
目录
尚硅谷资料包i中的文件复制到非中文路径

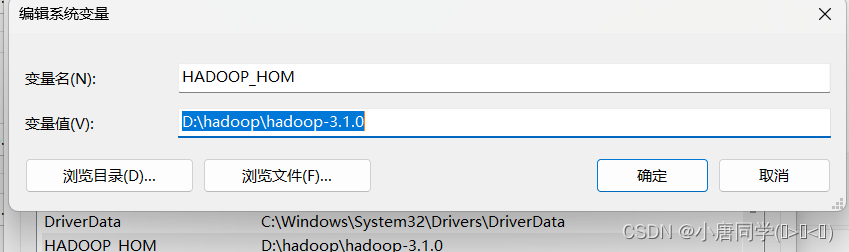
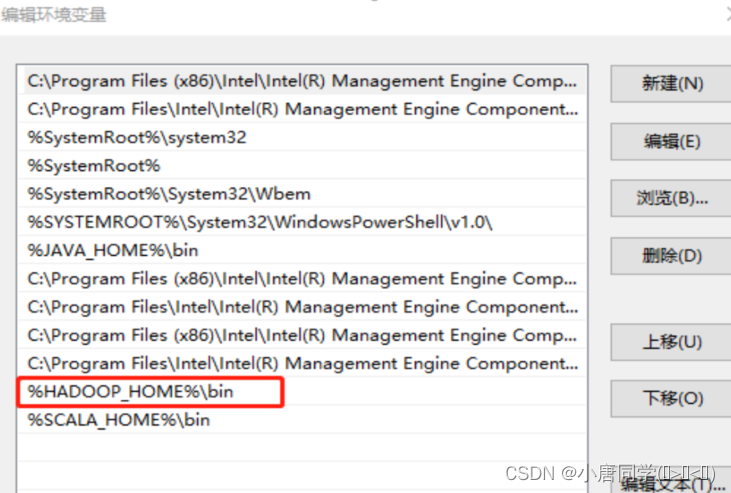
验证Hadoop环境变量是否正常。双击winutils.exe,如果报如下错误。说明缺少微软运行库(正版系统往往有这个问题)。再资料包里面有对应的微软运行库安装包双击安装即可
新建maven项目工程
让后设置换你的maven库(换成你本机上的阿里,不然有些依赖你是下载不下来的,而且下载慢)
导入maven依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>HDFSClient</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
</project>在项目的src/main/resources目录(该目录主要放置配置文件 ,页面文件 、静态资源文件)下,新建一个文件,命名为“log4j.properties”,该文件与日志相关,在文件中填入
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%ncom.xxx.hdfs
创建HdfsClient类
现在本人已经完成了部分API操作,先描述一下HdfsClient类的分布
因为HDFS的API操作会有很多冗余代码,所以我们对他进行了封装,
这个代码主要是Java连接集群,获取集群的配置文件,并且获取客户端连接对象,使用注解@Before (不懂注解的可以看我的另一篇文章 点击直接跳转,在这不多做解释 注解讲解 )便于后续的使用
这个代码主要用于关闭资源,就是把一个简单的close 进行了封装 使用注解 @After 同上不做解释,需要的话跳转另一篇文章
使用注解@Test进行测试,调用的还是Linux中的mkdir 让客户端连接对象进行调用(**注意 这里 客户端连接对象要在类的上方使用private进行定义,方便在下方方法中的调用)
@Test
public void testmkdir() throws Exception{
//此时window与namenode 节点的虚拟机已经连接成功 执行命令,创建文件夹
fs.mkdirs(new Path("/xiyou"));
}通过客户端远程访问hdfs 上传文件
copyFromLocalFile方法用于上传数据 参数1: 删除原数据 参数2: 是否允许覆盖(原文件存在) 参数3: 原数据路径(本地路径) 参数4:目的地路径
@Test
public void testput() throws IOException {
//参数1: 删除原数据 参数2: 是否允许覆盖(原文件存在) 参数3: 原数据路径(本地路径) 参数4:目的地路径
fs.copyFromLocalFile(false,true,new Path("D:\\Hadoop3.1.3.txt\\"),new Path("hdfs://hadoop102/xiyou/huaguoshan"));
}hdfs下载到window本地
copyToLocalFile方法用于下载文件 参数解析 1:原文件是否删除 2.原文件hdfs的路径 3.目标地址路径 4. false 是开启crc校验 true 是不开启
@Test
public void testGet() throws Exception {
// 参数解析 1:原文件是否删除 2.原文件hdfs的路径 3.目标地址路径 4. false 是开启crc校验 true 是不开启
fs.copyToLocalFile(false,new Path("hdfs://hadoop102/jinguo/shuguo.txt"),new Path("D:\\jinchao"),false);
}文件的删除分为:删除非空目录,删除空目录
delete方法删除文件,当问及那非空的时候必须递归删除
fs.delete(new Path("hdfs://hadoop102/xiyou"),true);delete删除空目录的时候可以不是递归删除
fs.delete(new Path("/xiyou"));
整体代码:
@Test
public void testRm() throws Exception {
// 1. 要删除的路径 2 是否递归路径
fs.delete(new Path("hdfs://hadoop102/xiyou"),true);
// 删除空目录 不需要递归
fs.delete(new Path("/xiyou"));
// 删除非空目录 必须递归删除
}文件移动分为很多,根据参数的不同,做出不同的操作,都是调用rename方法
代码注释有详细解释
@Test
public void testmv() throws IOException {
// 对文件的移动 1.原文件路径 2.目标路径
// fs.rename(new Path("/jinguo/shuguo.txt"),new Path("/output"));
// 修改文件的名称
// fs.rename(new Path("/output/shuguo.txt"),new Path("/output/reshuguo.txt"));
//修改名称并且移动位置
// fs.rename(new Path("/output/reshuguo.txt"),new Path("/jinguo/shuguo.txt"));
// 目录更名
fs.rename(new Path("/outputtwo"),new Path("/output2"));
}查看hdfs上文件详情 比如
文件名称 权限 长度 块信息
@Test
public void testListFiles() throws IOException {
//参数 1.需要查看文件的路径 2.是否递归
//返回迭代器 递归 相当于栈 后进先出 递归是从底层向上进行遍历 针对的是文件不是目录
// fileStatus 返回的是数组
//listFiles 返回的是迭代器
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while(listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println("======"+fileStatus.getPath()+"=====");
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getModificationTime());
System.out.println(fileStatus.getReplication());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPath().getName());
//查看块的存储信息--(备份)存储在那几个服务器上
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
}调用方法的解释:

先解释参数: 1.需要查看文件的路径 2.是否递归
返回值:返回的形式是迭代器(迭代器是一种设计模式,官方话不多数,说一下自己的理解可能不贴切---个人认为迭代器就像把数据封装成一个数据库一样,包含各种属性,每一条信息就是一个元组)
获取迭代器后就是迭代器的操作了
文件和文件夹的判断也分为两种,一种是可迭代的,一种是不可迭代的
个人感觉还是使用迭代器进行递归判断操作方便一点
下边有两种 一种利用迭代器进行递归判断,一种是非递归判断
@Test
public void testFile() throws IOException {
//可迭代判断
RemoteIterator<LocatedFileStatus> locatedFileStatusRemoteIterator = fs.listFiles(new Path("/"), true);
while(locatedFileStatusRemoteIterator.hasNext())
{
LocatedFileStatus next = locatedFileStatusRemoteIterator.next();
if (next.isFile()) {
System.out.println("这是文件"+next.getPath().getName());
}
else
{
System.out.println("这是目录"+next.getPath().getName());
}
}
// 不可迭代判断
// FileStatus[] fileStatuses = fs.listStatus(new Path("/"));
// for (FileStatus fileStatus : fileStatuses) {
// if (fileStatus.isFile()) { //判断fileStatus是否是文件
//
// System.out.println("这是文件"+fileStatus.getPath().getName());
//
// }
// else
// {
// System.out.println("这是目录"+fileStatus.getPath().getName());
// }
我有用于控制用户任务的Rails5API项目,我有以下错误,但并非总是针对相同的Controller和路由。ActionController::RoutingError:uninitializedconstantApi::V1::ApiController我向您描述了一些我的项目,以更详细地解释错误。应用结构路线scopemodule:'api'donamespace:v1do#=>Loginroutesscopemodule:'login'domatch'login',to:'sessions#login',as:'login',via::postend#=>Teamroutessc
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
我正在使用Mandrill的RubyAPIGem并使用以下简单的测试模板:testastic按照Heroku指南中的示例,我有以下Ruby代码:require'mandrill'm=Mandrill::API.newrendered=m.templates.render'test-template',[{:header=>'someheadertext',:main_section=>'Themaincontentblock',:footer=>'asdf'}]mail(:to=>"JaysonLane",:subject=>"TestEmail")do|format|format.h
我正在尝试使用Ruby2.0.0和Rails4.0.0提供的API从imgur中提取图像。我已尝试按照Ruby2.0.0文档中列出的各种方式构建http请求,但均无济于事。代码如下:require'net/http'require'net/https'defimgurheaders={"Authorization"=>"Client-ID"+my_client_id}path="/3/gallery/image/#{img_id}.json"uri=URI("https://api.imgur.com"+path)request,data=Net::HTTP::Get.new(path
Rails相对较新。我正在尝试调用一个API,它应该向我返回一个唯一的URL。我的应用程序中捆绑了HTTParty。我已经创建了一个UniqueNumberController,并且我已经阅读了几个HTTParty指南,直到我想要什么,但也许我只是有点迷路,真的不知道该怎么做。基本上,我需要做的就是调用API,获取它返回的URL,然后将该URL插入到用户的数据库中。谁能给我指出正确的方向或与我分享一些代码? 最佳答案 假设API为JSON格式并返回如下数据:{"url":"http://example.com/unique-url"
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我的公司有一个巨大的数据库,该数据库接收来自多个来源的(许多)事件,用于监控和报告目的。到目前为止,数据中的每个新仪表板或图形都是一个新的Rails应用程序,在巨大的数据库中有额外的表,并且可以完全访问数据库内容。最近,有一个想法让外部(不是我们公司,而是姊妹公司)客户访问我们的数据,并且决定我们应该公开一个只读的RESTfulAPI来查询我们的数据。我的观点是-我们是否也应该为我们的自己
a=[3,4,7,8,3]b=[5,3,6,8,3]假设数组长度相同,是否有办法使用each或其他一些惯用方法从两个数组的每个元素中获取结果?不使用计数器?例如获取每个元素的乘积:[15,12,42,64,9](0..a.count-1).eachdo|i|太丑了...ruby1.9.3 最佳答案 使用Array.zip怎么样?:>>a=[3,4,7,8,3]=>[3,4,7,8,3]>>b=[5,3,6,8,3]=>[5,3,6,8,3]>>c=[]=>[]>>a.zip(b)do|i,j|c[[3,5],[4,3],[7,6],