1.Kafka 副本作用:提高数据可靠性。
2.Kafka 中副本分为:Leader 和 Follower。Kafka 生产者只会把数据发往 Leader, 然后 Follower 找 Leader 进行同步数据。
读写由leader来完成,follower只备份,和leader同步数据,leader发生故障,follower顶上去。
leader副本:可以理解为某个分区中,除了不是副本的那个分区。
3.Kafka 分区中的所有副本统称为 AR(Assigned Repllicas)。
AR = ISR + OSR
4.ISR:表示和 Leader 保持同步的 Follower 集合。如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值由 replica.lag.time.max.ms参数设定,默认 30s。Leader 发生故障之后,就会从 ISR 中选举新的 Leader。
5.OSR:表示 Follower 与 Leader 副本同步时,超时的副本集合。
假设创建4个节点,5个分区,2个副本,那么分区,副本的关系,如下图所示:
root@VM_15_71_centos kafka_2.11-1.0.0]# bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test-part
[2019-06-28 01:23:50,646] INFO Accepted socket connection from /127.0.0.1:41204 (org.apache.zookeeper.server.NIOServerCnxnFactory)
[2019-06-28 01:23:50,646] INFO Client attempting to establish new session at /127.0.0.1:41204 (org.apache.zookeeper.server.ZooKeeperServer)
[2019-06-28 01:23:50,649] INFO Established session 0x16b99ec1ce1000c with negotiated timeout 30000 for client /127.0.0.1:41204 (org.apache.zookeeper.server.ZooKeeperServer)
Topic:test-part PartitionCount:5 ReplicationFactor:2 Configs:
Topic: test-part Partition: 0 Leader: 0 Replicas: 0,2 Isr: 0,2
Topic: test-part Partition: 1 Leader: 1 Replicas: 1,3 Isr: 1,3
Topic: test-part Partition: 2 Leader: 2 Replicas: 2,0 Isr: 2,0
Topic: test-part Partition: 3 Leader: 3 Replicas: 3,1 Isr: 3,1
Topic: test-part Partition: 4 Leader: 0 Replicas: 0,3 Isr: 0,3
[2019-06-28 01:23:50,899] INFO Processed session termination for sessionid: 0x16b99ec1ce1000c (org.apache.zookeeper.server.PrepRequestProcessor)
[2019-06-28 01:23:50,904] INFO Closed socket connection for client /127.0.0.1:41204 which had sessionid 0x16b99ec1ce1000c (org.apache.zookeeper.server.NIOServerCnxn)通过以上信息我们可以分析得出:
1.opic:test-part PartitionCount:5 ReplicationFactor:2 Configs:
一个主题: test-part, 5个分区,2个副本。
2.Partition这一列竖着看,【0,1,2,3,4】共5个分区。
3.Replicas 这一列竖着看,将所有boker的id去重后【[0,2],[1,3],[2,0],[3,1],[0,3]】,得到的集合个数为节点的数目【0,1,2,3】
4.Replicas 这一列,选择任意一行横着看,boker的id的集合大小为,副本的个数,如【0,2】副本数为2。
梳理存储分布图:

按照:在 isr中存活为前提,按照 AR中排在前面的优先顺序,比如

2.查看 Leader 分布情况
 3.停止掉 hadoop105 的 kafka 进程,并查看 Leader 分区情况
3.停止掉 hadoop105 的 kafka 进程,并查看 Leader 分区情况

可以看到按照AR中的顺序,3021中3挂掉,0成为主节点。
1.LEO和HW
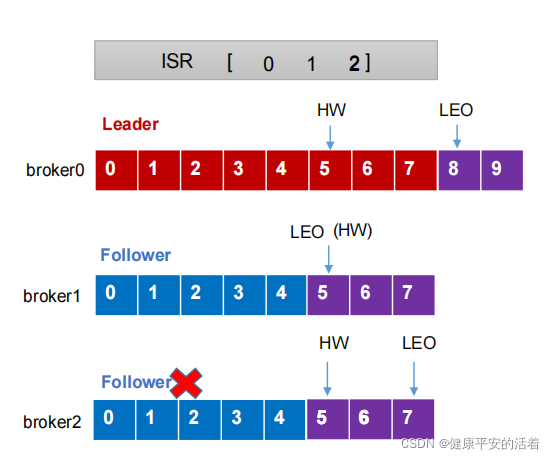
2.流程
1.Follower发生故障后会被临时踢出ISR
2.这个期间Leader和Follower继续接收数据(不管follower是否还能接收到,二者还是在通信同步数据)
3.待该Follower恢复后,Follower会读取本地磁盘记录的上次的HW,并将log文件高于HW的部分截取掉,从HW开始向Leader进行同步。
4.等该Follower的LEO大于等于该Partition的HW,即Follower追上Leader之后,就可以重新加入ISR了。
1.LEO和HW
2.流程

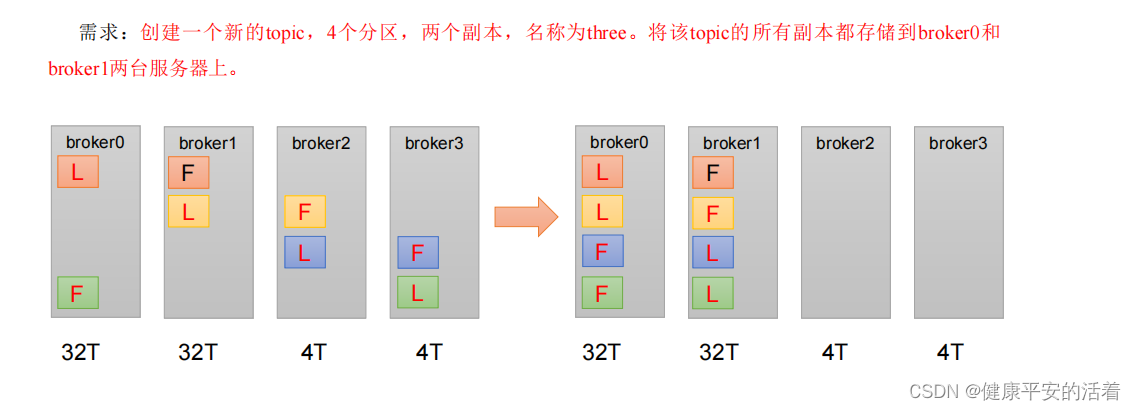

2.查看分区副本存储情况。

3. 创建副本存储计划(所有副本都指定存储在 broker0、broker1 中)。

4.执行副本存储计划。

5.验证副本存储计划。
 6.查看分区副本存储情况
6.查看分区副本存储情况


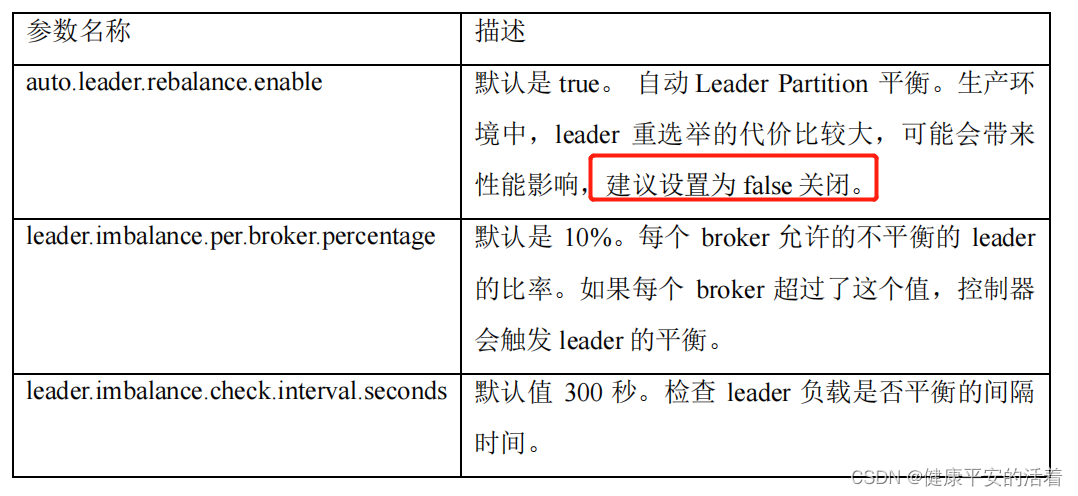
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
rpartition和partition有什么区别?我已经阅读了文档,但我认为它们是一样的。只是那些出现在后来的ruby版本中吗? 最佳答案 以下示例将有助于识别差异:"abccba".partition("b")#=>["a","b","ccba"]"abccba".rpartition("b")#=>["abcc","b","a"]所以区别在于rpartition搜索最右边的匹配项,而不是最左边的匹配项。 关于Rubyrpartition与分区?,我们在StackOverflow
我的问题的一个例子是体育游戏。一场体育比赛有两支球队,一支主队和一支客队。我的事件记录模型如下:classTeam"Team"has_one:away_team,:class_name=>"Team"end我希望能够通过游戏访问一个团队,例如:Game.find(1).home_team但我收到一个单元化常量错误:Game::team。谁能告诉我我做错了什么?谢谢, 最佳答案 如果Gamehas_one:team那么Rails假设您的teams表有一个game_id列。不过,您想要的是games表有一个team_id列,在这种情况下
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
📢博客主页:https://blog.csdn.net/weixin_43197380📢欢迎点赞👍收藏⭐留言📝如有错误敬请指正!📢本文由Loewen丶原创,首发于CSDN,转载注明出处🙉📢现在的付出,都会是一种沉淀,只为让你成为更好的人✨文章预览:一.分辨率(Resolution)1、工业相机的分辨率是如何定义的?2、工业相机的分辨率是如何选择的?二.精度(Accuracy)1、像素精度(PixelAccuracy)2、定位精度和重复定位精度(RepeatPrecision)三.公差(Tolerance)四.课后作业(Post-ClassExercises)视觉行业的初学者,甚至是做了1~2年
我想合并多个事件记录关系例如,apple_companies=Company.where("namelike?","%apple%")banana_companies=Company.where("namelike?","%banana%")我想结合这两个关系。不是合并,合并是apple_companies.merge(banana_companies)=>Company.where("namelike?andnamelike?","%apple%","%banana%")我要Company.where("名字像?还是名字像?","%apple%","%banana%")之后,我会写代
我的ruby脚本从命令行参数获取某些输入。它检查是否缺少任何命令行参数,然后提示用户输入。但是我无法使用gets从用户那里获得输入。示例代码:test.rbname=""ARGV.eachdo|a|ifa.include?('-n')name=aputs"Argument:#{a}"endendifname==""puts"entername:"name=getsputsnameend运行脚本:rubytest.rbraghav-k错误结果:test.rb:6:in`gets':Nosuchfileordirectory-raghav-k(Errno::ENOENT)fromtes
我有一个简单的问题,与关联有关。我有一个书的模型,它有_onereservation。预订属于_书本。我想在预订Controller的创建方法中确保在预订时没有预订一本书。换句话说,我需要检查该书是否存在任何其他预订。我该怎么做?编辑:Aaa我做到了,感谢大家的提示,学到了一些新东西。当我尝试提供的解决方案时,出现no_method错误或nil_class等。这让我开始思考,我尝试处理的对象根本不存在。Krule给了我使用book.find的想法,所以我尝试使用它。最终我得到了它的工作:book=Book.find_by_id(reservation_params[:book_id])
文章目录一基础定义二创建逻辑卷2-1准备物理设备2-2创建物理卷2-3创建卷组2-4创建逻辑卷2-5创建文件系统并挂载文件三扩展卷组和缩减卷组3-1准备物理设备3-2创建物理卷3-3扩展卷组3-4查看卷组的详细信息以验证3-5缩减卷组四扩展逻辑卷4-1检查卷组是否有可用的空间4-2扩展逻辑卷4-3扩展文件系统五删除逻辑卷5-1备份数据5-2卸载文件系统5-3删除逻辑卷5-4删除卷组5-5删除物理卷六LVM逻辑卷缩容6-1缩容注意事项6-2标准缩容步骤一基础定义LVM,LogicalVolumeManger,逻辑卷管理,Linux磁盘分区管理的一种机制,建立在硬盘和分区上的一个逻辑层,提高磁盘分