伪静态是相对于静态文件来说的,例如https://www.cnblogs.com/hesujian/p/11165818.html
将一个动态网页伪装成静态网页
将url地址模拟成html结尾的样子,看上去像是一个静态文件,只是改变了URL的表现形式,实际上还是动态页面
搜索优化:seo
在路由的最后加上.html
1、美观(传统的问号拼接看起来比较杂乱)
2、seo(搜索引擎优化技术),搜索引擎比较喜欢收录静态页面,所以大家都做成伪静态去增加收录机会,增大本网站的seo查询力度,增加搜索引擎收藏本网站的概率
# 在路由后面加上.html就可实现静态页面效果
path('index.html',view.index)
Django视图层,视图就是Django项目下的views.py文件,它的内部是一系列的函数或者是类,用来专门处理客户端访问请求后处理请求并且返回相应的数据,相当于一个中央情报处理系统。
"""
HttpResponse
返回字符串类型
httpresponse() 括号内直接跟一个具体的字符串作为响应体,比较直接简单,所有这里主要介绍后面两种形式。
render
返回html页面 并且在返回给浏览器之前还可以给html文件传值
render(request, template_name[, context])结合一个给定的模板和一个给定的上下文字典,并返回一个渲染后的 HttpResponse 对象。
# 参数:
request: 用于生成响应的请求对象。
template_name:要使用的模板的完整名称,可选的参数
context:添加到模板上下文的一个字典。默认是一个空字典。如果字典中的某个值是可调用的,视图将在渲染模板之前调用它。
render方法就是将一个模板页面中的模板语法进行渲染,最终渲染成一个html页面作为响应体。
redirect
传递要重定向的一个硬编码的URL
def my_view(request):
rerurn redirect('/some/url/')
也可以是一个完整的URL
def my_view(request):
...
return redirect('http://www.baidu.com/')
"""
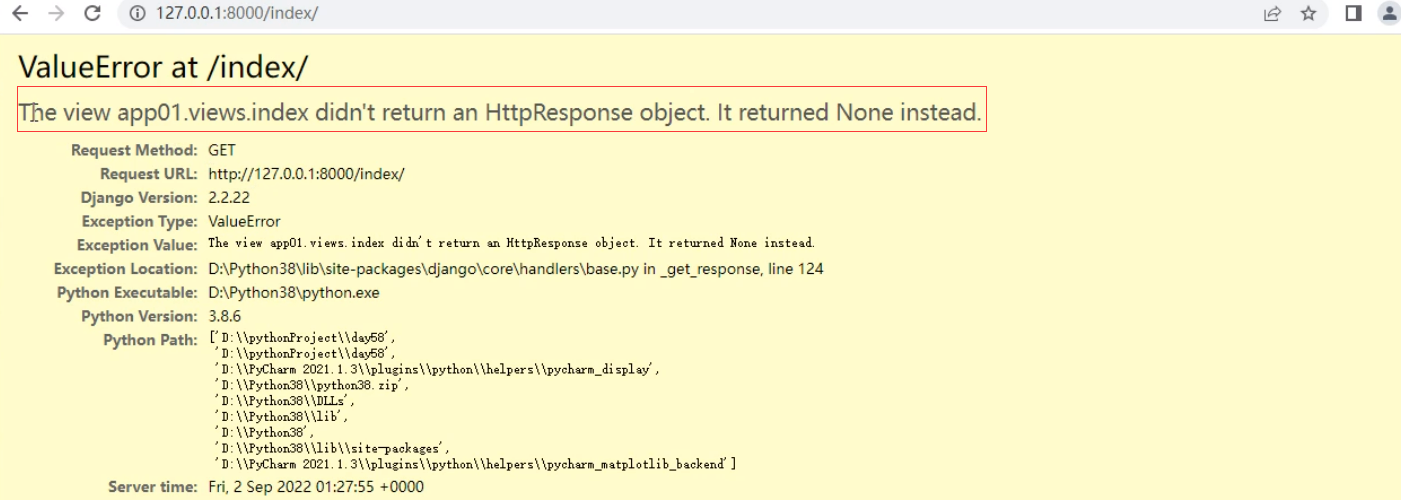
视图app01没有返回一个HttpResponse对象,返回一个None代替了
django视图层函数必须有一个返回值,并且返回值的数据类型必须是HttpResponse对象
1.def index(request):
return HttpResponse()
"""
按住ctrl点击进入HttpResponse:
发现HttpResponse其实是一个类,那么类名加()实例化产生一个对象
class HttpResponse(HttpResponseBase):
pass
"""
2.def index(request):
return render()
"""
按住ctrl点击进入render:
def render(request, template_name, context=None, content_type=None, status=None, using=None):
content = loader.render_to_string(template_name, context, request, using=using)
return HttpResponse(content, content_type, status)
先执行的是render函数,然后render函数返回的是HttpResponse(content, content_type, status)
"""
3.def index(request):
return redirect()
"""
按住ctrl点击进入redirect:
def redirect(to, *args, permanent=False, **kwargs):
redirect_class = HttpResponsePermanentRedirect if permanent else HttpResponseRedirect
return redirect_class(resolve_url(to, *args, **kwargs))
按住ctrl点击进入HttpResponsePermanentRedirect:
class HttpResponsePermanentRedirect(HttpResponseRedirectBase):
pass
按住ctrl点击进入HttpResponseRedirectBase:
class HttpResponseRedirectBase(HttpResponse):
pass
会发现它继承的也是HttpResponse
按住ctrl点击进入HttpResponseRedirect:
class HttpResponseRedirect(HttpResponseRedirectBase):
pass
按住ctrl点击进入HttpResponseRedirectBase:
class HttpResponseRedirectBase(HttpResponse):
pass
会发现它继承的也是HttpResponse
"""
'''综上研究发现:Django视图层函数必须要返回一个HttpResponse对象'''
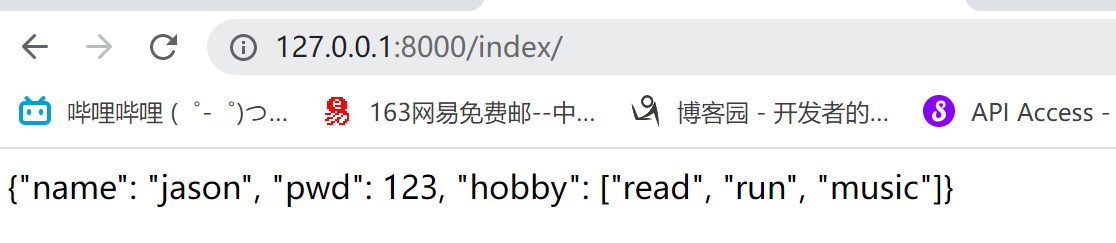
def index(request):
# 将后端字典序列化发送到前端
user_dict = {'name': 'jason', 'pwd': 123, 'hobby': ['read', 'run', 'music']}
# 先转成json格式字符串
json_str = json.dumps(user_dict)
# 将该字段返回
return HttpResponse(json_str)
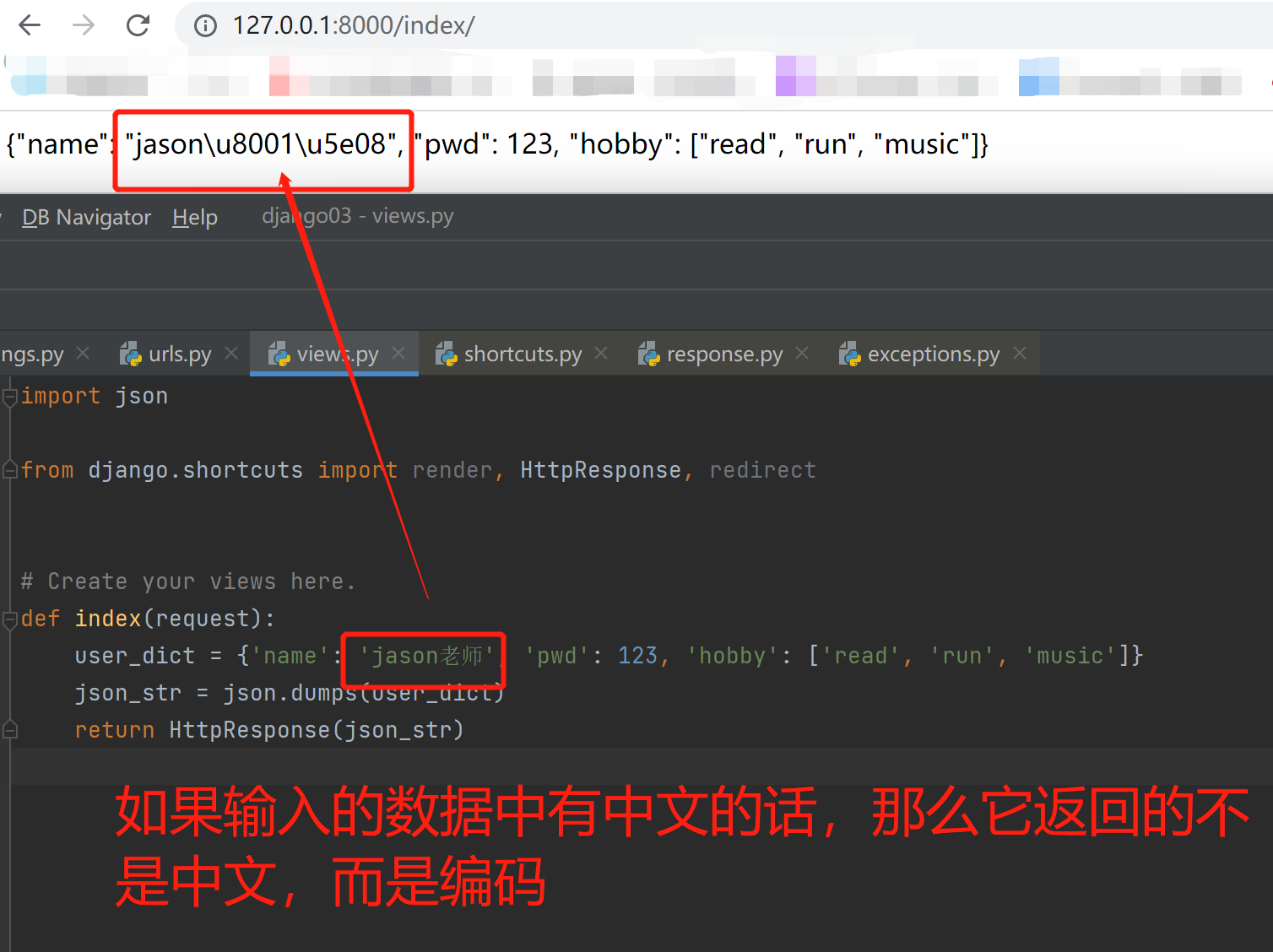
解决这个中文输入的问题我们之前是加了ensure_ascill=False,ensure_ascii 内部默认True自动转码,改为False不转码,只生成json格式,双引号
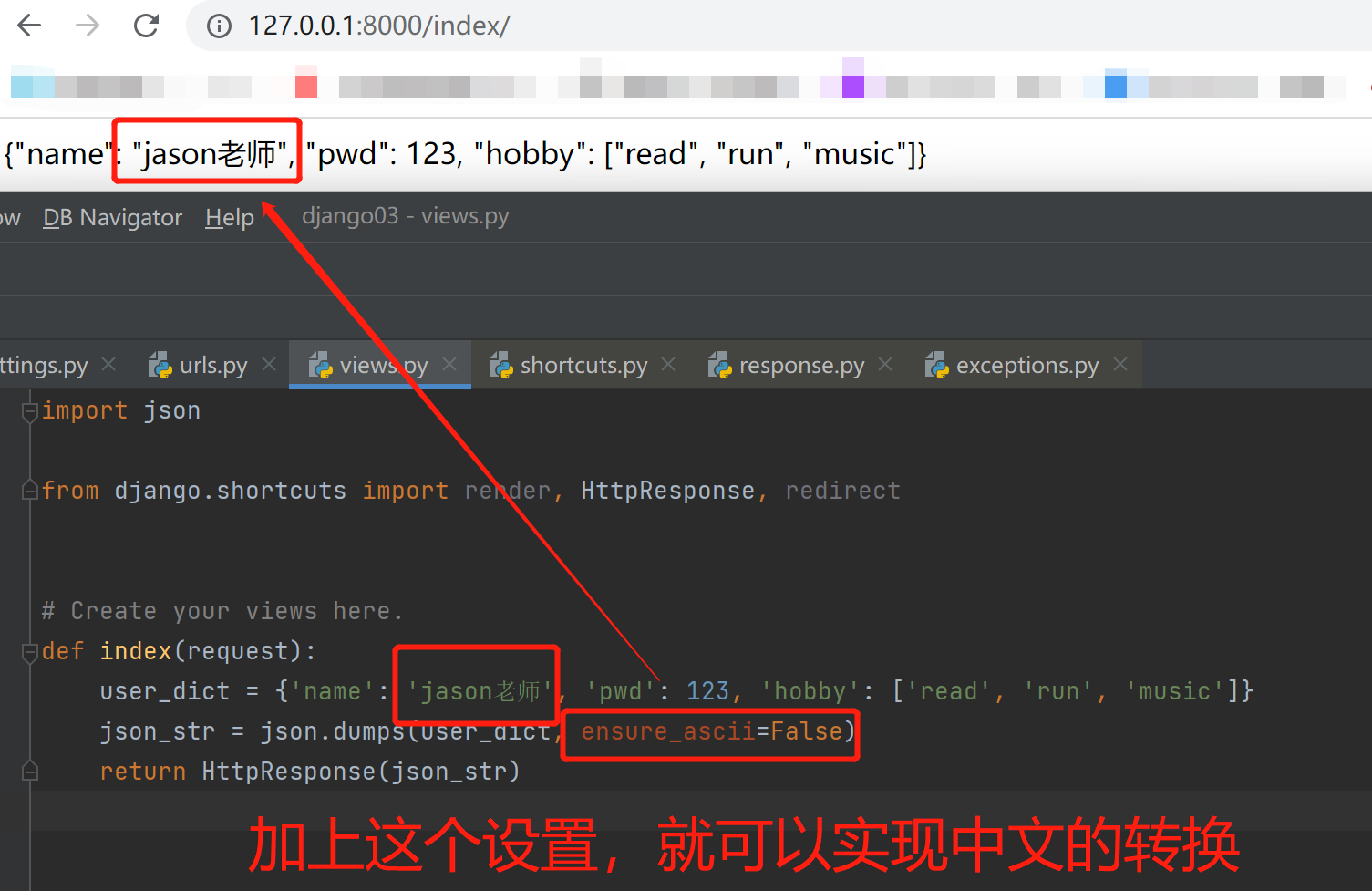
以上实现返沪json格式数据比较麻烦,又得转换json格式又得编码设置,那么Django的出现就在这方面做出了改变
# 导入JsonResponse模块
from django.http import JsonResponse
def index(request):
user_dict = {'name': 'jason老师', 'pwd': 123, 'hobby': ['read', 'run', 'music']}
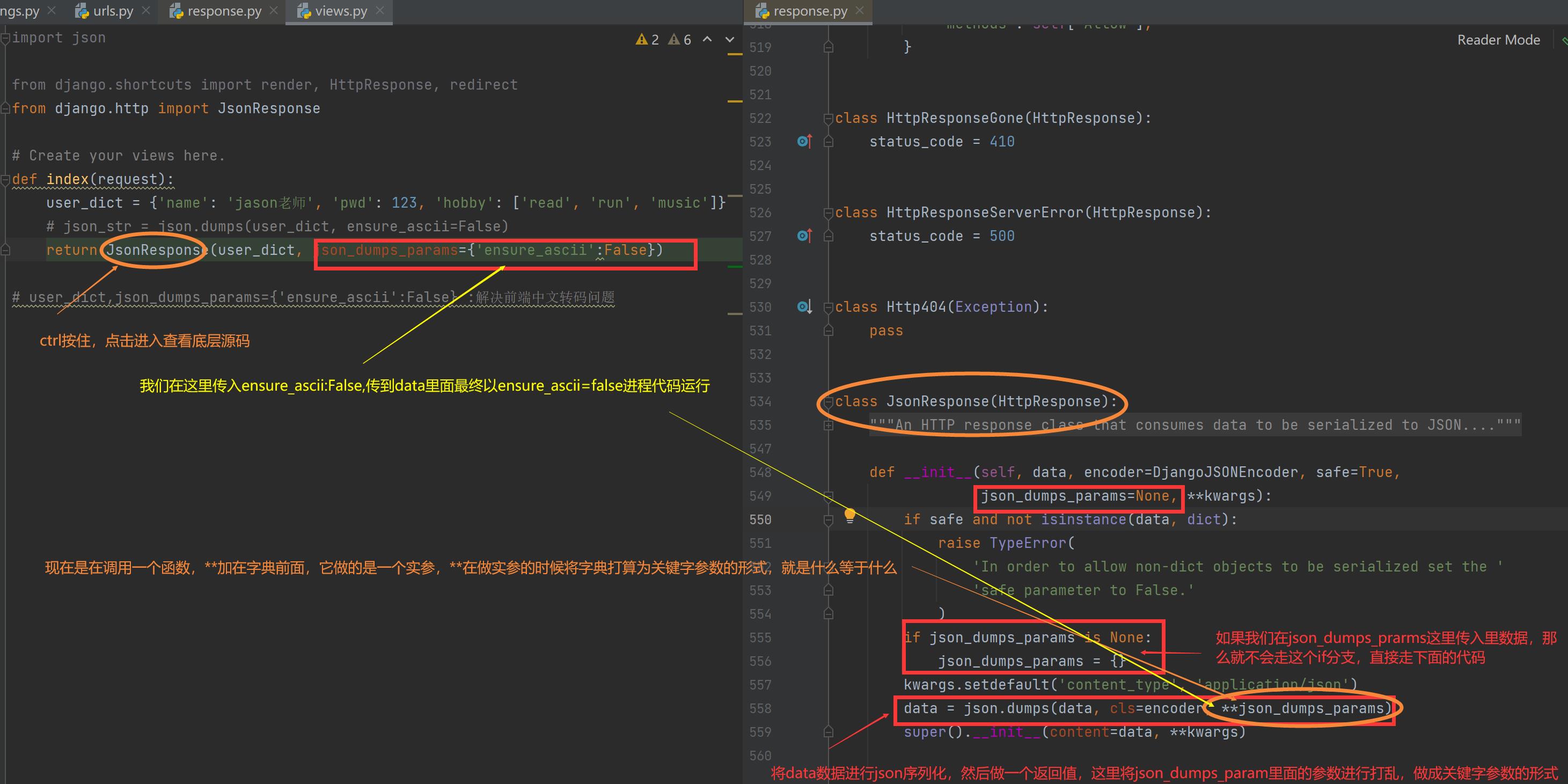
# json_str = json.dumps(user_dict, ensure_ascii=False)
return JsonResponse(user_dict, json_dumps_params={'ensure_ascii':False}) # 直接写入JsonResponse,不需要去做json序列化操作
# user_dict,json_dumps_params={'ensure_ascii':False} :解决前端中文转码问题
JsonResponse底层
# 继承了HttpResponse,返回的还是HttpResponse对象
class JsonResponse(HttpResponse):
def __init__(self, data, encoder=DjangoJSONEncoder, safe=True,
json_dumps_params=None, **kwargs):
# json_dumps_params=None,注意这个参数,是一个默认参数
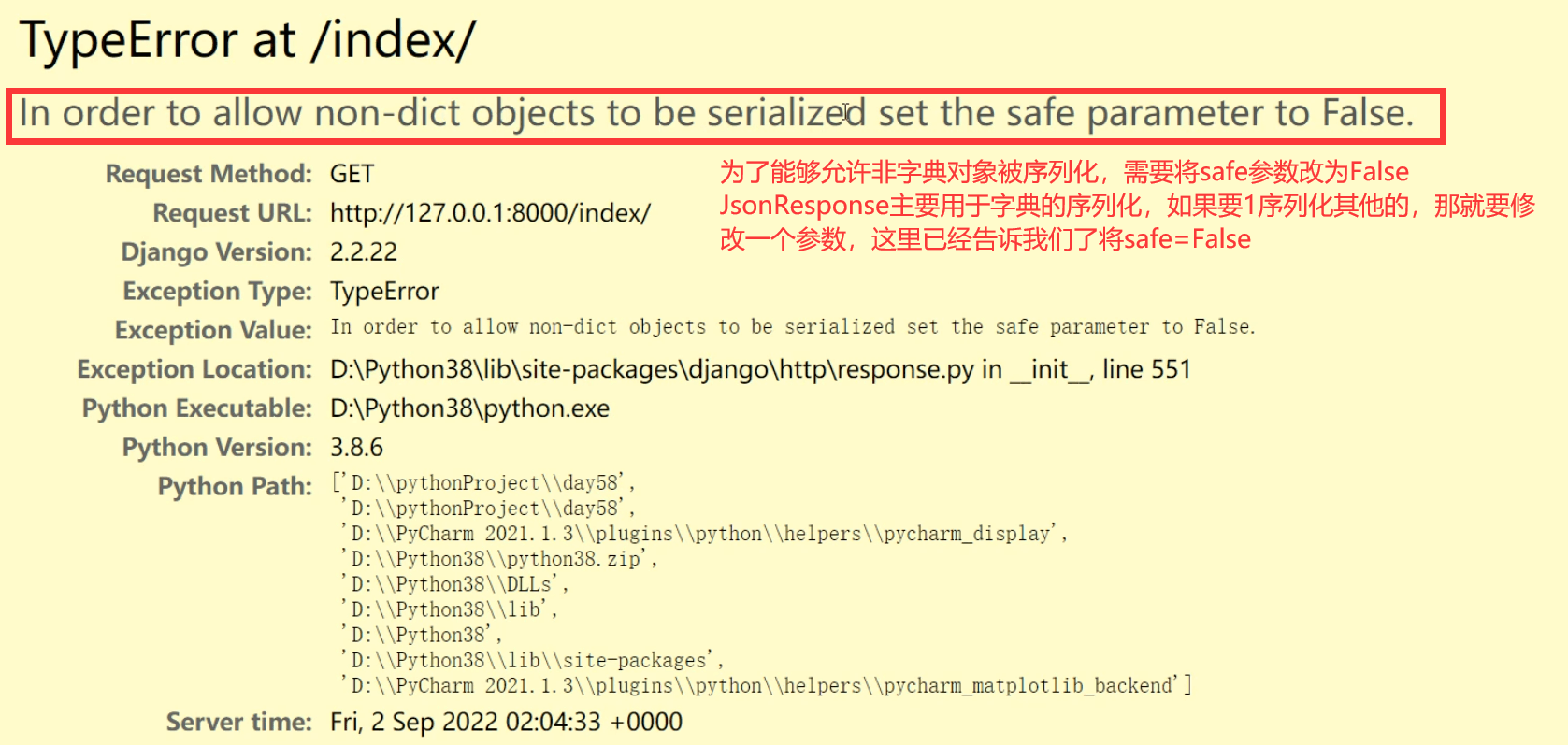
if safe and not isinstance(data, dict):
raise TypeError(
'In order to allow non-dict objects to be serialized set the '
'safe parameter to False.'
)
if json_dumps_params is None:
# 对应开始json_dumps_params=None,
json_dumps_params = {}
# 如果我们在这里传入了一个值,那么这里的json_dumps_params = {'XXX':'XXX'},然后在下面的data里面转换为的是关键字参数,XXX=XX
kwargs.setdefault('content_type', 'application/json')
'''
将data数据进行了json序列化,然后做了一个返回
**json_dumps_param,**加在字典前面,现在是在调用一个函数,那么它在这里做实参,**在是实参中将字典打散为关键字参数形式,就是什么等于什么
'''
data = json.dumps(data, cls=encoder, **json_dumps_params)
super().__init__(content=data, **kwargs)

# 导入JsonResponse模块
from django.http import JsonResponse
def ab_json(request):
l = [111,222,333,444,555]
# 默认只能序列化字典 序列化其他需要加safe参数 safe=False
return JsonResponse(l,safe=False)
import json
'''支持的数据类型:str,list, tuple, dict, set'''
# 序列化出来的数据是可以看得懂的,就是一个字符串
dumps 将Python对象转换成json字符串
loads
dump 将Python对象写入json文件
load
import pickle
'''支持的数据类型:python中的所有数据类型'''
# 序列化出来的结果看不懂,因为结果是一个二进制
# pickle序列化出的来的数据只能在python中使用
dumps
loads
dump
load
FBV基于函数的视图(Function base view) 我们前面写的视图函数都是FBV
CBV基于类的视图(Class base view)
视图文件种除了用一系列的函数来对应处理客户端请求的数据逻辑外,还可以通过定义类来处理相应的逻辑。
# 视图函数既可以是函数也可以是类
def index(request):
return HttpResponse('index')
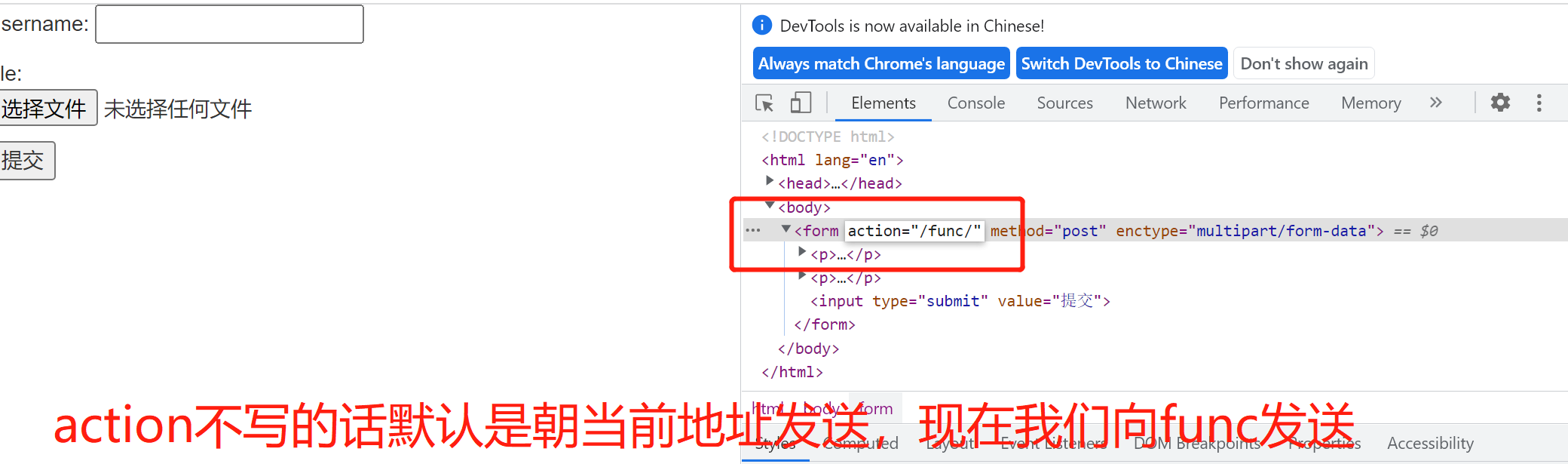
从index页面,后台修改action的参数,朝func发送post请求
点击提交以后自动出发了类里面的post方法

CBV比起FBV来说的话,不需要通过request.method来判断当前是什么请求,CBV会自动判断,是哪种请求,就去触发哪种方法(写在类里面里的函数叫做方法)
源码分析入口
path('func/', views.MyView.as_view())
"""
# 面向对象属性方法查找顺序
1.先从对象自己名称空间找
2.在去产生类对象的类里面找
3.在去父类里面找
"""
1.绑定给类的as_view方法(它是我们自己写的类里面继承的类)
class View:
@classonlymethod
def as_view(...):
绑定给类的,类调用会自动将类当作第一个参数传入
def view(...):
pass
return view
2.CBV路由匹配本质:跟FBV是一致的
path('func/', views.view)
3.访问func触发view执行
def view(...):
obj = cls() # 我们自己写的类加括号产生的对象
return obj.dispatch()
'''涉及到对象点名字 一定要确定对象是谁 再确定查找顺序'''
4.研究dispatch方法
def dispatch(...):
判断 request.method将当前请求方式转成小写 在不在 self内 self==MyLogin
"http_method_names 内有八个请求方式 合法"
['get', 'post', 'put', 'patch', 'delete', 'head', 'options', 'trace']
if request.method.lower() in self.http_method_names:
# getattr 反射: 通过字符串来操作对象的属性或者方法
func_name = getattr(obj,request.method.lower())
else:
handler = self.http_method_not_allowed
return handler(request, *args, **kwargs)
用到了一个反射的知识,从obj这个对象里面,找一个request.method.lower()这个的函数
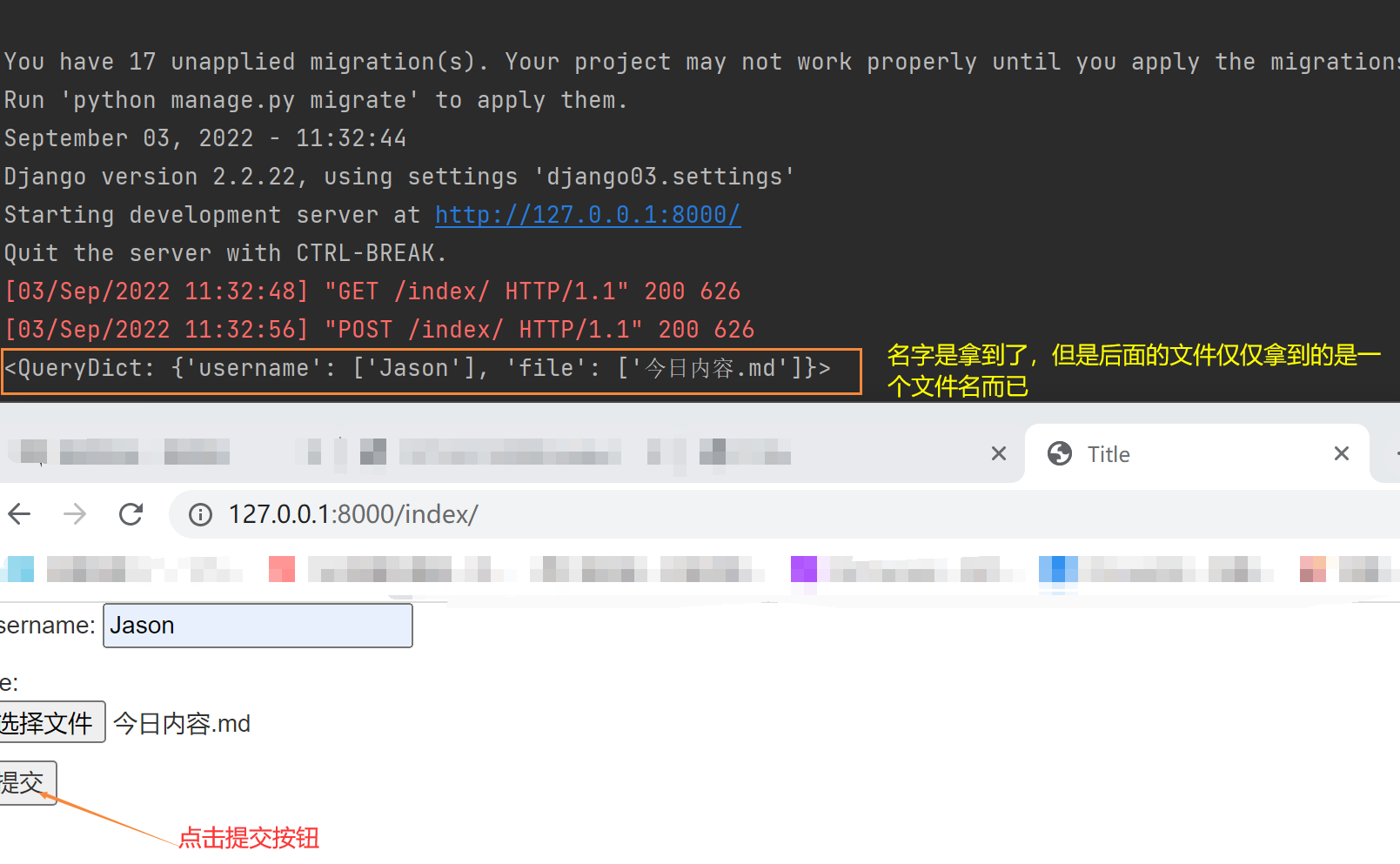
form表单如何携带数据文件需要注意满足以下俩个要求
1.method属性值必须是post
2.enctype属性值必须是multipart/form-data
后端获取文件数据的操作,request对象方法
1.获取请求方式POST/GET
request.method
一个字符串,表示请求使用的HTTP 方法。必须使用大写。
2.request.POST
获取POST请求提交普通的键值对数据 一个类似于字典的对象,如果请求中包含表单数据,则将这些数据封装成
3.获取GET请求
request.GET
获取GET请求 一个类似于字典的对象,包含 HTTP GET 的所有参数
4.获取文件
request.FILES
一个类似于字典的对象,包含所有的上传文件信息。
FILES 中的每个键为<input type="file" name="" /> 中的name,值则为对应的数据。
注意,FILES 只有在请求的方法为POST 且提交的<form> 带有enctype="multipart/form-data" 的情况下才会包含数据。否则,FILES 将为一个空的类似于字典的对象。
5.原生的浏览器发过来的二进制数据
request.body
一个字符串,代表请求报文的主体。在处理非 HTTP 形式的报文时非常有用,
例如:二进制图片、XML,Json等。
6.拿到路由
request.path
print(request.path) # /app01/index/
个字符串,表示请求的路径组件(不含域名)
7.拿到路由
request.path_info
print(request.path_info) # /app01/index/
8.能过获取完整的url及问号后面的参数
request.get_full_path()
print(request.get_full_path()) # /app01/index/?username=jason
实际案例展示
import json
from django.shortcuts import render, HttpResponse, redirect
from django.http import JsonResponse
# Create your views here.
def index(request):
# user_dict = {'name': 'jason老师', 'pwd': 123, 'hobby': ['read', 'run', 'music']}
# # json_str = json.dumps(user_dict, ensure_ascii=False)
# return JsonResponse(user_dict, json_dumps_params={'ensure_ascii':False}) # 直接写入JsonResponse,不需要去做json序列化操作
#
# # user_dict,json_dumps_params={'ensure_ascii':False} :解决前端中文转码问题
if request.method == 'POST':
# 普通的键值对形式的数据
print(request.POST)
# 专门用来携带过来的文件数据,流式的文件数据
print(request.FILES) # <MultiValueDict: {'file': [<InMemoryUploadedFile: 今日内容.md (application/octet-stream)>]}>
# 也可以取到这个文件,注意它也是一个Dict,可以通过点的方式得到,'file'由前端的name标签决定
file_obj = request.FILES.get('file')
# 可以使用这个对象去点出一些方法
print(file_obj.name)
# 也可以将这个文件保存下来,这个文件可以是文本文件,也可以是音频文件,只不过pycharm不能拿播放音频文件
with open(file_obj.name, 'wb') as f:
for line in file_obj:
f.write(line)
return render(request, 'index.html')
方式一:指名道姓的传
urls代码:
path('modal/', views.modal)
views代码:
def modal(request):
name = 'jason'
return render(request, 'modal.html', {'name':name})
指名道姓传参 不浪费资源
方式二:关键字locals()
html代码:
<body>
{{ name }}
{{ age }}
{{ gender }}
</body>
urls代码:
path('modal/', views.modal)
views代码:
def modal(request):
name = 'jason'
age = 18
gender = 'female'
return render(request, 'modal.html', locals()) # 将函数体里局部空间里所有的名字全部传入给前面的那个页面
将整个局部名称空间中的名字去全部传入简单快捷
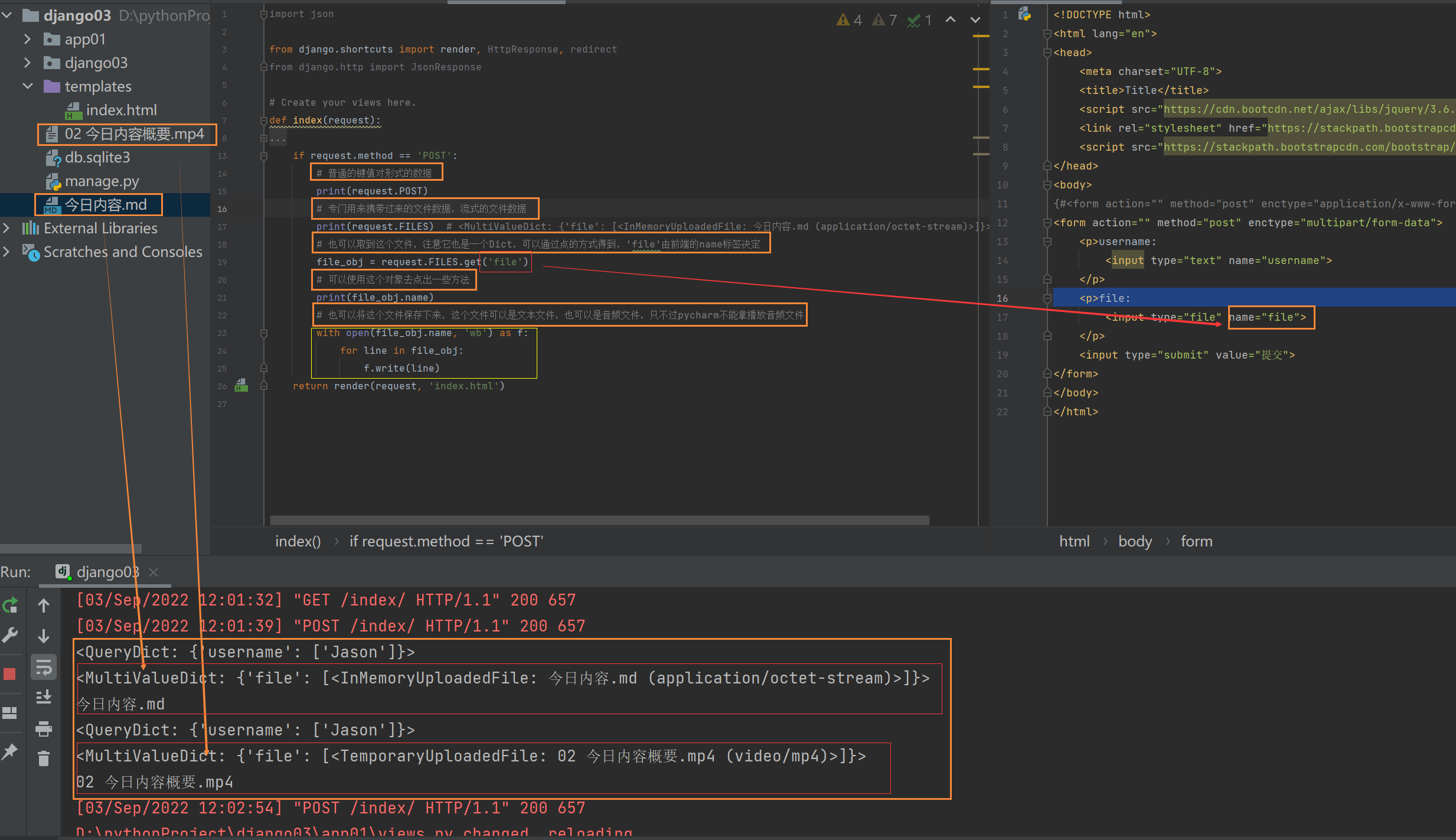
基本数据类型直接传递使用
views代码
def modal(request):
i = 123
f = 13.4
s = 'study work hard'
d = {'name': 'Tony', 'pwd': 123}
t = (11, 22, 33)
se = {11, 22, 33}
b = True
return render(request, 'modal.html', locals())
html代码
<body>
<p>{{ i }}</p>
<p>{{ f }}</p>
<p>{{ s }}</p>
<p>{{ l }}</p>
<p>{{ d }}</p>
<p>{{ t }}</p>
<p>{{ se }}</p>
<p>{{ b }}</p>
</body>
函数名的传递会自动加括号执行并将返回值展示到页面上,注意函数如果有参数则不会执行也不会展示 模板语法不支持有参函数
views代码
def modal(request):
def func1():
print('函数')
return '这里才能传过去值哦'
return render(request, 'modal.html', locals())
html代码
<body>
{#传递函数名会自动加括号调用 但是模板语法不支持给函数传额外的参数#}
<p>{{ func1 }}</p>
</body>


类名的传递也会自动加括号产生对象并展示到页面上,对象的传递则直接使用即可,对象默认情况下不可以加括号了,除非自己写__call__方法,模板语法会判断每一个名字是否可调用 如果可以则调用!!!
views代码
class MyClass(object):
def get_obj(self):
return 'obj'
@classmethod
def get_cls(cls):
return 'cls'
@staticmethod
def get_func():
return 'func'
obj = MyClass()'
return render(request, 'modal.html', locals())
html代码
<body>
{#传类名的时候也会自动加括号调用(实列化) 生成对象#}
<p>{{ MyClass }}</p>
{#内部能够自动判断出当前的变量名是否可以加括号调用 如果可以就会自动执行 针对的是函数名和类名#}
<p>{{ obj }}</p>
{#模板语法支持对象调用类方法#}
<p>{{ obj.get_self }}</p>
<p>{{ obj.get_func }}</p>
<p>{{ obj.get_class }}</p>
</body>

django的模板语法在操作容器类型的时候只允许使用句点符,既可以点键,也可以点索引
.key
.index
.key.index.index.key
过滤器就类似于是模板语法内置的 内置方法
模板语法提供了一些内置方法,以助于快速的处理数据(过滤器最多只能有两个参数)
{{ 变量|过滤器:参数}}
过滤器:会自动将竖杠左侧的变量当做第一个参数交给过滤器处理,右侧的当做第二个参数。
<p>统计长度:{{ s|length }}</p>
# 统计长度:15
<p>加法运算:{{ i|add:123 }}、加法运算:{{ s|add:'heiheihei' }}</p>
# 加法运算:246、字符串加法运算:study work hard +every day
<p>日期转换:{{ s|date:'Y-m-d H:i:s' }}</p>
<p>文件大小:{{ file_size|filesizeformat }}</p>
# 文件大小:31.1 KB
<p>数据切片:{{ l|slice:'0:10' }}</p>
# 切片操作(支持步长)
<p>字符截取(三个点算一个):{{ s1|truncatechars:6 }}</p>
# 字符截取(包含三个点):模板语法提供...
<p>单词截取(空格):{{ s1|truncatewords:6 }}</p>
# 单词截取(不包含三个点 按照空格切):my name is objk my age is 18 and ...
<p>语法转义:{{ script_tag }}</p>
# <h1>今晚晚饭又有好多好吃的了</h1>(是不会识别前端标签的)
<p>语法转义:{{ script_tag|safe }}</p>
# 今晚晚饭又有好多好吃的了
# 如果不转移的话,那么无法识别前端标签,那么以下这种功能的情况就没有办法实现
<p>语法转义:{{ script_tag1|safe }}</p>
script_tag1 = '<script>alert(666)</script>'
# 也可以使用后端转
from django.utils.safestring import mark_safe
script_tag2 = '<script>alert(666)</script>'
res = mark_safe(script_tag2)
ps:有时候html页面上的数据不一定非要在html页面上编写了 也可以后端写好传入
'''django模板语法中的符号就两个 一个{{}} 一个{%%}
需要使用数据的时候 {{}}
需要使用方法的时候 {%%}
'''
<body>
{% if 条件 %} 条件一般是模板语法传过来的数据 直接写名字使用即可
条件成立执行的代码
{% elif 条件1 %}
条件1成立执行的代码
{% else %}
条件都不成立执行的代码
{% endif %}
</body>
forloop 模板语法自带的变量名
{% for i in s %}
{% if forloop.first %}
<p>这是第一次哟~</p>
{% elif forloop.last %}
<p>这是最后一次!</p>
{% else %}
<p>{{ i }}</p>
{% endif %}
{% empty %}
<p>empty专门用来判断空的时候,当in后面是空的时候执行这个,给予提示</p>
{% endfor %}
解析:
forloop内置对象:运行结果解析
'counter0': 从0开始计数
'counter' : 从1开始计数
'first': True,判断循环的开始
'last' : Tues,判断循环的结束

# with起别名
{% with d.hobby.3.info as nb %}
<p>{{ nb }}</p>
在with语法内就可以通过as后面的别名快速的使用到前面非常复杂获取数据的方式
<p>{{ d.hobby.3.info }}</p>
{% endwith %}
解析:
可以通过as后面的别名快速的使用到前面非常复杂获取数据的方式
取别名后原来的名字也能正常使用
命名规范: 只能在with代码块儿的范围之内才能使用别名
1.在应用下创建一个名为templatetags文件夹
2.在该文件夹创建任意名称的py文件
3.在该py文件内编写自定义相关代码
from django.template import Library
register = Library()

# mytag.py
from django import template
register = template.Library()
# 参数 过滤器 过滤器名字
@register.filter(name='myfiltermyfilter')
def my_add(a, b):
return a + b
# index.html页面使用
加载自定义文件名
{% load mytag %}
<p>{{ i|myfilter:1 }}</p>
# 参数 标签(函数)标签(函数)名字
@register.simple_tag(name='mt')
def func(a, b, c, d):
return a + b + c + d
加载自定义文件名
{% load mytag %}
{% mt 1 2 3 4 %}
当html页面某一个地方的页面需要传参数才能够动态的渲染出来,并且在多个页面上都需要使用到该局部
@register.inclusion_tag(filename='it.html')
def index(n):
html = []
for i in range(n):
html.append('第%s页'%i)
return locals() # 将html传给filename这个页面,然后可以在那个页面上使用
加载自定义文件名
{% load mytag %}
{% index 10 %}
filename是作用于一个页面,这个页面可以不是一个完整的页面,只是一部分,
你需要事先在你想要使用的主页面上划定区域做好标记,之后在子页面继承的时候你就可以使用在主页面划定的区域,也就意味着,如果你不划定任何区域,那么你子页面将无法修改主页面内容
1.先在你想要继承的主页面上通过bolck划定你将来可能要改的区域,并做好标记
2.在子页面上继承extends,利用block自动提示选取你想要修改的内容区域标记名称
3.在子页面extends中写你要修改主页面标记区的代码
4.然后就可以让子页面的修改内容渲染到主页面的划定区域上
# 模板页面提前先写好将来可能要替换的内容
{% block 名字 %}
"""模板内容"""
{% endblock %}
# 新页面要基于模板页面替换的内容
{% extends 'html文件名' %}
{% block 名字 %}
"""子板内容"""
{% endblock %}
"""一般情况下母板中至少应该有三个区域使得扩展性更高!!! css content js"""
{% block css %}
<style>...</style>
{% endblock %}
{% block content %}
...
{% endblock %}
{% block js %}
<script>...</script>
{% endblock %}
'''子板中还可以使用母板的内容 {{ block.super }} '''
将页面的某一个局部当成模块的形式
哪个地方需要就可以直接导入使用即可
{% include '导入html文件名' %}
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl