前端代码管理一直是困扰不少前端开发团队的难题,从开发到发布的整体工作流程中,除了常规的技术问题外,往往还伴随着沟通成本、维护成本及协作效率等问题。这些问题在团队规模较小的时候可能不太明显,但是当团队规模变大时就矛盾越发凸显。
数栈前端开发团队负责着离线开发,实时开发,数据服务等多条产品线的开发和维护工作,面对众多的产品线,如何合理的管理代码,成了团队需要思考的问题,虽然借助了Multirepo进行管理,但还是遇到了许多难题:
● 私有源维护成本增加
为复用相关业务逻辑,团队内部抽象出一些私有包,由于不能在公网暴露,为了管理这些私有包团队使用了私有源,但由于搭建私有源服务器资源问题,私有源常常不稳定且下载速度慢,特别是对于需要源码交付的某些客户来说,安装这些私有包更会遇到各种问题,交付的时间和人力成本大大升高。
● 逻辑难复用,重复造轮子
各个仓库中会抽象出同一功能的组件,组件之间的共享往往难以同步,造成了「重复造轮子」等现象。
● 工具/配置不统一,沟通成本高
各个仓库所使用的工具和配置没有进行统一,在进行配置更新等的过程中,往往需要同步到各个产品线负责人,沟通成本较高。
这些问题严重拖慢了数栈前端团队从开发到发布的整体流程,同时增加了团队的维护成本和沟通成本,如何寻找新的工具解决这些问题已迫在眉睫,在进行了深入调研和多次讨论的过程中,新的项目管理方式Monorepo 在这时映入了我们的眼帘。
那么Multirepo和Monorepo到底是什么呢?其实他们分别代表的是两种前端代码管理方式:
Multirepo是一种分散式的前端代码管理方式,按照功能或其他维度,将项目拆分为不同模块并单独维护于各自仓库中。作为传统的管理方式,Multirepo具备灵活度高、安全控制等特点,但同时也带了管理成本和写作成本的增加,依赖升级等问题。
Monorepo是集中式管理的前端代码管理方式,将所有的项目在集中一个代码仓库中进行管理,严格的统一和收归,有利于统一的升级和管理。作为新型的管理方式,Monorepo有效降低了运营及协作成本,但一个代码仓库的管理模式带来了项目体积的上升,获取时间延长,同时安全性也有所下降。
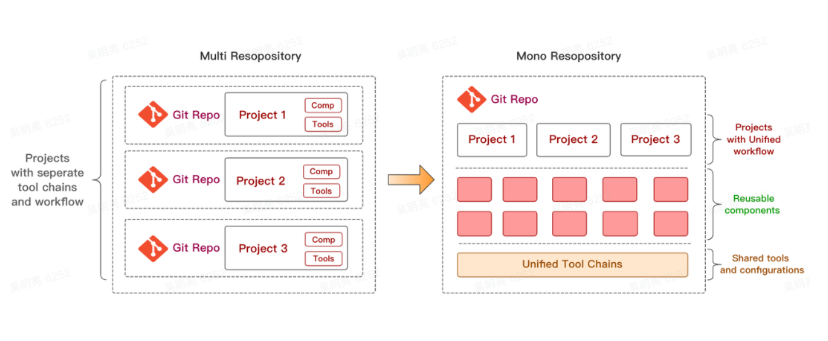
上图为Multirepo和Monorepo对比图,从图中我们可以简要归纳:
Multirepo是由多个仓库组成的项目管理方式,每个仓库有着独立的工作流、组件与配置
Monorepo则将不同仓库整合成为一个仓库,并共享工作流、组件与配置。
两种管理方式各有千秋,不能简单的定义哪种方式更好,但Monorepo的共享机制、统一管理及协作成本低等优势,显然更符合深陷复杂产品线挑战的数栈前端团队的需求,选择Monorepo也是团队探索效率提升的必然道路。
确定了新的管理方式后,接下来面对的就是如何与数栈相适配的问题。市面上关于Monorepo的解决方案和相关工具有很多,虽然rush、nx 之类的工具能够在特定的领域提供较好的解决方案,但却并不符合我们的实际需求。
在调研了社区的各种Monorepo实现和解决方案之后,结合我们自身的业务场景和需求,最终我们选择了pnpm和turborepo作为底层的包管理工具和任务调度工具,因为只有最合适的产品才是最好的解决方案。
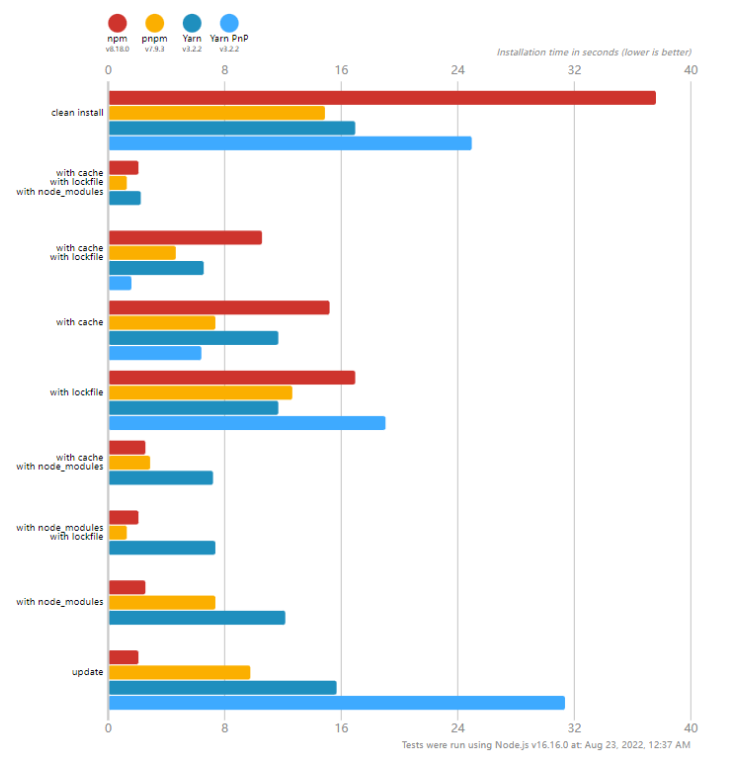
在前端社区中,npm、 yarn、 pnpm 三个包管理工具三足鼎立,而我们最终选择了pnpm原因在于:pnpm对monorepo有着较好的支持,同时对比其他两个包管理工具,pnpm在性能等各个方面有着显著的优势:
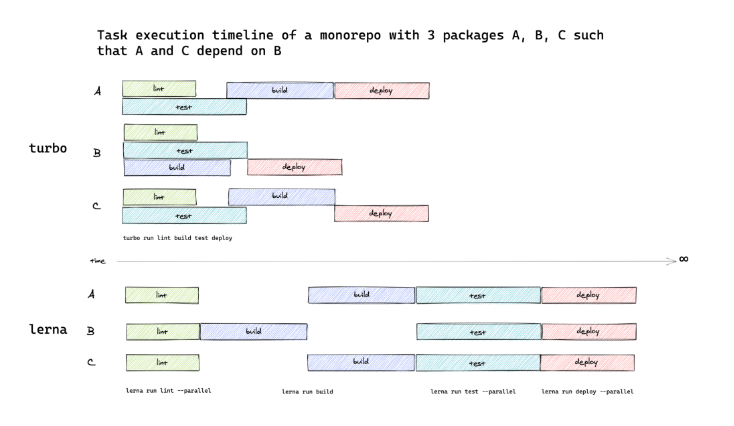
任务调度方面,社区中也存在很多优秀的工具,如 rush、nx、lerna、turborepo等,综合对比之后,我们选择了配置简单易懂、调度更加科学的turborepo作为我们的任务调度工具:
在确定了底层包管理工具和任务调度工具后,数栈&Monorepo整体架构方案也就明确了:
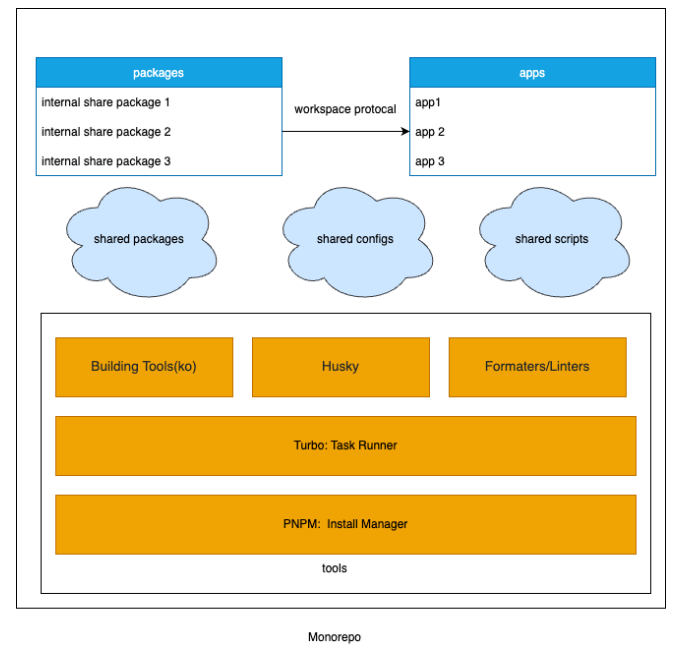
Monorepo解决了之前使用Multirepo时存在的问题,帮助我们更好的管理代码,接下来我们将结合Multirepo存在的问题来详细说明Monorepo是如何在数栈产品中落地的。
Multirepo存在的一个显著问题是配置的不统一导致的难以维护,所以我们需要对格式化、代码检测、打包等相关流程的配置进行规范化和统一,同时针对不同产品线的细微差别,也需要支持其灵活的扩展。因此我们在Monorepo仓库的根目录提供了统一的基础配置,同时如需要进行调整,不同产品线可以继承该配置并进行必要的修改。
Multirepo存在的另一个显著问题就是逻辑难以复用,迁移之前的逻辑复用主要是靠抽象到私有包并发布,或者直接复制粘贴,整体效率低,流程长且难以维护。迁移之后我们对各种配置等进行了统一的同时,也将公用的业务逻辑和组件整合到了仓库根目录的packages目录下,同时通过pnpm的 workspace protocal 链接到各个产品线中以复用。这样不仅解决了逻辑复用的相关问题,同时私有源也不用进行维护,Multirepo下的私有源维护成本问题得以解决。
当基础配置和公共逻辑被暴露出来之后,就面临着这些内容可以被随意修改的问题,而这往往会影响所有的产品线,稍有不慎会有造成巨大损失,因此我们需要给这些重要的内容施以限制和保护。
我们基于git hooks做了一些工作,在pre-commit和pre-push阶段分别对权限和分支名等内容进行了校验,并定义了Maintainer、Owner、Deverloper 三个角色,对应的权限分别为:
Maintainer: 拥有全部权限,可以修改包括基础配置文件等的所有内容。
Owner: 各产品线或者公共组件主要负责人,拥有对应范围内的所有权限。
Developer: 该产品线或者公共组件的辅助开发人员,只拥有包括开发新功能等的部分产品线权限。
角色权限进行明确的划分之后,我们可以将基础配置和公共逻辑等内容的修改交给更有经验的工程师。同时权限分配配置维护在本地,这样可以更清晰的了解不同产品线对应的人员,方便沟通。
从 Multirepo迁移到 Monorepo如果采用手动的方式逐个迁移会有如下问题:
1.迁移前的各产品线仓库存在多个版本需要维护,手动迁移多个版本工作内容重复且效率较低。
2.人为的操作往往会出错,且出错时沟通成本较高。
因此我们在迁移的过程中实现了自动化的迁移流程,主要流程如下:
1.自动克隆原仓库的目标分支内容到Monorepo删除需要统一的配置如commitlint等配置;
2.删除需要统一的配置如commitlint等配置;
3.删除babel, webpack等相关重复依赖;
4.检测并替换通过pnpm的 workspace protocal 链接的内部依赖引入方式;
5.删除yarn,npm相关的lock文件,并安装依赖生成最新的pnpm-lock.yaml.
自动化迁移的实现,保证了迁移过程的快速且顺利的进行,各产品线的同学可以较为平滑的过渡到新的Monorepo项目管理方式。
数栈前端团队在今年上半年正式迁移到了Monorepo,解决了之前Multirepo项目管理方式下的私有源维护成本较高,工具/配置等不统一,逻辑复用链路长且难以维护等问题。在迁移的过程中,实现了大部分迁移工作的自动化进行,并对重要的配置等进行了权限校验以进行限制和保护。整体提升了数栈前端团队研发的效率,降低了协作和沟通成本,有效实现降本增效。
袋鼠云开源框架钉钉技术交流qun(30537511),欢迎对大数据开源项目有兴趣的同学加入交流最新技术信息,开源项目库地址:https://github.com/DTStack
我这样做(在我看来):#myUserisaUserinActiveRecordwith:has_many:postsmyUser.posts.eachdo|post|end如果用户有10个帖子,这会调用10次数据库吗?这些循环应该像(不那么漂亮)吗?:myPosts=myUser.postsmyPosts.eachdo|post|endHere是我测试的ruby文件的粘贴箱。编辑修改了粘贴箱。这让我想起了Java中的代码for(inti=0;i应该是(除非数组被修改)for(inti=0,len=someExpensiveFunction();i我错过了什么吗?我看到一堆Rails
如果用户是所有者,我有一个条件来检查说删除和文章。delete_articleifuser.owner?另一种方式是user.owner?&&delete_article选择它有什么好处还是它只是一种写作风格 最佳答案 性能不太可能成为该声明的问题。第一个要好得多-它更容易阅读。您future的自己和其他将开始编写代码的人会为此感谢您。 关于ruby-on-rails-如果条件与&&,是否有任何性能提升,我们在StackOverflow上找到一个类似的问题:
catch在Ruby中是为了跳出深度嵌套的代码。在Java中,例如Java用于处理异常的try-catch可以实现同样的效果,但它被认为是糟糕的解决方案,而且效率也很低。在用于处理异常的Ruby中,我们有begin-raise-rescue,我认为将它用于其他任务也很昂贵。Ruby的catch-throw真的是比begin-raise-rescue更有效的解决方案吗?或者还有其他原因可以使用它来打破嵌套block而不是begin-raise-rescue? 最佳答案 除了是摆脱控制结构的“正确”方式之外,catch-throw也明显
3月26日,映宇宙(HK:03700,即“映客”)发布截至2022年12月31日的2022年度业绩财务报告。财报显示,映宇宙2022年的总营收为63.19亿元,较2021年同期的91.76亿元下降31.1%。2022年,映宇宙的经营亏损为4698.7万元,2021年同期则为净利润4.57亿元;期内亏损(净亏损)为1.68亿元,2021年同期的净利润为4.33亿元;非国际财务报告准则经调整净利润为3.88亿元,2021年同期为4.82亿元,同比下降19.6%。 映宇宙在财报中表示,收入减少主要是由于行业竞争加剧,该集团对旗下产品采取更为谨慎的运营策略以应对市场变化。不过,映宇宙的毛利率则有所提升
在Rails3.x应用程序中,我正在使用net::ssh并向远程pc运行一些命令。我想向用户的浏览器显示实时日志。比如,如果两个命令在net中运行::ssh执行即echo"Hello",echo"Bye"被传递然后"Hello"应该在执行后立即显示在浏览器中。这是代码我在rubyonrails应用程序中使用ssh连接和运行命令Net::SSH.start(@servers['local'],@machine_name,:password=>@machine_pwd,:timeout=>30)do|ssh|ssh.open_channeldo|channel|channel.requ
我正在为Jekyll编写一个转换器插件,需要访问一些页眉(YAML前端)属性。只有内容被传递给主要的转换器方法,似乎无法访问上下文。例子:moduleJekyllclassUpcaseConverter关于如何在转换器插件中访问页眉数据有什么想法吗? 最佳答案 基于Jekyll源代码,无法在转换器中检索YAML前端内容。根据您的情况,我看到了两种可行的解决方案。您的文件扩展名可以具有足够的描述性,以提供您本应包含在前言中的信息。看起来Converter插件的设计就是这么基本的。如果修改Jekyll是一个选项,您可以更改Convert
目录1古彝文与古典保护2古文识别的挑战2.1西文与汉文OCR2.2古彝文识别难点3合合信息:古彝文保护新思路3.1图像矫正3.2图像增强3.3语义理解3.4工程技巧4总结1古彝文与古典保护彝文指的是云南、贵州、四川等地的彝族人使用的文字,区别于现代意义上的彝文,古彝文指的是在民间流通使用的原生态彝文,多达87046字。古彝文的起源距今至少数千年,是世界上最古老的文字之一。对古彝文字集研究有助于理解尚未被翻译成汉文、用字尚未规范化的古籍,更深层、透彻地作用于传统文化保护。古彝文字义对照图(网络资料+邵文苑供图)古籍是不可再生的宝贵资源,应当得到妥善保护。中国的古籍在历史上迭经水火兵燹等自然灾害、
一、简介之前在Vue项目中使用过element的上传组件,实现了点击上传+拖拽上传的两种上传功能。然后我就在想是否可以通过原生的html+js来实现文件的点击上传和拖拽上传,说干就干。首先是点击获取上传文件自然没的说,只需要借助input标签即可,但原生的点击上传按钮,实在是过于简陋,所以我的想法是通过一个div,模拟成上传按钮,然后监听其点击事件,通过input.click()去模拟点击真正的上传元素。然后是拖拽获取上传文件,这个稍有难度,我的想法是通过HTML5新增的drag拖放API+dataTransfer来实现文件的拖拽获取,但是由于是html5新增的,所以可能在某些低版本IE浏览器
文章目录背景一、最初的疑惑二、简单聊聊原理三、组织内实践案例四、实践带来的反思五、最后聊几句问题背景这个概念由来已久,但是在国内兴起,是最近几年;低代码即Low-Code;指提供可视化开发环境,可以用来创建和管理软件应用;简单的说就是可以通过各种组件的拖拽,实现页面的创建,交互流程和逻辑,以及数据层面的管理,更加高效的实现需求;早先在数据公司时;见识过低代码的应用,也参与过部分研发,比如元数据平台,BI分析等;不过,当时还是以数据管理的工具来定义项目,并非是低代码;从「2020年底」开始;实际上,那个时间节点,低代码平台的应用已经形成趋势了;现在的公司,将低代码平台的使用规划到业务体系中;后来
一、介绍一下vercelvercel是一个站点托管平台,提供CDN加速,同类的平台有Netlify和GithubPages,相比之下,vercel国内的访问速度更快,并且提供Production环境和development环境,对于项目开发非常的有用的,并且支持持续集成,一次push或者一次PR会自动化构建发布,发布在development环境,都会生成不一样的链接可供预览。但是vercel只是针对个人用户免费,teams是收费的首先vercel零配置部署,第二访问速度比github-page好很多,并且构建很快,还是免费使用的,对于部署个人前端项目路、接口服务非常方便vercel类似于git