⭐️我叫忆_恒心,一名喜欢书写博客的在读研究生👨🎓。
如果觉得本文能帮到您,麻烦点个赞👍呗!
近期会不断在专栏里进行更新讲解博客~~~ 有什么问题的小伙伴 欢迎留言提问欧,喜欢的小伙伴给个三连支持一下呗。👍⭐️❤️
Qt5.9专栏定期更新Qt的一些项目Demo
项目与比赛专栏定期更新比赛的一些心得,面试项目常被问到的知识点。
⭐️最近在整理以前的学习资料时,看到了之前之前入门NLP的一些学习笔记,就进行了一些整理。

目录
各位同学,欢迎来到今天的课程!我们将会探索一门有趣且富有挑战性的领域——自然语言处理。在本次课程中,我将先介绍一下当下人工智能领域的热点,以此引出什么是什么是自然语言处理,以及它的应用,以及自然语言基石的“词向量
Word2Vec。
相信各位同学最近都听过ChatGPT,GPT-4,百度的文言一心甚至有些同学也已经玩上了这些工具,大家都知道这是人工智能的产物,但是ChatGPT有哪些功能,我们进行一个简单的介绍。
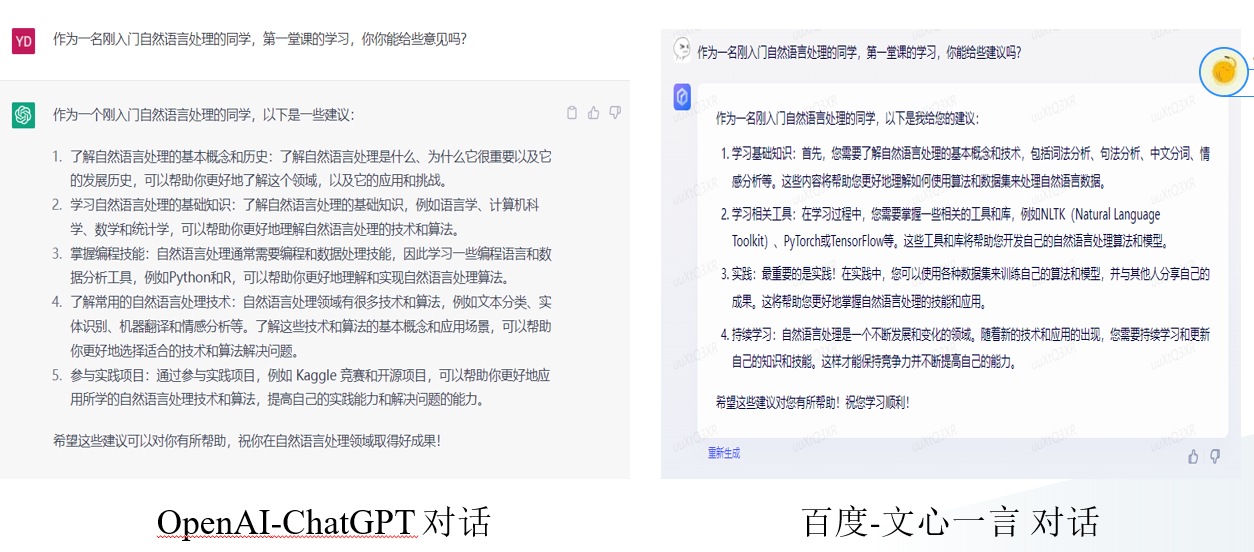
我们输入一句:
作为一名刚入门自然语言处理的同学,第一堂课的学习,你能给些建议吗?即使这个输入,可能含有错别字。
那这背后运用的是那些技术的呢?
是CV还是自然语言处理
上述设计到的模型所用的人工智能领域技术是自然语言处理,那么什么是自然语言处理呢?
我们来看一下维基百科上是如何进行定义的:
计算机科学与语言学领域交叉的一门学科,目的是让计算机能够理解、解释、生成人类语言。
这么说可能会优点抽象,简单来说就是:
自然语言处理 (Nautral Language Process, NLP) =自然语言理解(Natural Language Understand, NLU) + 自然语言生成
(Natural Language Generate, NLG)。
可能这在你看来是很神奇的一件事情,但其实ChatGPT也就做了这两部分的内容。
总的来说:NLP = NLU + NLR。
ChatGPT可以说是自然语言处理综合应用的一个典型的模型了

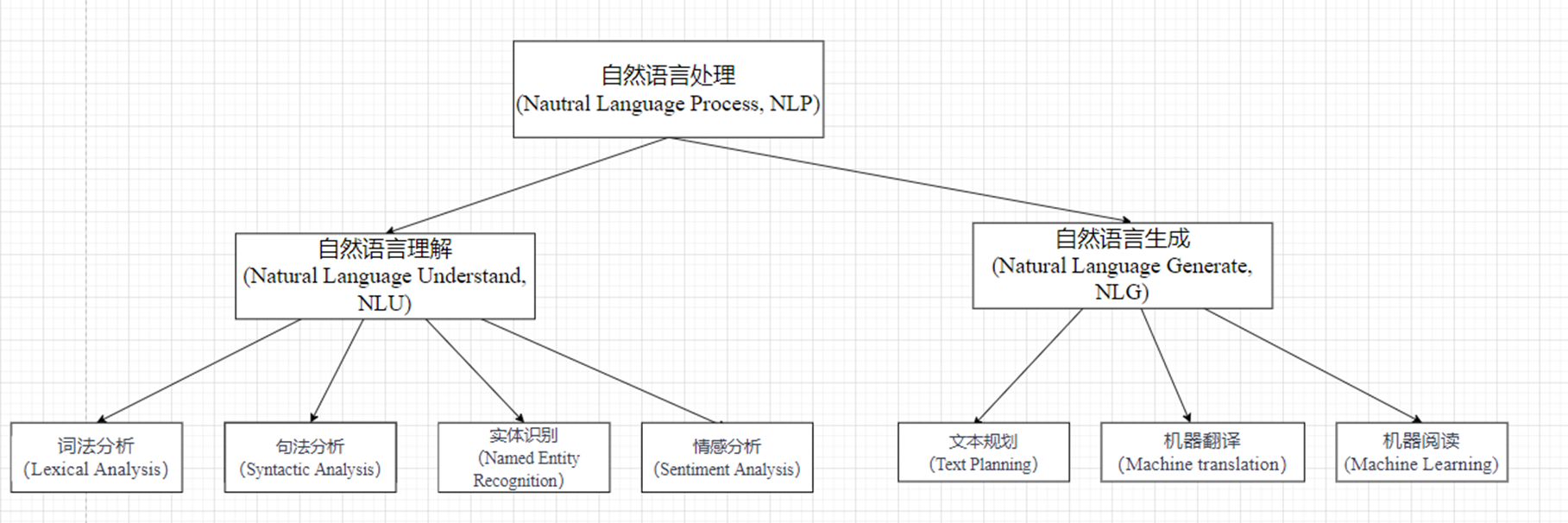
自然语言处理技术可以看出是两个阶段。
我们以ChatGPT为例,他是如何做到这些功能的呢?
(通过一个图 人–>电脑 电脑—人)
以ChatGPT为例,我们每一次向他输入一段话的时候,会发生哪些事情呢?
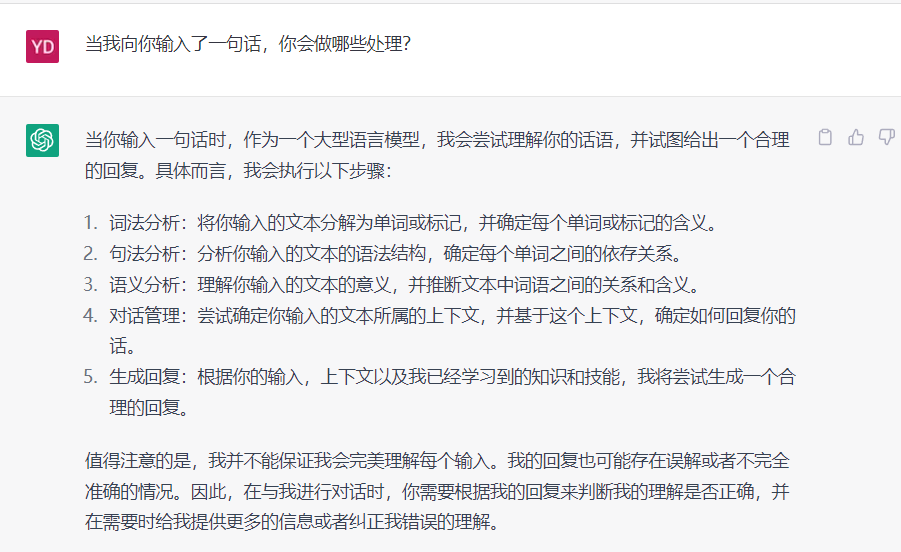
其中词法分析、句法分析、语义分析属于NLU任务,对话管理、生成回复属于NLG任务。
我门进行一个简单的小结。
与图像处理相比,自然语言处理更为复杂。
图像:所见即所得
文本:所要的文字背后的语义。
简单来说自然语言处理,普遍遇到以下三个问题:

万丈高楼平地起,接下来我们讲解一下自然语言处理的基石Word2Vec
自然语言处理以及语言模型的本质是词向量。
我们以问题为导向进行Word2Vec的学习。
Word2Vec从自然语言的发展趋势来看:
从词向量表示方法出现后,短短5年时间,自然语言处理就得到了大幅度进展(预训练语言模型BERT、GPT).。
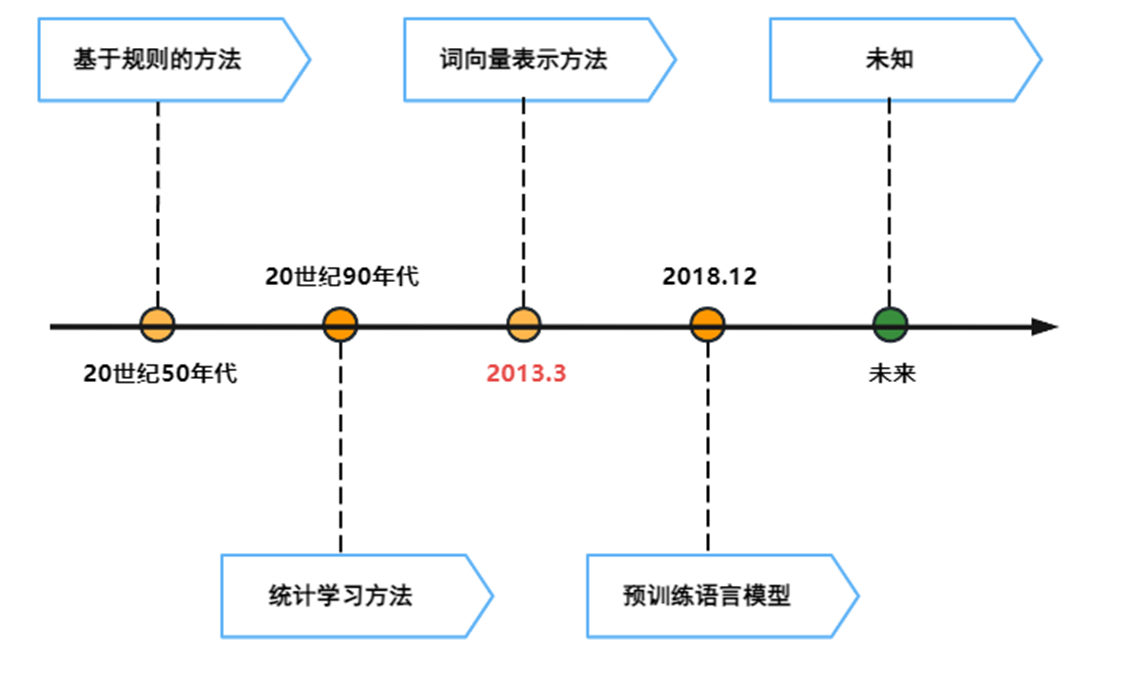
一句话或一个文章都是一个词一个词组成。
解决了基于规则和基于统计学习方法遗留的问题:
•输入词的语序问题。
•词之间相似性的问题。
基于统计的方法:
只看一个词的出现和总体的关系。
但是这种统计词频,避免不了一个问题,就是比如一个词出现在不同的位置,所表达的语义是不同的。如下面的例句。
Input1:我|要|学习|自然|语言|处理。
Input2:我|要|语言|自然|地|学习。
比如:
“自然语言处理”=“NLP”
但与“吃饭”无关。
不同语义的文字相似度应该低,相同语义的相似度高。
具体表现在二维空间上是
距离的疏远

相关性
越相近的表达离得越近 。
通过一些问题来解释。
这里有个前提大家先熟悉了神经网络,不过多强调神经网络而是把重点放到词向量模型中。
先考虑第一个问题:
看起来比较抽象,可以先从人的角度来观察。
比如说,现在来了一个人,我们应该如何对其进行描述呢?

对一个人进行打分,一个指标相当于一个维度****。
身高、性格、能力等综合特征多个维度构成了一个独特的人的描述。
当我们有了这种多个指标构成的多种维度时,我们就可以进行向量的运算。
比如相似度计算:
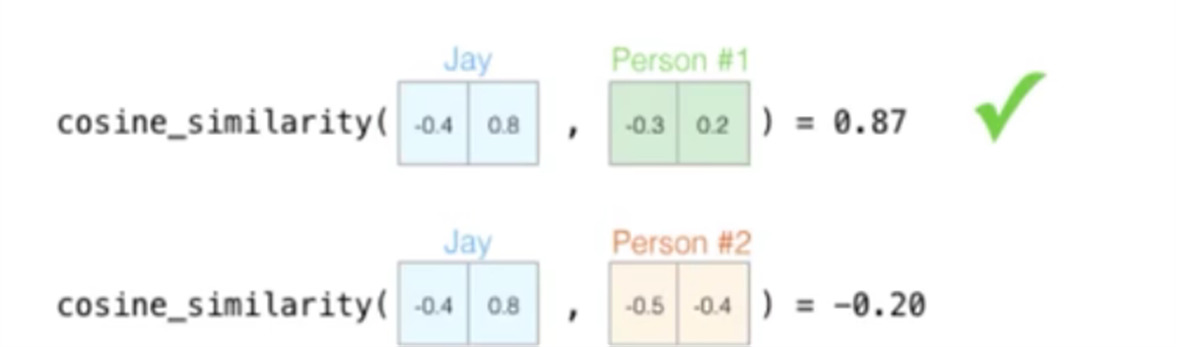
欧拉公式、余弦公式通过距离计算他们的相似度。
在实际的训练过程中,数据的维度越高,能提供的信息也就越多,从而计算结果的可靠性就更值得信赖。(通常为50-300维)


•输入:词的特征。
•黑盒:通过神经神经网络反向传播调整模型参数
•输出:下个单词的预测
我们来看一下一个整体的结果:
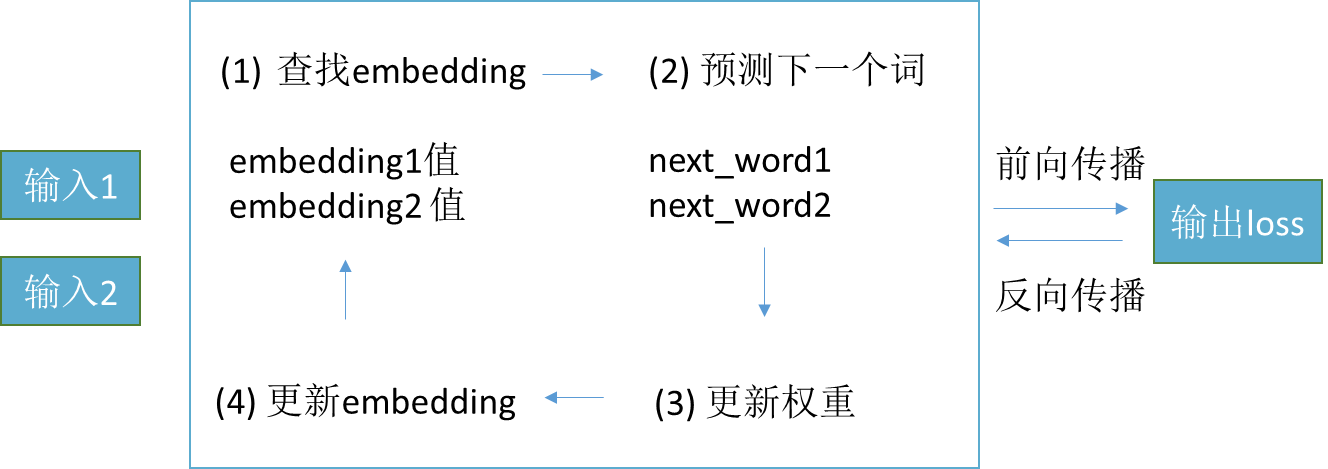
训练过程:
1.从embedding表中查找输入词的初始embedding值
2.通过神经网络来预测下一个值。
3.前向传播:求损失函数的值
4.反向传播:更新权重参数和输入的embedding值
输入:自然 语言 处理 包含 很多 任务
分为两个部分
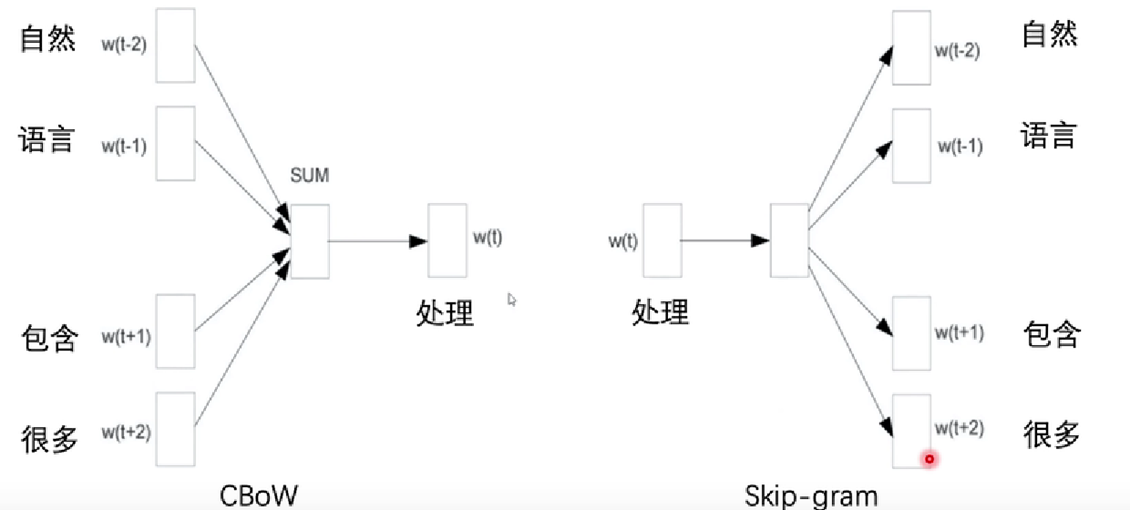
简单来说:
就是输入的不同,CBow,以上下文预测中渐次。Skip-gram 以一个中间词预测上下文。
输入:自然 语言 处理 包含 很多 任务
Window Size = 3
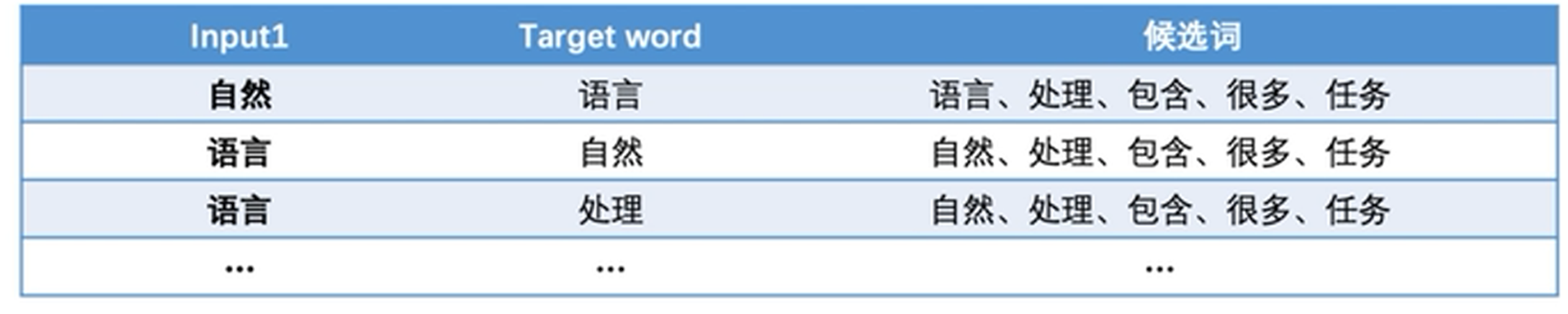
存在的问题:求解一个Length(corpus)的多分类问题。
解释:因为从预测结果来看,候选词为长度-1 个。
解决办法:将输入与输出同时作为输入,计算候选输出的概率。

解释:然而由于输入包含了输出的标签,预测目标全为1,因此模型进行乱猜导致无法训练。
由于训练过程只有正样本,导致模型训练无法收敛,因此可以适当添加错误的样本。
负采样(Negative Sample)方法:在输入样本中加入负样本(错误的样本)
输入:自然 语言 处理 包含 很多 任务

根据大量实验的经验值:负样本个数3-5个比较合适

输出Word2Vec下面是一个五十维的向量:

我们用热度图来判断他们之间的相似性

我们用热度图来判断他们之间的相似性,其中红色越深 关系越强。

假设我们已经训练好了词向量,
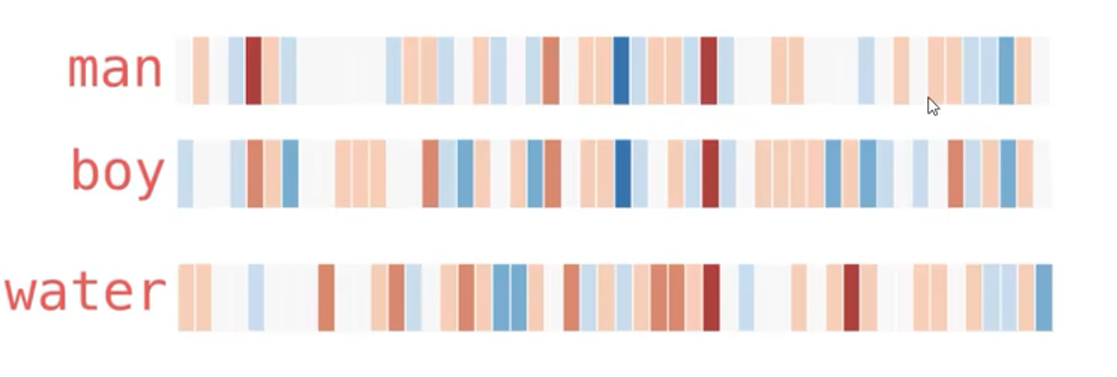
观察一下当前的词向量的相似性:
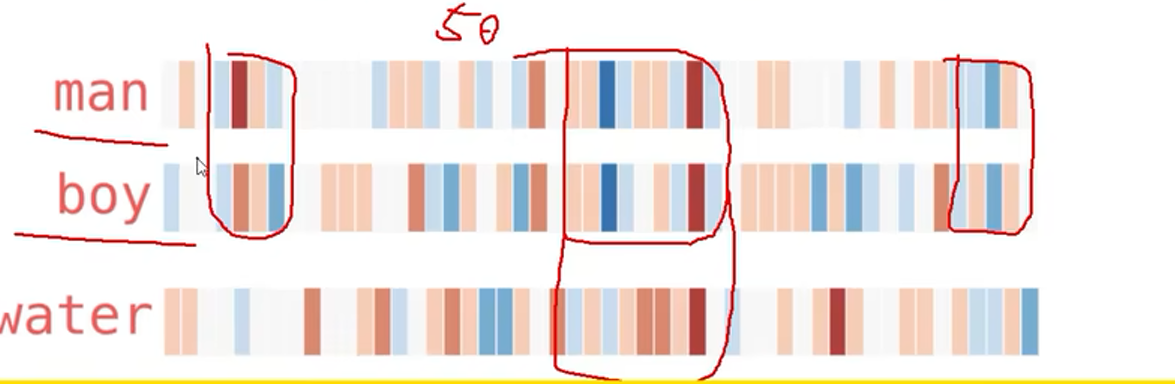
可以可视化的观察到,词向量的相关性。
最后,最后
如果觉得有用,麻烦三连👍⭐️❤️支持一下呀,希望这篇文章可以帮到你,你的点赞是我持续更新的动力
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
在控制台中反复尝试之后,我想到了这种方法,可以按发生日期对类似activerecord的(Mongoid)对象进行分组。我不确定这是完成此任务的最佳方法,但它确实有效。有没有人有更好的建议,或者这是一个很好的方法?#eventsisanarrayofactiverecord-likeobjectsthatincludeatimeattributeevents.map{|event|#converteventsarrayintoanarrayofhasheswiththedayofthemonthandtheevent{:number=>event.time.day,:event=>ev
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
这是一道面试题,我没有答对,但还是很好奇怎么解。你有N个人的大家庭,分别是1,2,3,...,N岁。你想给你的大家庭拍张照片。所有的家庭成员都排成一排。“我是家里的friend,建议家庭成员安排如下:”1岁的家庭成员坐在这一排的最左边。每两个坐在一起的家庭成员的年龄相差不得超过2岁。输入:整数N,1≤N≤55。输出:摄影师可以拍摄的照片数量。示例->输入:4,输出:4符合条件的数组:[1,2,3,4][1,2,4,3][1,3,2,4][1,3,4,2]另一个例子:输入:5输出:6符合条件的数组:[1,2,3,4,5][1,2,3,5,4][1,2,4,3,5][1,2,4,5,3][
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub