1)HTML报告的生成:测试报告最好要生成在一个特殊的目录下面
1)在python的lib文件下面添加文件是HTMLTestRunner.py文件:
self就是当前类中的实例
2)HTML报告的生成步骤:
2.1)解决HTML文件存放的问题:创建一个文件夹
2.2)HTML报告命名问题,如何进行动态命名,每一次生成的文件名称如何不一致?可以用当前的时间来进行命名?
import HTMLTestRunner import result from selenium import webdriver import time import unittest import sys import os class TestBaiDuThree(unittest.TestCase): def setUp(self): print("开始执行自动化测试") self.driver=webdriver.Edge("C://Users//18947//AppData//Local//Programs//Python//Python310//msedgedriver.exe") self.baseurl="http://www.baidu.com" self.driver.maximize_window() time.sleep(3) def tearDown(self): print("自动化测试执行完毕") self.driver.quit() def testXinWen(self): self.driver.get(self.baseurl) text=self.driver.find_element_by_link_text("新闻") text.click() time.sleep(3) # 在这里面使用断言 print(self.driver.title) if __name__ == '__main__': #1.创建文件夹 #获取项目所在的工程目录,HTML报告不能和py文件混合在一起 curpath=sys.path[0] if not os.path.exists( curpath+"/resultreport/"): os.makedirs(curpath+"/resultreport/") # 2.文件的创建,不能让名称重复,时间,时,分,秒名称绝对不会重复,防止文件名重复把前一个文件名进行覆盖 now=time.strftime("%Y-%m-%d-%H %M %S",time.localtime(time.time())) # 打印相关信息 str="curpath:"+curpath+"now:"+now+"time.time():"+time.time()+"/n"+"time.localtime(time.time())"+time.localtime(time.time()) print(str) filename=curpath+'/resultreport/'+now+"resultport.html" with open(filename,'wb') as fp: runner=HTMLTestRunner.HTMLTestRunner(stream=fp,title=u"测试报告",description=u"用例执行情况",verbosity=2) suite = result.createsuite(); runner.run(suite)createsuite()方法在这里:
import unittest def createsuite(): discover=unittest.defaultTestLoader.discover("./TestCase",pattern="TestBaiDu*.py",top_level_dir=None) return discover
2)异常捕捉和错误截图:
因为用例不可能每一次运行都会成功,肯定运行有不成功的时候,如果可以捕捉到错误,并且把错误截图给保存下来,这是一个非常棒的功能,也会给我们定位问题带来方便
目的:自动保存错误现场
使用方法:依靠get_screenshot_as_file(文件生成的路径+文件后缀名)就可以实现截图
下面我们来写一个方法来进行演示一下:哪一个函数调用这个方法,就会产生错误截图
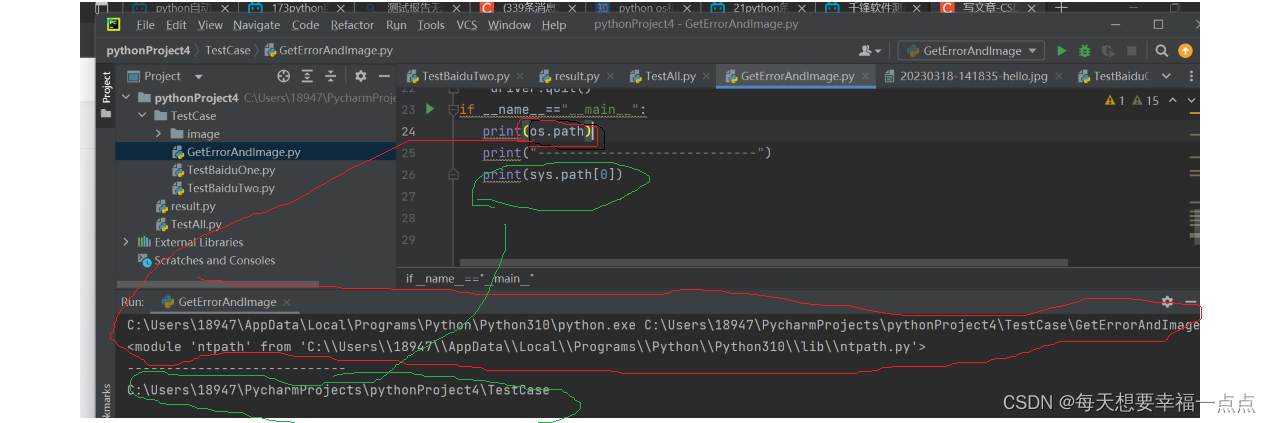
import unittest from selenium import webdriver import time import os import sys def GetErrorImage(driver,file_name): print(os.path) print(sys.path[0]) #创建保存错误截图的目录 if not os.path.exists("./image"): os.makedirs('./image/') #解决可能会冲突的命名方式 now=time.strftime("%Y%m%d-%H%M%S",time.localtime(time.time())) #正式进行错误截图 driver.get_screenshot_as_file("./image/"+now+"-"+file_name) time.sleep(1) def Test_Baidu(): driver=webdriver.Edge("C://Users//18947//AppData//Local//Programs//Python//Python310//msedgedriver.exe") driver.get("http://www.baidu.com") driver.find_element_by_id("kw").send_keys("王广元") time.sleep(3) driver.find_element_by_id("su").click() time.sleep(3) try: driver.assertNotEqual(driver.title,"百度一下你不知道",msg="不一致") except: GetErrorImage(driver, "hello.jpg") driver.quit() if __name__=="__main__": Test_Baidu()
数据驱动:
用数据驱动去驱动一个测试用例去不断的执行直到所有的测试数据都执行完成
比如说我要进行测试一个软件的登录功能的测试步骤:
1)输入账户
2)输入密码
3)点击登录
输入正确账号错误密码 登陆失败
输入错误账号正确密码 登录失败
输入错误账号错误密码 登陆失败
输入正确账号正确密码 登陆成功
不存在的账号和密码
已经挂失的账户
已经注销的账户
用户密码输入为空
总结:这些用例的变化的只有数据,测试步骤都是一样的
1)安装数据驱动:
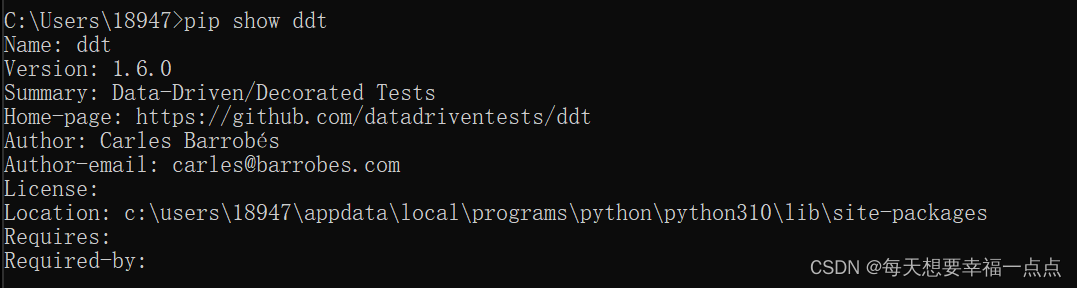
2)检查ddt是否安装成功:
或者执行一下pip3
1)data注解:支持一个数据或者是多个数据的传入甚至是一个读取文件的函数,多组数据之间用[]括起来,多组数据之间使用逗号进行分割
@data(*方法名('文件名字'))
2)unpack:多个数据传入的时候需要对一组数据进行映射,测试数据和测试方法参数的映射
3)file_data:测试数据在json文件中,和测试方法中的参数进行映射
一)使用ddt和data和unpack(多个数据传入)注解
import unittest from ddt import ddt, data, unpack ,file_data from selenium import webdriver import time @ddt class TestBaiDu(unittest.TestCase): def setUp(self): self.driver = webdriver.Edge("C://Users//18947//AppData//Local//Programs//Python//Python310//msedgedriver.exe") self.url="http://www.baidu.com" self.driver.maximize_window() def tearDown(self): time.sleep(3) self.driver.quit() @data("张三","李四","王二麻子","小淘气") def test_baidu1(self, value): driver=self.driver url=self.url driver.get(url) time.sleep(1) driver.find_element_by_id("kw").clear() time.sleep(2) driver.find_element_by_id("kw").send_keys(value) time.sleep(1) driver.find_element_by_id("su").click() time.sleep(3) @data(["张天", "百度搜索"], ["生命在于运动", "我的小孩子"], ["可可脂巧克力", "我的好兄弟"]) @unpack def test_baidu2(self,value1,value2): driver=self.driver url=self.url driver.get(url) driver.find_element_by_id("kw").clear() time.sleep(3) driver.find_element_by_id("kw").send_keys(value1) driver.find_element_by_id("su").click() time.sleep(3) if __name__ == '__main__': unittest.main()二)使用ddt.file_data来修饰
1)选择读取普通的txt文件,需要写读取文件的代码
import csv import sys import unittest from ddt import ddt, data, unpack ,file_data from selenium import webdriver import time @ddt class TestBaiDu(unittest.TestCase): def setUp(self): self.driver = webdriver.Edge("C://Users//18947//AppData//Local//Programs//Python//Python310//msedgedriver.exe") self.url="http://www.baidu.com" self.driver.maximize_window() def tearDown(self): time.sleep(3) self.driver.quit() @data("张三","李四","王二麻子","小淘气") def test_baidu1(self, value): driver=self.driver url=self.url driver.get(url) time.sleep(1) driver.find_element_by_id("kw").clear() time.sleep(2) driver.find_element_by_id("kw").send_keys(value) time.sleep(1) driver.find_element_by_id("su").click() time.sleep(3) @data(["张天", "百度搜索"], ["生命在于运动", "我的小孩子"], ["可可脂巧克力", "我的好兄弟"]) @unpack def test_baidu2(self,value1,value2): driver=self.driver url=self.url driver.get(url) driver.find_element_by_id("kw").clear() time.sleep(3) driver.find_element_by_id("kw").send_keys(value1) driver.find_element_by_id("su").click() time.sleep(3) def GetAll(filename): rows=[] path=sys.path[0] with open(path+'/data/'+filename,"rt") as f: readers=csv.reader(f,delimiter=',',quotechar='|') next(readers, None) for row in readers: temprows = [] for i in row: temprows.append(i) rows.append(temprows) return rows #([张三,张三百度搜索],[李四,李四百度搜索],[王五,王五百度搜索]) @data(*GetAll('test_baidu_data.txt')) @unpack def test_baidu3(self,value1,value2): driver = self.driver url = self.url driver.get(url) driver.find_element_by_id("kw").clear() time.sleep(3) driver.find_element_by_id("kw").send_keys(value1) driver.find_element_by_id("su").click() if __name__ == '__main__': unittest.main()2)选择读取json格式的文件,不需要再写额外读取函数的代码
import csv import sys import unittest from ddt import ddt, data, unpack ,file_data from selenium import webdriver import time @ddt class TestBaiDu(unittest.TestCase): def setUp(self): self.driver = webdriver.Edge("C://Users//18947//AppData//Local//Programs//Python//Python310//msedgedriver.exe") self.url="http://www.baidu.com" self.driver.maximize_window() def tearDown(self): time.sleep(3) self.driver.quit() @unittest.skip("skipping") @data("张三","李四","王二麻子","小淘气") def test_baidu1(self, value): driver=self.driver url=self.url driver.get(url) time.sleep(1) driver.find_element_by_id("kw").clear() time.sleep(2) driver.find_element_by_id("kw").send_keys(value) time.sleep(1) driver.find_element_by_id("su").click() time.sleep(3) @data(["张天", "百度搜索"], ["生命在于运动", "我的小孩子"], ["可可脂巧克力", "我的好兄弟"]) @unpack @unittest.skip("skipping") def test_baidu2(self,value1,value2): driver=self.driver url=self.url driver.get(url) driver.find_element_by_id("kw").clear() time.sleep(3) driver.find_element_by_id("kw").send_keys(value1) driver.find_element_by_id("su").click() time.sleep(3) def GetAll(filename): rows=[] path=sys.path[0] with open(path+'/data/'+filename,"rt") as f: readers=csv.reader(f,delimiter=',',quotechar='|') next(readers, None) for row in readers: temprows = [] for i in row: temprows.append(i) rows.append(temprows) return rows #([张三,张三百度搜索],[李四,李四百度搜索],[王五,王五百度搜索]) @file_data('test_baidu_data.json') def test_baidu3(self,value): driver = self.driver url = self.url driver.get(url) driver.find_element_by_id("kw").clear() time.sleep(3) driver.find_element_by_id("kw").send_keys(value) driver.find_element_by_id("su").click() if __name__ == '__main__': unittest.main()
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我正在尝试修改当前依赖于定义为activeresource的gem:s.add_dependency"activeresource","~>3.0"为了让gem与Rails4一起工作,我需要扩展依赖关系以与activeresource的版本3或4一起工作。我不想简单地添加以下内容,因为它可能会在以后引起问题:s.add_dependency"activeresource",">=3.0"有没有办法指定可接受版本的列表?~>3.0还是~>4.0? 最佳答案 根据thedocumentation,如果你想要3到4之间的所有版本,你可以这