对于ElasticSearch比较陌生的小伙伴可以先看看ElasticSearch的概述ElasticSearch安装、启动、操作及概念简介
好的开始啦~
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
新版本配置方式(推荐使用)
新的配置方式使用的是 High Level REST Client 的方式来替代之前的 Transport Client 方式,使用的是 HTTP 请求,和 Kibana 一样使用的是 Elasticsearch 的 9200 端口。
这种配置方案中,你使用的不是配置文件,而是自定义配置类:
/**
* 你也可以不继承 AbstractElasticsearchConfiguration 类,而将 ESConfig 写成一般的配置类的型式。
* 不过继承 AbstractElasticsearchConfiguration 好处在于,它已经帮我们配置好了 elasticsearchTemplate 直接使用。
*/
@Configuration
public class ESConfig extends AbstractElasticsearchConfiguration {
@Override
public RestHighLevelClient elasticsearchClient() {
ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("localhost:9200")
.build();
return RestClients.create(clientConfiguration).rest();
}
}
Elasticsearch 中的 PO 类:
@Document(indexName = "books",shards = 1,replicas = 0)
@Data
@AllArgsConstructor
@NoArgsConstructor
public class ESBook {
@Id
@Field(type = FieldType.Keyword)
private String id;
@Field(type = FieldType.Text)
private String title;
@Field(type = FieldType.Keyword)
private String language;
@Field(type = FieldType.Keyword)
private String author;
@Field(type = FieldType.Float)
private Float price;
@Field(type = FieldType.Text)
private String description;
}
@Repository
//看实体类Id索引是什么类型 我这里是String
public interface ESBookRepstitory extends ElasticsearchRepository<ESBook, String> {
}
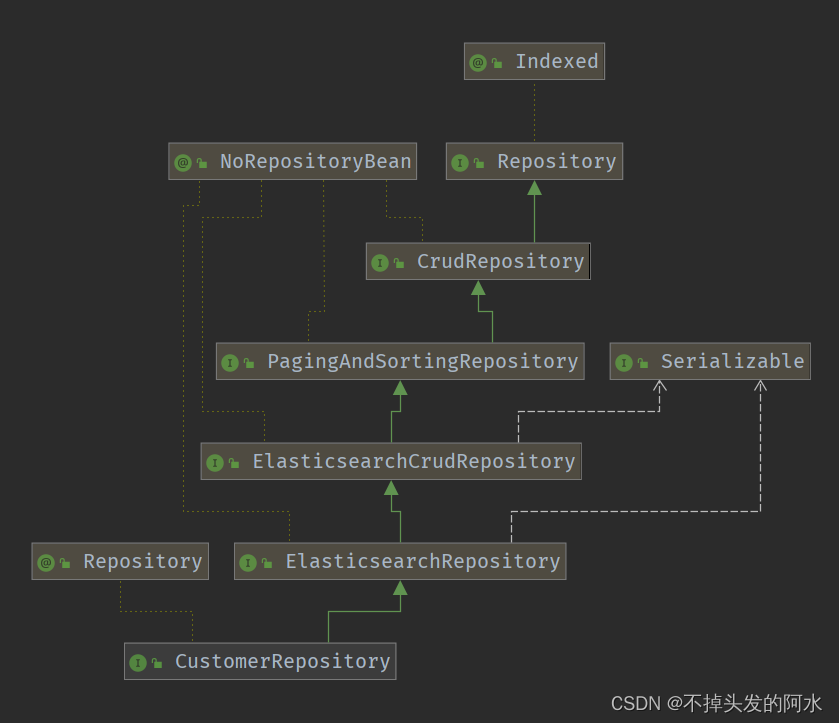
我们自定义的 CustomerRepository 接口,从它的祖先们那里继承了大量的现成的方法,除此之外,它还可以按 spring data 的规则定义特定的方法。
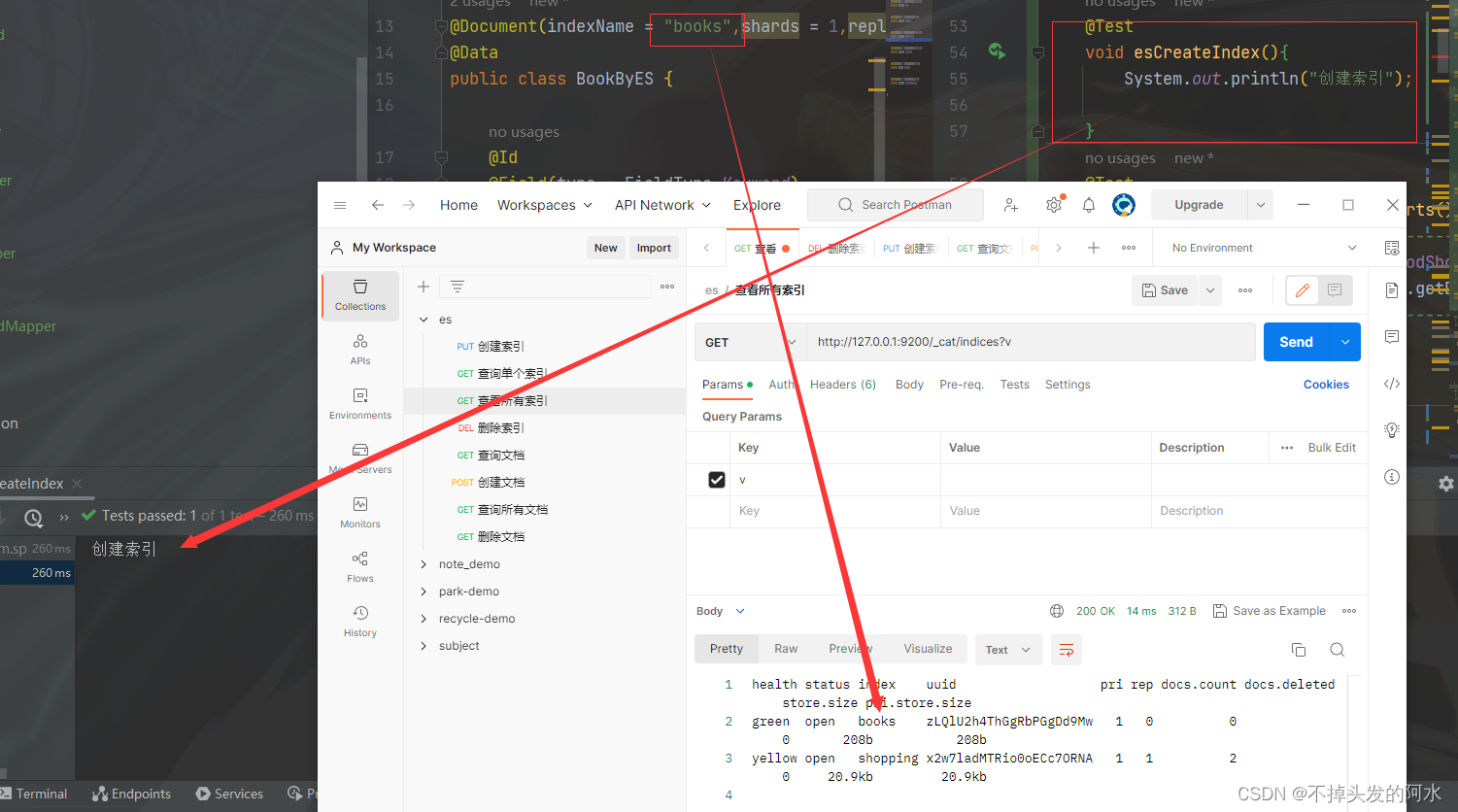
// 创建索引
@Test
public void indexList() {
System.out.println("创建索引");
}
// 删除索引
@Test
public void indexList() {
restTemplate.indexOps(IndexCoordinates.of("books")).delete();
System.out.println("删除索引");
}
@Autowired
private ESBookRepstitory bookByESRepstitory;
@Test
public void indexList() {
List<ESBook> lists = new ArrayList<>();
lists.add(new ESBook("1", "Java 程序设计", "汉语", "盖伦",
18.88F, "哈哈嗨"));
lists.add(new ESBook("2", "Python程序设计", "英语", "赵信",
66.88F, "陷阵之至有死无生"));
lists.add(new ESBook("3", "PHP 程序设计", "俄语", "宝石",
88.88F, "我曾踏足山巅,也曾跌入低谷"));
bookByESRepstitory.saveAll(lists);
}
id重复的话 会覆盖之前的~~~
修改和新增是同一个接口,区分的依据就是id,这一点跟我们在页面发起PUT请求是类似的。
ESBook ESBook = new ESBook("3", "宝石 程序设计", "俄语", "宝石",
88.88F, "我曾踏足山巅,也曾跌入低谷");
bookByESRepstitory.save(ESBook);
//由于上面的id = 3 已经存在,故再次save 就是修改
@Test
public void test2(){
bookByESRepstitory.deleteById("1");
bookByESRepstitory.deleteAll();
}
@Test
public void testQuery(){
Optional<BookByES> optionalById = this.bookByESRepstitory.findById("1");
System.out.println(optionalById.get());
}
@Test
public void testFind(){
// 查询全部,并按照价格降序排序
//写法一:
Iterable<BookByES> items = this.bookByESRepstitory.findAll(Sort.by(Sort.Direction.DESC,
"price"));
//写法二:
Iterable<BookByES> items1 = this.bookByESRepstitory.findAll(Sort.by(Sort.Order.desc("price")));
}
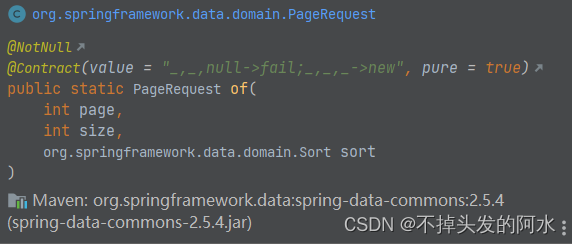
Spring Data 自带的分页方案:
@Test
public void testByPage(){
Sort sort = Sort.by(Sort.Direction.DESC,"id");
//分页
PageRequest pageRequest = PageRequest.of(0, 2, sort);
Page<BookByES> all = bookByESRepstitory.findAll(pageRequest);
for (BookByES bookByES : all) {
System.out.println(bookByES);
}
}
Spring Data 的另一个强大功能,是根据方法名称自动实现功能。
比如:你的方法名叫做:findByTitle,那么它就知道你是根据title查询,然后自动帮你完成,无需写实现类。
当然,方法名称要符合一定的约定
| Keyword | Sample | Elasticsearch Query String |
|---|---|---|
And | findByNameAndPrice | {"bool" : {"must" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
Or | findByNameOrPrice | {"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
Is | findByName | {"bool" : {"must" : {"field" : {"name" : "?"}}}} |
Not | findByNameNot | {"bool" : {"must_not" : {"field" : {"name" : "?"}}}} |
Between | findByPriceBetween | {"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
LessThanEqual | findByPriceLessThan | {"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
GreaterThanEqual | findByPriceGreaterThan | {"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
Before | findByPriceBefore | {"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
After | findByPriceAfter | {"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
Like | findByNameLike | {"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
StartingWith | findByNameStartingWith | {"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
EndingWith | findByNameEndingWith | {"bool" : {"must" : {"field" : {"name" : {"query" : "*?","analyze_wildcard" : true}}}}} |
Contains/Containing | findByNameContaining | {"bool" : {"must" : {"field" : {"name" : {"query" : "**?**","analyze_wildcard" : true}}}}} |
In | findByNameIn(Collection<String>names) | {"bool" : {"must" : {"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"name" : "?"}} ]}}}} |
NotIn | findByNameNotIn(Collection<String>names) | {"bool" : {"must_not" : {"bool" : {"should" : {"field" : {"name" : "?"}}}}}} |
Near | findByStoreNear | Not Supported Yet ! |
True | findByAvailableTrue | {"bool" : {"must" : {"field" : {"available" : true}}}} |
False | findByAvailableFalse | {"bool" : {"must" : {"field" : {"available" : false}}}} |
OrderBy | findByAvailableTrueOrderByNameDesc | {"sort" : [{ "name" : {"order" : "desc"} }],"bool" : {"must" : {"field" : {"available" : true}}}} |
如:
import com.springsecurity.domain.ESBook;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
import java.util.List;
/**
* @author 阿水
* @create 2023-04-13 11:05
*/
@Repository
//看实体类Id索引是什么类型 我这里是String
public interface ESBookRepstitory extends ElasticsearchRepository<ESBook, String> {
/**
* 根据描述查询书籍,带分页的
* @param description
* @return
*/
List<ESBook> findESBookByDescription(String description, Pageable variable);
/**
* 根据作者和描述和标题查
*/
List<ESBook> queryESBookByAuthorAndDescriptionOrTitle(String author,String description,String title);
/**
* 根据书的价格范围查询
*/
List<ESBook> queryESBookByPriceBetween(Float price1,Float price2);
}
@Test
void esQueryCondition() {
Sort sort = Sort.by(Sort.Order.desc("id"));
PageRequest pageRequest = PageRequest.of(0, 2, sort);
List<ESBook> EBooks = bookByESRepstitory.findESBookByDescription("我",pageRequest);
for (ESBook bookByE : EBooks) {
System.out.println(bookByE);
}
}
@Test
void esQueryCondition2() {
List<ESBook> esBooks = bookByESRepstitory.queryESBookByAuthorAndDescriptionOrTitle("盖伦", "哈嗨", "程序");
for (ESBook book : esBooks) {
System.out.println(book);
}
}
@Test
void esQueryCondition3() {
List<ESBook> esBooks = bookByESRepstitory.queryESBookByPriceBetween(18.88F,77.88F);
for (ESBook book : esBooks) {
System.out.println(book);
}
}
@Autowired
private ElasticsearchRestTemplate restTemplate;
QueryBuilders.queryStringQuery() #指定字符串作为关键词查询,关键词支持分词
QueryBuilders.queryStringQuery("华为手机").defaultField("description");
//不指定feild,查询范围为所有feild
QueryBuilders.queryStringQuery("华为手机");
//指定多个feild
QueryBuilders.queryStringQuery("华为手机").field("title").field("description");
QueryBuilders.boolQuery #子方法must可多条件联查
QueryBuilders.termQuery #精确查询指定字段不支持分词
QueryBuilders.termQuery("description", "华为手机")
QueryBuilders.matchQuery #按分词器进行模糊查询支持分词
QueryBuilders.matchQuery("description", "华为手机")
QueryBuilders.rangeQuery #按指定字段进行区间范围查询
- `QueryBuilders.boolQuery()`
- `QueryBuilders.boolQuery().must()`:相当于 and
- `QueryBuilders.boolQuery().should()`:相当于 or
- `QueryBuilders.boolQuery().mustNot()`:相当于 not
- ——————————————————————————————————————————————————————————————————————————————————————————————————————
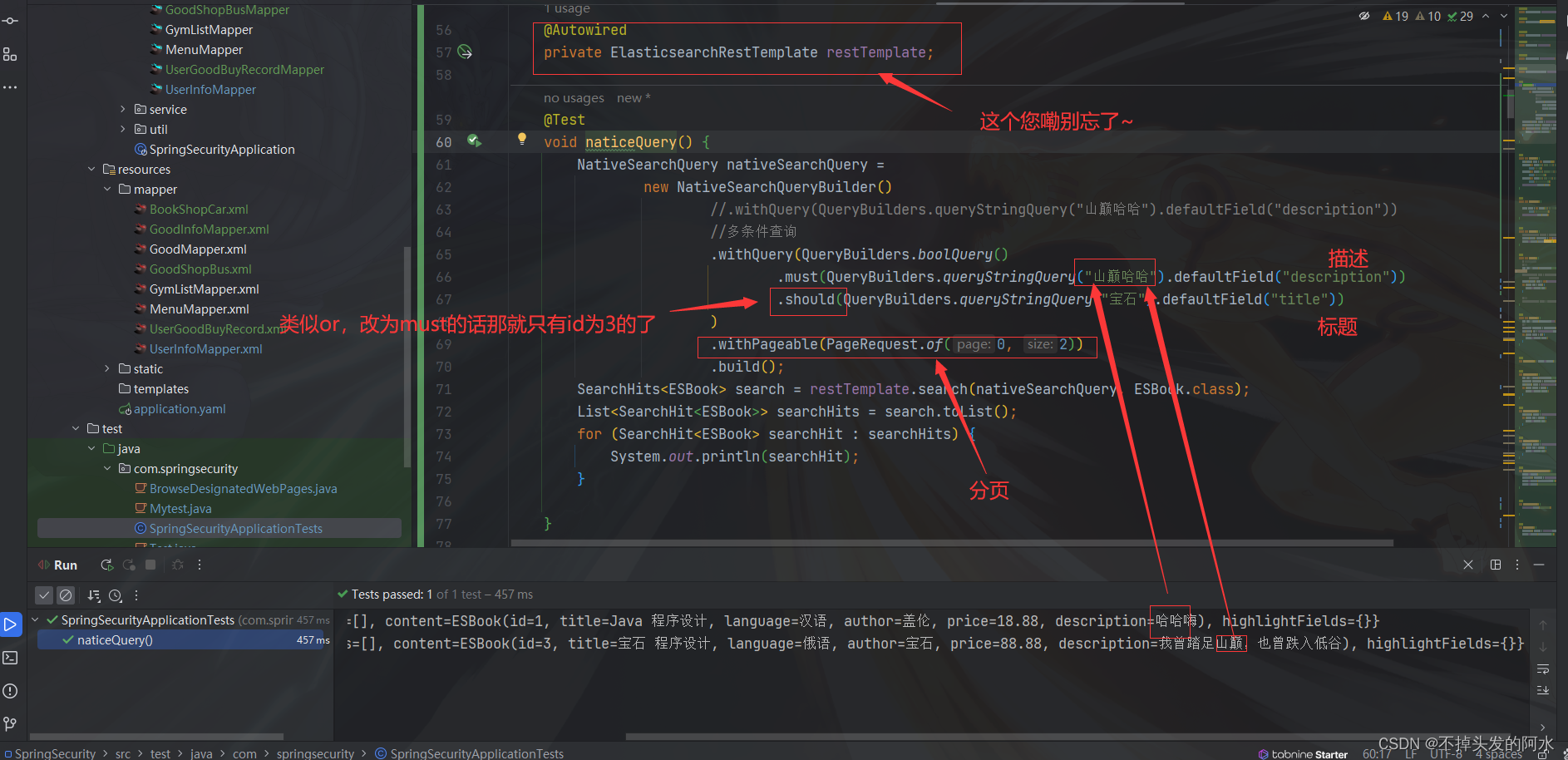
@Test
void naticeQuery() {
NativeSearchQuery nativeSearchQuery =
new NativeSearchQueryBuilder()
//.withQuery(QueryBuilders.queryStringQuery("山巅哈哈").defaultField("description"))
//多条件查询
.withQuery(QueryBuilders.boolQuery()
.must(QueryBuilders.queryStringQuery("山巅哈哈").defaultField("description"))
.should(QueryBuilders.queryStringQuery("宝石").defaultField("title"))
)
.withPageable(PageRequest.of(0, 2))
.build();
SearchHits<ESBook> search = restTemplate.search(nativeSearchQuery, ESBook.class);
List<SearchHit<ESBook>> searchHits = search.toList();
for (SearchHit<ESBook> searchHit : searchHits) {
System.out.println(searchHit);
}
}
举个例子:
场景一:对外暴露的数据(数据量大的)的用es,如果不需要对外暴露,不需要全文检索的话,那么直接从数据查,所以做项目分析数据分成2块(哪些数据需要放es,从es查,哪些不需要)
场景二:作为mysql的外置索引,把作为数据库查询条件的列数据放到es里面,这样在查询的时候,先从es查询出符合条件的id,然后根据id去数据库查,数据维护大,一旦es宕机,就麻烦了
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
我一直很高兴地使用DelayedJob习惯用法:foo.send_later(:bar)这会调用DelayedJob进程中对象foo的方法bar。我一直在使用DaemonSpawn在我的服务器上启动DelayedJob进程。但是...如果foo抛出异常,Hoptoad不会捕获它。这是任何这些包中的错误...还是我需要更改某些配置...或者我是否需要在DS或DJ中插入一些异常处理来调用Hoptoad通知程序?回应下面的第一条评论。classDelayedJobWorker 最佳答案 尝试monkeypatchingDelayed::W
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
三分钟集成Tap防沉迷SDK(Unity版)一、SDK介绍基于国家对上线所有游戏必须增加防沉迷功能的政策下,TapTap推出防沉迷SDK,供游戏开发者进行接入;允许未成年用户在周五、六、日以及法定节假日晚上8:00-9:00进行游戏,防沉谜时间段进入游戏会弹窗进行提示!开发环境要求:Unity2019.4或更高版本iOS10或更高版本Android5.0(APIlevel21)或更高版本🔗Unity集成Demo参考链接🔗UnityTapSDK功能体验APK下载链接二、集成前准备1.创建应用进入开发者后台,按照提示开始创建应用;2.开通服务在使用TDS实名认证和防沉迷服务之前,需要在上面创建的应
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>
我被这个难住了。到目前为止教程中的一切都进行得很顺利,但是当我将这段代码添加到我的/spec/requests/users_spec.rb文件中时,事情开始变得糟糕:describe"success"doit"shouldmakeanewuser"dolambdadovisitsignup_pathfill_in"Name",:with=>"ExampleUser"fill_in"Email",:with=>"ryan@example.com"fill_in"Password",:with=>"foobar"fill_in"Confirmation",:with=>"foobar"cl
我有一个Rails应用程序,现在设置了ElasticSearch和Tiregem以在模型上进行搜索,我想知道我应该如何设置我的应用程序以对模型中的某些索引进行模糊字符串匹配。我将我的模型设置为索引标题、描述等内容,但我想对其中一些进行模糊字符串匹配,但我不确定在何处进行此操作。如果您想发表评论,我将在下面包含我的代码!谢谢!在Controller中:defsearch@resource=Resource.search(params[:q],:page=>(params[:page]||1),:per_page=>15,load:true)end在模型中:classResource'Us
我需要一些指导来了解如何将Angular整合到rails中。选择Rails的原因:我喜欢他们偏执的做事方式。还有迁移,gem真的很酷。使用angular的原因:我正在研究和寻找最适合SPA的框架。Backbone似乎太抽象了。我不得不在Angular和Ember之间做出选择。我首先开始阅读Angular,它对我来说很有意义。所以我从来没有去读过关于ember的文章。使用Angular和Rails的原因:我研究并尝试使用小型框架,例如grape、slim(是的,我也使用php)。但我觉得需要坚持项目的长期范围。我个人喜欢用Rails的方式做事。这就是我需要帮助的地方,我在Rails4中有
有没有人有在Maven中运行用Ruby编写的单元测试的经验。任何输入,如要使用的库/maven插件,将不胜感激!我们已经在使用Maven+hudson+Junit。但是我们正在引入Ruby单元测试,找不到任何同样好的组合。 最佳答案 我建议让Maven使用ExecMavenPlugin启动rake测试(exec:exec目标)并使用ci_reportergem生成单元测试结果的XML文件,Hudson、Bamboo等可以读取该文件,以与JUnit测试相同的格式显示测试结果。如果您不需要使用mvntest运行Ruby测试,您也可以只使