目录
励志环节
不要躺平去发光
重点
(1)为什么存在动态内存分配 (2)动态内存函数的介绍 molloc free calloc realloc (3)常见的动态内存错误(4)题目(5)柔型数组
int a = 4; int arr[40] = { 0 };
上面的内存开辟(1)空间开辟大小是固定的(2)数组在申明的时候,必须指定数组的长度,它所需要的内存在编译时分配。
但是,对空间的需求,不仅仅是上述的情况,需要的空间大小在运行的时候才能知道,可能有的空间比较多,有的需要的空间不足,这个时候就需要动态内存分配了。
动态内存分配在堆区
在malloc、calloc、realloc创建的空间需要释放
这两个函数的头文件是<stdlib.h>
malloc
这是一个动态内存开辟的函数
void* malloc ( size_t size );
size_t size 单位是字节,因为不知道开辟的空间是什么类型的,所以直接用字节数来表示
free
这是一个动态内存的开辟和回收的函数
void free ( void* ptr );
#include <stdio.h>
#include <stdlib.h>
#include <string.h> //strerror函数头文件
#include <errno.h> //errno这个变量头文件
int main()
{
//开辟10个整形的空间int arr[10];
int* p = (int*)malloc(40);//malloc返回的是void*
//如果开辟失败,返回的是一个空指针,所以要先检查,后使用
if (p == NULL)
{
printf("%s\n", strerror(errno));//字符串
return 0;
}
//使用
int i = 0;
for (i = 0; i < 10; i++)
{
*(p + 1) = i;
printf("%d ", *(p + 1));
}
//释放这份空间,还给操作系统
free(p);
//但是p还是保存的这个地址,就变成了野指针,
p = NULL;//就可以防止野指针这种操作
return 0;
}提示:野指针成因之一:指针指向的空间释放(在C语言初阶专栏的初阶指针知识点的文章中有详细写到野指针成因)http://t.csdn.cn/nr6EZ(文章链接)
头文件是<stdlib.h>
void* calloc ( size_t num , size_t size );
num元素个数 size每个元素的大小 例如: calloc(10,sizeof(int))
增容失败,返回空指针。
头文件是<stdlib.h>
void* realloc ( void* ptr , size_t size );
(1)ptr 是要调整的内存地址 (2)size 调整之后新大小 (3)返回值为调整之后的内存起始位置。 (4)这个函数调整原内存空间大小的基础上,还会将原来内存中的数据移动到 新 的空间。
(1)原有的空间后面的空间足够,要扩展内存就直接原有内存之后直接追加空间,原来空间的数据不发生变化。 (2)原有的空间后面的空间不够,当是情况 2 的时候,原有空间之后没有足够多的空间时,扩展的方法是:在堆空间上另找一个合适大小的连续空间来使用。这样函数返回的是一个新的内存地址。
#include <stdlib.h>
#include <stdio.h>
#include <string.h> //strerror函数头文件
#include <errno.h> //errno这个变量头文件
int main()
{
//开辟10个整形的空间int arr[10];
int* p = (int*)malloc(40);//malloc返回的是void*
//如果开辟失败,返回的是一个空指针,所以要先检查,后使用
if (p == NULL)
{
printf("%s\n", strerror(errno));//字符串
return 0;
}
//使用
int i = 0;
for (i = 0; i < 10; i++)
{
*(p + 1) = i;
printf("%d ", *(p + 1));
}
//增容
int* ptr = (int*)realloc(p, 80);
if (ptr != NULL)
{
p = ptr;
ptr = NULL;//因为这个地址,后面会被释放
}
//释放这份空间,还给操作系统
free(p);
//但是p还是保存的这个地址,就变成了野指针,
//野指针成因之一:指针指向的空间释放(在C语言初阶专栏的初阶指针知识点的文章中有详细写到野指针成因)
p = NULL;
return 0;
}这个函数也会出现增容失败的时候。(返回空指针,意思空间被释放,会导致原来的空间也被释放)(所以不能把返回的指针直接放在原来的指针变量里,应该再定义一个指针变量存放返回地址,先判断是否是空指针(增容失败),不是空指针,再赋值给p)
realloc(NULL,40),就和malloc一样了
void test()
{
int *p = (int *)malloc(INT_MAX/4);
*p = 20;//如果p的值是NULL,就会有问题
free(p);
}应该先判断是否为空指针
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
int main()
{
int i = 0;
int* p = (int*)malloc(10 * sizeof(int));
if (NULL == p)
{
printf("%s\n", strerror(errno));
}
for (i = 0; i <= 10; i++)
{
*(p + i) = i;//当i是10的时候越界访问
}
free(p);
p = NULL;
return 0;
}不可以越界访问
#include <stdio.h>
#include <string.h>
int main()
{
int a = 10;
int* p = &a;
free(p);//非动态开辟,不可以释放
return 0;
}#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <errno.h>
int main()
{
int* p = (int*)malloc(100);
if (p == NULL)
{
printf("%s\n", strerror(errno));
return 0;
}
p++;
free(p);//p不再指向动态内存的起始位置,不能释放
return 0;
}#include <stdio.h>
#include <string.h>
int main()
{
int* p = (int*)malloc(100);
free(p);
free(p);//重复释放
return 0;
}不可以重复释放(当把p赋值为空指针后再释放是可以的)
#include <stdio.h>
#include <stdlib.h>
void test()
{
int* p = (int*)malloc(100);
if (NULL != p)
{
*p = 20;
}
//记得要释放
}
int main()
{
test();
//在这里释放不可以
return 0;
}
//或者把函数返回值改为int*,在主函数接收一下,这样就可以在主函数释放
//总而言之,要释放,这块内存要释放忘记释放不再使用的动态开辟的空间会造成内存泄漏。 记得释放,也要正确释放。
(1)
#include <stdio.h>
#include <stdlib.h>
void GetMemory(char* p)
{
p = (char*)malloc(100);
//没有释放
//并没有返回任何值,也没有改变str的值
}
void Test(void)
{
char* str = NULL;
GetMemory(str);
strcpy(str, "hello world");
//常量字符串传递的是h的地址,所以是正确的
//str是空指针,在这里非法访问,程序会崩溃
printf(str);//这个写法是可以的,但是程序崩溃无法运行到这里
}
int main()
{
Test();
return 0;
}运行结果:程序崩溃
(2)
#include <stdio.h>
char* GetMemory(void)
{
char p[] = "hello world";
return p;
}
//出了这个子函数,地址所指向空间被回收
void Test(void)
{
char* str = NULL;
str = GetMemory();//没有这块地址的使用权,所以地址里内容不确定
printf(str);
}
int main()
{
Test();
return 0;
}(3)
#include <stdio.h>
#include <stdlib.h>
void GetMemory(char** p, int num)
{
*p = (char*)malloc(num);
//没有释放
}
void Test(void)
{
char* str = NULL;
GetMemory(&str, 100);
strcpy(str, "hello");
printf(str);
}
int main()
{
Test();
return 0;
}(4)
#include <stdio.h>
#include <stdlib.h>
void Test(void)
{
char* str = (char*)malloc(100);
strcpy(str, "hello");
free(str);//空间释放后,要赋值为空指针
if (str != NULL)
{
strcpy(str, "world");//非法访问(空间被释放,还给操作系统,没有使用的权利,如果使用,就是非法访问)
printf(str);
}
}
int main()
{
Test();
return 0;
}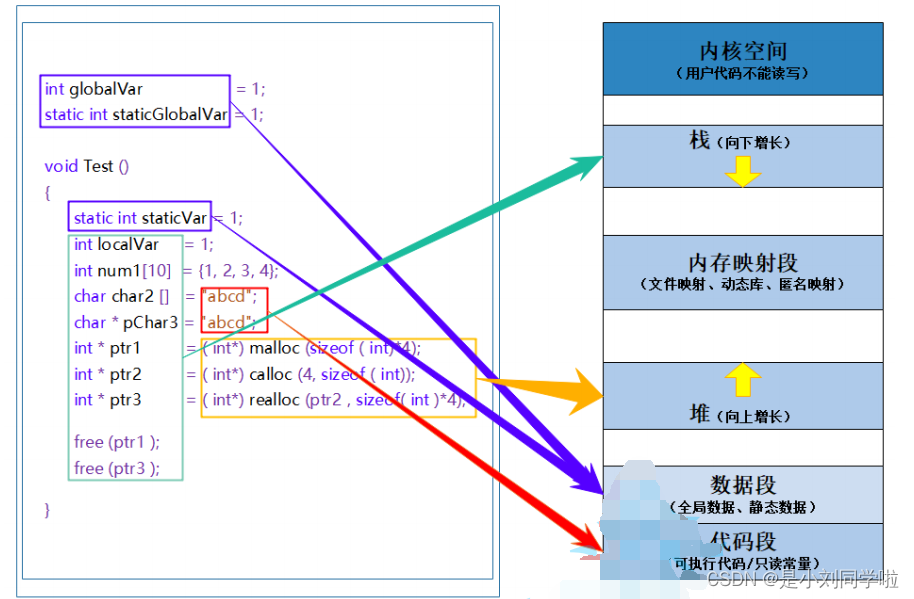
1. 栈区( stack ):在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结 束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是 分配的内存容量有限。 栈区主要存放运行函数而分配的局部变量、函数参数、返回数据、返 回地址等。 2. 堆区( heap ):一般由程序员分配释放, 若程序员不释放,程序结束时可能由 OS 回收 。分 配方式类似于链表。 3. 数据段(静态区)( static )存放全局变量、静态数据。程序结束后由系统释放。 4. 代码段:存放函数体(类成员函数和全局函数)的二进制代码。
实际上普通的局部变量是在 栈区 分配空间的,栈区的特点是在上面创建的变量出了作用域就销毁。但是被 static 修饰的变量存放在 数据段(静态区) ,数据段的特点是在上面创建的变量,直到程序 结束才销毁 所以生命周期变长。
struct S1
{
int n;
int arr[0];//大小是未指定的,并不是0
};写法二
struct S2
{
int n;
int arr[];
};
#include <stdio.h>
#include <stdlib.h>
struct S2
{
int n;
int arr[];
};
int main()
{
struct S2* ps = (struct S2*)malloc(sizeof(struct S2) + 40);
ps->n = 100;
int i = 0;
for (i = 0; i < 10; i++)
{
ps->arr[i] = i;
}
//增容
struct S2* ptr = (struct S2*)realloc(ps, sizeof(struct S2) + 80);
if (ptr == NULL)
{
return 0;
}
else
{
ps = ptr;
}
free(ps);
ps = NULL;
return 0;
}代码二:
#include <stdio.h>
#include <stdlib.h>
struct S2
{
int n;
int* arr;
};
int main()
{
struct S2* ps = (struct S2*)malloc(sizeof(struct S2));
ps->n = 100;
ps->arr = (int*)molloc(40);
//增容
free(ps->arr);
ps->arr = NULL;
free(ps);
ps = NULL;
free(ps);
ps = NULL;
return 0;
}代码一相对于来说比较好:(1)方便内存释放 如果我们的代码是在一个给别人用的函数中,你在里面做了二次内存分配,并把整个结构体返回给 用户。用户调用free可以释放结构体,但是用户并不知道这个结构体内的成员也需要free,所以你 不能指望用户来发现这个事。所以,如果我们把结构体的内存以及其成员要的内存一次性分配好 了,并返回给用户一个结构体指针,用户做一次free就可以把所有的内存也给释放掉。 (2)这样有利于访问速度. 连续的内存有益于提高访问速度,也有益于减少内存碎片。
(代码二:开辟和释放的次数多,容易出错;容易形成内存碎片)
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
我安装了ruby版本管理器,并将RVM安装的ruby实现设置为默认值,这样'哪个ruby'显示'~/.rvm/ruby-1.8.6-p383/bin/ruby'但是当我在emacs中打开inf-ruby缓冲区时,它使用安装在/usr/bin中的ruby。有没有办法让emacs像shell一样尊重ruby的路径?谢谢! 最佳答案 我创建了一个emacs扩展来将rvm集成到emacs中。如果您有兴趣,可以在这里获取:http://github.com/senny/rvm.el
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
我想用这两种语言中的任何一种(最好是ruby)制作一个窗口管理器。老实说,除了我需要加载某种X模块外,我不知道从哪里开始。因此,如果有人有线索,如果您能指出正确的方向,那就太好了。谢谢 最佳答案 XCB,X的下一代API使用XML格式定义X协议(protocol),并使用脚本生成特定语言绑定(bind)。它在概念上与SWIG类似,只是它描述的不是CAPI,而是X协议(protocol)。目前,C和Python存在绑定(bind)。理论上,Ruby端口只是编写一个从XML协议(protocol)定义语言到Ruby的翻译器的问题。生
有没有办法在Ruby中动态创建数组?例如,假设我想遍历用户输入的书籍数组:books=gets.chomp用户输入:"TheGreatGatsby,CrimeandPunishment,Dracula,Fahrenheit451,PrideandPrejudice,SenseandSensibility,Slaughterhouse-Five,TheAdventuresofHuckleberryFinn"我把它变成一个数组:books_array=books.split(",")现在,对于用户输入的每一本书,我想用Ruby创建一个数组。伪代码来做到这一点:x=0books_array.
你好,我无法成功如何在散列中删除key后释放内存。当我从哈希中删除键时,内存不会释放,也不会在手动调用GC.start后释放。当从Hash中删除键并且这些对象在某处泄漏时,这是预期的行为还是GC不释放内存?如何在Ruby中删除Hash中的键并在内存中取消分配它?例子:irb(main):001:0>`ps-orss=-p#{Process.pid}`.to_i=>4748irb(main):002:0>a={}=>{}irb(main):003:0>1000000.times{|i|a[i]="test#{i}"}=>1000000irb(main):004:0>`ps-orss=-p
我想在IRB中浏览文件系统并让提示更改以反射(reflect)当前工作目录,但我不知道如何在每个命令后进行提示更新。最终,我想在日常工作中更多地使用IRB,让bash溜走。我在我的.irbrc中试过这个:require'fileutils'includeFileUtilsIRB.conf[:PROMPT][:CUSTOM]={:PROMPT_N=>"\e[1m:\e[m",:PROMPT_I=>"\e[1m#{pwd}>\e[m",:PROMPT_S=>"FOO",:PROMPT_C=>"\e[1m#{pwd}>\e[m",:RETURN=>""}IRB.conf[:PROMPT_MO
这是我在ActiveAdmin中的自定义页面ActiveAdmin.register_page"Settings"doaction_itemdolink_to('Importprojects','settings/importprojects')endcontentdopara"Text"endcontrollerdodefimportprojectssystem"rakedataspider:import_projects_ninja"para"OK"endendend我想做的是,当我单击“导入项目”按钮时,我想在Controller中执行rake任务。但是我无法访问该方法。可能是什