CAM、SAM、CBAM详见:CBAM——即插即用的注意力模块(附代码)
目录
从数学角度看,注意力机制即提供一种权重模式进行运算。
神经网络中,注意力机制即利用一些网络层计算得到特征图对应的权重值,对特征图进行”注意力机制“。
论文地址:论文
该论文于2018年发表于CVPR,是较早的将注意力机制引入卷积神经网络,并且该机制是一种即插即用的模块,可嵌入任意主流的卷积神经网络中,为卷积神经网络模型设计提供新思路——即插即用模块设计。
摘要核心:
SE Block模型图如下所示:由两部分组成Squeeze和Excitation
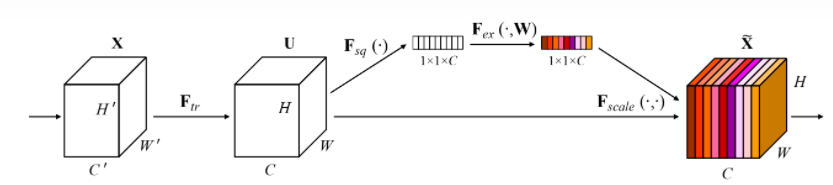
Squeeze(Global Information Embedding):全局信息低维嵌入
Squeeze操作:采用全局池化,即压缩H和W至1*1,利用1个像素来表示一个通道,实现低维嵌入。压缩后的特征本质是一个向量,无空间维度,只有通道维度。
Squeeze计算公式:
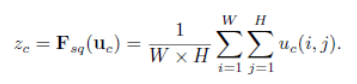
相对应模型的实现位置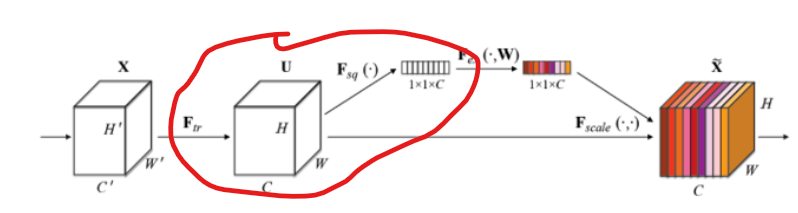
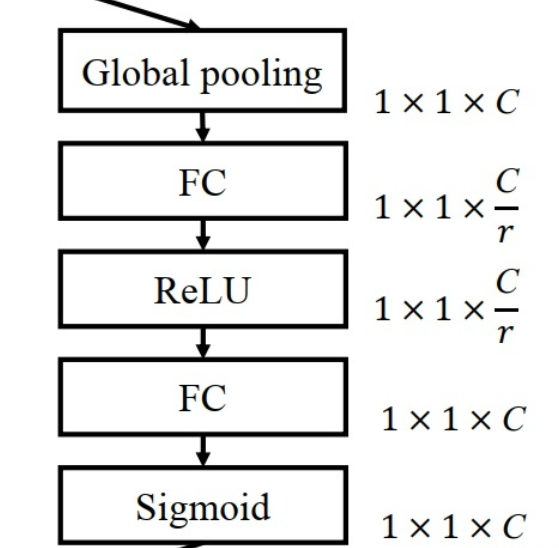
Excitation(Adaptative Recalibration):适应变换
Excitation部分是用2个全连接来实现 ,第一个全连接把C个通道压缩成了C/r个通道来降低计算量(后面跟了RELU),第二个全连接再恢复回C个通道(后面跟了Sigmoid),r是指压缩的比例。作者尝试了r在各种取值下的性能 ,最后得出结论r=16时整体性能和计算量最平衡。
Excitation公式: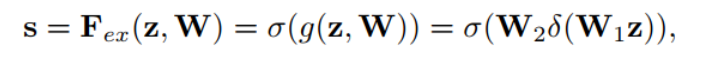
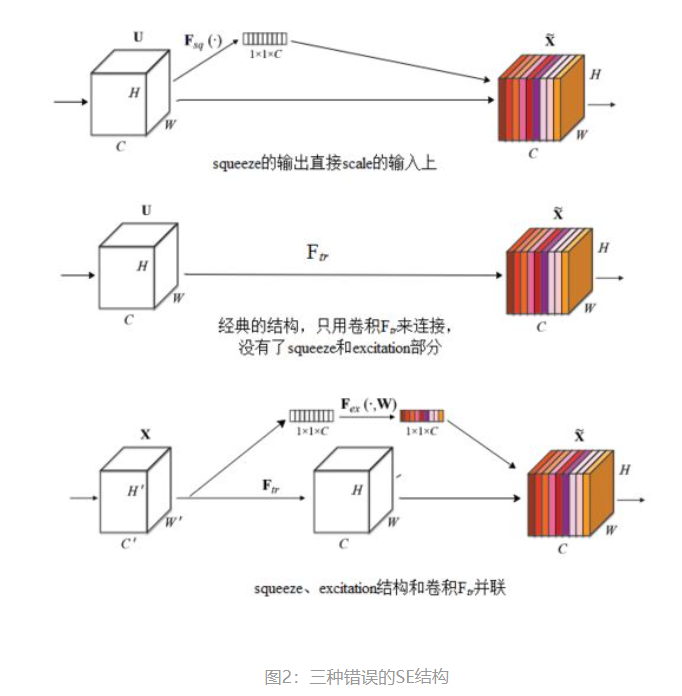
为什么要加全连接层呢?这是为了利用通道间的相关性来训练出真正的scale。一次mini-batch个样本的squeeze输出并不代表通道真实要调整的scale值,真实的scale要基于全部数据集来训练得出,而不是基于单个batch,所以后面要加个全连接层来进行训练。可以拿SE Block和下面3种错误的结构比较来进一步理解:
图2最上方的结构,squeeze的输出直接scale到输入上,没有了全连接层,某个通道的调整值完全基于单个通道GAP的结果,事实上只有GAP的分支是完全没有反向计算、没有训练的过程的,就无法基于全部数据集来训练得出通道增强、减弱的规律。
图2中间是经典的卷积结构,有人会说卷积训练出的权值就含有了scale的成分在里面,也利用了通道间的相关性,为啥还要多个SE Block?那是因为这种卷积有空间的成分在里面,为了排除空间上的干扰就得先用GAP压缩成一个点后再作卷积,压缩后因为没有了Height、Width的成分,这种卷积就是全连接了。
图2最下面的结构,SE模块和传统的卷积间采用并联而不是串联的方式,这时SE利用的是Ftr输入X的相关性来计算scale,X和U的相关性是不同的,把根据X的相关性计算出的scale应用到U上明显不合适。
相对应模型的实现位置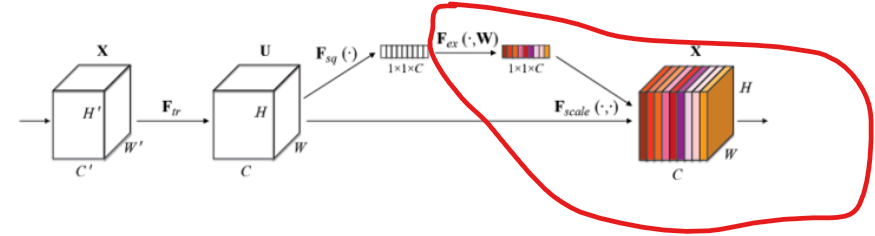
分开看完之后,再整合起来看就是如下图这样的操作过程。
SE Block的嵌入方式:只“重构”特征图,不改变原来结构。
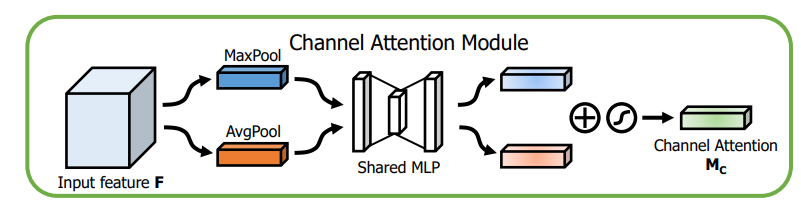
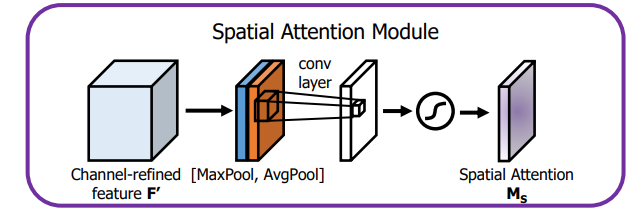
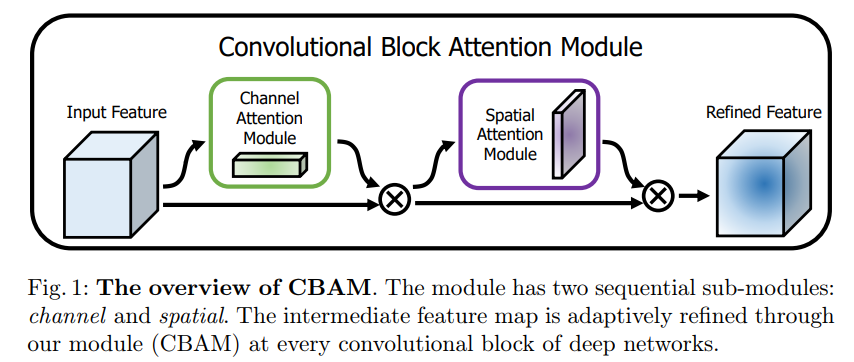
空间注意力模块
import torch
from torch import nn
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) # 7,3 3,1
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
if __name__ == '__main__':
SA = SpatialAttention(7)
data_in = torch.randn(8,32,300,300)
data_out = SA(data_in)
print(data_in.shape) # torch.Size([8, 32, 300, 300])
print(data_out.shape) # torch.Size([8, 1, 300, 300])
通道注意力模块
import torch
from torch import nn
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
if __name__ == '__main__':
CA = ChannelAttention(32)
data_in = torch.randn(8,32,300,300)
data_out = CA(data_in)
print(data_in.shape) # torch.Size([8, 32, 300, 300])
print(data_out.shape) # torch.Size([8, 32, 1, 1])
CBAM注意力机制
import torch
from torch import nn
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False) # 7,3 3,1
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class CBAM(nn.Module):
def __init__(self, in_planes, ratio=16, kernel_size=7):
super(CBAM, self).__init__()
self.ca = ChannelAttention(in_planes, ratio)
self.sa = SpatialAttention(kernel_size)
def forward(self, x):
out = x * self.ca(x)
result = out * self.sa(out)
return result
if __name__ == '__main__':
print('testing ChannelAttention'.center(100,'-'))
torch.manual_seed(seed=20200910)
CA = ChannelAttention(32)
data_in = torch.randn(8,32,300,300)
data_out = CA(data_in)
print(data_in.shape) # torch.Size([8, 32, 300, 300])
print(data_out.shape) # torch.Size([8, 32, 1, 1])
if __name__ == '__main__':
print('testing SpatialAttention'.center(100,'-'))
torch.manual_seed(seed=20200910)
SA = SpatialAttention(7)
data_in = torch.randn(8,32,300,300)
data_out = SA(data_in)
print(data_in.shape) # torch.Size([8, 32, 300, 300])
print(data_out.shape) # torch.Size([8, 1, 300, 300])
if __name__ == '__main__':
print('testing CBAM'.center(100,'-'))
torch.manual_seed(seed=20200910)
cbam = CBAM(32, 16, 7)
data_in = torch.randn(8,32,300,300)
data_out = cbam(data_in)
print(data_in.shape) # torch.Size([8, 32, 300, 300])
print(data_out.shape) # torch.Size([8, 1, 300, 300])
SE注意力机制
from torch import nn
import torch
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
# return x * y
if __name__ == '__main__':
torch.manual_seed(seed=20200910)
data_in = torch.randn(8,32,300,300)
SE = SELayer(32)
data_out = SE(data_in)
print(data_in.shape) # torch.Size([8, 32, 300, 300])
print(data_out.shape) # torch.Size([8, 32, 300, 300])
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
我正在使用Ruby-Tk为OSX开发一个桌面应用程序,我想为该应用程序提供一个AppleEvents接口(interface)。这意味着应用程序将定义它将响应的AppleScript命令的字典(对应于发送到应用程序的Apple事件),并且用户/其他应用程序可以使用AppleScript命令编写Ruby-Tk应用程序的脚本。其他脚本语言支持此类功能——Python通过位于http://appscript.svn.sourceforge.net/viewvc/appscript/py-aemreceive/的py-aemreceive库和Tcl通过位于http://tclae.source
Method#unbind返回对该方法的UnboundMethod引用,稍后可以使用UnboundMethod#bind将其绑定(bind)到另一个对象.classFooattr_reader:bazdefinitialize(baz)@baz=bazendendclassBardefinitialize(baz)@baz=bazendendf=Foo.new(:test1)g=Foo.new(:test2)h=Bar.new(:test3)f.method(:baz).unbind.bind(g).call#=>:test2f.method(:baz).unbind.bind(h).
本文档适用于SOPHGO(算能)BM1684-SE5及对应通用云开发空间,主要内容:注意:由于SOPHGOSE5微服务器的CPU是基于ARM架构,部分步骤将在基于x86架构CPU的开发环境中完成初始化开发环境(基于x86架构CPU的开发环境中完成)YOLO3D目标检测算法模型转换(基于x86架构CPU的开发环境中完成)YOLO3D模型推理测试(处理后的YOLO3D项目文件将被拷贝至SOPHGOSE5微服务器上推理测试)1.初始化开发环境(基于x86架构CPU的开发环境中完成)1.1初始化开发环境(若wget后的地址不可用,请前往算能官网下载Docker镜像及SDK)#切换成root权限sudo
如果觉得文章还行,能点个赞嘛?您的点赞是我更新的动力!!目录SAM的demo源码使用结合SAM,进行人机交互ui使用的案例介绍:最近新发现的,可以利用这个模型,进行一个简单的UI使用,效果如下:labelimg结合SAM实现半自动标注软件SAM的demo源码使用首先说明这个链接里面的代码是关于demo的,目前还不能训练。原仓库https://github.com/facebookresearch/segment-anything我们都知道在CV领域比较重要的处理图像的几个方向有:识别,测量(标定),三维物体重建等。识别是最基础也是最重要的,那么分割在识别里面更是重中之重,所以这个大模型分割真的
显示等待需要用到两个类:WebDriverWait和expected_conditions两个类WebDriverWait:指定轮询间隔、超时时间等expected_conditions:指定了很多条件函数(也可以自定义条件函数)具体可以参考官网:selenium.webdriver.support.expected_conditions—Selenium4.5documentationfromseleniumimportwebdriverfromselenium.webdriver.common.byimportByfromselenium.webdriver.support.uiimpor
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭10年前。社区在12个月前审查了是否重新打开此问题,并将其关闭:原始关闭原因未解决最近学习了Ruby编程语言,总的来说是一门很好的语言。但是我很惊讶地发现它并不像我预期的那么简单。更准确地说,“最小惊喜规则”在我看来并不是很受尊重(当然这是相当主观的)。例如:x=trueandfalseputsx#displaystrue!和著名的:puts"zeroistrue
我收到错误AWS::S3::Errors::InvalidRequest不支持您提供的授权机制。请使用AWS4-HMAC-SHA256.当我尝试将文件上传到新法兰克福地区的S3存储桶时。所有适用于USStandard区域。脚本:backup_file='/media/db-backup_for_dev/2014-10-23_02-00-07/slave_dump.sql.gz's3=AWS::S3.new(access_key_id:AMAZONS3['access_key_id'],secret_access_key:AMAZONS3['secret_access_key'])s3_
【摘 要】近年来,基于自注意力机制的神经网络在计算机视觉任务中得到广泛的应用。随着智能交通系统的广泛应用,面对复杂多变的交通场景,车牌识别任务的难度不断提高,准确识别的需求更加迫切。因此提出一个基于自注意力的免矫正的车牌识别方法T-LPR。首先对图像进行切片和序列化,并使用3D卷积对切片序列进行特征提取,从而得到图像的嵌入向量序列。然后将嵌入向量序列输入基于TransformerEncoder的编码器中,学习各个嵌入向量之间的关系并输出最终的编码结果。最后使用分类器进行分类。在多个公共数据集上的实验结果表明,所提方法对各类困难场景下的车牌识别都非常有效。【关键词】车牌识别 ; 图像嵌入向量 ;
这个问题在这里已经有了答案:"CAUTION:provisionalheadersareshown"inChromedebugger(36个答案)关闭8年前。这是我的Angularjs片段代码:$http({method:'POST',withCredential:true,url:$scope.config.app_ws+'auth/signup',data:{user:$scope.auth}}).success(function(status,response){console.log(response);}).error(function(status,response){al