目录
三、Fast and Efficient Saliency (FES)
完整代码:李忆如 - Gitee.com
本系列博客重点在计算机视觉的概念原理与代码实践,不包含繁琐的数学推导(有问题欢迎在评论区讨论指出,或直接私信联系我)。
第一章 计算机视觉——图像去噪及直方图均衡化(图像增强)_@李忆如的博客
第二章 计算机视觉——车道线(路沿)检测_@李忆如的博客-CSDN博客
第三章 计算机视觉——图像视觉显著性检测
梗概
本篇博客主要介绍图像显著性检测(注意预测)定义、原理及其相关流程。探究并实践不同数据集、不同平台下传统显著性检测算法与深度学习的显著性检测算法,故选择了Matlab下的传统算法Fast and Efficient Saliency (FES)与Python下的深度学习算法MSI-Net进行实验。此外,还在部分开源平台进行了线上注意预测尝试,另外使用了不同的评价标准对效果进行评价与对比(内附数据、python、matlab代码)
请选择一种基于图像的注意预测算法,使用该算法进行图像注意区域的预测,并使用注意预测的常用评价标准进行评价。在这里请给出方法简介、原图像、预测结果、评价结果。
视觉显著性是指对于真实世界中的场景,人们会自动的识别出感兴趣区域,并对感兴趣的区域进行处理,忽略掉不感兴趣的区域。
图像的注意预测,也称视觉显著性检测。指通过智能算法模拟人的视觉系统特点,预测人类的视觉凝视点和眼动,提取图像中的显著区域(即人类感兴趣的区域),是计算机视觉领域关键的图像分析技术。部分图像及其注意预测结果示例如图1所示:

图1 部分图像及其注意预测结果示例
自1980年Treisman和Gelade提出开创性的自底向上的注意力模型以来,涌现出大量的注意预测算法。主要可以分为两个阶段,第一阶段为基于强度、颜色和方向等传统尺度空间手工特征的注意预测算法。第二个阶段,随着计算机神经网络技术的革新和发展,基于深度学习的注意预测算法大量出现。
对于传统注意预测算法,由于其特征提取和学习方法都以图像本身空间特征为基础,缺乏多语义等深度特征,相较于人眼仍然具有较大差距,即并很难检测到人眼注视信息包含的大量高级语义信息,在预测效果的提高上有局限。且不同人的注意力机制存在一定差异,在大部分传统模型中未加入先验信息,处理相对困难。
对于深度学习注意预测算法,卷积神经网络中具有下采样的操作,会逐渐降低特征分辨率,并在此过程中丢失不同尺度包含的特征信息。且深度学习算法在神经网络的设计上针对不同任务需要不断变更,算法较复杂。另外,深度学习模型一般存在可解释性差的共性缺点,且对硬件环境要求较高,效率较低。
对于注意预测的常用评价标准是多方面的。
比如在经典的评价标准中,可用KL距离来度量预测与真实分布的距离,接受者操作特性曲线(ROC曲线)来度量真假阳,将归一化后预测人眼扫描路径与真实路径计算相关系数。
在论文实验常用标准MIT/Tuebingen Saliency Benchmark中,使用IG、AUC、sAUC、NSS、CC、KLDiv、SIM指标评价,从不同维度评价,指标高则代表该方面注意预测能力较强,评价标准详见:MIT/Tuebingen Saliency Benchmark。
在其他方面,可以基于显著点评价,基于区域评价,主观评价等。
本实验以ROS曲线为例,详细介绍一种注意预测的常用评价标准和计算方法。
对于二分类问题,可将样本根据其真实类别与学习器预测类别的组合划分为TP(true positive)、FP(false positive)、TN(true negative)、FN(false negative)四种情况,TP+FP+TN+FN=样本总数,如图2所示:
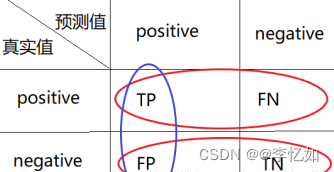
图2 混淆矩阵样本划分
其中,有如下三个定义须知,对应的公式如图3所示:
Ⅰ、真正率 TPR:预测为正例且实际为正例的样本占所有正例样本(真实结果为正样本)的比例。
Ⅱ、假正率 FPR:预测为正例但实际为负例的样本占所有负例样本(真实结果为负样本)的比例。
Ⅲ、特异性(真阴性率)TNR:是指实际为阴性的样本中,判断为阴性的比例。
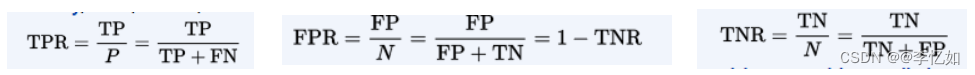
图3 混淆矩阵三大相关公式计算
ROC曲线是对同一信号刺激的反应在几种不同的判定标准下所得的结果,用来度量真阳vs假阳,是一种比较分类模型可视化的工具。其中有如图4其他四种常见评价标准计算方法:

图4 四种常见评价标准的计算方法
根据上述说明及混淆矩阵定义可知,ROC曲线的横坐标和纵坐标是没有相关性的,所以不能把ROC曲线当做一个函数曲线来分析,应该把ROC曲线看成无数个点,每个点代表一个分类器。横坐标为分类器的FPR,纵坐标为分类器的TPR。引入例子如图5所示:
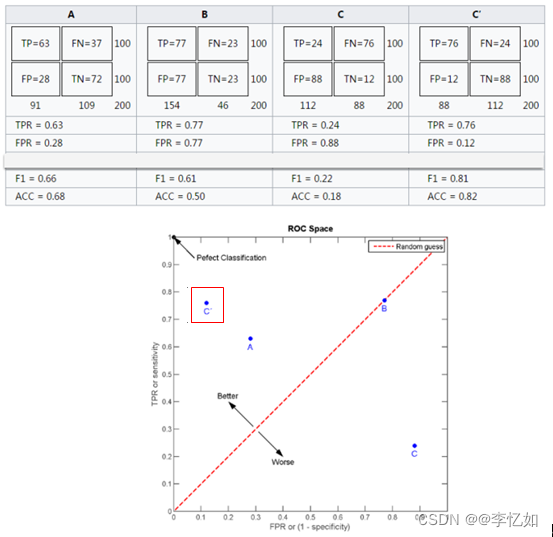
图5 ROC曲线绘制样例
分析:由图5所示,评价分类器好坏只需对比位置与相关参数。样例中C'的性能最好。而B的准确率只有0.5,几乎是随机分类。其中,图中左上角坐标为(1,0)的点为完美分类点(perfect classification),它代表所有的分类全部正确。
补充:实际ROC曲线绘制只需对多个分类器绘图即可。
ROC分类器具体分类标准如图6所示,优点与作用如表1所示:
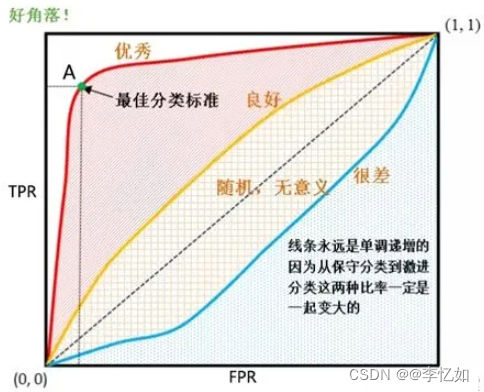
图6 ROC分类标准
表1 ROC曲线优点与作用
| 优点 | 作用 |
| 1.简单、直观 | 1.查出一个分类器在某个阈值时对样本的识别能力 |
| 2.对类分布的改变不敏感 | 2.选择出某一诊断方法最佳的诊断界限值 |
| 3.可延申为其他评价标准 | 3. 比较两种及以上不同诊断方法对疾病的识别能力大小 |
补充: AUC(Area Under Curve)也是注意预测常用评价标准,被定义为ROC曲线下与坐标轴围成的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值。
本部分将使用FES算法进行图像注意区域的预测,相关信息与设置如表2所示:
表2 FES算法相关信息与设置
| 官方数据集 | CAT2000 |
| 相关论文 | |
| 源码地址 | |
| 语言 | Matlab |
注意预测在计算机视觉中获得了大量的关注。在论文中,作者研究了使用中心-周围方法的注意预测,样例如图7所示。提出的方法是基于在贝叶斯框架下估计局部特征对比的显著性。所需的分布特别是使用稀疏抽样和核密度估计来估计。此外,该方法的性质隐含地考虑了文献中所指的中心偏差。
论文的方法在CAT2000上进行了评估,该数据集包含了人类眼睛的固定位置作为地面实况。结果表明,与最先进的方法相比,有5%以上的改进(2011)。此外,该方法足够快,可以实时运行,论文使用FES进行注意预测前后的图像样例如图8所示:

图7 中心-周围方法样例

图8 论文使用FES进行注意预测前后的图像
进入github下载对应项目,该项目包含的文件和目录如表3所示:
表3 FES项目文件目录
| 名称 | 作用 |
| calculateImageSaliency.p | 计算单一比例的图像显著性 |
| calculateFinalSaliency.m | 计算多个比例的图像显著性 |
| runSaliency.m(主文件) | 一个显示如何计算突出性的样本文件 |
| prior.mat | 通过学习获得的先验 |
将项目导入Matlab中,观察并解析代码,总结算法流程如图9:
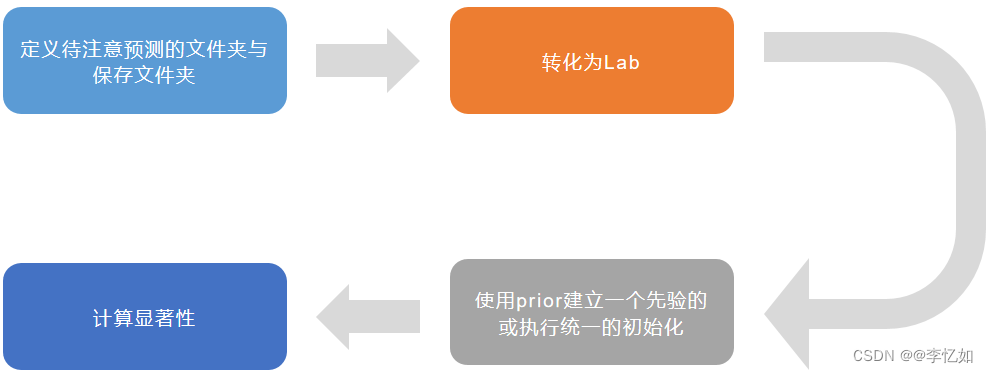
图9 FES在Matlab中的算法流程
按图9中算法流程,先定义好待实验图像文件夹data与保存文件夹result,之后运行runSaliency.m。实验中原图像与预测图像样例如图10所示:

图10 FES注意预测前后图像样例
分析:在MatlabR2020a下运行FES对10张图片进行注意预测,用时3.122s,符合在Fast and Efficient的特点。图10中可见预测效果与原理相符,评价结果在后续详述。
为对FES算法的注意预测效果进行合理评价,本实验使用论文实验常用标准MIT/Tuebingen Saliency Benchmark,FES论文在CAT2000数据集下给出的参考指标如表4所示:
表4 FES参考预测效果指标(CAT2000数据集)
| AUC | sAuc | NSS | CC | KLDiv | SIM |
| 0.8212 | 0.5450 | 1.6103 | 0.5799 | 2.6123 | 0.5255 |
由于评价体系官方依赖库为pysaliency python library,寻找matlab相关依赖无果,故采用网络方法单项实现不同指标对FES的评估,参考文档如下:
①AUS:AUC值计算(matlab) - zhouerba - 博客园 (cnblogs.com)
②sAuc:显著性检测(saliency detection)评价指标之sAUC(shuffled AUC)的Matlab代码实现_a18861227的博客-CSDN博客
③NSS:Matlab显著性检测模型性能度量之NSS_Mr.Q的博客-CSDN博客
④CC:Matlab 显著性检测模型性能度量线性相关系数 CC_Mr.Q的博客-CSDN博客_相关系数cc
⑤KLDiv:KLDIV - File Exchange - MATLAB Central (mathworks.com)
⑥SIM:显著性检测SIM算法--Matlab_matlabsim-图像处理代码类资源-CSDN文库
在将评价标准代码接入matlab中后对于(3)中的样例进行MIT/Tuebingen Saliency Benchmark评价,实验结果与论文结果比较数据如表5所示,效果比较如图11所示:
表5 论文与实验中FES在不同评价标准下的数据汇总

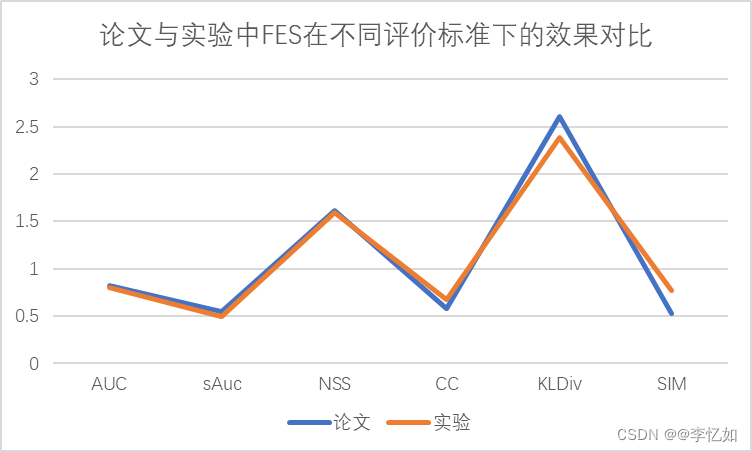
图11 论文与实验中FES在不同评价标准下的效果对比
分析:由表5与图11可见,在AUC、sAUC、NSS、KLDiv四个评价标准下,实验数据略低于论文数据,而在其他两个评价标准下,实验数据略高于论文数据,差异的原因与数据集有一定的联系,总体来说拟合效果较好,FES算法符合论文提出的高效、高评价效果(2011)的特点。
本部分将使用MSI-Net算法进行图像注意区域的预测,相关信息与设置如表6所示:
表6 MSI-Net算法相关信息与设置
| 官方数据集 | MIT300 |
| 相关论文 | |
| 源码地址 | |
| 语言(框架) | Python(tensorflow) |
| 参考文档 |
注意预测任务需要检测场景中存在的物体。为了开发稳健的表征,必须在多个空间尺度上提取高层次的视觉特征,并辅以背景信息。在论文中,作者提出了一种基于卷积神经网络的方法,该网络在大规模的图像分类任务中进行了预训练。该架构形成了一个编码器-解码器结构,如图12所示。并包括一个具有不同扩张率的多个卷积层的模块,以平行捕捉多尺度特征。此外,我们将得到的表征与全局场景信息相结合,以准确预测视觉显著性。
论文的模型在两个公共显著性基准的多个评估指标上取得了有竞争力的一致结果,我们在五个数据集和选定的例子上证明了建议的方法的有效性。与最先进的方法(2020)相比,该网络是基于一个轻量级的图像分类骨干,因此为计算资源有限的应用提供了一个合适的选择,如(虚拟)机器人系统,以估计人类在复杂自然场景中的固定。论文使用MSI-Net进行注意预测前后的图像样例如图13所示:
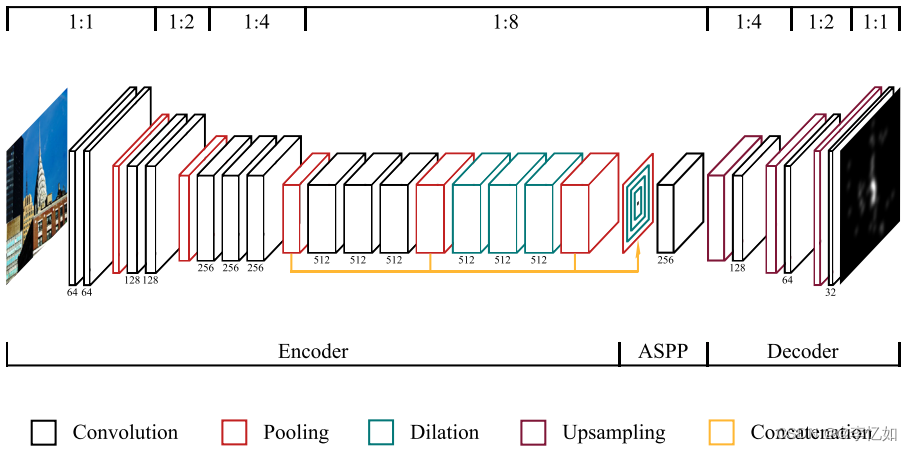
图12 编码器-解码器架构的模块图
补充:如图12所示,VGG16主干被修改以考虑密集预测任务的要求,省略了最后两个最大集合层的特征降采样。然后,多级激活被转发到ASPP模块,该模块在不同的空间尺度上并行地捕获信息。最后,输入的图像尺寸通过解码器网络被恢复。卷积层下面的小写字母表示相应的特征图的数量。

图13 论文使用MSI-Net进行注意预测前后的图像
进入github下载对应项目,该项目包含的文件及核心作用与环境配置如图14所示,将项目导入Pycharm中,观察并解析代码,总结算法流程如图15:
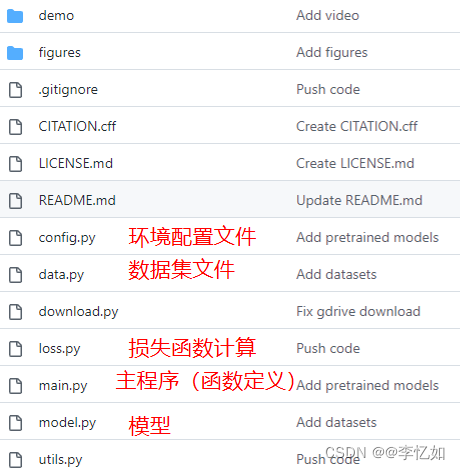

图14 MSI-Net项目文件及核心作用与环境配置

图15 MSI-Net在Pycharm中的算法流程
如图14,安装好对应环境与相关依赖后才可以正常运行项目。在环境搭配于配置过程中遇到了如下几个问题:
Ⅰ、缺少函数问题:在未作版本处理前,本人使用的环境为tensorflow2.10,在运行时会出现缺少函数问题,如图16所示:


图16 运行中的函数缺少问题
Ⅱ、tensorflow降级问题:为解决问题Ⅰ需做降级。由于本人使用的Python为3.8,不支持MSI-Net项目所需的tensorflow1.x版本,故在搜索资料后使用pip install --upgrade https://storage.googleapis.com/tensorflow/mac/cpu/tensorflow-1.14.0-py3-none-any.whl命令降低版本,如图17所示:

图17 tensorflow强制降级
Ⅲ、环境选择问题:在降级后仍然无法成功运行,在查阅github官方文档后发现算法的运行同时提供GPU与CPU的形式运行(其默认为GPU运行),由于本人为tensorflow-cpu,所以需要修改config.py的“device”,如图18所示:
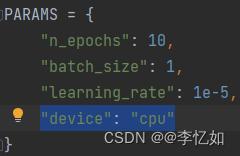
图18 切换算法环境方法
Github中MSI-Net项目默认是使用SALICON数据集,能够自动抓取的数据集有``salicon, mit1003, cat2000, dutomron, pascals, osie, fiwi`。在运行训练代码时会检测数据集是否存在,若不存在会自动下载(本实验选择手动下载导入)。
使用python main.py train命令即可开始训练,默认epoch = 10。
使用③中训练好的模型,或者直接使用(论文)官网中作者中给定的参数进行测试,命令为python main.py test -d DATA -p PATH。其中DATA对应的是用于训练时的数据集,若没有事先训练的话,它会直接从网上下载已经训练好的权重进行评估。而PATH对应的是所要测试的图片地址,可以是多张图片也可以是单张图片。最后训练得到的结果会放在 results/images/中。
实验中原图像与预测图像样例如图19所示:

图19 MSI-Net注意预测前后图像样例
分析:在Pycharm2021下运行MSI-Net对10张图片进行注意预测,用时4.712s(测试时间)。图19中可见预测效果与原理相符,评价结果在后续详述。
为对MSI-Net算法的注意预测效果进行合理评价,本实验使用论文实验常用标准MIT/Tuebingen Saliency Benchmark,MSI-Net论文在MIT300数据集下给出的参考指标如表7所示:
表7 MSI-Net参考预测效果指标(MIT300数据集)
| IG | AUC | sAuc | NSS | CC | KLDiv | SIM |
| 0.9185 | 0.8738 | 0.7787 | 2.3053 | 0.7790 | 0.4232 | 0.6704 |
评价体系官方依赖库为pysaliency python library,所以Python可以直接使用相关依赖,有如下两种使用途径
Ⅰ、直接利用源代码进行注意预测评价:首先可以直接在github相关源上下载https://github.com/matthias-k/saliency-benchmarking,然后进行评估。
Ⅱ、直接使用pysaliency库:利用pip工具进行安装库,根据官方文档与参考文档进行代码编写,如图20所示:
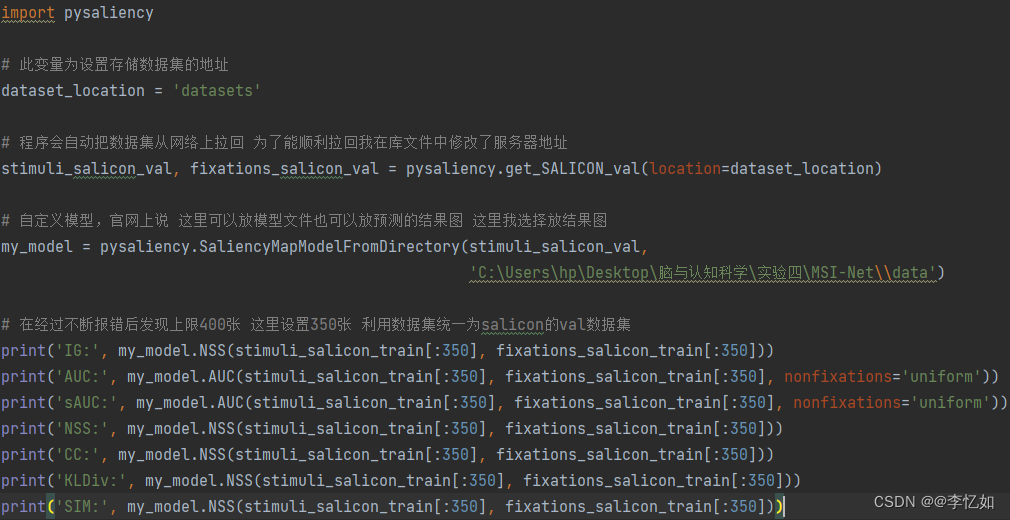
图20 使用pysaliency库实现评价标准
在将评价标准代码接入Pycharm中后对于(3)中的样例进行MIT/Tuebingen Saliency Benchmark评价,实验结果与论文结果比较数据如表8所示,效果比较如图21所示:
表8 论文与实验中MSI-Net在不同评价标准下的数据汇总

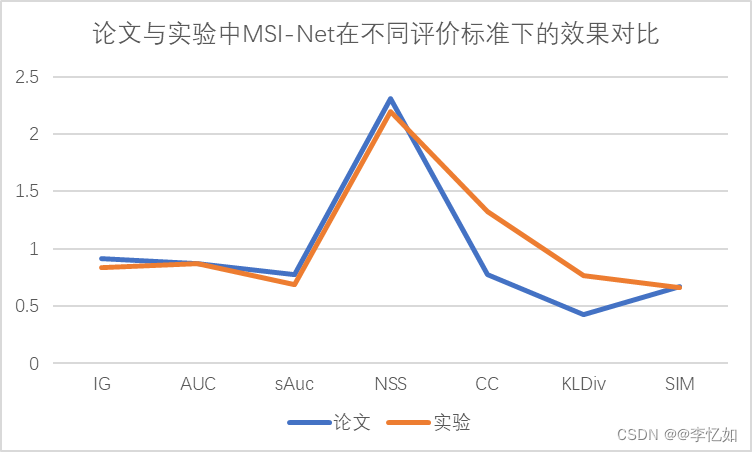
图21 论文与实验中MSI-Net在不同评价标准下的效果对比
分析:由表8与图21可见,在IG、AUC、sAUC、NSS、SIM五个评价标准下,实验数据略低于论文数据,而在其他两个评价标准下,实验数据略高于论文数据,差异的原因与数据集有一定的联系,总体来说拟合效果较好,MSI-Net算法符合论文提出的轻量化、高评价效果(2020)的特点。
除了上文提到的github项目与代码外,还有一些线上平台与集成软件可以较方便地完成注意预测,本部分将会稍作介绍。
DeepGaze为注意预测系列算法,包含DeepGaze I, DeepGaze II, DeepGaze IIE and DeepGaze III四种,在注意预测多种评价标准下至今仍处领先地位,相关信息如表8:
表8 DeepGaze算法相关信息与设置
| 官方数据集 | MIT300与CAT2000 |
| 相关论文 | 多篇 |
| 源码地址 | GitHub - matthias-k/DeepGaze: pytorch implementation of the different DeepGaze models |
| 语言(框架) | Python(pytorch) |
其中,DeepGaze II制作了在线平台供用户进行注意预测,地址如下:Index - DeepGaze II (bethgelab.org),进入平台,点击“submit an image”按钮进入选择图片界面,有以下两种设置,如图22所示:
DeepGaze II在线平台提供了两种模型,分别是Use the DeepGaze II model和Use the ICF (Intensity Contrast Features) model。
DeepGaze II在线平台提供了两种中心偏置设置,分别是Use no centerbias (i.e. use a uniform distribution as prior)和Use the centerbias from the MIT1003 dataset。
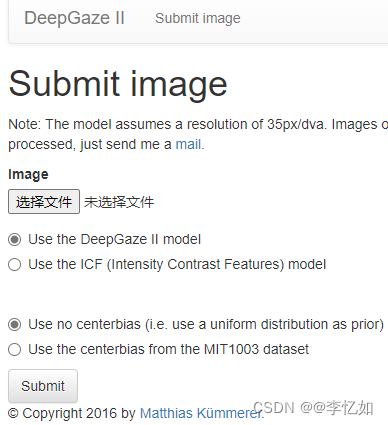
图22 DeepGaze II在线平台图片提交设置
使用DeepGaze II在线平台进行注意预测,原图像与预测图像样例如图23所示(以DeepGaze II模型、使用MIT1003数据集的中心偏置为例):

图23 DeepGaze II注意预测前后图像样例
补充:DeepGaze II在线平台未给出评价方法,故在此对效果不做评价。
AttentionInsight为注意预测的一种算法,开发了集成软件(demo版),地址如下:Attention Insight Heatmaps | AI-Driven Pre-Launch Analytics,样例注意预测如图24所示:
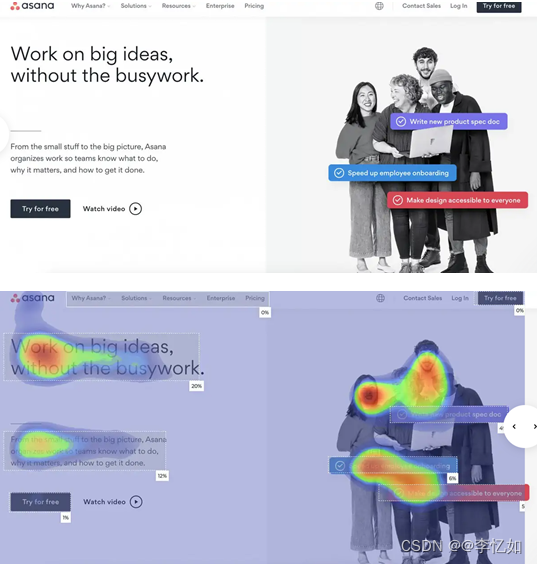
图24 AttentionInsight注意预测前后图像样例
为探究不同算法注意预测产生的图像区别,分别将上文中算法产生的图像汇总对比,样例如图25所示:

图25 不同算法与模型注意预测前后图像样例
分析:由于不同算法与模型使用的标准不同,设计流程不同,产生结果自然不同。
1.刘瑞航.视觉显著性预测方法研究.2022.中国矿业大学,MA thesis.
2.孙夏,and 石志儒."视觉显著性预测综述." 电子设计工程 25.09(2017):189-193. doi:10.14022/j.cnki.dzsjgc.2017.09.047.
3.脑与认知实验:图像中的注意区域预测_Asionm的博客-CSDN博客
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我有带有Logo图像的公司模型has_attached_file:logo我用他们的Logo创建了许多公司。现在,我需要添加新样式has_attached_file:logo,:styles=>{:small=>"30x15>",:medium=>"155x85>"}我是否应该重新上传所有旧数据以重新生成新样式?我不这么认为……或者有什么rake任务可以重新生成样式吗? 最佳答案 参见Thumbnail-Generation.如果rake任务不适合你,你应该能够在控制台中使用一个片段来调用重新处理!关于相关公司
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
我正在尝试使用Ruby2.0.0和Rails4.0.0提供的API从imgur中提取图像。我已尝试按照Ruby2.0.0文档中列出的各种方式构建http请求,但均无济于事。代码如下:require'net/http'require'net/https'defimgurheaders={"Authorization"=>"Client-ID"+my_client_id}path="/3/gallery/image/#{img_id}.json"uri=URI("https://api.imgur.com"+path)request,data=Net::HTTP::Get.new(path
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
有这样的事吗?我想在Ruby程序中使用它。 最佳答案 试试这个http://csl.sublevel3.org/jp2a/此外,Imagemagick可能还有一些东西 关于ruby-是否有将图像文件转换为ASCII艺术的命令行程序或库?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/6510445/
我正在使用Dragonfly在Rails3.1应用程序上处理图像。我正在努力通过url将图像分配给模型。我有一个很好的表格:{:multipart=>true}do|f|%>RemovePicture?Dragonfly的文档指出:Dragonfly提供了一个直接从url分配的访问器:@album.cover_image_url='http://some.url/file.jpg'但是当我在控制台中尝试时:=>#ruby-1.9.2-p290>picture.image_url="http://i.imgur.com/QQiMz.jpg"=>"http://i.imgur.com/QQ