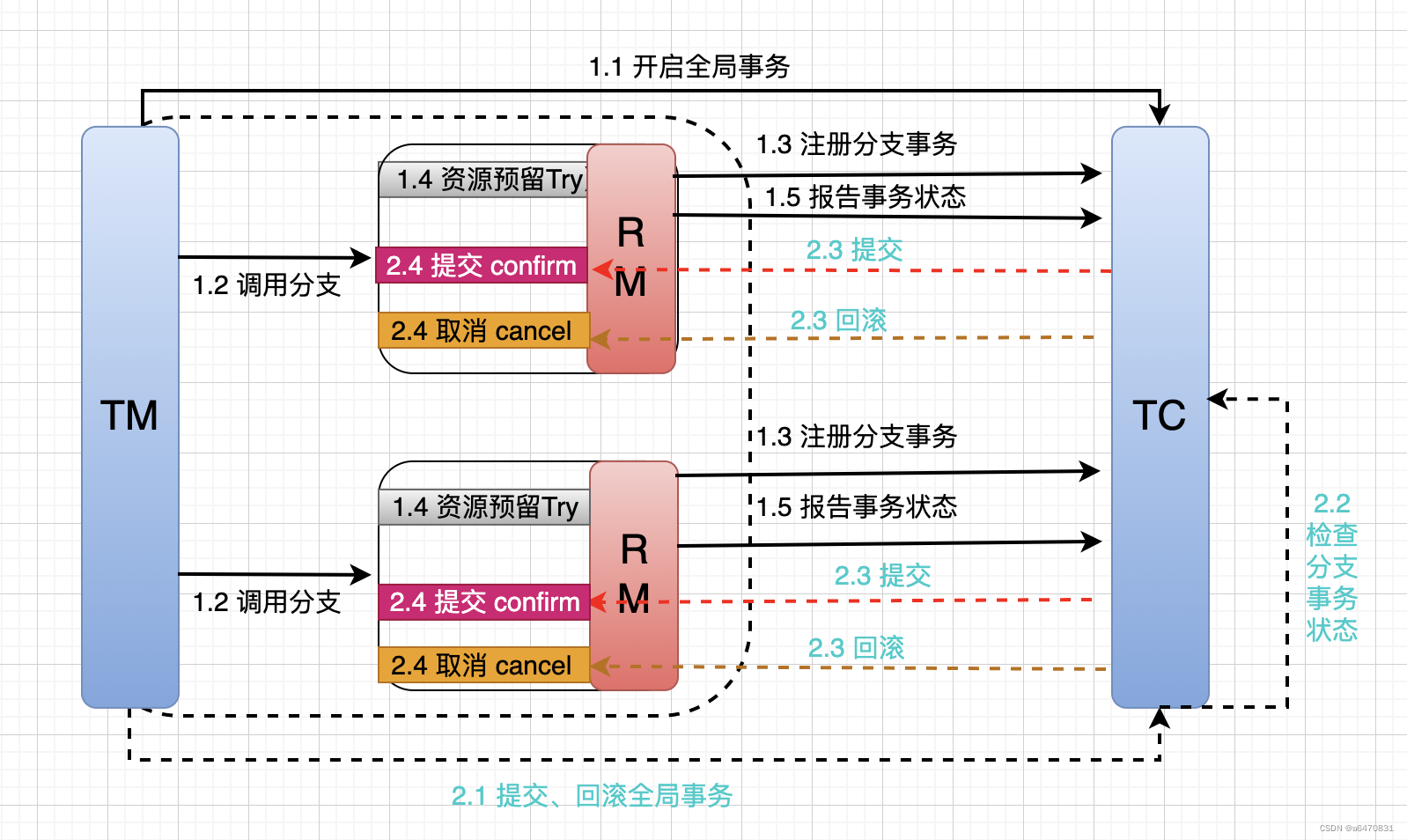
TCC模式与AT模式非常相似,每阶段都是独立事务,不同的是TCC通过人工编码来实现数据恢复。需要实现三个方法:
- Try:资源的检测和预留;
- Confirm:完成资源操作业务;要求 Try 成功 Confirm 一定要能成功。
- Cancel:预留资源释放,可以理解为try的反向操作。
TCC的工作模型图:
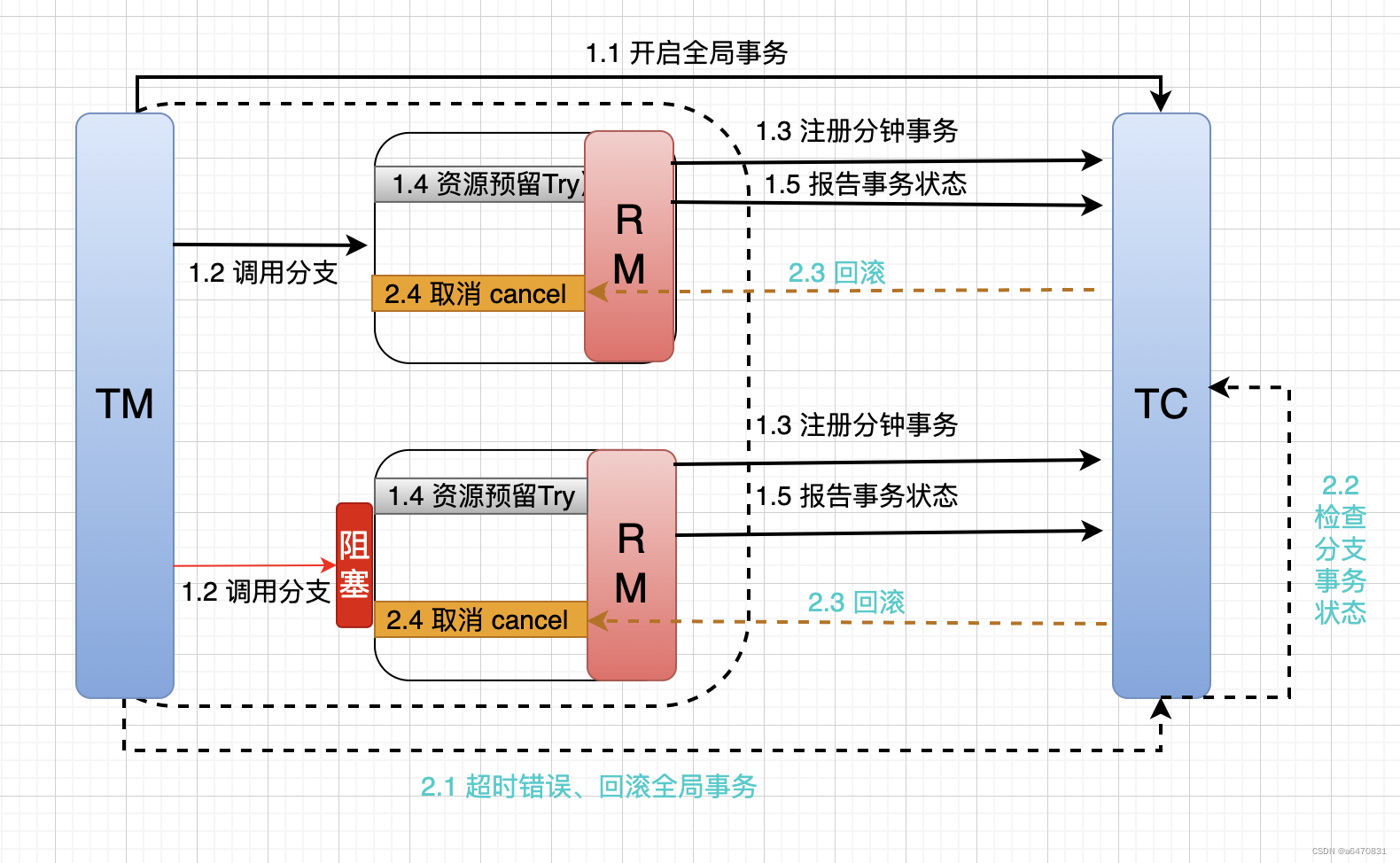
当某分支事务的try阶段阻塞时,可能导致全局事务超时而触发二阶段的cancel操作。在未执行try操作时先执行了cancel操作,这时cancel不能做回滚,就是空回滚。
对于已经空回滚的业务,如果以后继续执行try,就永远不可能confirm或cancel,这就是业务悬挂。应当阻止执行空回滚后的try操作,避免悬挂
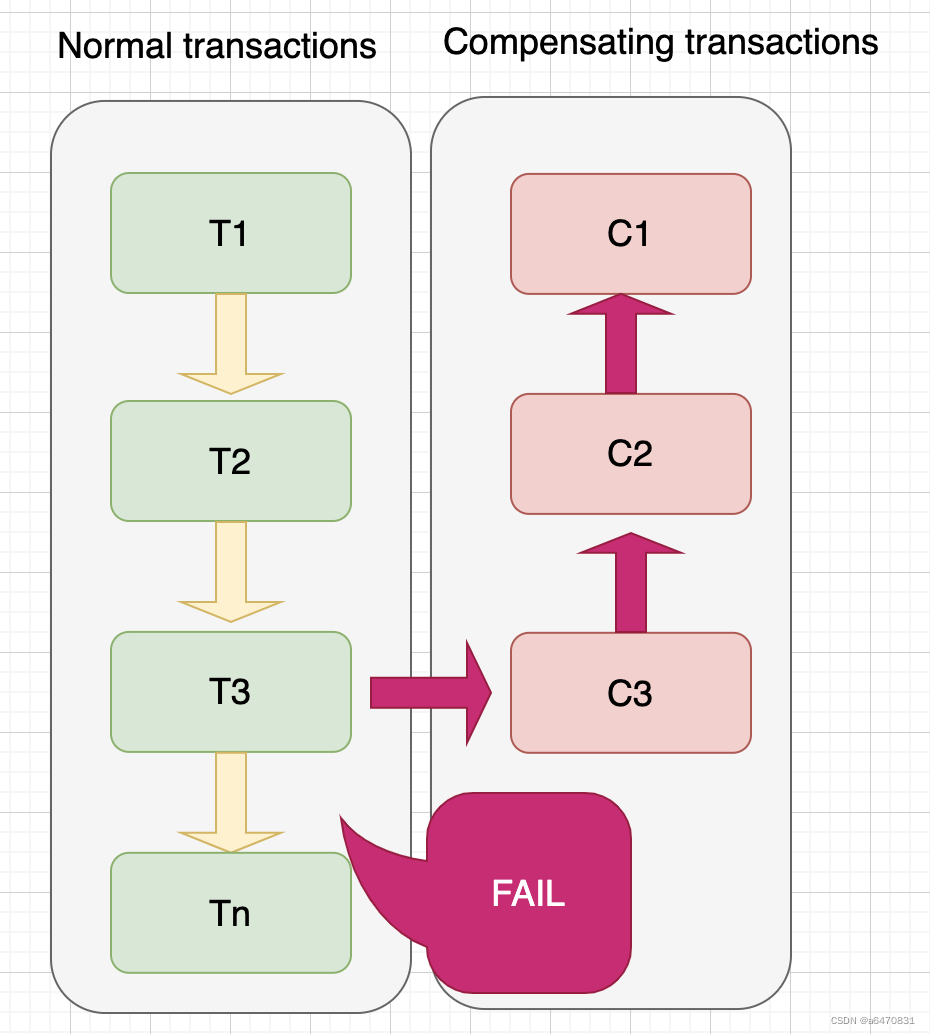
Saga模式是SEATA提供的长事务解决方案。也分为两个阶段:
- 一阶段:直接提交本地事务
- 二阶段:成功则什么都不做;失败则通过编写补偿业务来回滚
Saga模式优点:
- 事务参与者可以基于事件驱动实现异步调用,吞吐高
- 一阶段直接提交事务,无锁,性能好
- 不用编写TCC中的三个阶段,实现简单
缺点:
- 软状态持续时间不确定,时效性差
- 没有锁,没有事务隔离,会有脏写
|
| XA | AT | TCC | SAGA |
| 一致性 | 强一致 | 弱一致 | 弱一致 | 最终一致 |
| 隔离性 | 完全隔离 | 基于全局锁隔离 | 基于资源预留隔离 | 无隔离 |
| 代码侵入 | 无 | 无 | 有,要编写三个接口 | 有,要编写状态机和补偿业务 |
| 性能 | 差 | 好 | 非常好 | 非常好 |
| 场景 | 对一致性、隔离性有高要求的业务 | 基于关系型数据库的大多数分布式事务场景都可以 | 对性能要求较高的事务。 有非关系型数据库要参与的事务。 | 业务流程长、业务流程多 参与者包含其它公司或遗留系统服务,无法提供 TCC 模式要求的三个接口 |

我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
我已经开始使用mysql2gem。我试图弄清楚一些基本的事情——其中之一是如何明确地执行事务(对于批处理操作,比如多个INSERT/UPDATE查询)。在旧的ruby-mysql中,这是我的方法:client=Mysql.real_connect(...)inserts=["INSERTINTO...","UPDATE..WHEREid=..",#etc]client.autocommit(false)inserts.eachdo|ins|beginclient.query(ins)rescue#handleerrorsorabortentirelyendendclient.commi
保存成功后可以回滚吗?让我有一个带有属性名称、电子邮件等的用户模型。例如u=User.newu.name="test_name"u.email="test@email.com"u.save现在记录将成功保存在数据库中,之后我想回滚我的事务(不是销毁或删除)。有什么想法吗? 最佳答案 您可以通过交易来做到这一点,请参阅http://markdaggett.com/blog/2011/12/01/transactions-in-rails/例子:User.transactiondoUser.create(:username=>'Nemu
我正在尝试使用Ruby将二进制文件转换为十六进制。目前我有以下内容:File.open(out_name,'w')do|f|f.puts"constunsignedintmodFileSize=#{data.length};"f.puts"constcharmodFile[]={"first_line=truedata.bytes.each_slice(15)do|a|line=a.map{|b|",#{b}"}.joiniffirst_linef.putsline[1..-1]elsef.putslineendfirst_line=falseendf.puts"};"end这是以下代
我目前正在上一门数据库类(class),其中一个实验室问题让我困惑于如何实现上述内容,事实上,如果可能的话。我试过搜索docs但是定义的交易方式比较模糊。这是我第一次尝试在没有Rails的情况下进行任何数据库操作,所以我有点迷茫。我已经成功地创建了一个到我的postgresql数据库的连接并且可以执行语句,我需要做的最后一件事是根据一个简单的条件回滚一个事务。请允许我向您展示代码:require'pg'@conn=PG::Connection.open(:dbname=>'db_15_11_labs')@conn.prepare('insert','INSERTINTOhouse(ho
如何使用Rails中的事务block一次性更新/保存模型的多个实例?我想更新数百条记录的值;每条记录的值都不同。这不是一个属性的批量更新情况。Model.update_all(attr:value)在这里不合适。MyModel.transactiondothings_to_update.eachdo|thing|thing.score=rand(100)+rand(100)thing.saveendendsave似乎发布了它自己的事务,而不是将更新分批处理到周围的事务中。我希望所有更新都在一次大交易中进行。我怎样才能做到这一点? 最佳答案
给定以下代码:defcreate@something=Something.new(params[:something])thing=@something.thing#anothermodel#modificationofattributesonboth'something'and'thing'omitted#doIneedtowrapitinsideatransactionblock?@something.savething.saveendcreate方法是隐式包装在ActiveRecord事务中,还是需要将其包装到事务block中?如果我确实需要包装它,这是最好的方法吗?
我有一个启动DRb服务的脚本,然后生成处理程序对象并通过DRb.thread.join等待。我希望脚本一直运行直到被明确杀死,所以我添加了trap"INT"doDRb.stop_serviceend在Ruby1.8下成功停止DRb服务并退出,但在1.9下似乎死锁(在OSX10.6.7上)。对该进程进行采样显示在semaphore_wait_signal_trap中有几个线程在旋转。我假设我在调用stop_service时做错了什么,但我不确定是什么。谁能给我任何关于如何正确处理它的指示? 最佳答案 好的,我想我已经找到了解决方案。如