由于大多数开源SLAM算法中都基于ROS开发,各传感器采集的数据通常以ROS的消息类型(sensor_msgs)进行发布和订阅。就激光雷达(LiDAR)而言,采集的原始点云数据通常以sensor_msgs::PointCloud2的数据类型进行发布,在算法中对点云进行处理时,调用点云开源算法库(PCL)中的功能可以便捷的实现相应功能。PCL库内部也定义了自己的点云数据结构。因此,在处理前,首先需要将点云由ROS的数据类型转换为PCL的数据类型。
ROS中的点云数据类型
sensor_msgs::PointCloud:该类型属于较早的版本,以逐渐弃用。
sensor_msgs::PointCloud2:目前常用的点云数据类型
PCL 中的点云数据类型
pcl::PointCloud<T>:点云以模板的形式定义,可以用pcl定义好的,也可以自定义
本文旨在分享如何将 sensor_msgs::PointCloud2 转换为 pcl::PointCloud<T>。
官方文档说明:ROS sensor_msgs/PointCloud2
std_msgs/Header header:数据头,包含该帧点云的时间戳、坐标系等属性信息
uint32 height:data的高度,一帧点云通常height=1,即表示无序点云;
uint32 width:data的宽度,即每行对应点的数量;
sensor_msgs/PointField[] fields:包含每个点的字段属性信息,详见下文。
bool is_bigendian:点云是否按正序排列
uint32 point_step:每个点占用的比特数,1字节=8比特,与PointField里所有字节数之和相等。
uint32 row_step:每行占用的比特数,=点的数量*Point_step;
uint8[] data:序列化后的点云二进制数据,所有点信息都在一串字符中,无法通过data[i]取值。
bool is_dense:是否存在无效点。
最值得关注的变量是:fields。
官方文档:sensor_msgs/PointField[] fields
string name # 点的字段名
uint32 offset # 相对于结构体起始地址的字节数
uint8 datatype # 该字段所占用的字节数
uint32 count # 该字段的数量,通常为1
datatype 不同值与类型的对应如下:
uint8 INT8 = 1 // 1字节
uint8 UINT8 = 2 // 1字节
uint8 INT16 = 3 // 2字节
uint8 UINT16 = 4 // 2字节
uint8 INT32 = 5 // 4字节
uint8 UINT32 = 6 // 4字节
uint8 FLOAT32 = 7 // 4字节
uint8 FLOAT64 = 8 // 8字节
以某开源数据包为例,回放bag包,编写一个ROS节点订阅其LiDAR数据,代码可参考示例。
VLP-16发布点云的类型为PointCloud2。其fields如下图所示:
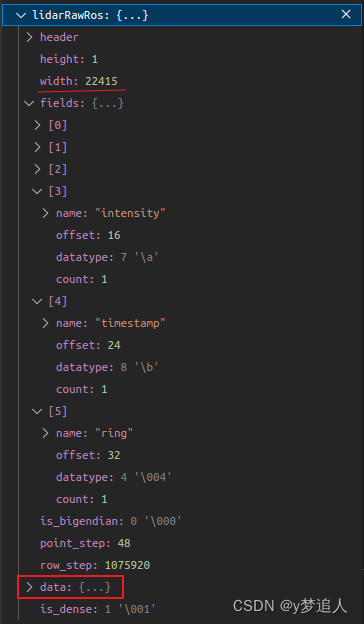
其中:
name值为每个点对应的字段名称,
datatype
fields[0]、fields[1]、fields[2]分别为每个点的x、y、z坐标字段,均为float类型,4个字节。
fields[3]为点云反射强度、float类型,4个字节。
fields[4]为每个点对应的时间戳,double类型,8个字节,64比特,
fields[5]为每个点对应的线ID,值为0~15,2个字节。
PCL中的功能函数多以模板的形式实现,可以使用多种点云类型,
一个典型的PCL点云类型为:X、Y、Z + 其他属性(反射强度、时间、RGB等等)
在将ROS点云转换为PCL点云时,我们期望转换前后,点云拥有相同的属性值,而不是具有反射强度的点云,格式转换后只剩XYZ坐标了。对于普通的点云,PCL定义好的点云数据结构即可满足需求。但是对于特殊点云,我们需要自定义点云结构体。
以LIO-SAM中的一段代码为例,定义自己的PCL点云类型的代码如下:
//定义每个点的数据结构
struct VelodynePointXYZIRT
{
PCL_ADD_POINT4D //XYZ,PCL宏
PCL_ADD_INTENSITY; //反射强度,PCL宏
uint16_t ring; //线ID
float time; //时间
EIGEN_MAKE_ALIGNED_OPERATOR_NEW //PCL宏,确保new操作符对其操作,无须理解,用就完了
} EIGEN_ALIGN16;
//注册点类型宏
POINT_CLOUD_REGISTER_POINT_STRUCT (VelodynePointXYZIRT,
(float, x, x) (float, y, y) (float, z, z) (float, intensity, intensity)
(uint16_t, ring, ring) (float, time, time)
)在自定义点云结构体PointT时,需根据传入的sensor_msgs::PointCloud2的fields来定义,
两点要求:
1、自定义结构体的字段命名、数量、顺序需要与fields中的name一致;
2、自定义结构体字段占用的字节数需与datatype一致。比如datatype=7,那么要用float。
若PointT的字段与fields name不一致,编译不会报错,但是运行时,会警告“Failed to find match for field *** ”。
若PointT的字节数与fields datatype不一致,则会取出错误的值,类似指针。本来取4个字节,结果取了8个字节,得到的点云信息肯定是错的,但编译器不提示。
ROS中已经集成了对PCL的API接口,PCL中也集成了用于转换的结构体PCLPointCloud2。因此我们可以直接调用函数。
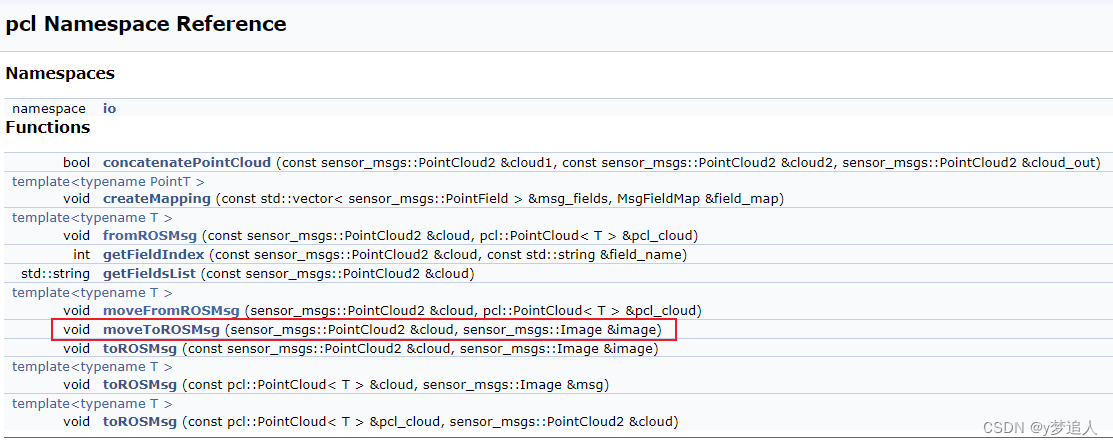
ROS的PCL转换接口主要在pcl_conversions.h中,里边提供了丰富的类型转换函数。实际上,该函数是基于pcl的功能实现了类型转换,对应pcl的函数文件conversions.h
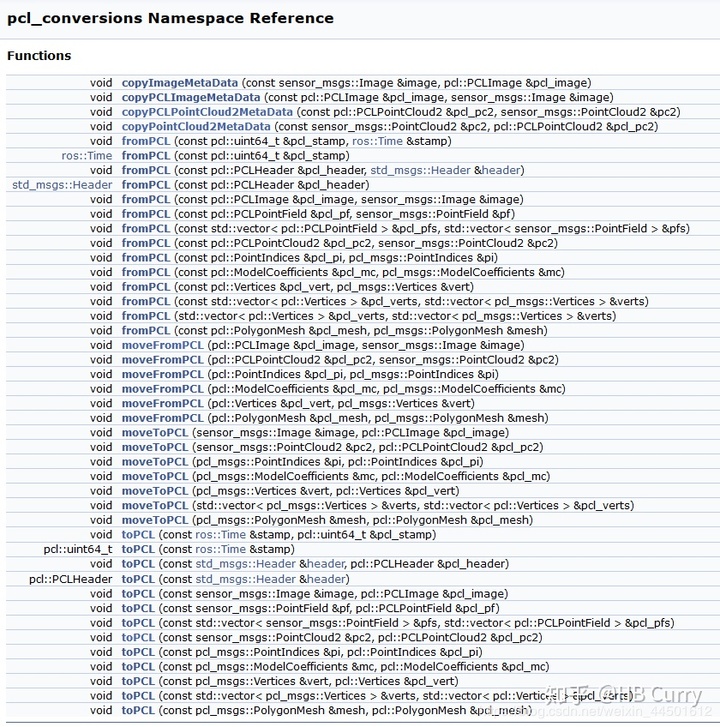
函数名中带move和不带move的区别是,移动(剪切)和拷贝的区别。可以自行转到定义查看他复制data时的操作。
本人使用的是moveFromROSMsg() 函数。首先由ROS的sensor_msgs::PointCloud2类型转换为PCL的pcl::PCLPointCloud2类型,然后再由PCL的pcl::PCLPointCloud2类型转换为PCL的pcl::PointCloud<T>。
template<typename T>
void moveFromROSMsg(sensor_msgs::PointCloud2 &cloud, pcl::PointCloud<T> &pcl_cloud)
{
pcl::PCLPointCloud2 pcl_pc2;
pcl_conversions::moveToPCL(cloud, pcl_pc2);
pcl::fromPCLPointCloud2(pcl_pc2, pcl_cloud);
}
先来看一下第一个函数:pcl_conversions::moveToPCL()
inline
void moveToPCL(sensor_msgs::PointCloud2 &pc2, pcl::PCLPointCloud2 &pcl_pc2)
{
copyPointCloud2MetaData(pc2, pcl_pc2);
pcl_pc2.data.swap(pc2.data);
}
inline
void copyPointCloud2MetaData(const sensor_msgs::PointCloud2 &pc2, pcl::PCLPointCloud2 &pcl_pc2)
{
toPCL(pc2.header, pcl_pc2.header);
pcl_pc2.height = pc2.height;
pcl_pc2.width = pc2.width;
toPCL(pc2.fields, pcl_pc2.fields);
pcl_pc2.is_bigendian = pc2.is_bigendian;
pcl_pc2.point_step = pc2.point_step;
pcl_pc2.row_step = pc2.row_step;
pcl_pc2.is_dense = pc2.is_dense;
}
inline
void toPCL(const sensor_msgs::PointField &pf, pcl::PCLPointField &pcl_pf)
{
pcl_pf.name = pf.name;
pcl_pf.offset = pf.offset;
pcl_pf.datatype = pf.datatype;
pcl_pf.count = pf.count;
}由于两个PointCloud2的定义几乎一样,所以这个转换只是简单的copy,field也是copy。
然后重点是第二个函数pcl::fromPCLPointCloud2(),第一步根据源点云的field表和目标点云类型PointT创建一个字段索引map(翻译比较蹩脚,建议直接按英文理解),第二步是从data里按照数据格式逐个memcpy点信息。
fromPCLPointCloud2 (const pcl::PCLPointCloud2& msg, pcl::PointCloud<PointT>& cloud)
{
MsgFieldMap field_map;
createMapping<PointT> (msg.fields, field_map); //创建一个field索引表
fromPCLPointCloud2 (msg, cloud, field_map); //转换点云
}
template<typename PointT> void
createMapping (const std::vector<pcl::PCLPointField>& msg_fields, MsgFieldMap& field_map)
{
// Create initial 1-1 mapping between serialized data segments and struct fields
detail::FieldMapper<PointT> mapper (msg_fields, field_map);
for_each_type< typename traits::fieldList<PointT>::type > (mapper);
// Coalesce adjacent fields into single memcpy's where possible
if (field_map.size() > 1)
{
std::sort(field_map.begin(), field_map.end(), detail::fieldOrdering);
MsgFieldMap::iterator i = field_map.begin(), j = i + 1;
while (j != field_map.end())
{
// This check is designed to permit padding between adjacent fields.
/// @todo One could construct a pathological case where the struct has a
/// field where the serialized data has padding
if (j->serialized_offset - i->serialized_offset == j->struct_offset - i->struct_offset)
{
i->size += (j->struct_offset + j->size) - (i->struct_offset + i->size);
j = field_map.erase(j);
}
else
{
++i;
++j;
}
}
}
}
// Return true if the PCLPointField matches the expected name and data type.
// Written as a struct to allow partially specializing on Tag.
template<typename PointT, typename Tag>
struct FieldMatches
{
bool operator() (const pcl::PCLPointField& field)
{
return (field.name == traits::name<PointT, Tag>::value &&
field.datatype == traits::datatype<PointT, Tag>::value &&
(field.count == traits::datatype<PointT, Tag>::size ||
field.count == 0 && traits::datatype<PointT, Tag>::size == 1 /* see bug #821 */));
}
};这个函数的主要作用是,程序也不知道你输入的PointT和原始点云的类型匹配不匹配,比如你的点云是XYZI类型的,非要转成XYZIRGB的也不行啊,所以要检核一下,找出那些匹配的点属性。createMapping()函数的关键在第一行:
FieldMapper<PointT> (msg_fields) (field_map)中,使用FieldMatches()函数,看看fields与PointT是否匹配:
1、命名要匹配,比如field中叫time,PointT中的也要有叫“time”的字段才行
2、字节大小匹配,field中time是4个字节的,PointT中就要定义time是float32类型的。
这对于后边用指针拷贝每个点的每个属性时,计算地址时很重要,千万不能错。
最后得到的field_map就是哪些匹配成功的字段及它的相对地址(struct_offset和serialized_offset)
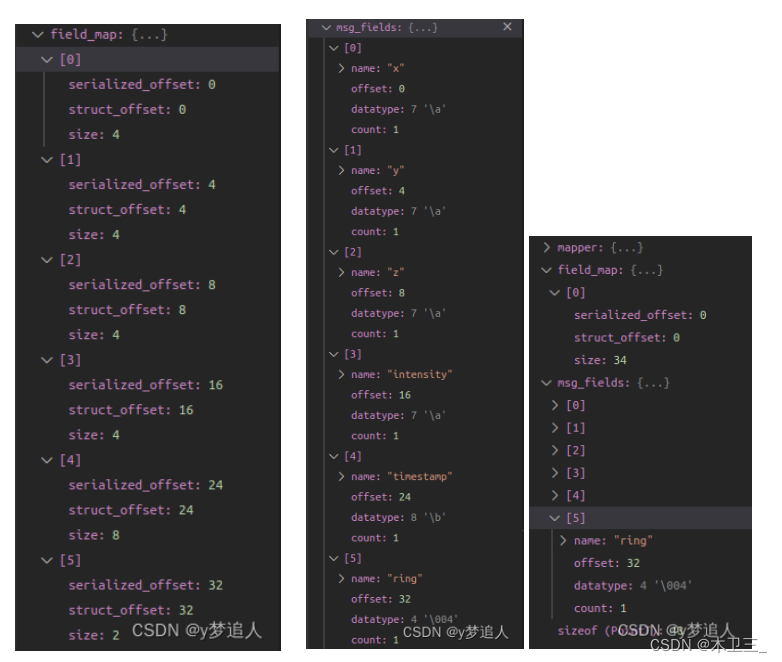
如果相邻的field都能成功匹配,就把这两个字段对应的字节大小合并,
比如三个相邻字段分别对应4字节+4字节+8字节,那我不必一个字段一个字段拷贝,直接拷贝16个字节就好了。
最后就是拷贝点云了:fromPCLPointCloud2 (msg, cloud, field_map),代码如下,
关键代码,首先cloud_data指向第1个点的地址,然后根据对应每个点字节大小步长,以及field_map索引表,用memcpy逐个field、逐个点拷贝。
template <typename PointT> void
fromPCLPointCloud2 (const pcl::PCLPointCloud2& msg, pcl::PointCloud<PointT>& cloud,
const MsgFieldMap& field_map)
{
// Copy info fields
cloud.header = msg.header;
cloud.width = msg.width;
cloud.height = msg.height;
cloud.is_dense = msg.is_dense == 1;
// Copy point data
uint32_t num_points = msg.width * msg.height;
cloud.points.resize (num_points);
uint8_t* cloud_data = reinterpret_cast<uint8_t*>(&cloud.points[0]);
// Check if we can copy adjacent points in a single memcpy
if (field_map.size() == 1 &&
field_map[0].serialized_offset == 0 &&
field_map[0].struct_offset == 0 &&
msg.point_step == sizeof(PointT))
{
balabala //太长了删掉这段没用的
}
else
{
// If not, memcpy each group of contiguous fields separately
for (uint32_t row = 0; row < msg.height; ++row)
{
const uint8_t* row_data = &msg.data[row * msg.row_step];
for (uint32_t col = 0; col < msg.width; ++col)
{
const uint8_t* msg_data = row_data + col * msg.point_step;
BOOST_FOREACH (const detail::FieldMapping& mapping, field_map)
{
memcpy (cloud_data + mapping.struct_offset, msg_data + mapping.serialized_offset, mapping.size);
}
cloud_data += sizeof (PointT);
}
}
}
}
代码比较多,希望耐心看完,如文中有所纰漏,欢迎指点和交流。
希望上述内容对您有帮助。
可供参考的其他官方文档: 在ROS中使用PCL
我可以得到Infinity和NaNn=9.0/0#=>Infinityn.class#=>Floatm=0/0.0#=>NaNm.class#=>Float但是当我想直接访问Infinity或NaN时:Infinity#=>uninitializedconstantInfinity(NameError)NaN#=>uninitializedconstantNaN(NameError)什么是Infinity和NaN?它们是对象、关键字还是其他东西? 最佳答案 您看到打印为Infinity和NaN的只是Float类的两个特殊实例的字符串
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
我想使用PostgreSQL中的point类型。我已经完成了:railsgmodelTestpoint:point最终的迁移是:classCreateTests当我运行时:rakedb:migrate结果是:==CreateTests:migrating====================================================--create_table(:tests)rakeaborted!Anerrorhasoccurred,thisandalllatermigrationscanceled:undefinedmethod`point'for#/hom
希望我没有误解“ducktyping”的含义,但从我读到的内容来看,这意味着我应该根据对象如何响应方法而不是它是什么类型/类来编写代码。代码如下:defconvert_hash(hash)ifhash.keys.all?{|k|k.is_a?(Integer)}returnhashelsifhash.keys.all?{|k|k.is_a?(Property)}new_hash={}hash.each_pair{|k,v|new_hash[k.id]=v}returnnew_hashelseraise"CustomattributekeysshouldbeID'sorPropertyo
我试图像这样在我的测试用例中执行获取:request.env['CONTENT_TYPE']='application/json'get:index,:application_name=>"Heka"虽然,它失败了:ActionView::MissingTemplate:Missingtemplatealarm_events/indexwith{:handlers=>[:builder,:haml,:erb,:rjs,:rhtml,:rxml],:locale=>[:en,:en],:formats=>[:html]尽管在我的Controller中我有:respond_to:html,
我有代码:classScenedefinitialize(number)@number=numberendattr_reader:numberendscenes=[Scene.new("one"),Scene.new("one"),Scene.new("two"),Scene.new("one")]groups=scenes.inject({})do|new_hash,scene|new_hash[scene.number]=[]ifnew_hash[scene.number].nil?new_hash[scene.number]当我启动它时出现错误:freq.rb:11:in`[]'
文章目录1.自动驾驶实战:基于Paddle3D的点云障碍物检测1.1环境信息1.2准备点云数据1.3安装Paddle3D1.4模型训练1.5模型评估1.6模型导出1.7模型部署效果附录show_lidar_pred_on_image.py1.自动驾驶实战:基于Paddle3D的点云障碍物检测项目地址——自动驾驶实战:基于Paddle3D的点云障碍物检测课程地址——自动驾驶感知系统揭秘1.1环境信息硬件信息CPU:2核AI加速卡:v100总显存:16GB总内存:16GB总硬盘:100GB环境配置Python:3.7.4框架信息框架版本:PaddlePaddle2.4.0(项目默认框架版本为2.3