
文章目录
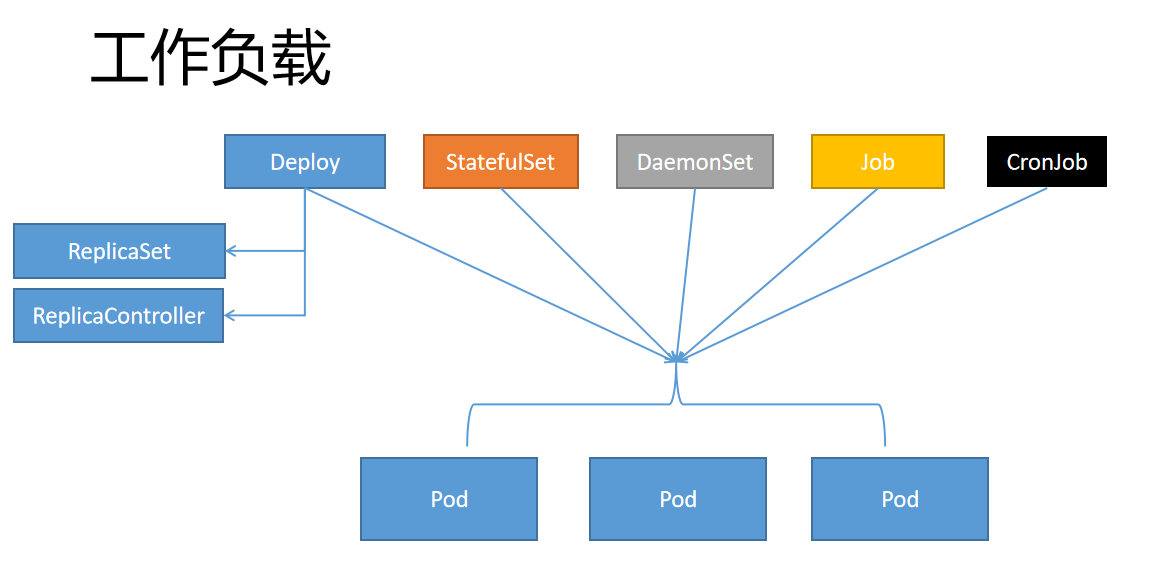
什么是工作负载(Workloads)
工作负载是运行在 Kubernetes 上的一个应用程序。
一个应用很复杂,可能由单个组件或者多个组件共同完成。无论怎样我们可以用一组Pod来表示一个应用,也就是一个工作负载
Pod又是一组容器(Containers)
所以关系又像是这样
工作负载(Workloads)控制一组Pod
Pod控制一组容器(Containers)
比如Deploy(工作负载) 3个副本的nginx(3个Pod),每个nginx里面是真正的nginx容器(container)
关于Pod深入介绍已经在之前文章讲述过,有不了解的同学可以再看看以下文章
【云原生 | Kubernetes篇】深入了解Pod(六)_Lansonli的博客-CSDN博客
关于Deployment深入介绍已经在上一篇文章讲述过,有不了解的同学可以看看以下文章
【云原生 | Kubernetes篇】深入了解Deployment_Lansonli的博客-CSDN博客
关于这块内容已经在之前文章讲述过,有不了解的同学可以再看看以下文章
【云原生 | Kubernetes篇】深入RC、RS、DaemonSet、StatefulSet(七)_Lansonli的博客-CSDN博客
Kubernetes中的 Job 对象将创建一个或多个 Pod,并确保指定数量的 Pod 可以成功执行到进程正常结束:
当 Job 创建的 Pod 执行成功并正常结束时,Job 将记录成功结束的 Pod 数量
当成功结束的 Pod 达到指定的数量时,Job 将完成执行
删除 Job 对象时,将清理掉由 Job 创建的 Pod

apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never #Job情况下,不支持Always
backoffLimit: 4 #任务4次都没成,认为失败
activeDeadlineSeconds: 10#默认这个任务需要成功执行一次。
#查看job情况
kubectl get job
#修改下面参数设置再试试
#千万不要用阻塞容器。nginx。job由于Pod一直running状态。下一个永远得不到执行,而且超时了,当前running的Pod还会删掉
kubectl api-resources#参数说明
kubectl explain job.spec
activeDeadlineSeconds:10 总共维持10s
#该字段限定了 Job 对象在集群中的存活时长,一旦达到 .spec.activeDeadlineSeconds 指定的时长,该 Job 创建的所有的 Pod 都将被终止。但是Job不会删除,Job需要手动删除,或者使用ttl进行清理
backoffLimit:
#设定 Job 最大的重试次数。该字段的默认值为 6;一旦重试次数达到了 backoffLimit 中的值,Job 将被标记为失败,且尤其创建的所有 Pod 将被终止;
completions: #Job结束需要成功运行的Pods。默认为1
manualSelector:
parallelism: #并行运行的Pod个数,默认为1
ttlSecondsAfterFinished:
ttlSecondsAfterFinished: 0 #在job执行完时马上删除
ttlSecondsAfterFinished: 100 #在job执行完后,等待100s再删除
#除了 CronJob 之外,TTL 机制是另外一种自动清理已结束Job(Completed 或 Finished)的方式:
#TTL 机制由 TTL 控制器 提供,ttlSecondsAfterFinished 字段可激活该特性
#当 TTL 控制器清理 Job 时,TTL 控制器将删除 Job 对象,以及由该 Job 创建的所有 Pod 对象。
#job超时以后 已经完成的不删,正在运行的Pod就删除
#单个Pod时,Pod成功运行,Job就结束了
#如果Job中定义了多个容器,则Job的状态将根据所有容器的执行状态来变化。
#Job任务不建议去运行nginx,tomcat,mysql等阻塞式的,否则这些任务永远完不了。
#如果Job定义的容器中存在http server、mysql等长期的容器和一些批处理容器,则Job状态不会发生变化(因为长期运行的容器不会主动结束)。此时可以通过Pod的.status.containerStatuses获取指定容器的运行状态。manualSelector:
job同样可以指定selector来关联pod。需要注意的是job目前可以使用两个API组来操作,batch/v1和extensions/v1beta1。当用户需要自定义selector时,使用两种API组时定义的参数有所差异。
使用batch/v1时,用户需要将jod的spec.manualSelector设置为true,才可以定制selector。默认为false。
使用extensions/v1beta1时,用户不需要额外的操作。因为extensions/v1beta1的spec.autoSelector默认为false,该项与batch/v1的spec.manualSelector含义正好相反。换句话说,使用extensions/v1beta1时,用户不想定制selector时,需要手动将spec.autoSelector设置为true。
CronJob 按照预定的时间计划(schedule)创建 Job(注意:启动的是Job不是Deploy,rs)。一个 CronJob 对象类似于 crontab (cron table) 文件中的一行记录。该对象根据 Cron 格式定义的时间计划,周期性地创建 Job 对象。
Schedule
所有 CronJob 的
schedule中所定义的时间,都是基于 master 所在时区来进行计算的。
一个 CronJob 在时间计划中的每次执行时刻,都创建 大约 一个 Job 对象。这里用到了 大约 ,是因为在少数情况下会创建两个 Job 对象,或者不创建 Job 对象。尽管 K8S 尽最大的可能性避免这种情况的出现,但是并不能完全杜绝此现象的发生。因此,Job 程序必须是幂等的。
当以下两个条件都满足时,Job 将至少运行一次:
startingDeadlineSeconds 被设置为一个较大的值,或者不设置该值(默认值将被采纳)
concurrencyPolicy 被设置为 Allow
# kubectl explain cronjob.spec
concurrencyPolicy:并发策略
"Allow" (允许,default):
"Forbid"(禁止): forbids;前个任务没执行完,要并发下一个的话,下一个会被跳过
"Replace"(替换): 新任务,替换当前运行的任务failedJobsHistoryLimit:记录失败数的上限,Defaults to 1.
successfulJobsHistoryLimit: 记录成功任务的上限。 Defaults to 3.
#指定了 CronJob 应该保留多少个 completed 和 failed 的 Job 记录。将其设置为 0,则 CronJob 不会保留已经结束的 Job 的记录。jobTemplate: job怎么定义(与前面我们说的job一样定义法)
schedule: cron 表达式;
startingDeadlineSeconds: 表示如果Job因为某种原因无法按调度准时启动,在spec.startingDeadlineSeconds时间段之内,CronJob仍然试图重新启动Job,如果在.spec.startingDeadlineSeconds时间之内没有启动成功,则不再试图重新启动。如果spec.startingDeadlineSeconds的值没有设置,则没有按时启动的任务不会被尝试重新启动。
suspend 暂停定时任务,对已经执行了的任务,不会生效; Defaults to false.
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *" #分、时、日、月、周
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
什么是垃圾回收
Kubernetes garbage collector(垃圾回收器)的作用是删除那些曾经有 owner,后来又不再有 owner 的对象。
垃圾收集器如何删除从属对象
当删除某个对象时,可以指定该对象的从属对象是否同时被自动删除,这种操作叫做级联删除(cascading deletion)。级联删除有两种模式:后台(background)和前台(foreground)
如果删除对象时不删除自动删除其从属对象,此时,从属对象被认为是孤儿(或孤立的 orphaned)
通过参数 --cascade,kubectl delete 命令也可以选择不同的级联删除策略:
--cascade=true 级联删除
--cascade=false 不级联删除 orphan
#删除rs,但不删除级联Pod
kubectl delete replicaset my-repset --cascade=false我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我花了三天的时间用头撞墙,试图弄清楚为什么简单的“rake”不能通过我的规范文件。如果您遇到这种情况:任何文件夹路径中都不要有空格!。严重地。事实上,从现在开始,您命名的任何内容都没有空格。这是我的控制台输出:(在/Users/*****/Desktop/LearningRuby/learn_ruby)$rake/Users/*******/Desktop/LearningRuby/learn_ruby/00_hello/hello_spec.rb:116:in`require':cannotloadsuchfile--hello(LoadError) 最佳
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion在首页我有:汽车:VolvoSaabMercedesAudistatic_pages_spec.rb中的测试代码:it"shouldhavetherightselect"dovisithome_pathit{shouldhave_select('cars',:options=>['volvo','saab','mercedes','audi'])}end响应是rspec./spec/request
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
使用Ruby1.9.2运行IDE提示说需要gemruby-debug-base19x并提供安装它。但是,在尝试安装它时会显示消息Failedtoinstallgems.Followinggemswerenotinstalled:C:/ProgramFiles(x86)/JetBrains/RubyMine3.2.4/rb/gems/ruby-debug-base19x-0.11.30.pre2.gem:Errorinstallingruby-debug-base19x-0.11.30.pre2.gem:The'linecache19'nativegemrequiresinstall
我知道全局变量$!包含最新的异常对象,但我对下面的语法感到困惑。谁能帮助我理解以下语法?rescue$! 最佳答案 此构造可防止异常停止您的程序并使堆栈跟踪冒泡。它还会将该异常作为值返回,这很有用。a=get_me_datarescue$!在此行之后,a将保存请求的数据或异常。然后您可以分析该异常并采取相应措施。defget_me_dataraise'Nodataforyou'enda=get_me_datarescue$!puts"Executioncarrieson"pa#>>Executioncarrieson#>>#更现实的
我在我正在处理的一些代码中发现了这一点。它旨在解决从磁盘读取key文件的要求。在生产环境中,key文件的内容位于环境变量中。旧代码:key=File.read('path/to/key.pem')新代码:key=File.read('|echo$KEY_VARIABLE')这是如何工作的? 最佳答案 来自IOdocs:Astringstartingwith“|”indicatesasubprocess.Theremainderofthestringfollowingthe“|”isinvokedasaprocesswithappro
我今天看到了一个ruby代码片段。[1,2,3,4,5,6,7].inject(:+)=>28[1,2,3,4,5,6,7].inject(:*)=>5040这里的注入(inject)和之前看到的完全不一样,比如[1,2,3,4,5,6,7].inject{|sum,x|sum+x}请解释一下它是如何工作的? 最佳答案 没有魔法,符号(方法)只是可能的参数之一。这是来自文档:#enum.inject(initial,sym)=>obj#enum.inject(sym)=>obj#enum.inject(initial){|mem
我刚刚有一个关于RubyonRails和模型(Rails3)中的attr_accessible属性的一般性问题。有人可以解释应该在那里定义哪些模型属性吗?我记得一些关于批量分配风险的事情,虽然我在这方面不太了解......谢谢:) 最佳答案 想象一个带有一些字段的订单类:Order.new({:type=>'Corn',:quantity=>6})现在假设订单也有折扣代码,比如:price_off。您不想将:price_off标记为attr_accessible。这会阻止恶意代码制作最终会执行如下操作的帖子:Order.new({: