目录
不知道大家有没有注意到,我们的「评论发红包」功能已经上线啦~ 现在几乎所有的内容 -- 博客,社区帖子,立Flag,直播,课程,blink, 等,都可以在评论区发红包了。 红包的内容通过审核后,就会出现在全站红包流里。
大家在抢红包的同时, 就会更关心你的内容,如果抢红包成功,就会成为你的粉丝,你可以在这里看到你的粉丝是怎么来的。
下面,我们以博客为例,说明一下具体操作。
在博客详情页,只要点击「评论图标」,即可在评论中发布红包了哦,当然也可在评论中领取别人发的红包!当然呢,该功能也有发布规则以及领取规则,也有发布红包评论的好处,具体请往下翻⬇️
领取用户如是 CSDN 任一种会员,原力等级 > 1,且在过去 1 天有参与学习,可正常参与拼手气红包的随机金额领取;
领取用户如是 CSDN 任一会员,原力等级 > 1,但在过去 1 天没有参与学习,仅可领取 0.01 元红包;
领取用户如不是 CSDN 任一种会员,且原力等级≤ 1 的用户,仅可领取 0.01 元红包;
领取用户在领取红包同时,会自动关注发红包用户和当前博主
领取用户领到的红包金额,会放入 CSDN 钱包,领取后可点击查看。
红包领取后进入余额,余额不支持提现,仅限于CSDN平台使用。
博客发评论红包的步骤:打开博文并点击评论--评论框找到对应的红包标识--填写红包相关信息--发放红包,具体参考下图:
步骤一:打开博文并点击评论,在评论框找到对应的红包标识
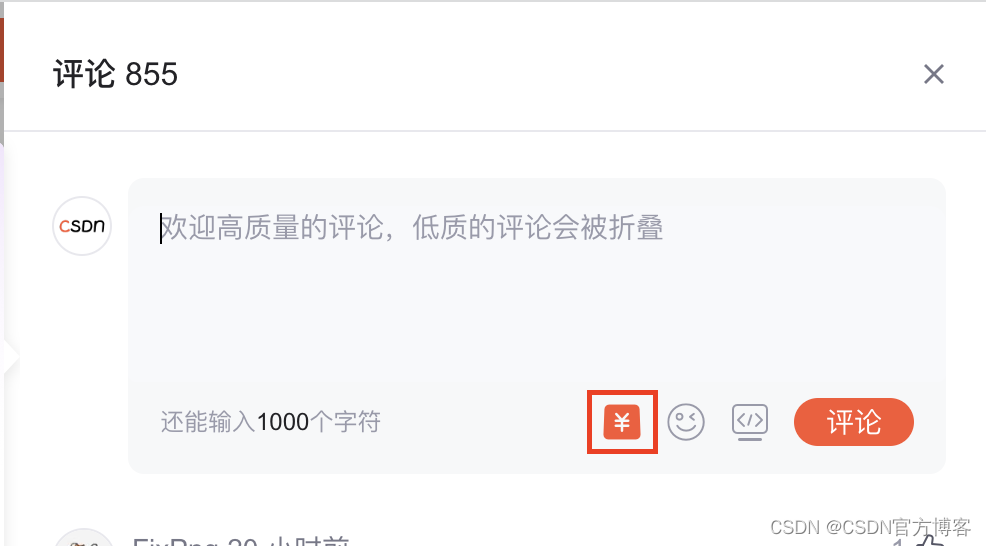
步骤二:填写红包相关信息--发放红包

步骤三:评论审核通过后即发放成功

社区帖子,课程,blink 都可以发评论红包啦, 操作方法同上哦。
发布评论红包的好处主要是博文引流和推荐优质博文,让你的优质博文更大限度的去被发现,同时也可增加博主与粉丝之间的互动,增加粉丝的粘性。当然你也可以为自己发现的其他博主写的优质博文发布评论红包,从而推荐给更多人看到。具体表现如下:

大家如果对博客「评论发红包」功能有更好的建议或者意见可以在本文下方留言,我们会认真吸取大家的建议和意见哦~
我需要读入一个包含数字列表的文件。此代码读取文件并将其放入二维数组中。现在我需要获取数组中所有数字的平均值,但我需要将数组的内容更改为int。有什么想法可以将to_i方法放在哪里吗?ClassTerraindefinitializefile_name@input=IO.readlines(file_name)#readinfile@size=@input[0].to_i@land=[@size]x=1whilex 最佳答案 只需将数组映射为整数:@land边注如果你想得到一条线的平均值,你可以这样做:values=@input[x]
这个问题在这里已经有了答案:Checktoseeifanarrayisalreadysorted?(8个答案)关闭9年前。我只是想知道是否有办法检查数组是否在增加?这是我的解决方案,但我正在寻找更漂亮的方法:n=-1@arr.flatten.each{|e|returnfalseife
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
我使用的是Firefox版本36.0.1和Selenium-Webdrivergem版本2.45.0。我能够创建Firefox实例,但无法使用脚本继续进行进一步的操作无法在60秒内获得稳定的Firefox连接(127.0.0.1:7055)错误。有人能帮帮我吗? 最佳答案 我遇到了同样的问题。降级到firefoxv33后一切正常。您可以找到旧版本here 关于ruby-无法在60秒内获得稳定的Firefox连接(127.0.0.1:7055),我们在StackOverflow上找到一个类
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我正在尝试提取方括号内的内容。到目前为止,我一直在使用它,它有效,但我想知道我是否可以直接在正则表达式中使用某些东西,而不是使用这个删除功能。a="Thisissuchagreatday[coolawesome]"a[/\[.*?\]/].delete('[]')#=>"coolawesome" 最佳答案 差不多。a="Thisissuchagreatday[coolawesome]"a[/\[(.*?)\]/,1]#=>"coolawesome"a[/(?"coolawesome"第一个依赖于提取组而不是完全匹配;第二个利用前瞻和
在Rails自动生成的功能测试(test/functional/products_controller_test.rb)中,我看到以下代码:classProductsControllerTest我的问题是:方法调用products()在哪里/如何定义?products(:one)到底是什么意思?看代码,大概意思是“创建一个产品”,但是它是如何工作的呢?注意我是Ruby/Rails的新手,如果这些是微不足道的问题,我深表歉意。 最佳答案 如果您查看test/fixtures文件夹,您会看到一个products.yml文件。这是在您创建
使用Ruby1.8.6/Rails2.3.2我注意到在我的任何ActiveRecord模型类上调用的任何方法都返回nil而不是NoMethodError。除了烦人之外,这还破坏了动态查找器(find_by_name、find_by_id等),因为即使存在记录,它们也总是返回nil。不从ActiveRecord::Base派生的标准类不受影响。有没有办法追踪在ActiveRecord::Base之前拦截method_missing的是什么?更新:切换到1.8.7后,我发现(感谢@MichaelKohl)will_paginate插件首先处理method_missing。但是will_pa