🌈欢迎来到C++专栏~~包装器解析
- (꒪ꇴ꒪(꒪ꇴ꒪ )🐣,我是Scort
- 目前状态:大三非科班啃C++中
- 🌍博客主页:张小姐的猫~江湖背景
- 快上车🚘,握好方向盘跟我有一起打天下嘞!
- 送给自己的一句鸡汤🤔:
- 🔥真正的大师永远怀着一颗学徒的心
- 作者水平很有限,如果发现错误,可在评论区指正,感谢🙏
- 🎉🎉欢迎持续关注!

文章目录

function包装器 也叫作适配器。C++中的function本质是一个类模板,也是一个包装器。
那么我们来看看,我们为什么需要function呢?
包装器定义式:
// 类模板原型如下
template <class T> function; // undefined
template <class Ret, class... Args>
class function<Ret(Args...)>;
模板参数说明:
Ret: 是被包装的可调用对象的返回值类型Args... :是被包装的可调用对象的形参类型function包装器可以对可调用对象进行包装,包括函数指针、函数名、仿函数(函数对象)、lambda表达式
int f(int a, int b)
{
return a + b;
}
struct Functor
{
public:
int operator() (int a, int b)
{
return a + b;
}
};
class Plus
{
public:
//静态 vs 非静态
static int plusi(int a, int b)
{
return a + b;
}
double plusd(double a, double b)
{
return a + b;
}
};
int main()
{
function<int(int, int)> f1 = f;
f1(1, 2);
function<int(int, int)> f2 = Functor();
f2(1, 2);
function<int(int, int)> f3 = Plus::plusi;
f3(1, 2);
//非静态成员函数 要 + 对象
function<double(Plus, double, double)> f4 = &Plus::plusd;
f4(Plus(), 1.1, 2.2);
return 0;
}
注意事项:
&”+ 对象,因为非静态成员函数的第一个参数是隐藏this指针,所以在包装时需要指明第一个形参的类型为类的类型。对于以下函数模板useF:
代码如下:
template<class F, class T>
T useF(F f, T x)
{
static int count = 0;
cout << "count:" << ++count << endl;
cout << "count:" << &count << endl;
return f(x);
}
在不使用包装器,直接传入对象的时候,会实例化出三份
double f(double i)
{
return i / 2;
}
struct Functor
{
double operator()(double d)
{
return d / 3;
}
};
int main()
{
//函数指针
cout << useF(f, 11.11) << endl;
//仿函数
cout << useF(Functor(), 11.11) << endl;
//lambda表达式
cout << useF([](double d)->double{return d / 4; }, 11.11) << endl;
return 0;
}
输出结果如下:
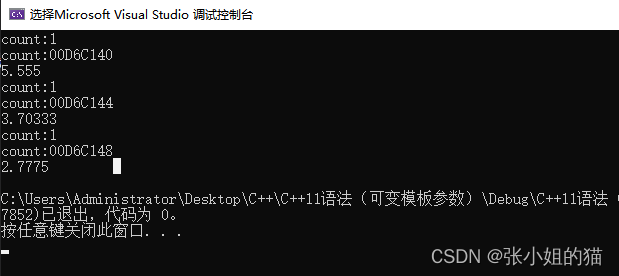
由于函数指针、仿函数、lambda表达式是不同的类型,因此useF函数会被实例化出三份,三次调用useF函数所打印count的地址也是不同的。
包装后代码如下:
int main()
{
// 函数指针
function<double(double)> f1 = f;
cout << useF(f1, 11.11) << endl;
// 函数对象
function<double(double)> f2 = Functor();
cout << useF(f2, 11.11) << endl;
// lamber表达式
function<double(double)> f3 = [](double d)->double { return d / 4; };
cout << useF(f3, 11.11) << endl;
return 0;
}
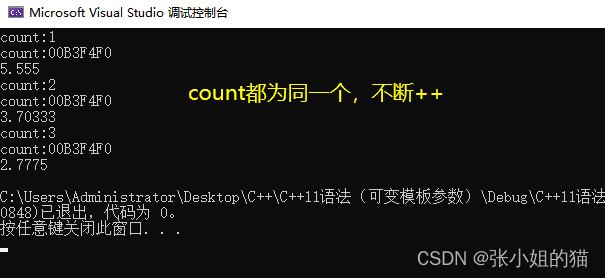
题目地址:传送
解题思路:
此处的包装器:
class Solution {
public:
int evalRPN(vector<string>& tokens) {
stack<long long> st;
map<string, function<long long(long long, long long)>> opfuncMap =
{
//自动构造pair ~ 初始化列表构造
{"+", [](long long a , long long b){return a + b;}},
{"-", [](long long a , long long b){return a - b;}},
{"*", [](long long a , long long b){return a * b;}},
{"/", [](long long a , long long b){return a / b;}},
};
for(auto& str : tokens)
{
if(opfuncMap.count(str))
{
//操作符 :出栈(先出右,再出左)
long long right = st.top();
st.pop();
long long left = st.top();
st.pop();
st.push(opfuncMap[str](left, right));
}
else
{
//操作数:入栈
st.push(stoll(str));
}
}
return st.top();
}
};
bind 是一种函数包装器,也叫做适配器。它可以接受一个可调用对象,生成一个新的可调用对象来“适应”原对象的参数列表,C++ 中的 bind 本质还是一个函数模板
bind函数模板的原型如下:
template <class Fn, class... Args>
/* unspecified */ bind(Fn&& fn, Args&&... args);
template <class Ret, class Fn, class... Args>
/* unspecified */ bind(Fn&& fn, Args&&... args);
模板参数说明:
fn:可调用对象args...:要绑定的参数列表:值或占位符调用bind的一般形式
auto newCallable = bind(callable, arg_list);
callable:需要包装的可调用对象
newCallable:生成的新的可调用对象
arg_list:逗号分隔的参数列表,对应给定的 callable 的参数,当调用 newCallable时,newCallable 会调用 callable,并传给它 arg_list 中的参数
_1 _2 ... 是定义在placeholders命名空间中,代表绑定函数对象的形参;_1代表第一个形参,_2代表第二个形参 …
举例:
using namespace placeholders;
int x = 2, y = 10;
Div(x, y);
auto bindFun1 = bind(Div, _1, _2);
原本传入的参数要求是要3个,现在只需要输入两个参数,因为绑定了固定的函数对象
using namespace placeholders;
class Sub
{
public:
int sub(int a, int b)
{
return a - b;
}
};
int main()
{
//function<int(Sub, int, int)> fsub = &Sub::sub;
function<int(int, int)> fsub = bind(&Sub::sub, Sub(), _1, _2);
}
想把Mul函数的第三个参数固定绑定为1.5,可以在绑定时将参数列表的placeholders::_3设置为1.5。比如:
int Mul(int a, int b, int rate)
{
return a * b * rate;
}
int main()
{
function<int(int, int)> fmul = bind(Mul, _1, _2, 1.5);
}
对于 Sub 类中的 sub 函数,因为 sub 的第一个参数是隐藏的 this 指针,如果想要在调用 sub 时不用对象进行调用,那么可以将 sub 的第一个参数固定绑定为一个 Sub 对象:
using namespace placeholders;
class Sub
{
public:
int sub(int a, int b)
{
return a - b;
}
};
int main()
{
//绑定固定参数
function<int(int, int)> func = bind(&Sub::sub, Sub(), _1, _2);
cout << func(1, 2) << endl;
return 0;
}
此时调用对象时就只需要传入用于相减的两个参数,因为在调用时会固定帮我们传入一个匿名对象给 this 指针。
如果想要将 sub 的两个参数顺序交换,那么直接在绑定时将 _1 和_2 的位置交换一下就行了:
using namespace placeholders;
class Sub
{
public:
int sub(int a, int b)
{
return a - b;
}
};
int main()
{
//绑定固定参数
function<int(int, int)> func = bind(&Sub::sub, Sub(), _2, _1);
cout << func(1, 2) << endl;
return 0;
}
其原理:第一个参数会传给_1,第二个参数会传给 _2,因此可以在绑定时通过控制 _n 的位置,来控制第 n 个参数的传递位置
kd

我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
运行bundleinstall后出现此错误:Gem::Package::FormatError:nometadatafoundin/Users/jeanosorio/.rvm/gems/ruby-1.9.3-p286/cache/libv8-3.11.8.13-x86_64-darwin-12.gemAnerroroccurredwhileinstallinglibv8(3.11.8.13),andBundlercannotcontinue.Makesurethat`geminstalllibv8-v'3.11.8.13'`succeedsbeforebundling.我试试gemin
我正在使用ruby2.1.0我有一个json文件。例如:test.json{"item":[{"apple":1},{"banana":2}]}用YAML.load加载这个文件安全吗?YAML.load(File.read('test.json'))我正在尝试加载一个json或yaml格式的文件。 最佳答案 YAML可以加载JSONYAML.load('{"something":"test","other":4}')=>{"something"=>"test","other"=>4}JSON将无法加载YAML。JSON.load("
我想用Nokogiri解析HTML页面。页面的一部分有一个表,它没有使用任何特定的ID。是否可以提取如下内容:Today,3,455,34Today,1,1300,3664Today,10,100000,3444,Yesterday,3454,5656,3Yesterday,3545,1000,10Yesterday,3411,36223,15来自这个HTML:TodayYesterdayQntySizeLengthLengthSizeQnty345534345456563113003664354510001010100000344434113622315
我使用的第一个解析器生成器是Parse::RecDescent,它的指南/教程很棒,但它最有用的功能是它的调试工具,特别是tracing功能(通过将$RD_TRACE设置为1来激活)。我正在寻找可以帮助您调试其规则的解析器生成器。问题是,它必须用python或ruby编写,并且具有详细模式/跟踪模式或非常有用的调试技术。有人知道这样的解析器生成器吗?编辑:当我说调试时,我并不是指调试python或ruby。我指的是调试解析器生成器,查看它在每一步都在做什么,查看它正在读取的每个字符,它试图匹配的规则。希望你明白这一点。赏金编辑:要赢得赏金,请展示一个解析器生成器框架,并说明它的
我正在运行Ubuntu11.10并像这样安装Ruby1.9:$sudoapt-getinstallruby1.9rubygems一切都运行良好,但ri似乎有空文档。ri告诉我文档是空的,我必须安装它们。我执行此操作是因为我读到它会有所帮助:$rdoc--all--ri现在,当我尝试打开任何文档时:$riArrayNothingknownaboutArray我搜索的其他所有内容都是一样的。 最佳答案 这个呢?apt-getinstallri1.8编辑或者试试这个:(非rvm)geminstallrdocrdoc-datardoc-da
