

ZooKeeper 是分布式应用程序的分布式开源协调服务;它公开了一组简单的原语,分布式应用程序可以基于这些原语来实现更高级别的同步、配置维护以及组和命名服务;数据模型是以熟悉的文件系统目录结构为导向的
ZooKeeper 官网:https://zookeeper.apache.org/doc/current/zookeeperOver.html
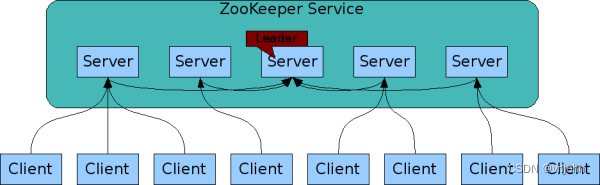
very simple,通过共享的命名空间相互协调,该命名空间的组织类似于标准文件系统;ZK 数据保存在内存中,这意味着 ZK 可以实现高吞吐量和低延迟读取比写入表现最佳,比率约为 10:1,读取多于写入的应用程序中具有特别高的性能,因为写入涉及到需要同步所有服务器状态(读取多于写入通常是协调服务的情况)
①跟随者的失败和恢复、②不同 follower 的故障和恢复、③领导者的失败、④两个 follower 的故障和恢复、⑤另一个领导者的失败
摘自官网的这张图中,有一些重要的观察结果。首先,如果跟随者失败并快速恢复,那么即使出现故障,ZooKeeper 也能够维持高吞吐量。但也许更重要的是,领导者选举算法允许系统足够快地恢复以防止吞吐量大幅下降。在我们的观察中,ZooKeeper
花费不到 200 毫秒的时间来选举一个新的领导者。其次,随着追随者的恢复,一旦他们开始处理请求,ZooKeeper 能够再次提高吞吐量

在 ZK 集群正常运作时,由客户端发起写请求,若请求的节点为 Follow 节点,那么它还会转发给到 Leader,由 Leader 节点去完成这部分写操作;若为读请求,在 Follow 节点这一侧直接读取即可.
既然是集群了,总归是会有网络不稳定或资源不足的情况导致节点宕机,在故障恢复的这一阶段,其他请求的服务都是 不可用状态,而 ZK 作为分布式协调服务组件,它必然会有可靠的方式去保证集群可用态
在 ZK 内部基于 Paxos 一致性算法,通过 ZAB(ZooKeeper Atomic Broadcast)->ZK 原子广播协议来恢复集群为可用状态;它有两种基本模式,如下:
1、崩溃恢复,Leader 出现网络中断、崩溃重启等异常情况下,ZAB 协议就会进行到恢复模式,来重新选举一个新的 Leader 服务来处理事务请求,当新的 Leader 服务器选择出来以后,并且和过半以上的机器进行了状态同步以后,恢复模式就结束了。在选举时,会有如下过程:3888 端口形成 一对一 通信、任何人投票,都会触发准 Leader 发起自己的投票、推选机制:先比较节点内部的 Zxid,若 Zxid 相同,就选取那个 myid 值最大的节点作为 Leader2、消息广播,消息广播使用的是一个原子广播协议,整体的过程可以看作是一个二阶段提交的过程.
第一阶段,Leader 机器会将事务消息生成对应的proposal(提案)广播,并且会生成一个单调递增的 ID,作为事务的 ID(Zxid),由于 ZAB 协议需要保证事务严格的上下顺序性,所以会严格按照 Zxid 的先后来处理对应的消息;在消息广播发起后,Leader 会为每一个 Follower 服务器分配一个单独的队列,然后将需要广播出去的事务Proposal依次存放进这个 FIFO 队列中,每个 Follower 机器收到事务消息后,会按照事务日志的方式写入,成功反馈给 Leader 服务器 Ack 响应,当收到半数以上的 Ack 响应后,Leader 就会发起第二阶段的 Commit 消息给所有的 Follower 机器,并且这个时候 Leader 也会和 Follower 一样进行本地事务的提交操作,完成整个消息的传递和提交
推荐一篇文章,使用总统选举的例子,来简要描述 ZK 服务中的一些概念模型,Zookeeper全解析——Paxos作为灵魂
ZooKeeper 提供的命名空间很像标准文件系统中的命名空间,名称是由斜杠 (/) 分隔开的一系列路径元素,ZooKeeper 命名空间中的每个节点都有路径去标识,每个节点最大存储数据大小为 1MB
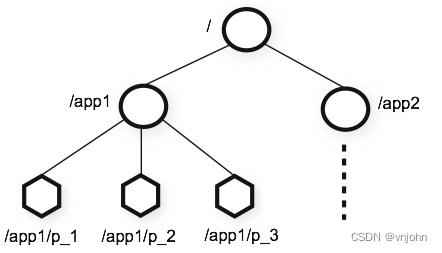
ZooKeeper 命名空间中的每个节点都可以拥有与其关联的数据以及子节点,使用术语 znode 来明确 ZooKeeper 的数据节点
节点存在以下几种类型
(ephemeral),通过它来创建客户端节点的 session,处于活动状态,znode 存在;当会话结束以后,znode 就会被删除-s 创建完的节点会按序列增长 00000000节点存在以下的特征及使用:
Server Id:服务器 id,它是每个服务节点的唯一标识
比如有三台服务节点,编号分别是 1、2、3,编号越大的服务权重就越大,在初始化启动时就是根据服务器 id 来进行比较的,较小的编号会变更选票偏向于编号大的,当对应的编号获得集群中过半数选票,那么此编号标识的服务就是 Leader
ZooKeeper transaction:事务id
服务中存放的事务 id 越大代表它的数据越新,即代表它的权重就越大,在重新选举时通过 Zxid 值比较,谁大谁当主
Looking:竞选状态
Following:随从状态,同步 Leader 状态,参与选票
Observing:观察状态,同步 Leader 状态,不参与选票
Leading:领导者状态
ZooKeeper 非常快速且非常简单,但是,由于它的目标是成为构建更复杂服务(例如同步)的基础,因此它提供了一组保证,如下:
基于该文章搭建好多台虚拟机节点:Mac M1 搭建虚拟机节点集群过程及软件分享
前置环境要求:Jdk 1.8,之前在搭建 Nacos 集群有具体描述:Nacos 介绍及搭建集群、相关组件
那么接下来就是如何搭建好一个 ZooKeeper 集群,准备好四台虚拟机节点,172.16.249.10-172.16.249.13(node1-node4)
zookeeper-tar.gz 下载:https://archive.apache.org/dist/zookeeper/zookeeper-3.4.6/
前置工作,先为每台机器节点配置域名,实现节点之间通过域名方式绑定
172.16.249.10 node1
172.16.249.11 node2
172.16.249.12 node3
172.16.249.13 node4
上传 zookeeper-release-3.4.6.tar.gz 文件到服务器中
1、解压 tar.gz:tar xf zookeeper-3.4.6.tar.gz
2、将文件拷贝到指定目录下:mv -p zookeeper-3.4.6 /opt/vnjohn/zk
3、备份配置文件:cd conf/ && cp zoo_sample.cfg zoo.cfg
4、调整 zoo.cfg 配置文件
# 指定数据目录
dataDir=/var/vnjohn/zk
# 绑定 Server Id、节点 | 端口 关系
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
server.4=node4:2888:3888
5、创建目录&设置节点的 Servcer Id 值,每个节点要设置的值不一样
# node1
mkdir -p /var/vnjohn/zk && touch /var/vnjohn/zk/myid && echo 1 > /var/vnjohn/zk/myid
# node2
mkdir -p /var/vnjohn/zk && touch /var/vnjohn/zk/myid && echo 2 > /var/vnjohn/zk/myid
# node3
mkdir -p /var/vnjohn/zk && touch /var/vnjohn/zk/myid && echo 3 > /var/vnjohn/zk/myid
# node4
mkdir -p /var/vnjohn/zk && touch /var/vnjohn/zk/myid && echo 4 > /var/vnjohn/zk/myid
6、由于每台节点的配置信息基本上都是一致的,除了 myid 文件内容需要保持不同而已,所以直接通过SFTP 方式传递到其他节点->node2~node4,目录保持和 node1 一样,再根据第 5 点设置 Server Id 值即可.
7、调整 /etc/profile 配置文件内容,追加内容如下:
ZOOKEEPER_HOME=/opt/vnjohn/zk
export PATH=$PATH:$ZOOKEEPER_HOME/bin
刷新配置文件:source /etc/profile
若配置文件修改出现问题,导致所有命令都不生效了,运行✅:export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin 后,再重新调整配置
8、启动 ZK,后台运行命令【zkServer.sh start】,先通过前台运行观察控制台打印的日志【zkServer.sh start-foreground】,如下:
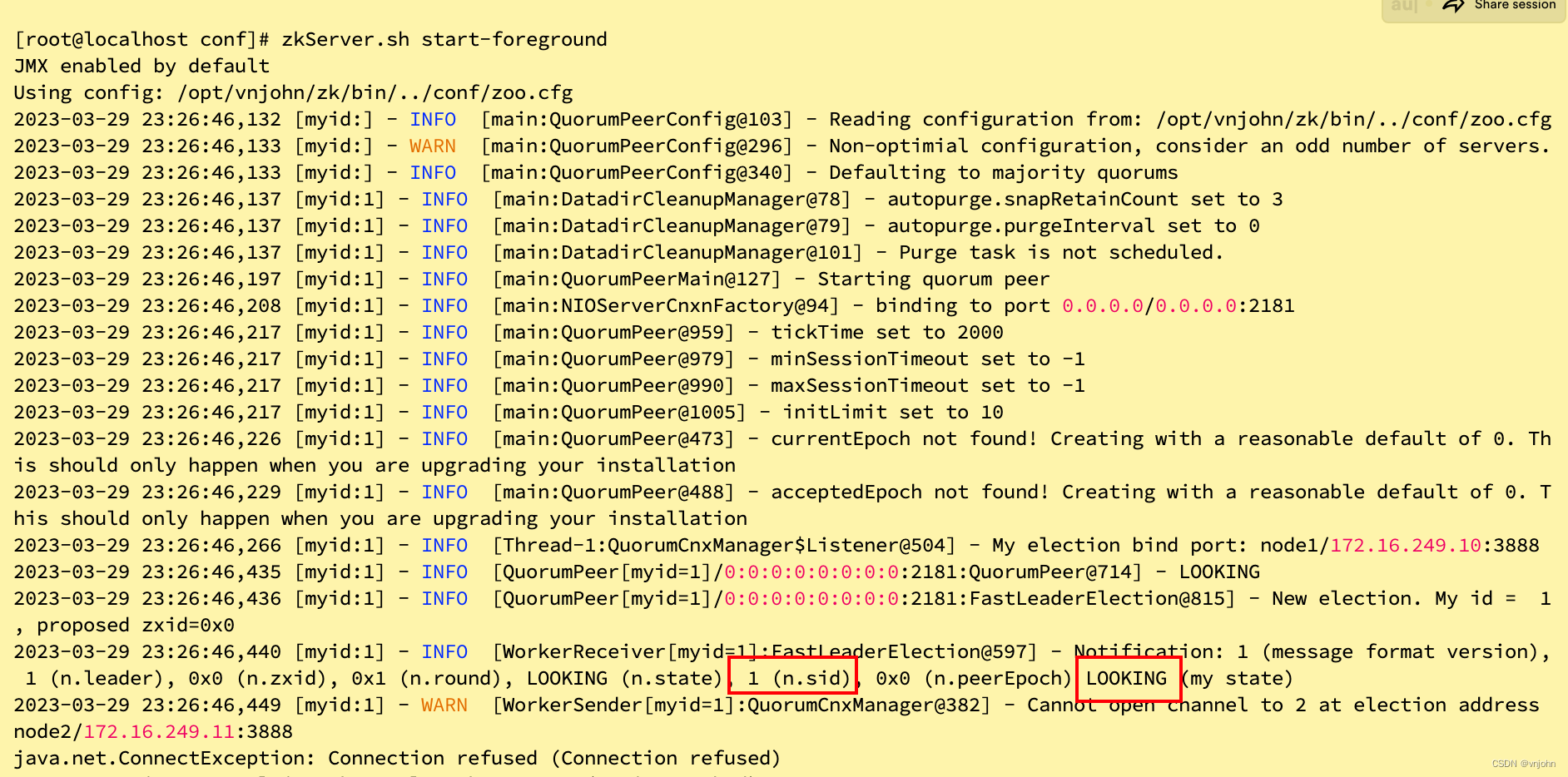
刚启动的节点目前还是一个竞选 LOOKING 状态,通过 zkServer.sh status 命令可以查看 ZK 节点的状态,输出的日志内容告知它并未在运行【其实也说明它目前所在的选举状态:LOOKING】
[root@localhost ~]# zkServer.sh status
JMX enabled by default
Using config: /opt/vnjohn/zk/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
当 node2、node3 起来以后,node2 角色是 follow,而 node-3 角色必然就是 leader,初始化启动主要通过 myid【Service id】最大值对比,最大值的那个节点作为 Leader 节点,观察 node3 节点最后的输出日志
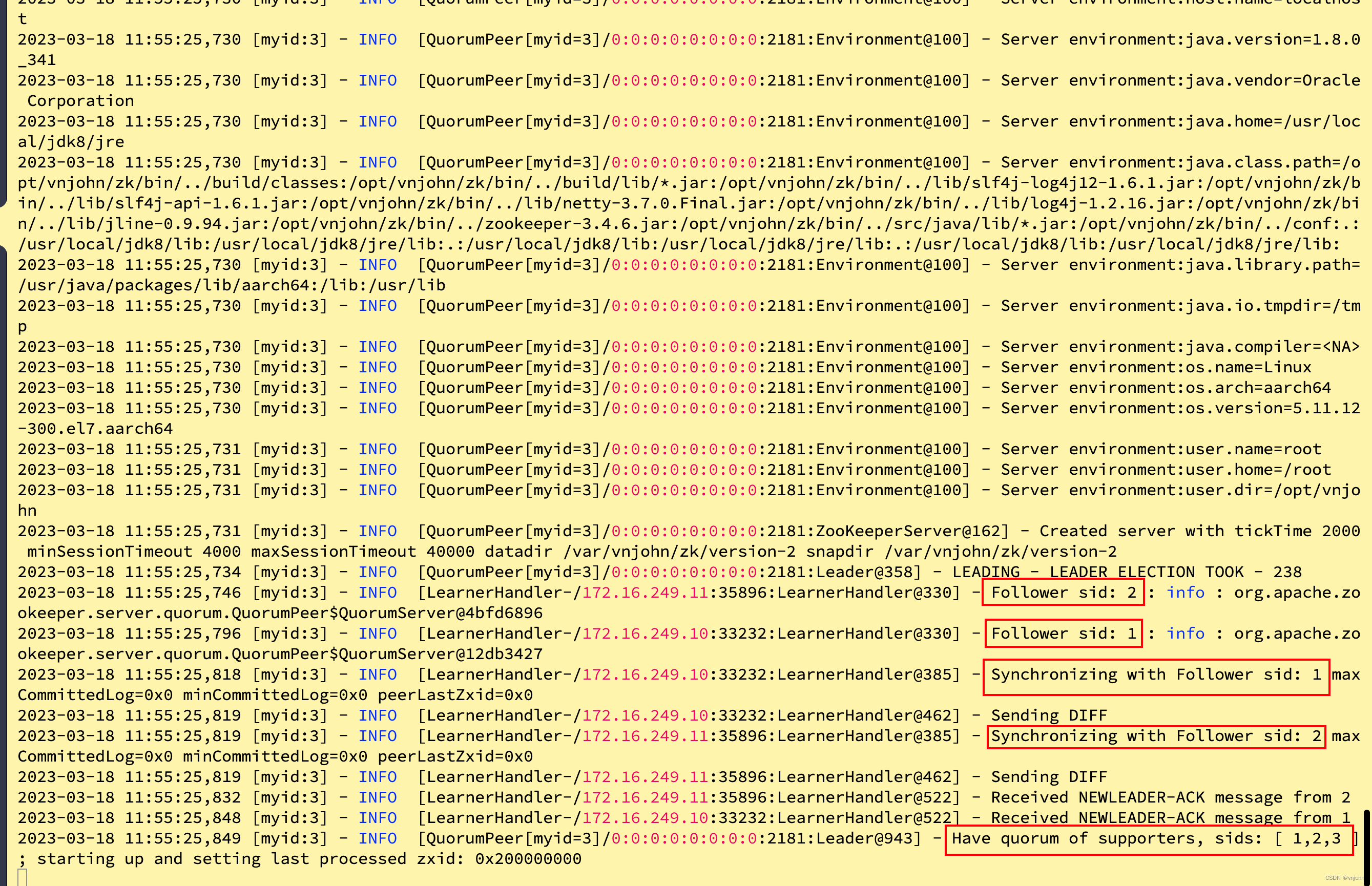
选举完成、同步数据给 Follower、收到 ack 响应
若 node4 此时再启动,那么它仍然会变为 node3 跟随者,随即 Leader 也会给它同步一份最新的数据样本
9、查看 node4->2888/3888 端口 TCP 连接信息

从图中可以观察到一些信息,node4 与 node1、2、3 的 3888 端口建立了连接,它们之间的通信是为了选举投票用的;但唯独与 node3 节点 2888 端口建立了连接,它的作用是:当 node4->follower 接到 write 写请求时,通过该端口转发数据包给 Leader 去处理
# leader 和 follow 每个连接心跳的毫秒数
tickTime=2000
# 当有新的 follow 节点追随 leader 时,可以被允许 10*2000 20秒时间等待连接
initLimit=10
# leader 同步数据给 follow 时,5*2000 10秒没有获得回复也认为 follow 有问题
syncLimit=5
# 持久化目录
dataDir=/var/vnjohn/zookeeper
# 客户端连接的端口号
clientPort=2181
# 允许客户端最大连接数量,可以调大
# maxClientCnxns=60
# 3888 用处:当主挂了以后,这个时候就需要去投票选举,用这个端口
# 2888 用处:当主选好以后,就用这个端口 Leader 节点做通信
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
server.4=node4:2888:3888
ZK 集群搭建好了,现在我们就可以基于它自带的客户端进行连接,去进行一些实际的命令操作!
1、进入控制台,输入:zkCli.sh 后回车即可
2、创建持久节点:create /vnjohn “”
创建一个 ooxx 的空内容节点,如果后面不写内容的话就不会进行创建,比如:create /vnjohn
3、创建临时节点:create /vnjohn/ephemeral -e
若我当前这个客户端连接关闭后,这个节点就会消失不见!
4、创建序列节点:create /vnjohn/sequence:1:1 -s “sequence” 10
防止并行时创建同样的节点从而覆盖掉,ZK 帮忙做了数据隔离
5、获取节点信息:get /vnjohn,获取到 vnjohn 创建时给的内容,同时对以下的参数进行描述:
"" # 节点内容
cZxid = 0x200000002 # 创建节点时分配的事务 ID
ctime = Sat Mar 18 12:27:56 CST 2023 # 创建节点的时间
mZxid = 0x200000002 # 修改节点时分配的事务 ID
mtime = Sat Mar 18 12:27:56 CST 2023 # 修改节点的时间
pZxid = 0x200000005 # 当前节点下的最后一个子节点事务 ID,没有子节点就是当前节点的事务 ID
cversion = 2
dataVersion = 0
aclVersion = 0
# 临时拥有者,只有创建临时节点时才会有值,这个值是客户端连接 ZK 时分配的 SESSION_ID
# 如果这个 SESSION 关闭了,这个节点就会消失
# SESSION 在所有 zookeeper 节点下是都可以被看到的
ephemeralOwner = 0x0
dataLength = 2
# 子节点数量,/vnjohn 下目前存在两个子节点
numChildren = 2
6、查询父节点下有多少个子节点:ls /
[zk: localhost:2181(CONNECTED) 24] ls /
[vnjohn, zookeeper]
连接 ZK 和关闭 ZK 都会消耗一个事务 ID
该篇文,对 ZooKeeper 服务模型以及它的一些特性作了简要的描述,同时,介绍了 ZooKeeper 中一些面试中常常问到的术语,比如:myid、Zxid、选举状态等;为大家准备了在 Linux 中如何搭建好一个 ZK 集群,从日志内容分析出它与上下文之间的关系,对核心配置文件 zoo.cfg 参数作了介绍,最后对一些常见的 ZK 命令操作作了演示,当然,还有更多的特性,比如:分布式锁、Watch 机制!
推荐给大家 Raft 算法演变过程的网站,用动画的方式生动演练了选举主的过程->Raft Distributed Consensus
如果觉得博文不错,关注我 vnjohn,后续会有更多实战、源码、架构干货分享!
大家的「关注❤️ + 点赞👍 + 收藏⭐」就是我创作的最大动力!谢谢大家的支持,我们下文见!
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
我的ruby脚本从命令行参数获取某些输入。它检查是否缺少任何命令行参数,然后提示用户输入。但是我无法使用gets从用户那里获得输入。示例代码:test.rbname=""ARGV.eachdo|a|ifa.include?('-n')name=aputs"Argument:#{a}"endendifname==""puts"entername:"name=getsputsnameend运行脚本:rubytest.rbraghav-k错误结果:test.rb:6:in`gets':Nosuchfileordirectory-raghav-k(Errno::ENOENT)fromtes
术语中文解释Ability原子化服务帮助用户完成任务的原子化服务,和用户的意图进行关联。Fulfillment服务履行通过图标,卡片,语音等形式呈现用户意图。开发者通过接口的方式,处理用户意图,返回内容。Intent意图用于表达用户想要达成的目标或完成的任务。HUAWEIAssistant智能助手“无微不智”的个人助手,通过不断的学习用户的使用习惯,不断的为用户提供贴心的精准的便捷的个性化服务。AISearch全局搜索用户可快速搜索关键词,与之匹配的原子化服务则会出现在搜索结果中。SmartService智慧服务用户订阅原子化服务,在到达特定触发条件(时间、地点、事件)后,卡片推送至用户智能助
目录H2数据库入门以及实际开发时的使用1.H2数据库的初识1.1H2数据库介绍1.2为什么要使用嵌入式数据库?1.3嵌入式数据库对比1.3.1性能对比1.4技术选型思考2.H2数据库实战2.1H2数据库下载搭建以及部署2.1.1H2数据库的下载2.1.2数据库启动2.1.2.1windows系统可以在bin目录下执行h2.bat2.1.2.2同理可以通过cmd直接使用命令进行启动:2.1.2.3启动后控制台页面:2.1.3spring整合H2数据库2.1.3.1引入依赖文件2.1.4数据库通过file模式实际保存数据的位置2.2H2数据库操作2.2.1Mysql兼容模式2.2.2Mysql模式
我有一个启动DRb服务的脚本,然后生成处理程序对象并通过DRb.thread.join等待。我希望脚本一直运行直到被明确杀死,所以我添加了trap"INT"doDRb.stop_serviceend在Ruby1.8下成功停止DRb服务并退出,但在1.9下似乎死锁(在OSX10.6.7上)。对该进程进行采样显示在semaphore_wait_signal_trap中有几个线程在旋转。我假设我在调用stop_service时做错了什么,但我不确定是什么。谁能给我任何关于如何正确处理它的指示? 最佳答案 好的,我想我已经找到了解决方案。如