
 对于事中风控和事后风控来讲,端上的感知是异步的,对于事先风控来讲,端上的感知是同步的。对于事先风控这里稍做一些解释,事先风控是把已经训练好的模型或者把已经计算好的数据存在 Redis 、MongoDB 等数据库中;
对于事中风控和事后风控来讲,端上的感知是异步的,对于事先风控来讲,端上的感知是同步的。对于事先风控这里稍做一些解释,事先风控是把已经训练好的模型或者把已经计算好的数据存在 Redis 、MongoDB 等数据库中;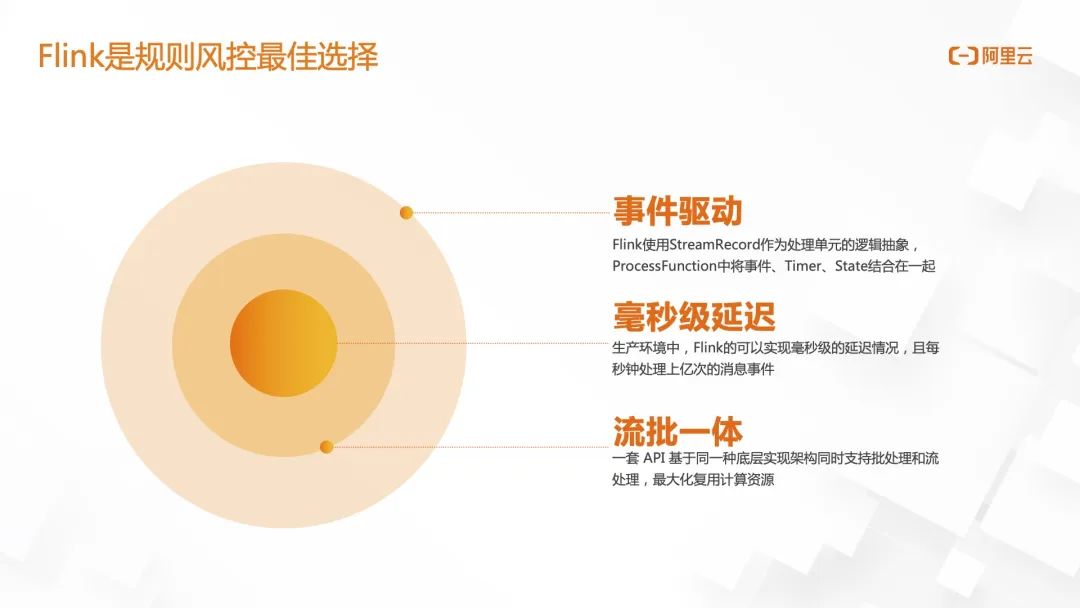

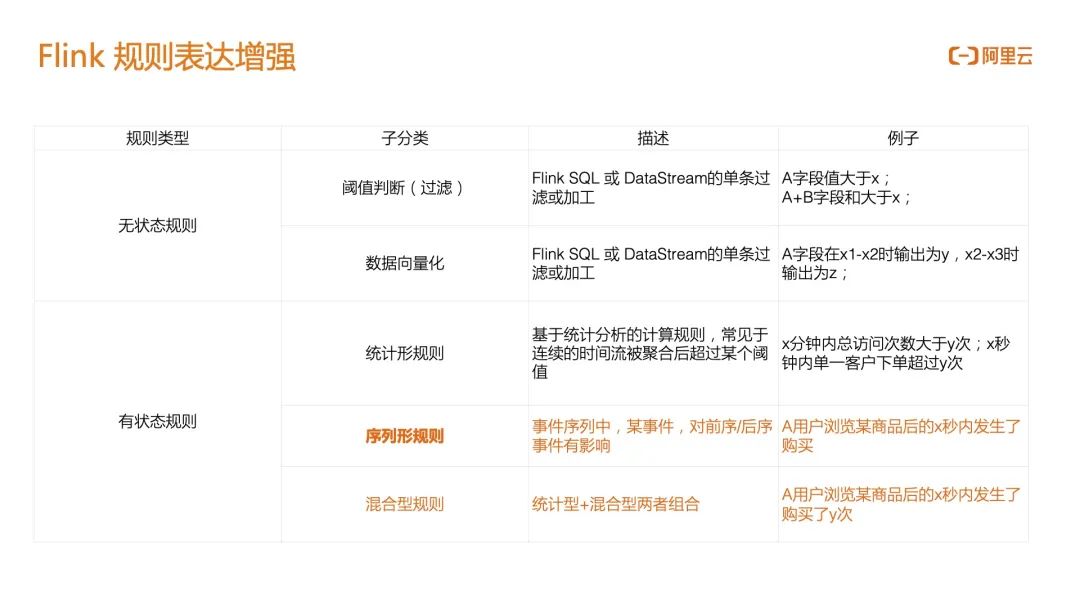
 从整体的技术来看,目前分成感知、处置和洞察三个模块:
从整体的技术来看,目前分成感知、处置和洞察三个模块:
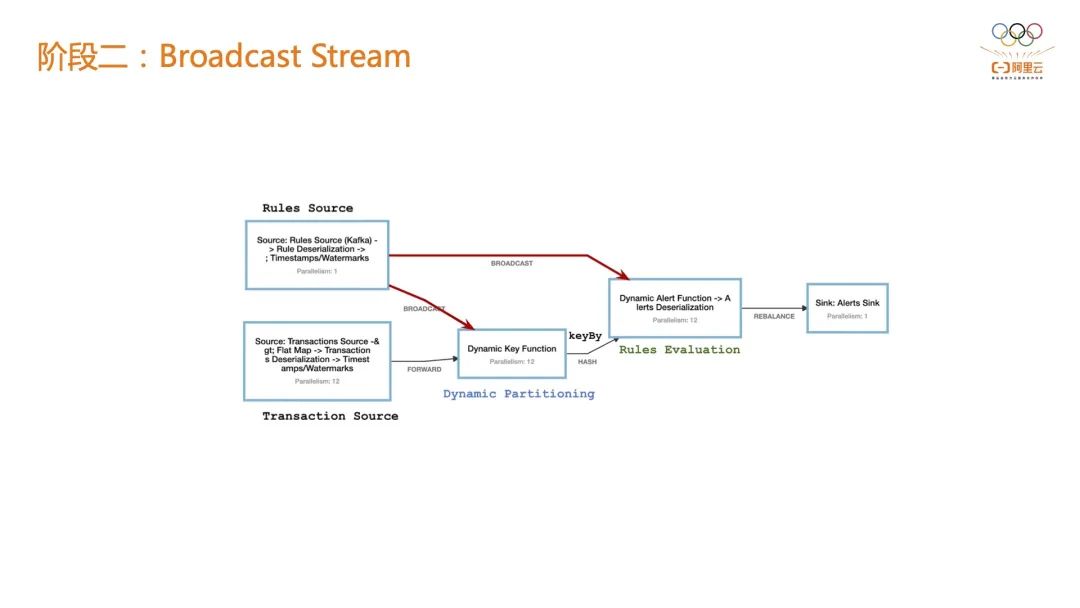 举个例子,判断在一分钟以内连续访问超过 10 次的风控对象,但是在 618 或双 11 可能要把它变成 20 或 30 次,才会被风控系统下游的在线系统感知到。如果在第一阶段的话,只有两种选择:第一种是所有的作业全量在线上跑;第二种是在某一刻停止掉一个Flink作业,新拉起一个基于新指标的作业。如果是基于 BroadcastStream 就可以实现规则指标阈值的下发,直接修改线上指标阈值而不需要作业重启。
举个例子,判断在一分钟以内连续访问超过 10 次的风控对象,但是在 618 或双 11 可能要把它变成 20 或 30 次,才会被风控系统下游的在线系统感知到。如果在第一阶段的话,只有两种选择:第一种是所有的作业全量在线上跑;第二种是在某一刻停止掉一个Flink作业,新拉起一个基于新指标的作业。如果是基于 BroadcastStream 就可以实现规则指标阈值的下发,直接修改线上指标阈值而不需要作业重启。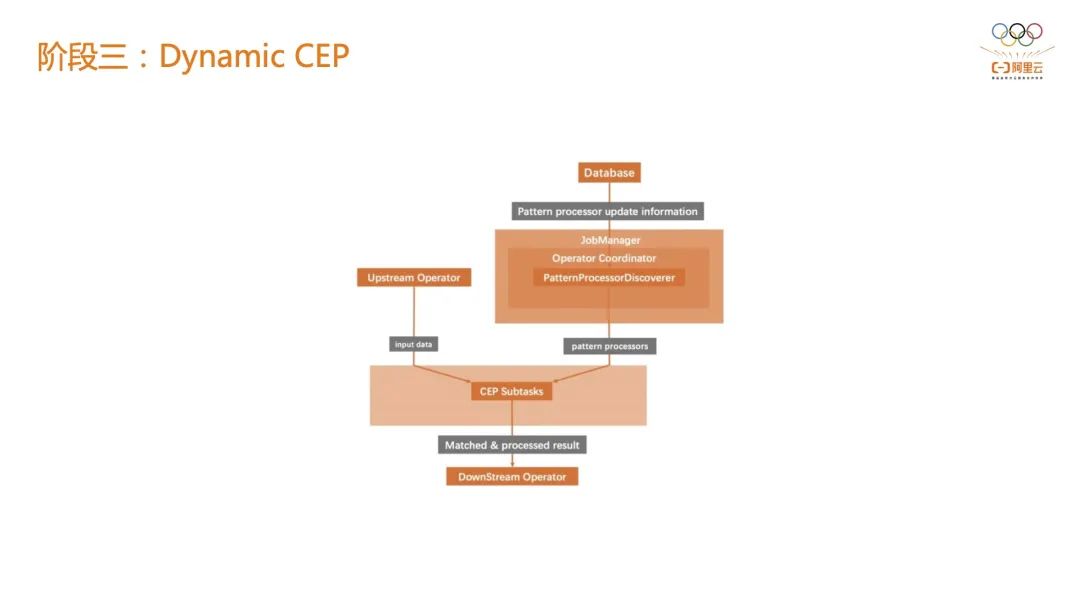
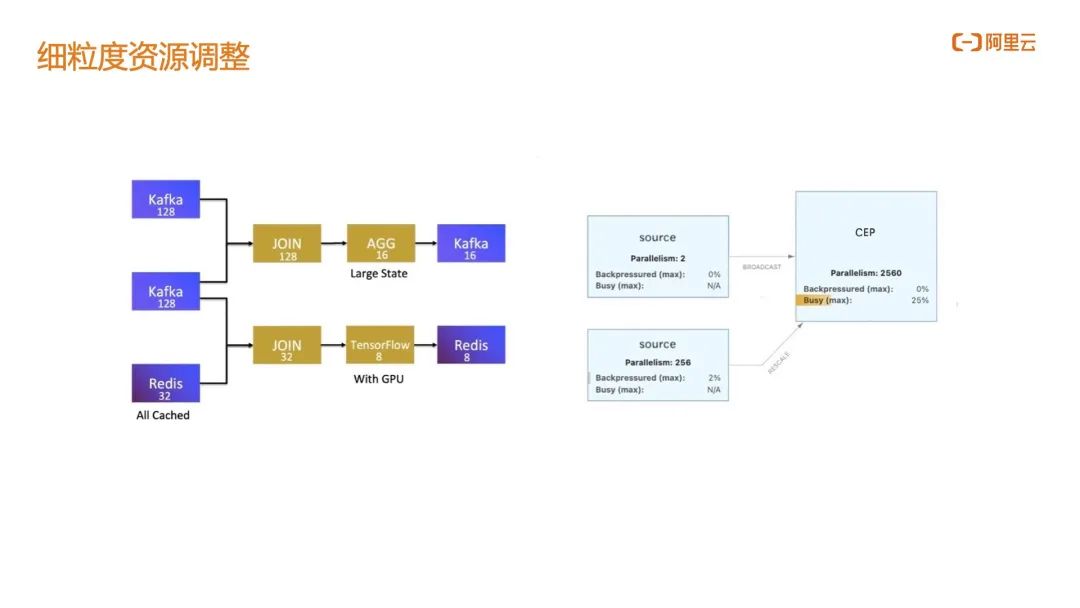 另外是对 CEP 工作节点所在的 TM 内存、CPU 资源的划分,在开源 Flink 中 TM 整体同构的,也就是说 Source 节点和工作节点是完全相同的规格。从节省资源的角度考虑,真实生产环境下 Source 节点并不需要 CEP 节点一样多的内存、CPU 资源, Source 节点只需要较小的 CPU 和内存就已经能够满足数据抓取。阿里云全托管 Flink 可以实现让 Source 节点和 CEP 节点运行在异构的 TM 上,即 CEP 工作节点 TM 资源显著大于 Source 节点 TM 资源,CEP 工作执行效率会变得更高。考虑细粒度资源调整带来的优化,云上全托管服务相比自建 IDC Flink 可节约 20% 成本。
另外是对 CEP 工作节点所在的 TM 内存、CPU 资源的划分,在开源 Flink 中 TM 整体同构的,也就是说 Source 节点和工作节点是完全相同的规格。从节省资源的角度考虑,真实生产环境下 Source 节点并不需要 CEP 节点一样多的内存、CPU 资源, Source 节点只需要较小的 CPU 和内存就已经能够满足数据抓取。阿里云全托管 Flink 可以实现让 Source 节点和 CEP 节点运行在异构的 TM 上,即 CEP 工作节点 TM 资源显著大于 Source 节点 TM 资源,CEP 工作执行效率会变得更高。考虑细粒度资源调整带来的优化,云上全托管服务相比自建 IDC Flink 可节约 20% 成本。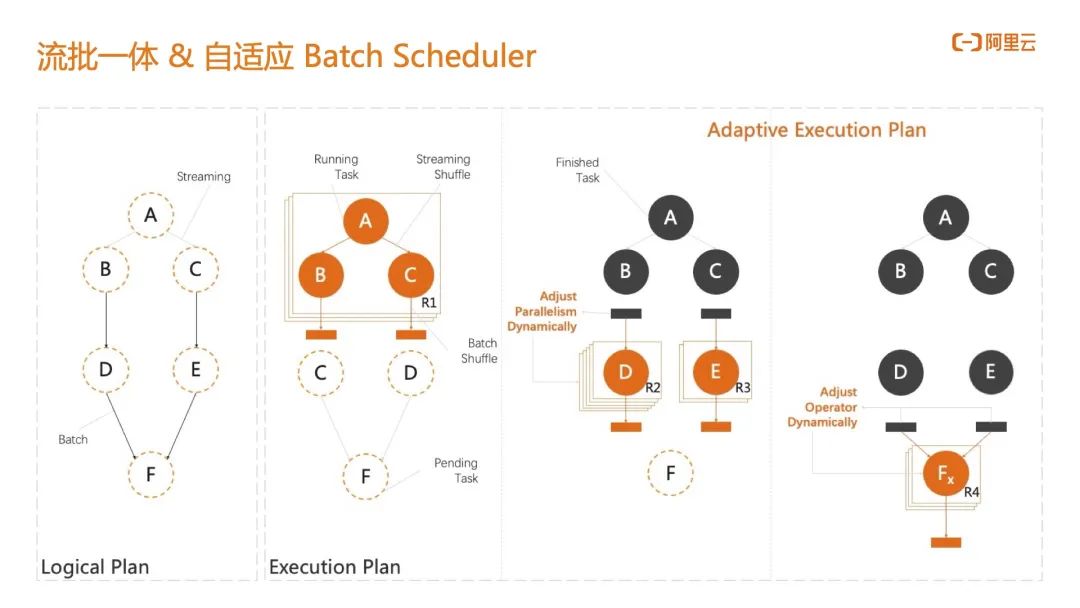 在此之上,阿里实现了自适应的 Batch Scheduler。其实 CEP 规则每天的效果产出并不一定是均衡的,比如说今天的行为序列中并没有任何异常行为,下游只有很少的数据输入,此时会为批分析预留一个弹性的集群;当 CEP 的结果很少时,下游的批分析只需要很小的资源,甚至每个批分析工作节点的并行度都不需要在一开始的时候就指定,工作节点可以根据上游数据的输出以及任务负载来自动调整批模式下的并行度,真正做到了弹性批分析,这是阿里云 Flink 流批一体 Batch Scheduler 的独特优势。
在此之上,阿里实现了自适应的 Batch Scheduler。其实 CEP 规则每天的效果产出并不一定是均衡的,比如说今天的行为序列中并没有任何异常行为,下游只有很少的数据输入,此时会为批分析预留一个弹性的集群;当 CEP 的结果很少时,下游的批分析只需要很小的资源,甚至每个批分析工作节点的并行度都不需要在一开始的时候就指定,工作节点可以根据上游数据的输出以及任务负载来自动调整批模式下的并行度,真正做到了弹性批分析,这是阿里云 Flink 流批一体 Batch Scheduler 的独特优势。
在编写Ruby(客户端脚本)时,我看到了三种构建更长字符串的方法,包括行尾,所有这些对我来说“闻起来”有点难看。有没有更干净、更好的方法?变量递增。ifrender_quote?quote="NowthatthereistheTec-9,acrappyspraygunfromSouthMiami."quote+="ThisgunisadvertisedasthemostpopularguninAmericancrime.Doyoubelievethatshit?"quote+="Itactuallysaysthatinthelittlebookthatcomeswithit:themo
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
电脑0x0000001A蓝屏错误怎么U盘重装系统教学分享。有用户电脑开机之后遇到了系统蓝屏的情况。系统蓝屏问题很多时候都是系统bug,只有通过重装系统来进行解决。那么蓝屏问题如何通过U盘重装新系统来解决呢?来看看以下的详细操作方法教学吧。 准备工作: 1、U盘一个(尽量使用8G以上的U盘)。 2、一台正常联网可使用的电脑。 3、ghost或ISO系统镜像文件(Win10系统下载_Win10专业版_windows10正式版下载-系统之家)。 4、在本页面下载U盘启动盘制作工具:系统之家U盘启动工具。 U盘启动盘制作步骤: 注意:制作期间,U盘会被格式化,因此U盘中的重要文件请注
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我正在尝试在配备ARMv7处理器的SynologyDS215j上安装ruby2.2.4或2.3.0。我用了optware-ng安装gcc、make、openssl、openssl-dev和zlib。我根据README中的说明安装了rbenv(版本1.0.0-19-g29b4da7)和ruby-build插件。.这些是随optware-ng安装的软件包及其版本binutils-2.25.1-1gcc-5.3.0-6gconv-modules-2.21-3glibc-opt-2.21-4libc-dev-2.21-1libgmp-6.0.0a-1libmpc-1.0.2-1libm
因为我现在正在做一些时间测量,我想知道是否可以在不使用Benchmark类或命令行实用程序time的情况下测量用户时间或系统时间。使用Time类只显示挂钟时间,而不显示系统和用户时间,但是我正在寻找具有相同灵active的解决方案,例如time=TimeUtility.now#somecodeuser,system,real=TimeUtility.now-time原因是我有点不喜欢Benchmark,因为它不能只返回数字(编辑:我错了-它可以。请参阅下面的答案。)。当然,我可以解析输出,但感觉不对。*NIX系统的time实用程序也应该可以解决我的问题,但我想知道是否已经在Ruby中实
在Ruby中,以毫秒为单位获取自纪元(1970)以来的当前系统时间的正确方法是什么?我试过了Time.now.to_i,好像不是我想要的结果。我需要结果显示毫秒并且使用long类型,而不是float或double。 最佳答案 (Time.now.to_f*1000).to_iTime.now.to_f显示包含十进制数字的时间。要获得毫秒数,只需将时间乘以1000。 关于ruby-以毫秒为单位获取当前系统时间,我们在StackOverflow上找到一个类似的问题:
我正在寻找用于Rails的优质管理插件。似乎大多数现有的插件/gem(例如“restful_authentication”、“acts_as_authenticated”)都围绕着self注册等展开。但是,我正在寻找一种功能齐全的基于管理/管理角色的解决方案——但不是简单地附加到另一个非基于角色的解决方案。如果我找不到,我想我会自己动手......只是不想重新发明轮子。 最佳答案 RyanBates最近做了两个关于授权的railscast(注意身份验证和授权之间的区别;身份验证检查用户是否如她所说的那样,授权检查用户是否有权访问资源