目录
本文记录论文【Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data】的阅读笔记及对其项目的简单测试。
论文地址:https://arxiv.org/abs/2107.10833v2
单图像超分辨率(SR)是一个非常活跃的研究课题,旨在从低分辨率(LR)图像重建高分辨率(HR)图像。自SRCNN的开创性工作以来,深度卷积神经网络(CNN)方法为SR领域带来了蓬勃的发展。然而,大多数方法假设了一个理想的双三次下采样退化核
作者认为这常常不能模拟出真实世界的各种退化,而这种不匹配使得这些方法在现实场景中并不实用。
而盲超分辨率(Blind super-resolution)则是为了恢复存在未知且复杂退化的低分辨率图像。根据模拟的退化过程,现有的方法可以大致分为显式建模和隐式建模。
- 显式建模:经典的退化模型由模糊、降采样、噪声和 JPEG
压缩组成。但是现实世界的降采样模型过于复杂,仅通过这几个方式的简单组合无法达到理想的效果。- 隐式建模:依赖于学习数据分布和采用 GAN 来学习退化模型,但是这种方法受限于数据集,无法很好的泛化到数据集之外分布的图像。
在本篇论文中,作者扩展ESRGAN,通过合成训练对与一个更实用的退化过程来恢复一般现实世界的LR图像。
这促使作者将经典的“一阶”退化模型扩展到现实降解的“高阶”退化模型,本文中的的“高阶”过程,知识用几个重复的退化过程来建模退化,其中每个过程都是经典的退化模型。
经典退化模型:一般情况下,高清图像y首先与模糊核k进行卷积,然后进行尺度因子r的降采样操作。再加上噪声n得到低分辨率x。最后因为JPEG压缩在实际图像中传播中被广泛应用,退化模型还采用了JPEG压缩。
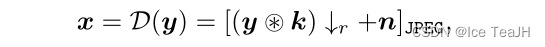
作者在实验中发现采用二阶退化过程之间的良好平衡简单和有效。(最近的一项研究也提出了一种随机洗牌策略来合成更实用的降解。然而,它仍然涉及固定数量的降解过程,并且所有的打乱的降解是否有用还不清楚)。作者认为高阶退化建模更加灵活,并试图模拟真实的退化生成过程。

所以作者在传统的退化模型中进一步加入能够截断高频的理想sinc滤波器来模拟常见的振铃和超调伪影。
因此,本篇论文将ESRGAN中的vgg式鉴别器改进为U-Net设计。U-Net结构和复杂的退化也增加了训练的不稳定性。因此,我们采用光谱归一化(SN)正则化来稳定训练,实现局部细节增强和伪影抑制的良好平衡。
总的来说,本篇论文主要工作有三点
- 使用了一个高阶退化过程来模拟实际退化,并利用sinc滤波器来模拟常见的振铃和超调伪影。
- 在训练中和进行了一些必要的修改(光谱归一化的U-Net鉴别器)来增加鉴别器的能力和稳定训练动态。
正如上文中所说的,文中的高阶退化模型是经典退化模型的重复操作,文中称为“first order”和“second order”,如下图:
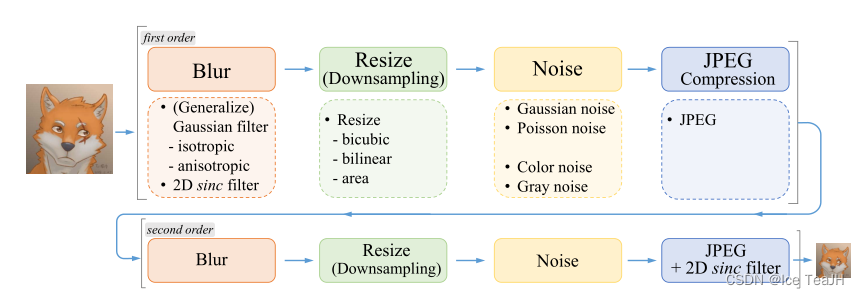
可以看出每层的退化模型包含了四个退化过程,每个退化过程中还有具体的退化操作
- 对于模糊核k,本方法使用各项同性(isotropic)和各向异性(anisotropic)的高斯模糊核。关于sinc filter会在下文中提到。
- 对于缩小操作r,常用的方法又双三次插值、双线性插值、区域插值---由于最近邻插值需要考虑对齐问题,所以不予以考虑。在执行缩小操作时,本方法从提到的3种插值方式中随机选择一种。
- 对于加入噪声操作n,本方法同时加入高斯噪声和服从泊松分布的噪声。同时,根据待超分图像的通道数,加入噪声的操作可以分为对彩色图像添加噪声和对灰度图像添加噪声。
- JPEG压缩,本方法通过从[0, 100]范围中选择压缩质量,对图像进行JPEG压缩,其中0表示压缩后的质量最差,100表示压缩后的质量最好。
上图中可以看出在模糊处理和合成的最后一步都采用了sinc滤波器,这是作者刻意进行的操作,并且最后一个sinc滤波器和JPEG压缩的顺序是随机交换的,以覆盖更大的退化空间,因为一些图像可能会先被过度锐化(有超调伪影),然后进行JPEG压缩;而有些图像可能会先做JPEG压缩后进行锐化操作。
本篇论文采用与ESRGAN相同的生成器(SR网络),即具有多个残差中残差密集块(RRDB)的深度网络,如下图所示,我们还扩展了原始的×4 ESRGAN架构,以×2和×1的比例因子执行超分辨率。

由于ESRGAN是一个重网络,我们首先采用像素反洗牌(pixelshuffle的逆操作)来减小空间的大小和扩大通道的大小,然后将其输入到ESRGAN主架构中。因此,大部分计算都是在较小的分辨率空间内完成的,从而减少了GPU内存和计算资源的消耗。
由于Real-ESRGAN的目标是解决比ESRGAN大得多的退化空间,ESRGAN中原有的鉴别器设计已不再适用。
它还需要对局部纹理产生精确的梯度反馈,而不是判别全局样式。我们还将ESRGAN中的vgg式鉴别器改进为带有跳跃连接的U-Net设计。UNet输出每个像素的真实值,并可以向生成器提供详细的逐像素反馈,如下图。

同时,U-Net结构和复杂的退化也增加了训练的不稳定性。我们采用谱归一化正则化来稳定训练。此外,我们观察到,光谱归一化也有利于缓解过度锐化和伪影由GAN训练。
训练过程
分为两个阶段,首先,我们训练一个具有L1损失的面向psnr的模型。得到的模型采用Real-ESRNet命名。然后,我们使用训练后的面向psnr的模型作为生成器的初始化,并结合L1损失( L1 Loss)、知觉损失(perceptual loss)和GAN损失(GAN loss)来训练Real-ESRGAN。
下图为部分对比效果

现在realesrgan项目已经完善得更多,并且加入了许多其他的工作,如:进一步对视频进行处理、加入了GRFGAN人脸增强算法、针对动漫视频的模型等等。
这个项目有三种演示方法,在线推理、可执行文件、python项目,在线推理就不赘述了,链接为ARC官网-腾讯(但不支持一些模型)
 下载下来如上图所示,测试图片可以直接放在这个文件夹
下载下来如上图所示,测试图片可以直接放在这个文件夹
在cmd中进入这个文件夹,使用(-i是输入图片地址,-o是输出图片地址,-n是选择模型)
realesrgan-ncnn-vulkan.exe -i input.jpg -o output.png -n realesrgan-x4plus-anime执行成功会显示:
效果:
按照作者所说的,可执行文件的运行结果会与pytorch跑出来的结果不太一样
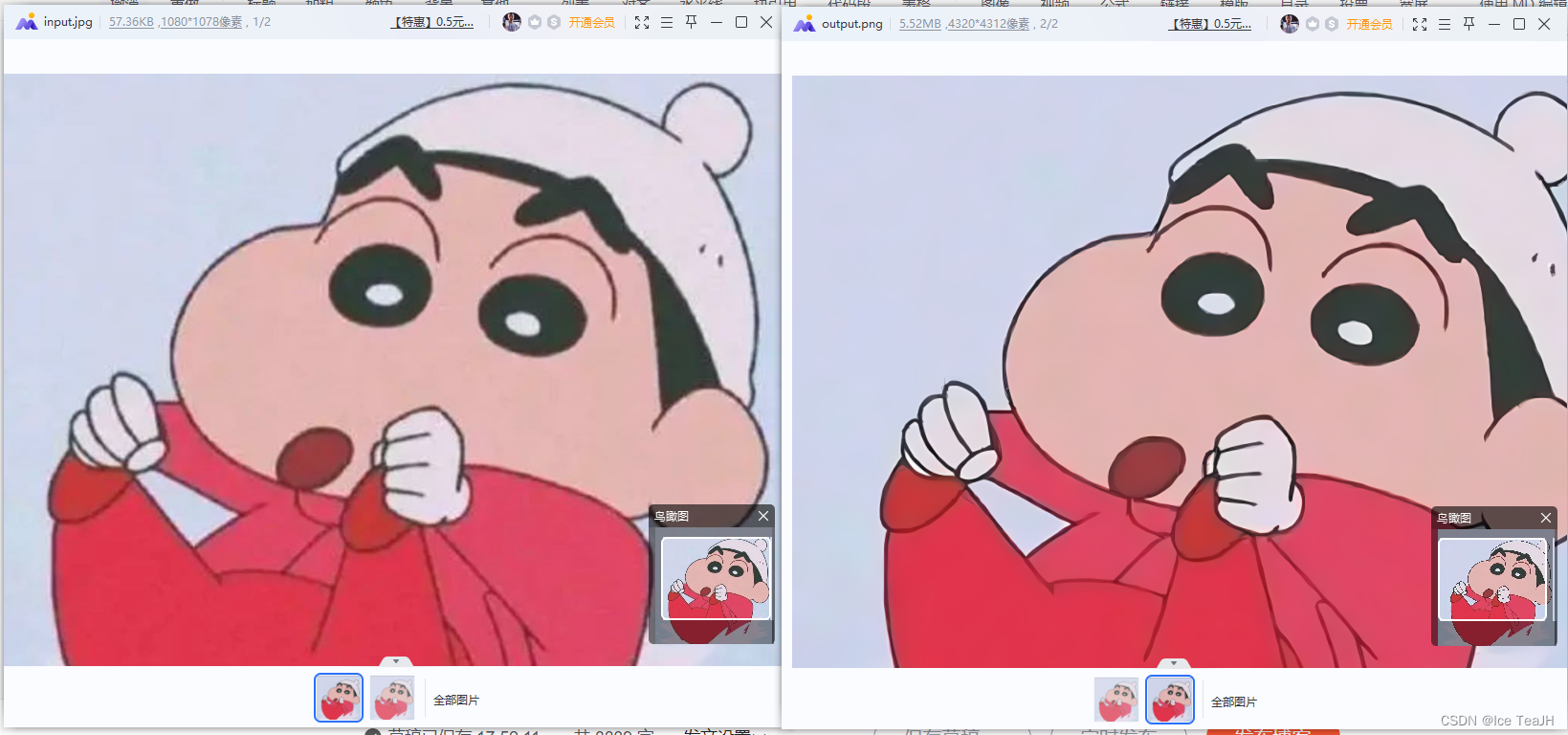
可以看出分辨率提升了四倍,并且对漫画图像的增强还是挺明显的(其他图像就较差)
将文章开头GitHub中的项目下载下来,看看需要的环境

使用anaconda创建虚拟环境,并进入:
conda create -n realesrgan python=3.8conda activate real按照需要安装pytorch
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=10.1 -c pytorch然后根据项目提示安装需要的包
# Install basicsr - https://github.com/xinntao/BasicSR
# We use BasicSR for both training and inference
pip install basicsr
# facexlib and gfpgan are for face enhancement
pip install facexlib
pip install gfpgan
pip install -r requirements.txt
python setup.py develop此部分经常报错,我的原因是由于网络问题,有两种方法:换源或使用vpn
pip换源:把对应的包名换一下就行
pip install basicsr -i https://pypi.tuna.tsinghua.edu.cn/simple仅换源还有报错的可能,比如我就遇到了找不到version的错误,于是搜索下发现是信任的问题,只需加入:
pip install basicsr -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
所有环境配置完成后就可以进行测试了
python inference_realesrgan.py -n RealESRGAN_x4plus -i inputs --face_enhance这是作者给的测试代码,但我用起来一直报错,仔细观察发现是--face_enhance这个参数需要下载一些模型,我的网络一直出错(换源也无法解决),如果已经跑过这个代码,记得先删除对应文件夹下下载了一半的模型,然后使用vpn后再跑一遍就可以成功
但如果不想费如此周章,使用所有默认参数也可以跑:
python inference_realesrgan.py但我发现这个项目对于人像的处理实在是一般,--face_enhance 是针对人脸增强,所以我还是跑了一下这个代码,跑之前要把测试图片放进inputs的文件夹中,输出会生成一个新的result文件夹。
效果: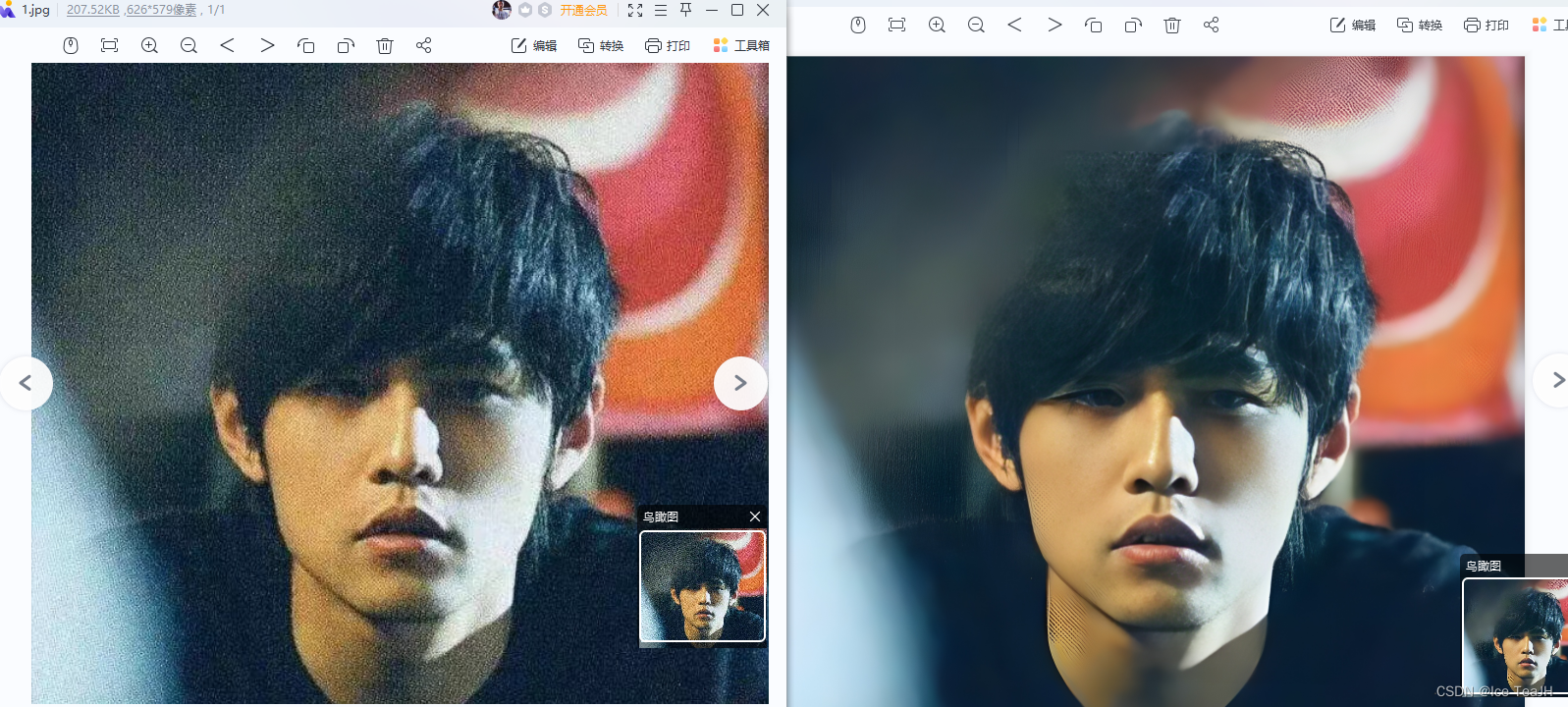
测试部分就是这样了,训练部分暂时就不展开讲。
本篇论文的创新点主要还是对退化模型的构造,这也是超分辨算法目前发展的方向之一。
但本篇论文的方法对图像类型如动漫图片的效果比较好,对更为复杂,包含更多纹理细节的图片就无法处理,虽然后期加入了GFPGAN的人脸增强方法,但个人认为它对人像的处理还是不够完美,不过这也确实是许多超分辨率算法的通病。
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个围绕一些对象的包装类,我想将这些对象用作散列中的键。包装对象和解包装对象应映射到相同的键。一个简单的例子是这样的:classAattr_reader:xdefinitialize(inner)@inner=innerenddefx;@inner.x;enddef==(other)@inner.x==other.xendenda=A.new(o)#oisjustanyobjectthatallowso.xb=A.new(o)h={a=>5}ph[a]#5ph[b]#nil,shouldbe5ph[o]#nil,shouldbe5我试过==、===、eq?并散列所有无济于事。
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
我遵循MichaelHartl的“RubyonRails教程:学习Web开发”,并创建了检查用户名和电子邮件长度有效性的测试(名称最多50个字符,电子邮件最多255个字符)。test/helpers/application_helper_test.rb的内容是:require'test_helper'classApplicationHelperTest在运行bundleexecraketest时,所有测试都通过了,但我看到以下消息在最后被标记为错误:ERROR["test_full_title_helper",ApplicationHelperTest,1.820016791]test
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您