
文章目录
我们已经掌握了数组和链表,为什么还要有树?先来看看数组和链表的优缺点
数组:因为有索引,所以可以快速地访问到某个元素。但是如果要进行插入或者删除的话,被插入/删除位置之后的元素都得移动,如果插入后超过了数组容量,还得进行数组扩容。可见,数组查询快,增删慢。
链表:没有索引,要查询某个元素,得从第一个元素开始,一个一个往后遍历。但是要进行插入或者删除,无需移动元素,只要找到插入/删除位置的前一个元素即可。所以链表查询慢,增删快。
说到这里,那肯定知道树存在的意义了,没错,它吸收了链表和数组的优点,查询快,增删也快。
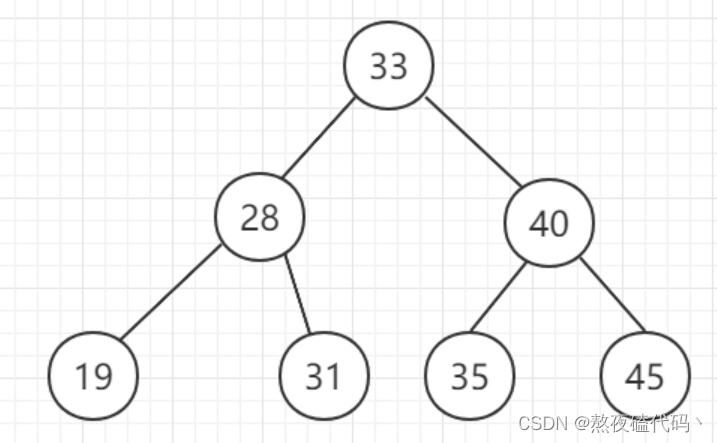
树是一种非线性的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
有一个特殊的结点,称为根结点,根结点没有前驱结点
除根结点外,其余结点被分成M(M > 0)个互不相交的集合T1、T2、…、Tm,其中每一个集合 Ti (1 <= i
<= m) 又是一棵与树类似的子树。每棵子树的根结点有且只有一个前驱,可以有0个或多个后继
树是递归定义的。
结点的度:一个结点含有子树的个数称为该结点的度;
树的度:一棵树中,所有结点度的最大值称为树的度;
叶子结点或终端结点:度为0的结点称为叶结点;
双亲结点或父结点:若一个结点含有子结点,则这个结点称为其子结点的父结点;
孩子结点或子结点:一个结点含有的子树的根结点称为该结点的子结点;
根结点:一棵树中,没有双亲结点的结点;
结点的层次:从根开始定义起,根为第1层,根的子结点为第2层,以此类推
树的高度或深度:树中结点的最大层次;
树的以下概念只需了解:
非终端结点或分支结点:度不为0的结点;
兄弟结点:具有相同父结点的结点互称为兄弟结点;
堂兄弟结点:双亲在同一层的结点互为堂兄弟;
结点的祖先:从根到该结点所经分支上的所有结点;
子孙:以某结点为根的子树中任一结点都称为该结点的子孙
森林:由m(m>=0)棵互不相交的树组成的集合称为森林
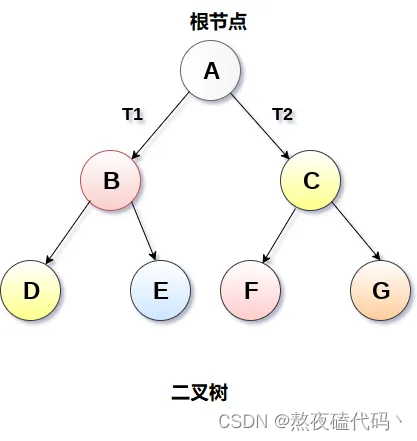
一棵二叉树是结点的一个有限集合,该集合:
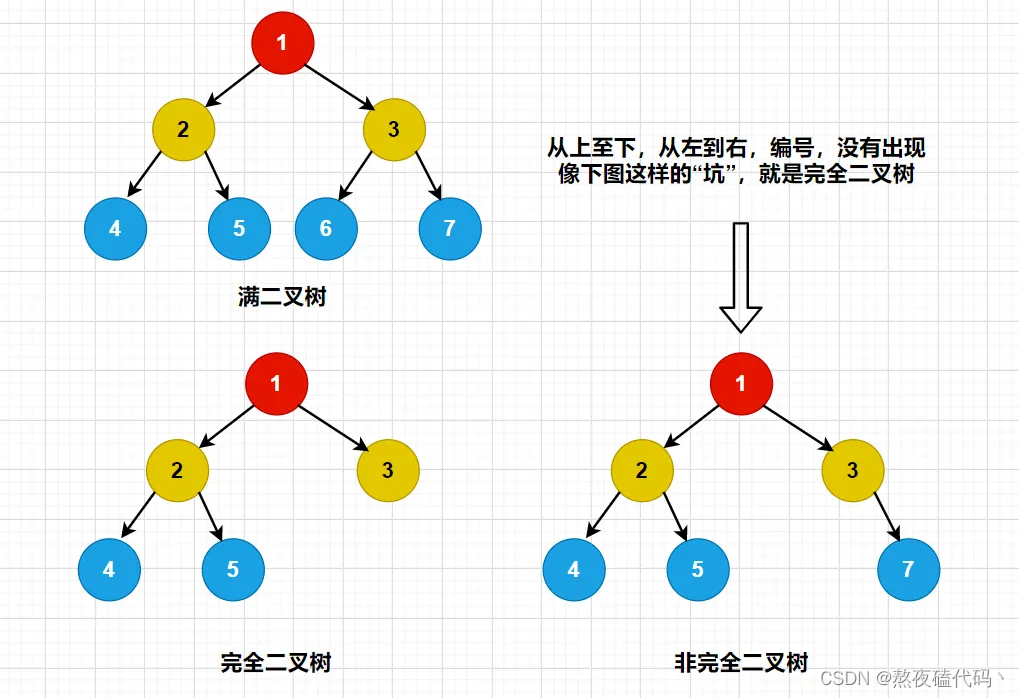
特殊的二叉树
二叉树的表示方法有很多,我们这里以孩子表示法为例
//孩子表示法
static class TreeNode {
public int val;
public TreeNode left;//左孩子
public TreeNode right;//右孩子
public TreeNode(int val) {
this.val = val;
}
}
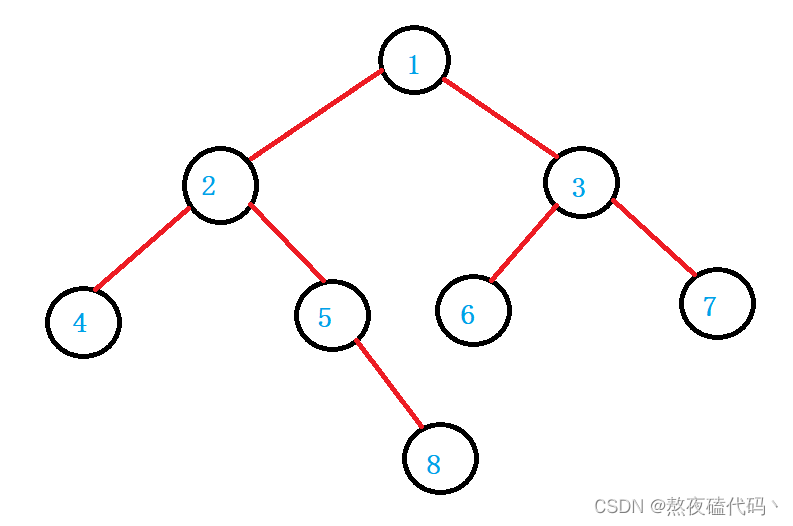
我们用最简单的方法创建这样一棵树。
public void InitTree() {
TreeNode node1 = new TreeNode(1);
TreeNode node2 = new TreeNode(2);
TreeNode node3 = new TreeNode(3);
TreeNode node4 = new TreeNode(4);
TreeNode node5 = new TreeNode(5);
TreeNode node6 = new TreeNode(6);
TreeNode node7 = new TreeNode(7);
TreeNode node8 = new TreeNode(8);
node1.left = node2;
node1.right = node3;
node2.left = node4;
node2.right = node5;
node3.left = node6;
node3.right = node7;
node5.right = node8;
}
所谓遍历(Traversal)是指沿着某条搜索路线,依次对树中每个结点均做一次且仅做一次访问。
NLR:前序遍历(Preorder Traversal 亦称先序遍历)——访问根结点—>根的左子树—>根的右子树。
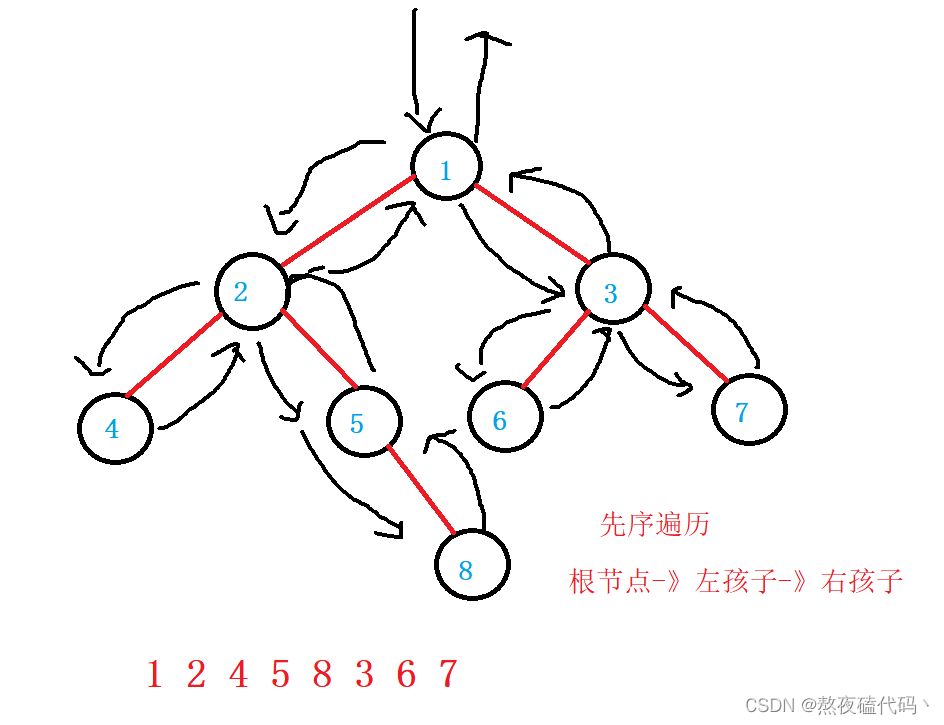
public void perOrder(TreeNode root) {
//先序遍历
if(root == null) {
return;
}
System.out.print(root.val+" ");
perOrder(root.left);
perOrder(root.right);
}

LNR:中序遍历(Inorder Traversal)——根的左子树—>根节点—>根的右子树。
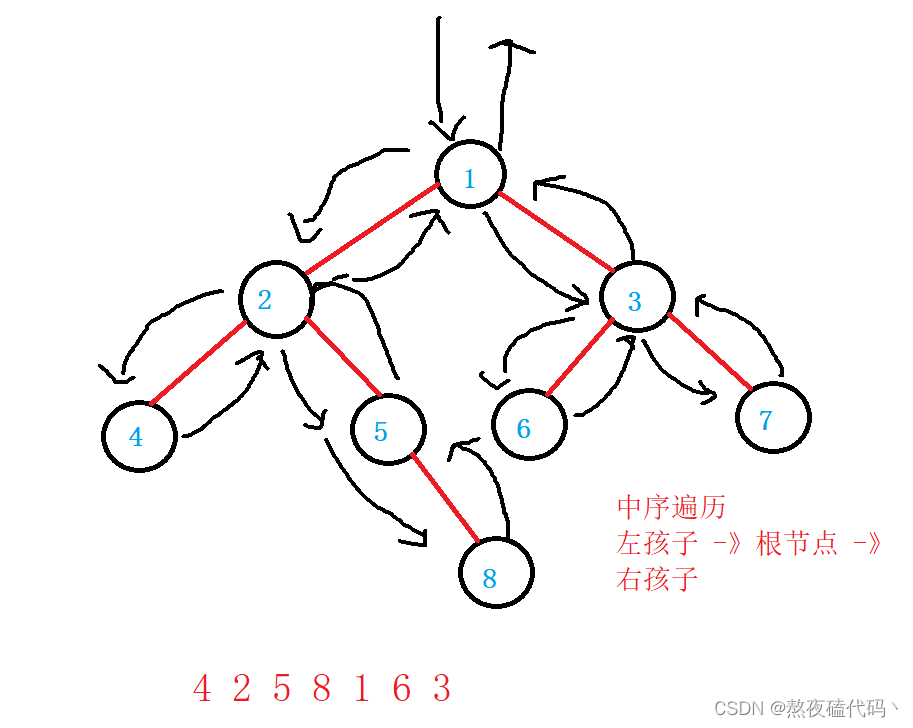
public void inOrder(TreeNode root) {
//中序遍历
if(root == null) {
return;
}
inOrder(root.left);
System.out.print(root.val+" ");
inOrder(root.right);
}

LRN:后序遍历(Postorder Traversal)——根的左子树—>根的右子树—>根节点。
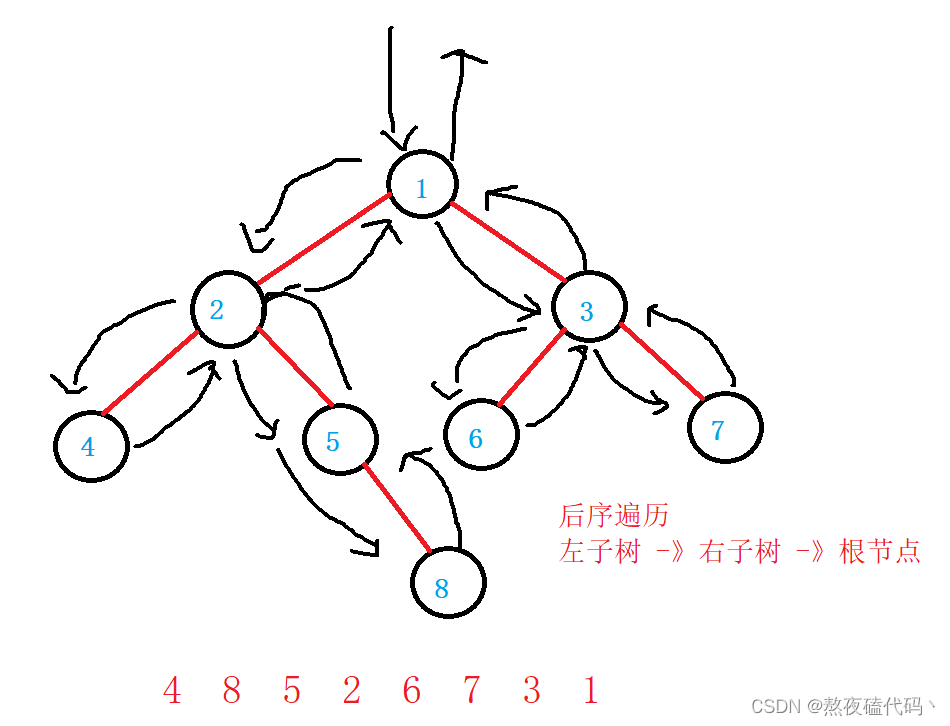
public void postOrder(TreeNode root) {
//后序遍历
if(root == null) {
return;
}
postOrder(root.left);
postOrder(root.right);
System.out.print(root.val+" ");
}

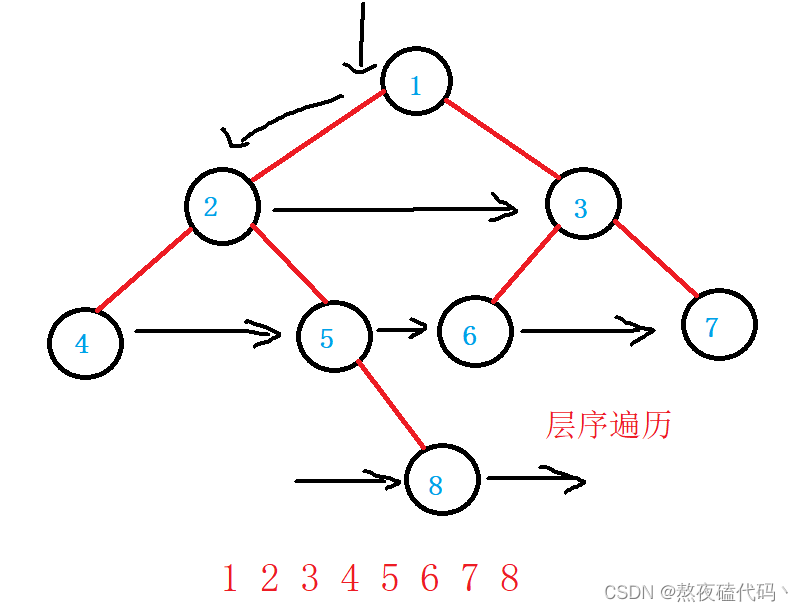
层序遍历就是一行一行遍历
我经常将预配置的lambda插入可枚举的方法中,例如“map”、“select”等。但是“注入(inject)”的行为似乎有所不同。例如与mult4=lambda{|item|item*4}然后(5..10).map&mult4给我[20,24,28,32,36,40]但是,如果我制作一个2参数lambda用于像这样的注入(inject),multL=lambda{|product,n|product*n}我想说(5..10).inject(2)&multL因为“inject”有一个可选的单个初始值参数,但这给了我......irb(main):027:0>(5..10).inject
是否有self验证的问题列表。看着那个,我可以确定我知道。我应该复习一下。在学习的过程中,我列了一个这样的list,但它只包含我在某处听说过的项目。我需要一段时间才能找到新的东西。 最佳答案 以下是针对ruby和Rails的一些测试列表。证书名称:RubyonRails谁提供:oDeskIncorporation认证费用:免费网站:https://www.odesk.com/tests/985?pos=0证书名称:RubyonRails提供者:Techgig.com(TimesBusinessSolutionsLimited(T
我想覆盖store_accessor的getter。可以查到here.代码在这里:#Fileactiverecord/lib/active_record/store.rb,line74defstore_accessor(store_attribute,*keys)keys=keys.flatten_store_accessors_module.module_evaldokeys.eachdo|key|define_method("#{key}=")do|value|write_store_attribute(store_attribute,key,value)enddefine_met
我一直在尝试在Ruby中实现BinaryTree类,但我得到了stackleveltoodeep错误,尽管我似乎没有在该特定代码段中使用任何递归:1.classBinaryTree2.includeEnumerable3.4.attr_accessor:value5.6.definitialize(value=nil)7.@value=value8.@left=BinaryTree.new#stackleveltoodeephere9.@right=BinaryTree.new#andhere10.end11.12.defempty?13.(self.value==nil)?true:
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我最近开始学习Ruby,这是我的第一门编程语言。我对语法感到满意,并且我已经完成了许多只教授相同基础知识的教程。我已经写了一些小程序(包括我自己的数组排序方法,在有人告诉我谷歌“冒泡排序”之前我认为它非常聪明),但我觉得我需要尝试更大更难的东西来理解更多关于Ruby.关于如何执行此操作的任何想法?
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭10年前。我一直在Rails上做两个项目,它们运行良好,但在这个过程中重新发明了轮子,自来水(和热水)和止痛药,正如我随后了解到的那样,这些已经存在于框架中。那么基本上,正确了解框架中所有智能部分的最佳方法是什么,这将节省时间而不是自己构建已经实现的功能?从第1页开始阅读文档?是否有公开所有内容的特定示例应用程序?一个特定的开源项目?所有的rails交通?还是完全
假设我有一个函数defodd_or_evennifn%2==0return:evenelsereturn:oddendend我有一个简单的可枚举数组simple=[1,2,3,4,5]然后我用我的函数在map中运行它,使用一个do-endblock:simple.mapdo|n|odd_or_even(n)end#=>[:odd,:even,:odd,:even,:odd]如果不首先定义函数,我怎么能做到这一点?例如,#doesnotworksimple.mapdo|n|ifn%2==0return:evenelsereturn:oddendend#Desiredresult:#=>[
在以下示例中,我无法理解Ruby运算符的优先级:x=1&&y=2由于&&的优先级高于=,我的理解是类似于+和*运算符:1+2*3+4解析为1+(2*3)+4它应该等于:x=(1&&y)=2但是,所有Ruby源代码(包括内部语法解析器Ripper)都将其解析为x=(1&&(y=2))为什么?编辑[08.01.2016]让我们关注一个子表达式:1&&y=2根据优先规则,我们应该尝试将其解析为:(1&&y)=2这没有意义,因为=需要特定的LHS(变量、常量、[]数组项等)。但是既然(1&&y)是一个正确的表达式,那么解析器应该如何处理呢?我试过咨询Ruby的parse.y,但它太像意大利面条
我在维基百科上找到了这个代码块,作为Ruby中quine(打印自身的程序)的示例。puts但是,我不明白它是如何工作的。特别是,我没有得到的是,当我删除最后一行时,出现此错误:syntaxerror,unexpected$end,expectingtSTRING_CONTENTortSTRING_DBEGortSTRING_DVARortSTRING_END这些行中发生了什么? 最佳答案 语法以here-document开始,通过Perl从UNIXshell借用-它基本上是一个多行字符串文字,从之后的行开始当一行以something
最近火热的“数字藏品”,你真正了解吗?其实有很多人会把数字藏品跟NFT混为一谈,但其实这两者还是有差别的。数字藏品并不等同于NFT数字藏品是什么?直观来看,它可能就是一张数字化照片或视频,甚至就只是一串数字。但它却是一件对应特定作品、艺术品生成的包含着大量数字信息且拥有唯一加密信息的可以买卖交易的收藏品。NFT则是指一种基于以太坊区块链的“非同质化代币”。它在百度百科里的释义是“用于表示数字资产(包括jpg和视频剪辑形式)的唯一加密货币令牌,可以买卖”。比如已被很多人认识的比特币就是NFT的一种。NFT在元宇宙中发挥的作用是巨大的,目前正是它在支撑着元宇宙中的经济体系。数字藏品其实也是NFT的