原文网址:RabbitMQ--重试机制_IT利刃出鞘的博客-CSDN博客
说明
本文介绍RabbitMQ的重试机制。
问题描述
消费者默认是自动提交,如果消费时出现了RuntimException,会导致消息直接重新入队,再次投递(进入队首),进入死循环,继而导致后面的消息被阻塞。
消息阻塞带来的后果是:后边的消息无法被消费;RabbitMQ服务端继续接收消息,占内存和磁盘越来越多。
RabbitMQ的自动确认
自动确认分四种情况(第一就是正常消费,其他三种为异常情况)
我遇到的是第四种情况,导致mq消息阻塞,并且消费者一直在消费同一条消息,然后抛异常,此时就进入了死循环。
消息未被确认时如下图所示:
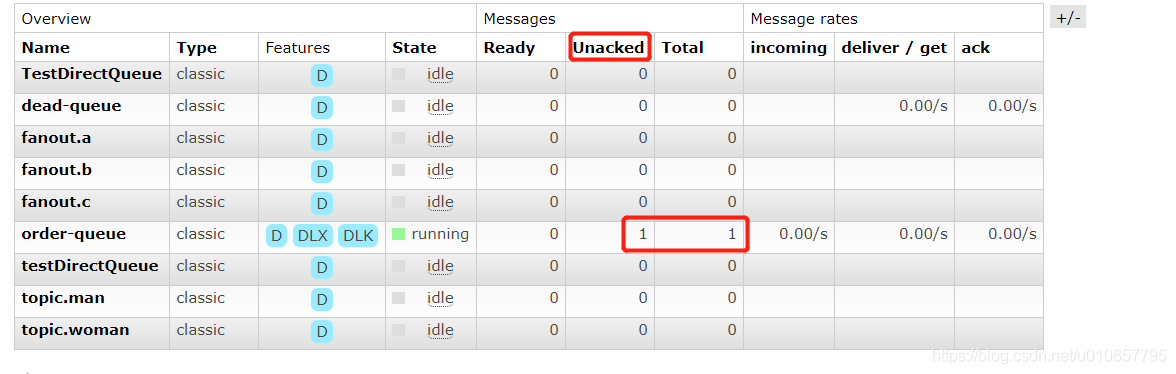
本处使用spring-rabbit中自带的重试功能解决上述问题。
注意
重试并不是RabbitMQ重新发送了消息,仅仅是消费者内部进行的重试,换句话说就是重试跟mq没有任何关系。
不管消息被消费了之后是手动确认还是自动确认,代码中不能使用try/catch捕获异常,否则重试机制失效。
重试机制有2种情况
配置
application.yml
spring:
# RabbitMQ服务配置
rabbitmq:
host: 127.0.0.1
port: 5672
username: guest
password: guest
listener:
simple:
# 重试机制
retry:
enabled: true #是否开启消费者重试
max-attempts: 3 #最大重试次数
initial-interval: 5000ms #重试间隔时间(单位毫秒)
max-interval: 1200000ms #重试最大时间间隔(单位毫秒)
# 乘子。间隔时间*乘子=下一次的间隔时间,不能超过max-interval
# 以本处为例:第一次间隔 5 秒,第二次间隔 10 秒,以此类推
multiplier: 2代码
@RabbitListener(queues = "meat_queue")
public void processMeatTwo(String message) throws InterruptedException {
System.out.println("processMeatTwo消费了队列meat_queue的消息:" + message);
Thread.sleep(1000);
//模拟异常
String is = null;
is.toString();
}结果

可以看到,消息重试了5次,之后会抛出ListenerExecutionFailedException的异常。后面附带着Retry Policy Exhausted,提示我们重试次数已经用尽了。
消息重试次数用尽后,消息就会被抛弃。
消息在重试完之后,会调用MessageRecoverer接口的recover方法。MessageRecoverer接口有如下三个实现类(看它们名字即可知道含义):
默认情况下是RejectAndDontRequeueRecoverer:拒绝而且不把消息重新放入队列。我们可以使用RepublishMessageRecoverer,重新发布消息,将它发布到其他队列,后边对它进行补偿处理。
先创建一个异常队列,然后与交换机绑定进行绑定,绑定之后设置MessageRecoverer。
@Configuration
public class MQErrorConfig {
@Autowired
private RabbitTemplate rabbitTemplate;
private static String errorTopicExchange = "error-topic-exchange";
private static String errorQueue = "error-queue";
private static String errorRoutingKey = "error-routing-key";
//创建异常交换机
@Bean
public TopicExchange errorTopicExchange(){
return new TopicExchange(errorTopicExchange, true, false);
}
//创建异常队列
@Bean
public Queue errorQueue(){
return new Queue(errorQueue, true);
}
//队列与交换机进行绑定
@Bean
public Binding BindingErrorQueueAndExchange(Queue errorQueue, TopicExchange errorTopicExchange){
return BindingBuilder.bind(errorQueue).to(errorTopicExchange).with(errorRoutingKey);
}
//设置MessageRecoverer
@Bean
public MessageRecoverer messageRecoverer(){
//AmqpTemplate和RabbitTemplate都可以
return new RepublishMessageRecoverer(rabbitTemplate, errorTopicExchange, errorRoutingKey);
}
}查看处理结果:

通过控制台可以看到,消息重试5次以后直接以新的routingKey发送到了配置的交换机中,此时再查看监控页面,可以看原始队列中已经没有消息了,但是配置的异常队列中存在一条消息:

上面的例子在测试中发现了一个问题,就是经过5次重试以后,控制台输出了一个异常的堆栈日志,然后队列中的数据也被ack掉了(自动ack模式),首先我们看一下这个异常日志是什么。
org.springframework.amqp.rabbit.listener.exception.ListenerExecutionFailedException: Retry Policy Exhausted出现消息被消费掉并且出现上述异常的原因是因为在构建SimpleRabbitListenerContainerFactoryConfigurer类时使用了MessageRecoverer接口,这个接口有一个cover方法,用来实现重试完成之后对消息的处理,源码如下:
ListenerRetry retryConfig = configuration.getRetry();
if (retryConfig.isEnabled()) {
RetryInterceptorBuilder<?, ?> builder = (retryConfig.isStateless()) ? RetryInterceptorBuilder.stateless()
: RetryInterceptorBuilder.stateful();
RetryTemplate retryTemplate = new RetryTemplateFactory(this.retryTemplateCustomizers)
.createRetryTemplate(retryConfig, RabbitRetryTemplateCustomizer.Target.LISTENER);
builder.retryOperations(retryTemplate);
MessageRecoverer recoverer = (this.messageRecoverer != null) ? this.messageRecoverer
: new RejectAndDontRequeueRecoverer(); // 1
builder.recoverer(recoverer);
factory.setAdviceChain(builder.build());注意看1处的代码,默认使用的是RejectAndDontRequeueRecoverer实现类,根据实现类的名字我们就可以看出来该实现类的作用就是拒绝并且不会将消息重新发回队列,我们可以看一下这个实现类的具体内容:
public class RejectAndDontRequeueRecoverer implements MessageRecoverer {
protected Log logger = LogFactory.getLog(RejectAndDontRequeueRecoverer.class); // NOSONAR protected
@Override
public void recover(Message message, Throwable cause) {
if (this.logger.isWarnEnabled()) {
this.logger.warn("Retries exhausted for message " + message, cause);
}
throw new ListenerExecutionFailedException("Retry Policy Exhausted",
new AmqpRejectAndDontRequeueException(cause), message);
}
}上述源码给出了异常的来源,但是未看到拒绝消息的代码,猜测应该是使用aop的方式实现的,此处不再继续深究。
redo我能想到的唯一用例是写入套接字或从数据库读取等操作,但如果这些操作失败一次,后续尝试很可能也会失败,因此它对我来说似乎仍然有点毫无意义,至于retry我真的想不出它在任何情况下都有用。这对我来说似乎毫无意义,因为我不知道或不使用Ruby,但我渴望有一天创造一种很棒的语言,所以我想至少知道一些最流行的语言设计背后的原因在那里。 最佳答案 想法是在调用redo或retry之前更改一些内容,希望您所做的任何事情第二次都能正常工作。我没有redo的示例,但我们已经在我正在处理的应用程序中找到了retry的用途。基本上,如果您有一些代
begin#someroutinerescueretry#onthirdretry,output"nodice!"end我想让它在“第三次”重试时打印一条消息。 最佳答案 可能不是最好的解决方案,但一个简单的方法就是制作一个tries变量。tries=0begin#someroutinerescuetries+=1retryiftries 关于ruby:如何知道脚本是否在第3次重试?,我们在StackOverflow上找到一个类似的问题: https://st
我正在使用Ruby-Tk为OSX开发一个桌面应用程序,我想为该应用程序提供一个AppleEvents接口(interface)。这意味着应用程序将定义它将响应的AppleScript命令的字典(对应于发送到应用程序的Apple事件),并且用户/其他应用程序可以使用AppleScript命令编写Ruby-Tk应用程序的脚本。其他脚本语言支持此类功能——Python通过位于http://appscript.svn.sourceforge.net/viewvc/appscript/py-aemreceive/的py-aemreceive库和Tcl通过位于http://tclae.source
Method#unbind返回对该方法的UnboundMethod引用,稍后可以使用UnboundMethod#bind将其绑定(bind)到另一个对象.classFooattr_reader:bazdefinitialize(baz)@baz=bazendendclassBardefinitialize(baz)@baz=bazendendf=Foo.new(:test1)g=Foo.new(:test2)h=Bar.new(:test3)f.method(:baz).unbind.bind(g).call#=>:test2f.method(:baz).unbind.bind(h).
绝对详细的RabbitMQ实践操作手册,看完本系列就够了。一、什么是MQ?1、MQ的概念2、理解消息队列二、MQ的优势和劣势1、优势和作用2、劣势三、MQ的应用场景四、AMQP五、工作原理一、什么是MQ?1、MQ的概念MQ全称MessageQueue(消息队列),是在消息的传输过程中保存消息的容器。多用于系统之间的异步通信。下面用图来理解异步通信,并阐明与同步通信的区别。同步通信:甲乙两人面对面交流,你一句我一句必须同步进行,两人除此之外不做任何事情异步通信:异步通信相当于通过第三方转述对话,可能有消息的延迟,但不需要二人时刻保持联系,消息传给第三方后,两人可以做其他自己想做的事情,当需要获取
有没有办法获取当前作业的重试次数?我希望作业在x次重试后停止,而不是崩溃。我想在perform方法中询问重试次数,这样我就可以在重试次数等于x时简单地返回。defperform(args)returnifretry_count>5...end使用Sidekiq2.12。编辑我(不是OP)有同样的问题,但出于不同的原因。如果正在重试该作业,我想进行额外的健全性检查以确保需要该作业,并在不再期望它成功时停止重试,因为它在排队后发生了外部变化。那么,有没有办法获取当前作业的重试次数呢?当前的答案仅建议您可以绕过需要它或可以从工作之外获得它的方法。 最佳答案
我有特定类型的作业,我希望重试的频率高于默认Sidekiq间隔设置的频率。这目前可能吗?理想情况下,作业将每5秒重试一次,最多一分钟。不完全确定这是目前插入Sidekiq作业的微不足道的事情。 最佳答案 根据:https://github.com/mperham/sidekiq/wiki/Error-Handling你可以这样做:classWorkerincludeSidekiq::Workersidekiq_retry_indo|count|5endend 关于ruby-on-rail
在Ruby的拙著中,提供了一个使用Rescue和retry的例子,使用以下代码向服务器发送HTTP头:defmake_requestif(@http11)self.send('HTTP/1.1')elseself.send('HTTP/1.0')endrescueProtocolError@http11=falseretryend要限制无限循环以防它无法解决,我必须插入什么代码来将重试限制为5次?会不会是这样的:5.times{retry} 最佳答案 您可以只在循环内编写一个5.times加上一个break,或者抽象该模式以将逻辑与
我有一个重试blockdefmy_methodapp_instances=[]attempts=0beginapp_instances=fetch_and_rescan_app_instances(page_n,policy_id,policy_cpath)rescueExceptionattempts+=1retryunlessattempts>2raiseExceptionendpage_n+=1end其中fetch_and_rescan_app_instances访问网络,因此可以抛出异常。我想编写一个rspec测试,它第一次抛出异常,第二次调用时不抛出异常,所以我可以测试它是否
我正在尝试编写一个规范来测试resque-retry的重试功能,但我似乎无法让测试正确命中binding.pry。有没有一种方法可以使用rspec3测试此功能,以便我可以验证它们是否按预期运行?这是一个请求规范,我正在尝试通过固定装置模拟实时请求,但无论我尝试什么,我似乎都无法让作业重试。gem'resque',require:'resque/server'gem'resque-web',require:'resque_web'gem'resque-scheduler'gem'resque-retry'gem'resque-lock-timeout'我正在使用resque_rspec,