在hive的开发交互中,有时需要获取hive表数据在hdfs中的location位置、或者获取hive的文件存储格式、使用的压缩算法,甚至是表中的字段类型、字段注释、字段约束、表中是否有数据、数据大小、文件数等信息。这些信息hive没有提供统一的入口,即使直连hive元数据存储的mysql数据库,也很难一次性拿到这些数据。
但是hive提供的desc命令则可以一次性获取所有的这些信息,例如:
desc formatted tableName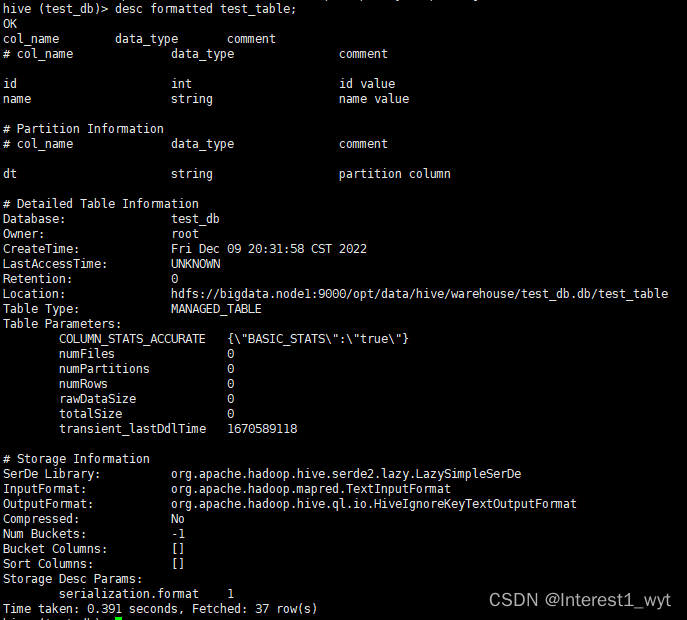
(注:我这里用的是2.3.9版本,加不了约束,所以详细信息里面看不到约束)
不过,虽然desc可以一次性获取所有的这些信息,但是这些信息并不是封装好的,需要通过resultSet一行行读取。以前为了获取hive表存储地址,我解析过一次,但那个不够通用。所以这次准备封装一个通用的解析,避免自己重复造轮子。
public static Map<String, Object> getTableInfo(ResultSet resultSet) throws Exception {
Map<String, Object> result = new HashMap<>();
// 定义多个集合用于存储hive不同模块的元数据
Map<String, String> detailTableInfo = new HashMap<>();
Map<String, String> tableParams = new HashMap<>();
Map<String, String> storageInfo = new HashMap<>();
Map<String, String> storageDescParams = new HashMap<>();
Map<String, Map<String, String>> constraints = new HashMap<>();
List<Map<String, String>> columns = new ArrayList<>();
List<Map<String, String>> partitions = new ArrayList<>();
Map<String, String> moduleMap = getDescTableModule();
// 解析resultSet获得原始的分块数据
String infoModule = "";
while (resultSet.next()) {
String title = resultSet.getString(1).trim();
if (("".equals(title) && resultSet.getString(2) == null) || "# Constraints".equals(title)) continue;
if (moduleMap.containsKey(title)) {
if ("partition_info".equals(infoModule) && "col_name".equals(moduleMap.get(title))) continue;
;
infoModule = moduleMap.get(title);
continue;
}
String key = null;
String value = null;
switch (infoModule) {
case "col_name":
Map<String, String> map = new HashMap<>();
int colNum = resultSet.getMetaData().getColumnCount();
for (int col = 0; col < colNum; col++) {
String columnName = resultSet.getMetaData().getColumnName(col + 1);
String columnValue = resultSet.getString(columnName);
map.put(columnName, columnValue);
}
columns.add(map);
break;
case "table_info":
key = resultSet.getString(1).trim().replace(":", "");
value = resultSet.getString(2).trim();
detailTableInfo.put(key, value);
break;
case "table_param":
key = resultSet.getString(2).trim().replace(":", "");
value = resultSet.getString(3).trim();
tableParams.put(key, value);
break;
case "storage_info":
key = resultSet.getString(1).trim().replace(":", "");
value = resultSet.getString(2).trim();
storageInfo.put(key, value);
break;
case "storage_desc":
key = resultSet.getString(2).trim().replace(":", "");
value = resultSet.getString(3).trim();
storageDescParams.put(key, value);
break;
case "not_null_constraint":
Map<String, String> notNullMap = constraints.getOrDefault("notnull", new HashMap<>());
if ("Table:".equals(title.trim())) resultSet.next();
String notNullConstraintName = resultSet.getString(2).trim();
resultSet.next();
key = resultSet.getString(2).trim();
notNullMap.put(key, notNullConstraintName);
constraints.put("notnull", notNullMap);
break;
case "default_constraint":
Map<String, String> defaultMap = constraints.getOrDefault("default", new HashMap<>());
if ("Table:".equals(title.trim())) resultSet.next();
String defaultConstraintName = resultSet.getString(2).trim();
resultSet.next();
key = resultSet.getString(1).trim().split(":")[1];
value = resultSet.getString(2).trim();
int valueIndex = value.indexOf(":");
value = value.substring(valueIndex + 1);
defaultMap.put(key + "_constraintName", defaultConstraintName);
constraints.put("default", defaultMap);
break;
case "partition_info":
Map<String, String> partitionMap = new HashMap<>();
int partitionColNum = resultSet.getMetaData().getColumnCount();
for (int col = 0; col < partitionColNum; col++) {
String columnName = resultSet.getMetaData().getColumnName(col + 1);
String columnValue = resultSet.getString(columnName);
partitionMap.put(columnName, columnValue);
}
partitions.add(partitionMap);
break;
default:
System.out.print("unknown module,please update method to support it : " + infoModule);
}
}
result.put("columns",columns);
result.put("detailTableInfo",detailTableInfo);
result.put("tableParams",tableParams);
result.put("storageInfo",storageInfo);
result.put("storageDescParams",storageDescParams);
result.put("constraints",constraints);
result.put("partitions",partitions);
return result;
}
private static Map<String, String> getDescTableModule() {
Map<String, String> descTableModule = new HashMap<>();
descTableModule.put("# col_name", "col_name");
descTableModule.put("# Detailed Table Information", "table_info");
descTableModule.put("Table Parameters:", "table_param");
descTableModule.put("# Storage Information", "storage_info");
descTableModule.put("Storage Desc Params:", "storage_desc");
descTableModule.put("# Not Null Constraints", "not_null_constraint");
descTableModule.put("# Default Constraints", "default_constraint");
descTableModule.put("# Partition Information", "partition_info");
return descTableModule;
}上面的代码基本上覆盖了所有常用的数据模块,如果有代码中没解析到的模块,则依据代码逻辑添加对应的模块名称和case模块即可。代码很简单,主要就是解析时要细心。
下面是我新建的一个简单测试demo,有兴趣的可以简单看下:
1)引入依赖
<!-- hive-jdbc -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.3.9</version>
</dependency>2)编辑代码
public static void main(String[] args) {
try {
String driverName = "org.apache.hive.jdbc.HiveDriver";
Class.forName(driverName);
Connection conn = DriverManager.getConnection("jdbc:hive2://192.168.71.135:10000/test_db");
String sql = "desc formatted test_table";
PreparedStatement ps = conn.prepareStatement(sql);
ResultSet resultSet = ps.executeQuery();
Map<String,Object> result = getTableInfo(resultSet);
System.out.println(result.size());
} catch (Exception throwables) {
throwables.printStackTrace();
}
}3)结果显示
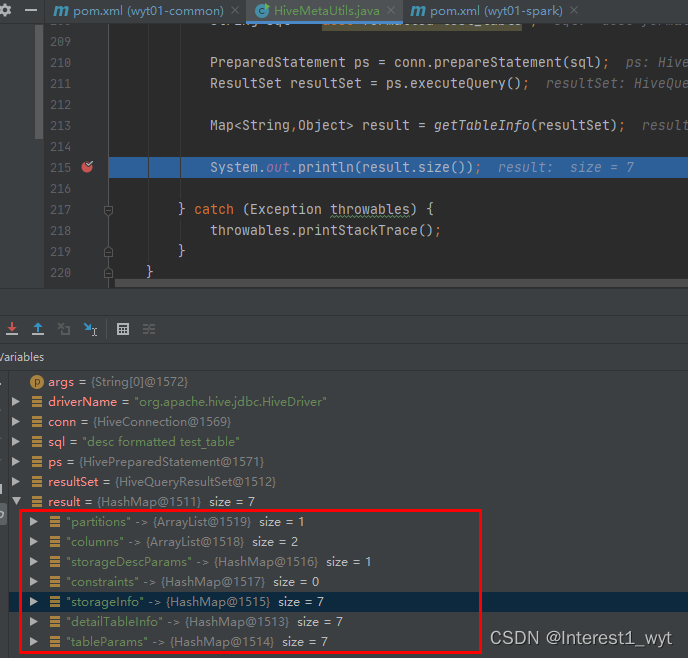
可以看到除了约束之外,其它的数据都正常的存入到了对应的集合中。(我测试用的2.3.9版本的约束创建有问题,但是在3.1.0版本中创建约束是正常的)。
4、总结
上面是我根据自己的需求使用进行的代码编辑,其基本包含了全部的表信息。但是也有可能有没考虑周到的地方,比如我一开始没考虑到多个同种约束的问题,在使用中遇到问题了又来重新更新了文章中的代码。所以如果使用中有些地方解析不对,可能需要您根据自己的实际场景再进行改写。
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
我有一个存储主机名的Ruby数组server_names。如果我打印出来,它看起来像这样:["hostname.abc.com","hostname2.abc.com","hostname3.abc.com"]相当标准。我想要做的是获取这些服务器的IP(可能将它们存储在另一个变量中)。看起来IPSocket类可以做到这一点,但我不确定如何使用IPSocket类遍历它。如果它只是尝试像这样打印出IP:server_names.eachdo|name|IPSocket::getaddress(name)pnameend它提示我没有提供服务器名称。这是语法问题还是我没有正确使用类?输出:ge
我想获取模块中定义的所有常量的值:moduleLettersA='apple'.freezeB='boy'.freezeendconstants给了我常量的名字:Letters.constants(false)#=>[:A,:B]如何获取它们的值的数组,即["apple","boy"]? 最佳答案 为了做到这一点,请使用mapLetters.constants(false).map&Letters.method(:const_get)这将返回["a","b"]第二种方式:Letters.constants(false).map{|c
我安装了ruby版本管理器,并将RVM安装的ruby实现设置为默认值,这样'哪个ruby'显示'~/.rvm/ruby-1.8.6-p383/bin/ruby'但是当我在emacs中打开inf-ruby缓冲区时,它使用安装在/usr/bin中的ruby。有没有办法让emacs像shell一样尊重ruby的路径?谢谢! 最佳答案 我创建了一个emacs扩展来将rvm集成到emacs中。如果您有兴趣,可以在这里获取:http://github.com/senny/rvm.el
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
如何在Ruby中获取BasicObject实例的类名?例如,假设我有这个:classMyObjectSystem我怎样才能使这段代码成功?编辑:我发现Object的实例方法class被定义为returnrb_class_real(CLASS_OF(obj));。有什么方法可以从Ruby中使用它? 最佳答案 我花了一些时间研究irb并想出了这个:classBasicObjectdefclassklass=class这将为任何从BasicObject继承的对象提供一个#class您可以调用的方法。编辑评论中要求的进一步解释:假设你有对象
是否可以在应用程序中包含的gem代码中知道应用程序的Rails文件系统根目录?这是gem来源的示例:moduleMyGemdefself.included(base)putsRails.root#returnnilendendActionController::Base.send:include,MyGem谢谢,抱歉我的英语不好 最佳答案 我发现解决类似问题的解决方案是使用railtie初始化程序包含我的模块。所以,在你的/lib/mygem/railtie.rbmoduleMyGemclassRailtie使用此代码,您的模块将在