| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |
| 💛Python量化交易实战💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
近期,需要实现检测摄像头中指定坐标区域内的主体颜色,通过查阅大量相关的内容,最终实现代码及效果如下,具体的实现步骤在代码中都详细注释,代码还可以进一步优化,但提升有限。
主要实现过程:按不同颜色的取值范围,对图像进行循环遍历,转换为灰度图,将本次遍历的颜色像素转换为白色,对白色部分进行膨胀处理,使其更加连续,计算白色部分外轮廓包围的面积累加求和,比较每种颜色围起来面积,保存最大值及其颜色,所有颜色遍历完后,返回最大值对应的颜色,显示在图像上
如果有类似的颜色识别的任务,可参考以下代码修改后实现具体需求
colorList.py
import numpy as np
import collections
# 将rgb图像转换为hsv图像后,确定不同颜色的取值范围
def getColorList():
dict = collections.defaultdict(list)
# black
lower_black = np.array([0, 0, 0])
upper_black = np.array([180, 255, 46])
color_list_black = []
color_list_black.append(lower_black)
color_list_black.append(upper_black)
dict['black'] = color_list_black
# gray
lower_gray = np.array([0, 0, 46])
upper_gray = np.array([180, 43, 220])
color_list_gray= []
color_list_gray.append(lower_gray)
color_list_gray.append(upper_gray)
dict['gray'] = color_list_gray
# white
lower_white = np.array([0, 0, 221])
upper_white = np.array([180, 30, 255])
color_list_white = []
color_list_white.append(lower_white)
color_list_white.append(upper_white)
dict['white'] = color_list_white
# red
lower_red = np.array([156, 43, 46])
upper_red = np.array([180, 255, 255])
color_list_red = []
color_list_red.append(lower_red)
color_list_red.append(upper_red)
dict['red'] = color_list_red
# red2
lower_red = np.array([0, 43, 46])
upper_red = np.array([10, 255, 255])
color_list_red2 = []
color_list_red2.append(lower_red)
color_list_red2.append(upper_red)
dict['red2'] = color_list_red2
# orange
lower_orange = np.array([11, 43, 46])
upper_orange = np.array([25, 255, 255])
color_list_orange = []
color_list_orange.append(lower_orange)
color_list_orange.append(upper_orange)
dict['orange'] = color_list_orange
# yellow
lower_yellow = np.array([26, 43, 46])
upper_yellow = np.array([34, 255, 255])
color_list_yellow = []
color_list_yellow.append(lower_yellow)
color_list_yellow.append(upper_yellow)
dict['yellow'] = color_list_yellow
# green
lower_green = np.array([35, 43, 46])
upper_green = np.array([77, 255, 255])
color_list_green = []
color_list_green.append(lower_green)
color_list_green.append(upper_green)
dict['green'] = color_list_green
# cyan
lower_cyan = np.array([78, 43, 46])
upper_cyan = np.array([99, 255, 255])
color_list_cyan = []
color_list_cyan.append(lower_cyan)
color_list_cyan.append(upper_cyan)
dict['cyan'] = color_list_cyan
# blue
lower_blue = np.array([100, 43, 46])
upper_blue = np.array([124, 255, 255])
color_list_blue = []
color_list_blue.append(lower_blue)
color_list_blue.append(upper_blue)
dict['blue'] = color_list_blue
# purple
lower_purple = np.array([125, 43, 46])
upper_purple = np.array([155, 255, 255])
color_list_purple = []
color_list_purple.append(lower_purple)
color_list_purple.append(upper_purple)
dict['purple'] = color_list_purple
return dict
if __name__ == '\_\_main\_\_':
color_dict = getColorList()
print(color_dict)
num = len(color_dict)
print('num=', num)
for d in color_dict:
print('key=', d)
print('value=', color_dict[d][1])
折叠
image_color_realize.py
import cv2
import colorList
# 实现对图片中目标区域颜色的识别
def get\_color(frame):
print('go in get\_color')
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
maxsum = 0
color = None
color_dict = colorList.getColorList()
# count = 0
for d in color_dict:
mask = cv2.inRange(hsv, color_dict[d][0], color_dict[d][1]) # 在后两个参数范围内的值变成255
binary = cv2.threshold(mask, 127, 255, cv2.THRESH_BINARY)[1] # 在灰度图片中,像素值大于127的都变成255,[1]表示调用图像,也就是该函数第二个返回值
# cv2.imshow("0",binary)
# cv2.waitKey(0)
# count+=1
binary = cv2.dilate(binary, None, iterations=2) # 使用默认内核进行膨胀操作,操作两次,使缝隙变小,图像更连续
cnts = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[-2] # 获取该函数倒数第二个返回值轮廓
sum = 0
for c in cnts:
sum += cv2.contourArea(c) # 获取该颜色所有轮廓围成的面积的和
# print("%s , %d" %(d, sum ))
if sum > maxsum:
maxsum = sum
color = d
if color == 'red2':
color = 'red'
elif color == 'orange':
color = 'yellow'
elif color == 'purple' or color == 'blue' or color == 'cyan' or color == 'white' or color == 'green':
color = 'normal'
return color
if __name__ == '\_\_main\_\_':
filename = "C:/Users/admin/Desktop/water\_samples/live01.jpg"
frame = cv2.imread(filename)
# frame = frame[180:280, 180:380] # [y:y+h, x:x+w] 注意x,y顺序
color = get_color(frame)
# 绘制文本
cv2.putText(img=frame,text=color,org=(20,50),fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=1.0,color=(0,255,0),thickness=2)
# cv2.namedWindow('frame',cv2.WINDOW\_NORMAL) # 设置显示窗口可调节
cv2.imshow('frame',frame)
cv2.waitKey(0)
折叠
video_color_realize.py
import cv2
import xf_color
# 对视频或摄像头获取的影像目标区域颜色进行识别
cap = cv2.VideoCapture("C:/Users/admin/Desktop/water\_samples/01.mp4")
# cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1100) # 这里窗口大小调节只对摄像头有效
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 750)
while cap.isOpened():
ret, frame0 = cap.read()
# 对图像帧进行翻转(因为opencv图像和我们正常是反着的) 视频是正常的,摄像头是反转的
# frame0 = cv2.flip(src=frame0, flipCode=2)
# frame = frame[180:280, 180:380] # [y:y+h, x:x+w]
# frame = frame0[200:400, 100:300] # 设置检测颜色的区域,四个顶点坐标
frame = frame0
# frame=cv2.resize(src=frame,dsize=(750,600))
hsv_frame = cv2.cvtColor(src=frame, code=cv2.COLOR_BGR2HSV)
# 获取读取的帧的高宽
height, width, channel = frame.shape
color = xf_color.get_color(hsv_frame)
# 绘制文本
cv2.putText(img=frame0, text=color, org=(20, 50), fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=1.0, color=(0, 255, 0), thickness=2)
cv2.imshow('frame', frame0)
key = cv2.waitKey(1)
if key == 27:
break
cap.release()
cv2.destroyAllWindows()
if __name__ == '\_\_main\_\_':
print('Pycharm')
效果如下:
示例图片1

示例图片2
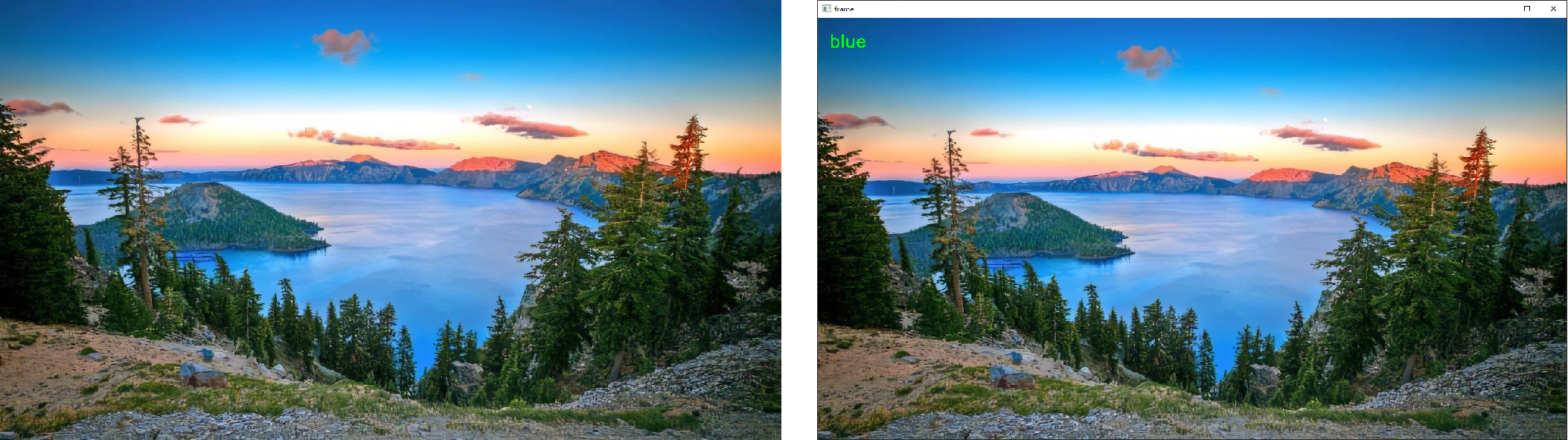
示例图片3

我想在一个没有Sass引擎的类中使用Sass颜色函数。我已经在项目中使用了sassgem,所以我认为搭载会像以下一样简单:classRectangleincludeSass::Script::FunctionsdefcolorSass::Script::Color.new([0x82,0x39,0x06])enddefrender#hamlengineexecutedwithcontextofself#sothatwithintemlateicouldcall#%stop{offset:'0%',stop:{color:lighten(color)}}endend更新:参见上面的#re
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我是Rails的新手,所以请原谅简单的问题。我正在为一家公司创建一个网站。那家公司想在网站上展示它的客户。我想让客户自己管理这个。我正在为“客户”生成一个表格,我想要的三列是:公司名称、公司描述和Logo。对于名称,我使用的是name:string但不确定如何在脚本/生成脚手架终端命令中最好地创建描述列(因为我打算将其设置为文本区域)和图片。我怀疑描述(我想成为一个文本区域)应该仍然是描述:字符串,然后以实际形式进行调整。不确定如何处理图片字段。那么……说来话长:我在脚手架命令中输入什么来生成描述和图片列? 最佳答案 对于“文本”数
如何使用Ruby的默认Curses库获取颜色?所以像这样:puts"\e[0m\e[30;47mtest\e[0m"效果很好。在浅灰色背景上呈现漂亮的黑色。但是这个:#!/usr/bin/envrubyrequire'curses'Curses.noecho#donotshowtypedkeysCurses.init_screenCurses.stdscr.keypad(true)#enablearrowkeys(forpageup/down)Curses.stdscr.nodelay=1Curses.clearCurses.setpos(0,0)Curses.addstr"Hello
状态:我正在构建一个应用程序,其中需要一个可供用户选择颜色的字段,该字段将包含RGB颜色代码字符串。我已经测试了一个看起来很漂亮但效果不佳的。它是“挑剔的颜色”,并托管在此存储库中:https://github.com/Astorsoft/picky-color.在这里我打开一个关于它的一些问题的问题。问题:请建议我在Rails3应用程序中使用一些颜色选择器。 最佳答案 也许页面上的列表jQueryUIDevelopment:ColorPicker为您提供开箱即用的产品。原因是jQuery现在包含在Rails3应用程序中,因此使用基
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
之前说过10之后的版本没有3dScan了,所以还是9.8的版本或者之前更早的版本。 3d物体扫描需要先下载扫描的APK进行扫面。首先要在手机上装一个扫描程序,扫描现实中的三维物体,然后上传高通官网,在下载成UnityPackage类型让Unity能够使用这个扫描程序可以从高通官网上进行下载,是一个安卓程序。点到Tools往下滑,找到VuforiaObjectScanner下载后解压数据线连接手机,将apk文件拷入手机安装然后刚才解压文件中的Media文件夹打开,两个PDF图打印第一张A4-ObjectScanningTarget.pdf,主要是用来辅助扫描的。好了,接下来就是扫描三维物体。将瓶