
论文笔记:CLIP:Learning Transferable Visual Models From Natural Language Supervision详解_nocol.的博客-CSDN博客
通俗理解DDPM:生成扩散模型_nocol.的博客-CSDN博客

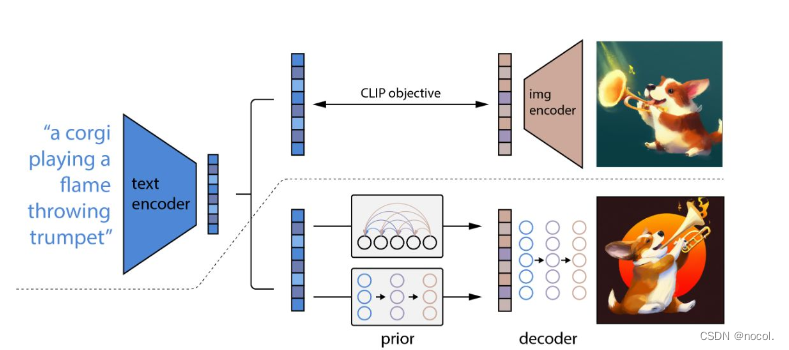
DALL·E 2 这个模型的任务很简单:输入文本text,生成与文本高度对应的图片。
它主要包括三个部分:CLIP,先验模块prior和img decoder。其中CLIP又包含text encoder和img encoder。(在看DALL·E 2之前强烈建议先搞懂CLIP模型的训练和运作机制)
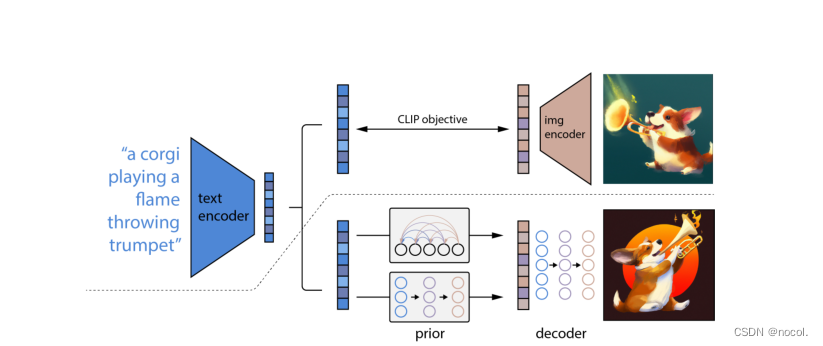
DALL·E 2是将其子模块分开训练的,最后将这些训练好的子模块拼接在一起,最后实现由文本生成图像的功能。
1. 训练CLIP,使其能够编码文本和对应图像
这一步是与CLIP模型的训练方式完全一样的,目的是能够得到训练好的text encoder和img encoder。这么一来,文本和图像都可以被编码到相应的特征空间。对应上图中的虚线以上部分。
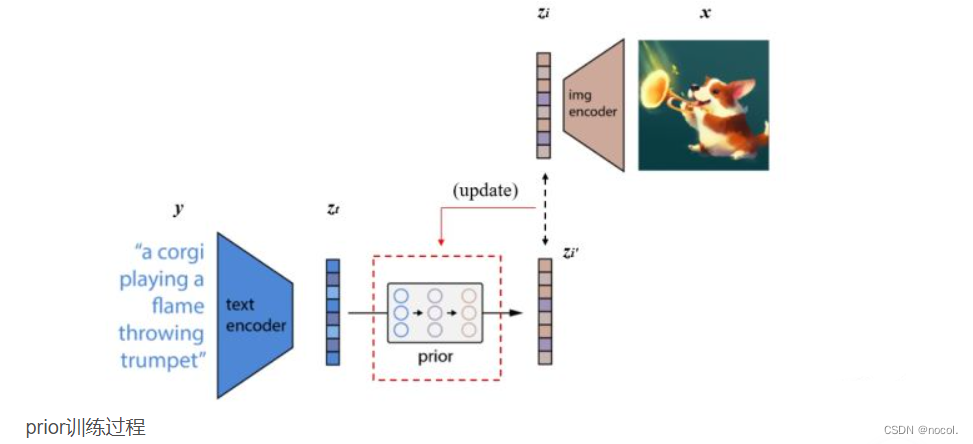
2. 训练prior,使文本编码可以转换为图像编码
论文中对于该步骤作用的解释为:
A prior P(zi|y) that produces CLIP image embeddings zi conditioned on captions y .
实际的训练过程为:将CLIP中训练好的text encoder拿出来,输入文本y,得到文本编码zt。同样的,将CLIP中训练好的img encoder拿出来,输入图像 x 得到图像编码zi。我们希望prior能从zt获取相对应的zi。假设zt经过prior输出的特征为zi′,那么我们自然希望zi′与zi越接近越好,这样来更新我们的prior模块。最终训练好的prior,将与CLIP的text encoder串联起来,它们可以根据我们的输入文本y生成对应的图像编码特征zi了。关于具体如何训练prior,有兴趣的小伙伴可以精度一下原文,作者使用了主成分分析法PCA来提升训练的稳定性。
在DALL·E 2 模型中,作者团队尝试了两种先验模型:自回归式Autoregressive (AR) prior 和扩散模型Diffusion prior [1]。实验效果上发现两种模型的性能相似,而因为扩散模型效率较高,因此最终选择了扩散模型作为prior模块。本文不具体解释扩散模型,大家可以查阅参考博文,或者我后期再整理相关知识。
3. 训练decoder生成最终的图像
论文中对于该步骤作用的解释为:
A decoder P(x|zi,y) that produces images x conditioned on CLIP image embeddingszi (and optionally text captions y ).
也就是说我们要训练decoder模块,从图像特征zi还原出真实的图像 x ,如下图左边所示。这个过程与自编码器类似,从中间特征层还原出输入图像,但又不完全一样。我们需要生成出的图像,只需要保持原始图像的显著特征就可以了,这样以便于多样化生成,例如下图右边的示例。

左:训练decoder的过程。右:图像经过img encoder再经decoder得到重建图像。顶部图像为输入。
DALL-E 2使用的是改进的GLIDE模型 [2]。这个模型可以根据CLIP图像编码的zi,还原出具有相同与 x 有相同语义,而又不是与 x 完全一致的图像。
经过以上三个步骤的训练,已经可以完成DALL·E 2预训练模型的搭建了。我们这事丢掉CLIP中的img encoder,留下CLIP中的text encoder,以及新训练好的prior和decoder。这么一来流程自然很清晰了:由text encoder将文本进行编码,再由prior将文本编码转换为图像编码,最后由decoder进行解码生成图像。
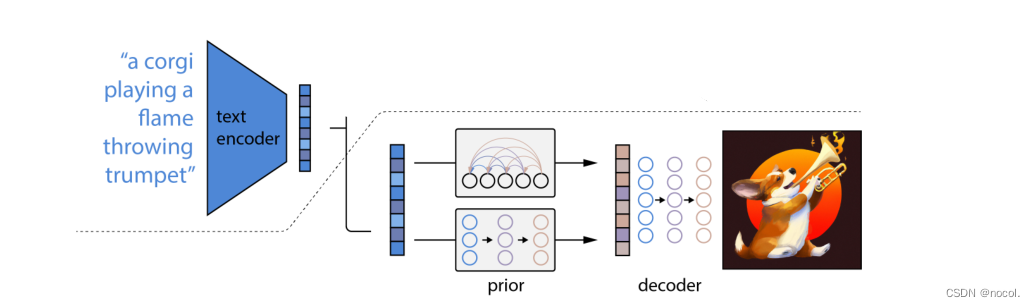
DALL·E 2 推理过程
看下DALL·E 2 在MS-COCO prompts上的生成效果:

本文作者提到了DALL·E 2的三个不足之处:

DALL·E 2与GLIDE由“a red cube on top of a blue cube”生成的图像
DALL·E 2 不容易将红色和蓝色分辨出来。这可能来源于CLIP的embedding过程没有将属性绑定到物体上;并且decoder的重建过程也经常混淆属性和物体,如下图所示,例如中间的柯基图片,有的重建结果将其帽子和领结的颜色搞反了。

decoder经常混淆属性和物体
2. DALL·E 2对于将文本放入图像中的能力不足,如下图所示,我们希望得到一个写着deep learning的标志,而标志却将单词/词组拼写得很离谱。这个问题可能来源于CLIP embedding不能精确地从输入地文本提取出“拼写”信息。

DALL·E 2由“A sign that says deep learning.”生成的图像
3.DALL·E 2 在生成复杂场景图片时,对细节处理有缺陷,如下图所示生成Times Square的高质量图片。这个可能来源于decoder的分层(hierarchy)结构,先生成64 × 64的图像,再逐步上采样得到最终结果的。如果将decoder先生成的图像分辨率提高,比如从64 × 64提升到128 × 128,那么这个问题可能可以缓解,但要付出更大计算量和训练成本的代价。

DALL·E 2由“A high quality photo of Times Square.”生成的图像
待更新内容:代码实现以及上手使用(OpenAI仍未开源,目前可先使用非官方实现代码)
原文链接:DALL·E 2 解读 | 结合预训练CLIP和扩散模型实现文本-图像生成-pudn.com
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我在开发的Rails3网站的一些搜索功能上遇到了一个小问题。我有一个简单的Post模型,如下所示:classPost我正在使用acts_as_taggable_on来更轻松地向我的帖子添加标签。当我有一个标记为“rails”的帖子并执行以下操作时,一切正常:@posts=Post.tagged_with("rails")问题是,我还想搜索帖子的标题。当我有一篇标题为“Helloworld”并标记为“rails”的帖子时,我希望能够通过搜索“hello”或“rails”来找到这篇帖子。因此,我希望标题列的LIKE语句与acts_as_taggable_on提供的tagged_with方法
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案